大规模模型训练tricks集锦
大规模模型训练其实就是在和计算、存储和通信玩的过程,所以我列一下跟这些相关的文章。
一. 大规模模型并行策略
先来介绍一下几种经典的并行范式,以及他们对应的经典文章
1.1 数据并行(Data parallelism)
不同设备执行相同模型,不同数据。

▲数据并行
这个比较简单,贴一篇PyTorch DDP:PyTorch Distributed: Experiences on Accelerating Data Parallel Training
1.2 模型并行(Model Parallelism or Tensor Parallelism)
不同设备执行相同数据,模型不同部分,图为行切分模型并行的一个例子。
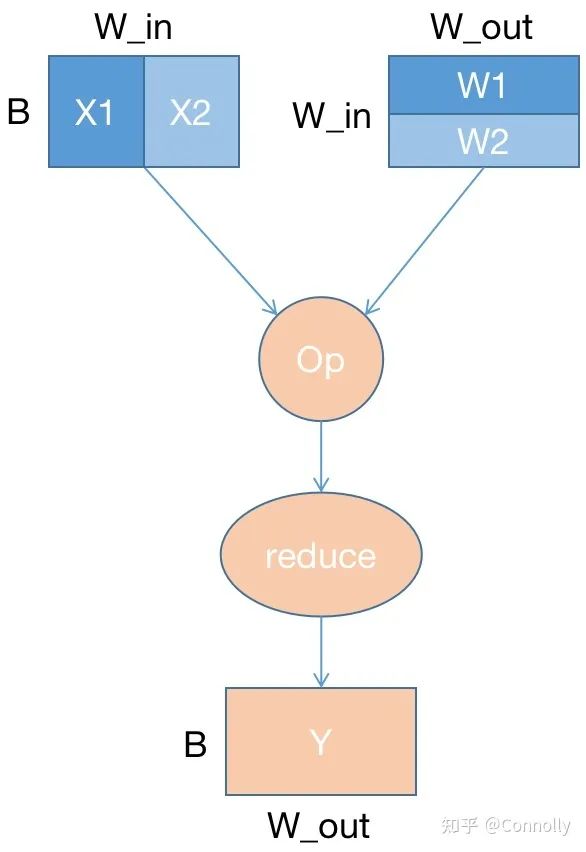
▲模型并行
代表性工作:
-
Megatron-LM: Efficient Large-Scale Language Model Training on GPU Clusters
-
Mesh-Tensorflow: Mesh-TensorFlow: Deep Learning for Supercomputers
1.2.1 高维模型并行
对参数矩阵进行二维以上切分的方法,目前尤洋的潞晨科技主推的夸父分布式框架在做这个。
- 夸父:Colossal-AI: A Unified Deep Learning System For Large-Scale Parallel Training
里面实现了2D,2.5D,3D并行
1.3 流水线并行(Pipeline parallelism)
以前也叫层间模型并行(inter-layer parallelism)。流水线并行分阶段(stage)运行模型,不同阶段之间可以流水化执行。

1.3.1 PipeDream一族
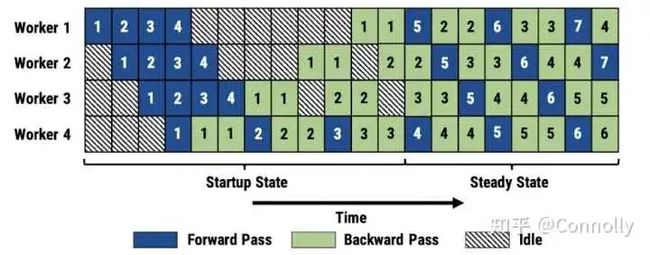
▲PipeDream 1F1B异步流水线
微软msr-fiddle团队提出的。不要在谷歌上搜PipeDream...,到github上搜。
PipeDream一族流水线是异步流水线,因为用的是异步更新(第N+m次的前向传播利用的是第N次更新的参数),所以可能存在一定的收敛性问题。但是实际应用上业界还没有发现大问题。
-
PipeDream: Fast and Efficient Pipeline Parallel DNN Training
-
PipeDream-2BW: Memory-Efficient Pipeline-Parallel DNN Training
-
HetPipe: Enabling Large DNN Training on (Whimpy) Heterogeneous GPU Clusters through Integration of Pipelined Model Parallelism and Data Parallelism
1.3.2 GPipe一族
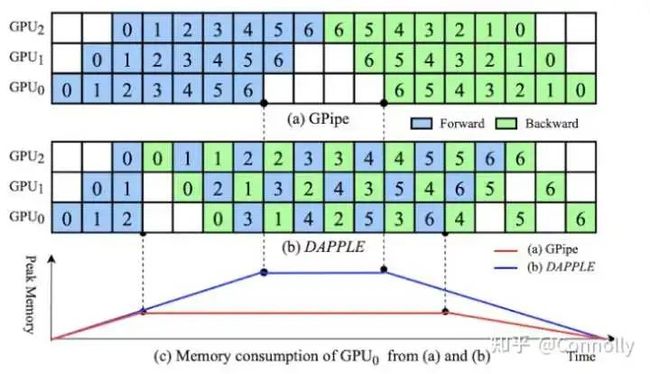
Gpipe和DAPPLE
Google最早提出的同步流水线,每一个minibatch计算完后进行同步后再计算下一个minibatch。
-
GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism
-
阿里的DAPPLE,目前业界最流行的流水线,Megatron的PipeDream-1F1B其实跟这个本质上是一个东西: DAPPLE: A Pipelined Data Parallel Approach for Training Large Models
-
双向化的GPipe,个人看好的一种内存计算折中方案:Chimera: efficiently training large-scale neural networks with bidirectional pipelines
1.4 重计算(Recomputation or Checkpointing)
华为把他列到了并行策略里,所以在这也提一提。
重计算将前向计算的激活值丢弃,在后向计算时再重新进行计算,节省了巨量的激活值开销。
pytorch的话用torch.utils.checkpoint就可以实现,很方便。
原始论文:Algorithm 799: Revolve: An implementation of checkpointing for the reverse or adjoint mode of computational differentiation
陈天奇最早把他带到了机器学习里:Training Deep Nets with Sublinear Memory Cost
1.5 零冗余优化器 (Zero REdundancy Optimizer)
很多公司把他也当做一种并行的策略(sharding),所以我也列在这里。
大名鼎鼎的ZeRO,来自于微软的DeepSpeed团队。在执行的逻辑上是数据并行,但是同时可以达到模型并行的显存优化效果。
-
ZeRO: memory optimizations toward training trillion parameter models
-
Meta(原Facebook)的FSDP,不同名字而已:[Fully Sharded Data Parallel: faster AI training with fewer GPUs][1] (混进来一篇不是paper的东东)
1.6 专家并行
现在为了扩大模型规模,很多人都在使用的方法

-
MoE Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
-
谷歌 GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
1.7 其他并行方法
几种针对Transformer模型训练中数据sequence_length维度的并行方法
-
谷歌的 TeraPipe: Token-Level Pipeline Parallelism for Training Large-Scale Language Models,本质上是一种流水线
-
新加坡国立(夸父)的 Sequence Parallelism: Making 4D Parallelism Possible
二. 显存优化技术
2.1 重计算
1.4 提到过了,不做赘述。
2.2 Offload
拿通信换显存的一种方法,简单来说就是让模型参数、激活值等在CPU内存和GPU显存之间左右横跳。
-
ZeRO-Offload: Democratizing Billion-Scale Model Training
-
ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning
2.3 优化器
为分布式训练设计的优化器
-
尤洋提出的用于大批量卷积神经网络训练的自适应优化器LARS: Layer-wise Adaptive Moments optimizer for Batch training
-
还是尤洋提出的用于大批量 BERT 训练的新型优化器 LAMB:Large Batch Optimization for Deep Learning: Training BERT in 76 minutes
节省显存的优化器
- Adafactor: Adaptive Learning Rates with Sublinear Memory Cost
低精度存储优化器状态的优化器
-
DeepSpeed: 1-bit Adam: Communication Efficient Large-Scale Training with Adam's Convergence Speed
-
DeepSpeed: 1-bit LAMB: Communication Efficient Large-Scale Large-Batch Training with LAMB's Convergence Speed
2.4 内核优化
以这个为例,Self-attention Does Not Need Memory
这个我研究的时候写了个实现。
[Connolly:Self Attention 固定激活值显存分析与优化及PyTorch实现][2]
目前因为大模型都是基于Transformer的,我认为Transformer核的优化是比较关键的:主要是可以把softmax和layernorm的激活值给去掉。可以参考DeepSpeed里[Transformer核的实现][3]。
三. 通信
这两篇博客可以涵盖大部分深度学习中的通信问题了。
[ZOMI酱:分布式训练硬核技术——通讯原语][4]
[兰瑞Frank:腾讯机智团队分享--AllReduce算法的前世今生][5]
3.1 通信方式
- 参数服务器:经典的主从节点模式,例子有PyTorch DP,基于PS的深度学习是李牧提出的,对就是这个人->[跟李沐学AI的个人空间_哔哩哔哩_Bilibili][6] 。现在多用于大规模的推荐系统。如果主节点弄得多的话,它的性能甚至可以超过Allreduce,比如在BytePS里提到的:A Unified Architecture for Accelerating Distributed DNN Training in Heterogeneous GPU/CPU Clusters 。

- 无参数服务器:采用集合通信的方法来实现模型参数、梯度等信息的同步,例子有PyTorch DDP,[horovod][7],DeepSpeed等等,目前比较流行。
3.2 通信优化
- 环状路由,采用ring的方式来进行通信,比原始方法的通信量降低N倍(N为设备数量),最早应该是[百度提出][8]用来搞深度学习的,现在PyTorch DDP,horovod,DeepSpeed等都有相应实现。
四. 流行大模型
时间,名字,组织,大小,论文或报告
-
2021.12.9 GLaM Google Brain 1.162T, [blog][9]
-
2021.12.8 Gopher Google DeepMind 280 B, [deepmind][10]
-
2021.12.8 Wenxin Baidu and PengCheng Lab 260 B, [arxiv][11]
-
2021.10.25 M6-10T Alibaba 10T, [arxiv][12]
-
2021.9.28 Yuan 1.0 Inspur 245.7 B, [arxiv][13]
-
2021.8 Jurassic-1 AI21 178B, [tech paper][14]
-
2021.5 Wudao 2.0 BAAI 1.75 T, ?
-
2021.4.26 Pangu-alpha Huawei and PengCheng Lab 207 B, [arxiv][15]
-
2020.5 GPT3 Open-AI 175 B, [arxiv][16]
五. 分布式框架
-
Colossal-AI,最新的一批框架,主打多维模型并行:Colossal-AI: A Unified Deep Learning System For Large-Scale Parallel Training (2021)
-
DeepSpeed,跟英伟达玩得比较近,大家都在学:Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (2020)
-
Horovod,比较经典,多人使用的Tensorflow分布式计算框架:Horovod: fast and easy distributed deep learning in TensorFlow。(2018)
-
Megatron-LM,手动的DP+MP+PP性能baseline:Efficient Large-Scale Language Model Training on GPU Clusters (2021)
-
OneFlow,介绍了SBP和Actor,现在业界都在学:OneFlow: Redesign the Distributed Deep Learning Framework from Scratch (2021)
-
PaddlePaddle,异构现在做的挺好:End-to-end Adaptive Distributed Training on PaddlePaddle (2021)
六. 自动并行
更新一波,我搜集的一些自动并行策略搜索算法,对部分内容进行了分析,欢迎大家star~
[https://github.com/ConnollyLeon/awesome-Auto-Parallelismgithub.com/ConnollyLeon/awesome-Auto-Parallelism] [17]
6.1 Jia Zhihao
据我所知...贾志豪开创了自动并行的先河,他提出的FlexFlow现在和Facebook的推荐模型DLRM玩的比较近。
-
OptCNN,用基于图搜索的动态规划来寻找CNN的自动并行策略: Exploring Hidden Dimensions in Parallelizing Convolutional Neural Networks (2018)。以OptCNN为起点,也延伸出了ToFu,TensorOpt等等的工作,老师木经常提。
-
FlexFlow,用蒙特卡洛马尔科夫链(MCMC)来搜索数据并行和模型并行策略:Beyond Data and Model Parallelism for Deep Neural Networks (2018)
6.2 Google
6.2.1 GSPMD
谷歌提出的GSPMD,现在被多个框架包括Tensorflow,MindSpore,OneFlow,PaddlePaddle借鉴和修改后使用。
GSPMD是一种半自动并行,用户手动配置部分的并行操作,然后他会对并行策略进行传播得到完成的并行策略。
- GSPMD: General and Scalable Parallelization for ML Computation Graphs (2021)
6.2.2 Automap
Google DeepMind提出的,利用蒙特卡洛树和交互网络进行策略的预测,生成策略的效果可逼近Megatron-LM:Automap: Towards Ergonomic Automated Parallelism for ML Models (2021)
6.2.3 REINFORCE
Google Brain做的,最早利用强化学习来做自动并行的方法,做的是层间模型并行:
Device Placement Optimization with Reinforcement Learning (2017)
6.3 msr-fiddle
又是PipeDream的那帮人,
-
利用动态规划和Profile技术来搜索数据并行及流水线并行策略:PipeDream: Fast and Efficient Pipeline Parallel DNN Training (2018)
-
Dnn-partition: 利用动态规划和整数规划来搜索数据并行和模型并行的策略:Efficient Algorithms for Device Placement of DNN Graph Operators
-
PipeDream作者的师弟(现在还不在fiddle),利用网格搜索方法来生成最优的并行策略:DistIR: An Intermediate Representation and Simulator for Efficient Neural Network Distribution (2021)
-
利用两级动态规划方法来做数据并行,模型并行和流水线并行策略的搜索 Piper: Multidimensional Planner for DNN Parallelization (2021)
6.4 MindSpore
MindSpore现在只能处理数据并行和模型并行的自动策略搜索,双递归算法的速度远比动态规划要快。
-
OptCNN的进阶版,可以处理非线性模型:TensorOpt: Exploring the Tradeoffs in Distributed DNN Training with Auto-Parallelism (2020)
-
双递归算法 Efficient and Systematic Partitioning of Large and Deep Neural Networks for Parallelization (2020)
6.5 阿里
- 利用强化学习的方法来解决策略划分问题,Auto-MAP: A DQN Framework for Exploring Distributed Execution Plans for DNN Workloads (2020)
各大公司现在都在暗搓搓的做自动并行,今年应该能看到百花齐放,部署到大模型上的场景:)
Alpa出来以后,引发了一大波MLSys的热点,卷起来了。