Linux中使用redis(四)Redis集群(cluster模式)
Redis集群(cluster模式)
1、什么是集群
Redis 集群(包括很多小集群)实现了对Redis的水平扩容,即启动N个redis节点,将整个数据库分布存储在这N个节点中,每个节点存储总数据的1/N,即一个小集群存储1/N的数据,每个小集群里面维护好自己的1/N的数据。
Redis 集群通过分区(partition)来提供一定程度的可用性(availability): 即使集群中有一部分节点失效或者无法进行通讯, 集群也可以继续处理命令请求。
该模式的redis集群特点是:分治、分片。
2、为什么使用
-
容量不够,redis如何进行扩容?
-
并发写操作, redis如何分摊?
-
另外,主从模式,薪火相传模式,主机宕机,导致ip地址发生变化,应用程序中配置需要修改对应的主机地址、端口等信息。
-
之前通过代理主机来解决,但是redis3.0中提供了解决方案。就是无中心化集群配置。
3、集群连接
普通方式登录:可能直接进入读主机,存储数据时,会出现MOVED重定向操作,所以,应该以集群方式登录
集群登录:redis-cli -c -p 6379 采用集群策略连接,设置数据会自动切换到相应的写主机.
4、*redis cluster** 如何分配这六个节点?
-
一个集群至少要有三个主节点。
-
选项 –cluster-replicas 1 :表示我们希望为集群中的每个主节点创建一个从节点。
-
分配原则尽量保证每个主数据库运行在不同的IP地址,每个从库和主库不在一个IP地址上。
5、集群搭建:
1、创建节点
1) 通过utils路径下install_server.sh执行文件创建6个不同的redis节点,端口号分别为6379、6380、6381、8362、6383、6384.
创建完后在Linux的/etc/redis路径下
[root@localhost utils]# ./install_server.sh 6379/6380/6381/.
2、修改以下六个配置文件,修改6个redis节点的配置文件

port:63XX # 设置成对应服务专属的端口号
bind 0.0.0.0
cluster-enabled yes
cluster-config-file nodes-63XX.conf # 设置成对应服务专属的名字
cluster-node-timeout 15000
daemonize yes
protedted-mode no
pidfile /var/run/redis_63XX.pid
dbfilename "dump6380.rdb" # 设置成对应服务专属的名字1)如果各个节点原本有存储数据,则先将各个节
[root@localhost src]# ps -ef | grep redis点的数据文件清空
-数据清空 flushdb命令清除所有节点中(我的是6个节点,3主3从)的数据
从机不能清空(从机只能读数据),只需要清空主机数据(3个主机)

3、启动以上几个redis实例,启动六个节点
[root@localhost src]# ./redis-server /etc/redis/63XX.conf
[root@localhost src]# ./redis-server /etc/redis/63XX.conf
[root@localhost src]# ./redis-server /etc/redis/63XX.conf
[root@localhost src]# ./redis-server /etc/redis/63XX.conf
[root@localhost src]# ./redis-server /etc/redis/63XX.conf
[root@localhost src]# ./redis-server /etc/redis/63XX.conf4、查看状态,查看各个节点是否启动成功
[root@localhost src]# ps -ef | grep redis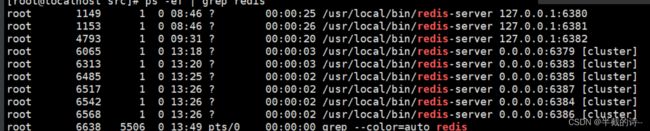
5、配置集群,配置静态IP (否则ip改变后集群失效)前三个是主节点,后三个是从节点
命令格式: --cluster-replicas 1 表示为每个master创建一个slave节点`
`注意:这里的IP为每个节点所在机器的真实IP[root@localhost src]# ./redis-cli --cluster create 192.168.100.128:6379 192.168.100.128:6383 192.168.100.128:6385 192.168.100.128:6387 192.168.100.128:6384 192.168.100.128:6386 --cluster-replicas 1
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 192.168.100.128:6384 to 192.168.100.128:6379
Adding replica 192.168.100.128:6386 to 192.168.100.128:6383
Adding replica 192.168.100.128:6387 to 192.168.100.128:6385
>>> Trying to optimize slaves allocation for anti-affinity
[WARNING] Some slaves are in the same host as their master
M: caba0d507ac4b7c81be5323b5e151d3919b26ac6 192.168.100.128:6379
slots:[0-5460] (5461 slots) master
M: ef94cab7f5515a19a376f623dd4df2e98fbf165e 192.168.100.128:6383
slots:[5461-10922] (5462 slots) master
M: 0f2887a983843cbbae0cc6801b935f4847f58c76 192.168.100.128:6385
slots:[10923-16383] (5461 slots) master
S: 4dbea80400032284de9d161589e995e84a9271c5 192.168.100.128:6387
replicates caba0d507ac4b7c81be5323b5e151d3919b26ac6
S: 5081d02398c650c0565e77682396528f128cbca5 192.168.100.128:6384
replicates ef94cab7f5515a19a376f623dd4df2e98fbf165e
S: 40e7769f0c20dce718fa137b958c971996b36860 192.168.100.128:6386
replicates 0f2887a983843cbbae0cc6801b935f4847f58c76
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
.
>>> Performing Cluster Check (using node 192.168.100.128:6379)
M: caba0d507ac4b7c81be5323b5e151d3919b26ac6 192.168.100.128:6379
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: 5081d02398c650c0565e77682396528f128cbca5 192.168.100.128:6384
slots: (0 slots) slave
replicates ef94cab7f5515a19a376f623dd4df2e98fbf165e
S: 40e7769f0c20dce718fa137b958c971996b36860 192.168.100.128:6386
slots: (0 slots) slave
replicates 0f2887a983843cbbae0cc6801b935f4847f58c76
S: 4dbea80400032284de9d161589e995e84a9271c5 192.168.100.128:6387
slots: (0 slots) slave
replicates caba0d507ac4b7c81be5323b5e151d3919b26ac6
M: 0f2887a983843cbbae0cc6801b935f4847f58c76 192.168.100.128:6385
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
M: ef94cab7f5515a19a376f623dd4df2e98fbf165e 192.168.100.128:6383
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
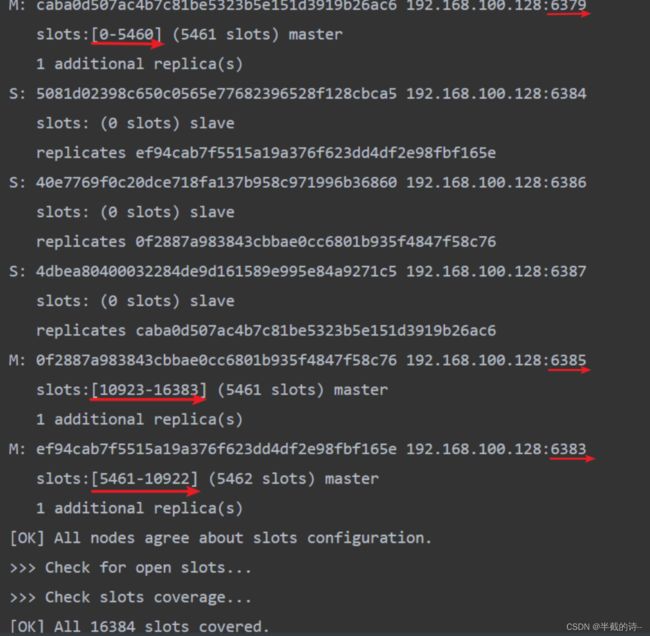
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.6)查看主从关系**
命令格式:redis-cli --cluster check 【本台redis自己的IP】:【本台redis自己的端口】`[root@localhost src]# ./redis-cli --cluster check 192.168.100.128:6379
192.168.100.128:6379 (caba0d50...) -> 1 keys | 5461 slots | 1 slaves.
192.168.100.128:6385 (0f2887a9...) -> 0 keys | 5461 slots | 1 slaves.
192.168.100.128:6383 (ef94cab7...) -> 1 keys | 5462 slots | 1 slaves.
[OK] 2 keys in 3 masters.
0.00 keys per slot on average.
>>> Performing Cluster Check (using node 192.168.100.128:6379)
M: caba0d507ac4b7c81be5323b5e151d3919b26ac6 192.168.100.128:6379
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: 5081d02398c650c0565e77682396528f128cbca5 192.168.100.128:6384
slots: (0 slots) slave
replicates ef94cab7f5515a19a376f623dd4df2e98fbf165e
S: 40e7769f0c20dce718fa137b958c971996b36860 192.168.100.128:6386
slots: (0 slots) slave
replicates 0f2887a983843cbbae0cc6801b935f4847f58c76
S: 4dbea80400032284de9d161589e995e84a9271c5 192.168.100.128:6387
slots: (0 slots) slave
replicates caba0d507ac4b7c81be5323b5e151d3919b26ac6
M: 0f2887a983843cbbae0cc6801b935f4847f58c76 192.168.100.128:6385
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
M: ef94cab7f5515a19a376f623dd4df2e98fbf165e 192.168.100.128:6383
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
7、主节点数据写测试**
加参数 -c ,防止路由失效
[root@bogon src]# ./redis-cli -p 6381 -c
127.0.0.1:6381> get name
-> Redirected to slot [5798] located at 192.168.109.149:6380
(nil)
192.168.109.149:6380> get name
(nil)
192.168.109.149:6380>8、从节点读数据测试**
情况:redis cluster集群中slave节点能成功复制master节点数据槽数据,但是无法get数据,显示只能到对应的master节点读取
原因:Redis Cluster集群中的从节点,官方默认设置的是不分担读请求的、只作备份和故障转移用,当有请求读向从节点时,会被重定向对应的主节点来处理
解决办法:在get数据之前先使用命令readonly,这个readonly告诉 Redis Cluster 从节点客户端愿意读取可能过时的数据并且对写请求不感兴趣
注意:断开连接后readonly就失效了,再次连接需要重新使用该命令
[root@bogon src]# ./redis-cli -p 6379 -c
127.0.0.1:6379> set name zhangsan
-> Redirected to slot [5798] located at 192.168.109.149:6380
OK
192.168.109.149:6380> get name
"zhangsan"
192.168.109.149:6380>
[root@bogon src]# ./redis-cli -p 6383 -c
127.0.0.1:6383> get name
-> Redirected to slot [5798] located at 192.168.109.149:6380
"zhangsan"
192.168.109.149:6380>
[root@bogon src]# ./redis-cli -p 6383 -c
127.0.0.1:6383> readonly
OK
127.0.0.1:6383> get name
"zhangsan"
127.0.0.1:6383>根据图1主节点set的哈希值,通过哈希值找到图2对应的哈希值范围,找到对应的主节点

9、报错信息
启动集群会出现的报错信息:无法连接
![]()
解决办法:
127.0.0.1:6385> shutdown
[root@localhost src]# systemctl stop redis_6385.service
[root@localhost src]# systemctl start redis_6385.service
再次执行启动集群