Mysql事务详细介绍
事务是什么?
数据库事务就是访问并可能操作各种数据项的一个数据库操作序列,是一个不可分割的工作单位;事务由事务开始与事务结束之间执行的全部数据库操作组成。
事务是数据为了保证操作的原子性,隔离性,持久性,一致性,数据库提供了一套机制,在同一事务中,如果有多条sql执行,事务确保执行的可靠性。
注:mysql中只有Innodb引擎支持了事务
事务的特性
ACID:原子性Atomicity,一致性Consistency,隔离性Isolation,持久性durability;(缘一持续隔离)
1.原子性Atomicity
一个事务中的多条sql要么都执行,要么都不执行
2.持久性durability
事务提交后,对数据的修改就是永久的,即使系统故障也不会丢失。
3.隔离性Isolation
数据库允许多个并发事务同时对数据进行操作,当多个事务对数据进行操作时,我们需要不同的隔离机制(级别)进行控制,不同的隔离级别能够读到正确的数据是不一样的,防止数据的不完整。且需要保证同一时间只有一个事务在写操作。
多用于读和写操作;
事务隔离分为以下不同级别(简单介绍,下面有更为详细的说明)
读未提交,即b读到了a未提交的数据
读已提交,即b只能读到a已经提交的数据,a即使修改了,但如果还没提交,b就读不到,只能读到已经提交的数据。
可重复读:b事务相同的查询语句读到的数据永远与第一次保持一致,可以多次重复读。
串行化:一个事务一个事务进行,不会出现读脏数据、幻读、不可重复读等问题
4.一致性
数据经过很多次的操作,最终的结果要与预期的结果一致,保证数据的完整性,原子性、隔离性、持久性都是为了保证数据的一致性。
mysql设置事务处理
1.事务的自动提交与手动提交
设置自动提交:
SET GLOBAL(session) autocommit=1;
global是全局,也可以设置当前会话,global改为session即可
mysql中只有innodb支持事务,且默认是自动提交。
设置手动提交:
SET GLOBAL(session) autocommit=0;
查看事务的提交模式:
SHOW GLOBAL(session) VARIABLES LIKE 'autocommit';
2.事务的手动开启以及结束
我们设置为事务手动提交后:
通过 begin ,Rollback,Commit 实现
Begin / start transaction;开始一个事务
Rollback 事务回滚
Commit 事务提交
3.事务的四种隔离级别
为什么要有隔离级别?
MySQL 是一个服务器/客户端架构的软件,对于同一个服务器来说,可以有若干个客户端与之连接,每个客户端与服务器连接上之后,就可以称之为一个会话。我们可以同时在不同的会话里输入各种语句,这些语句可以作为事务的一部分进行处理。不同的会话可以同时发送请求,也就是说服务器可能同时在处理多个事务,这样子就会导致不同的事务可能同时访问到相同的记录。我们前边说过事务有一个特性称之为隔离性,理论上在某个事务对某个数据进行访问时,其他事务应该进行排队,当该事务提交之后,其他事务才可以继续访问这个数据。但是这样子的话对性能影响太大,所以设计数据库的大叔提出了各种隔离级别,来最大限度的提升系统并发处理事务的能力.
只有 InnoDB 支持事务,所以这里说的事务隔离级别是指 InnoDB 下的事务隔离级别。
设置事务隔离级别:
SET GLOBAL(session) TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
(以读未提交举例,不同的级别我们修改即可)
1.读 未提交:
即B事务读到了A事务未提交的数据
A事务读数据时,只要其他事务对数据进行修改,即使没有提交这个修改,A事务也会读到。
问题:产生脏读(即读到了垃圾数据,因为A事务可能会回滚),安全性太差,数据准确性大幅降低。
解决脏读:设置隔离级别为 读 已提交;
read uncommitted
2.读 已提交:
即B事务读的只能是A事务已经提交的数据;
只要别的事务提交了,那么另一个事务就可以看到,每次读到的都是最新的数据。
解决了脏读问题,但会产生不可重复读问题(B事务在开启后的两次查询中,查询结果不相同),因为这个隔离级别下,无论a是否修改数据,b只能查到原本表中的数据,除非a进行事务提交,这时b再次查,查到的是新的数据,形成两次不同的数据,产生不可重复读问题
read committed
3.可重复 读:
B事务在开启后的两次查询中,两次查询结果是相同的;(这个隔离级别是mysql默认隔离级别)
B事务开启后,第一次读到数据后,就定格下来,后面的读操作读到的就和这个数据一致,即使这个过程中别的事务可能已经对数据修改提交过了。所以叫做可重复读,因为你不论读多少次,都是第一次读的结果,可以重复读。
解决不可重复读问题,不会出现幻读;但如果在sql语句后加上update,可能会出现幻读。
repeatable read
一般的查询操作不会产生幻读,但如果Select .. for update会出现幻读
4.串行hang化
事务串行执行(),避免了以上所有问题;
加锁实现,只要有一个事务执行,其他事务就得等待,哪怕是读操作,也会将读到的数据锁住;
一个事务一个事务执行,安全度最高,但速度、效率太慢。
不同隔离级别会出现的问题
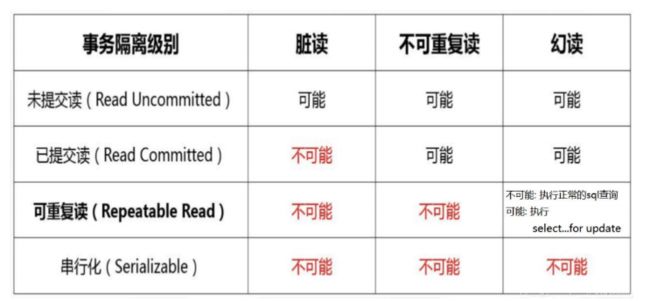
脏读问题、不可重复读问题,都是行级的错误,是内容方面的错误。而幻读是数据数量上的错误。
幻读的定义:两次相同的查询条件,出来的数据数量不同; 事务A 按照一定条件进行数据读取, 期间事务B 插入了相同搜索条件的新数据,事务A再次按照原先条件进行读取时,发现了事务B新插入的数据,这种情况称为幻读;
事务四种特性实现原理
即ACID四种特性的实现原理
MySQL 的日志有很多种,如二进制日志、错误日志、查询日志、慢查询日志等,此外 InnoDB 存储引擎还提供了两种事务日志:redolog(重做日志)和 undolog(回滚日志)。其中 redolog 用于保证事务持久性;undolog 则是事务原子性和隔离性实现的基础。即他还可以帮助实现隔离性
1.实现原子性
原子性的实现靠的是 undolog(回滚日志)
undolog:保存每次操作的反向操作,如我们执行insert操作,那么日志中保存delete操作。当会回滚时执行一个相反的update,把数据改回去
实现原子性的关键,是当事务回滚时能够撤销所有已经成功执行的 sql 语句。InnoDB 实现回滚,靠的是 undo log:当事务对数据库进行修改时,InnoDB会生成对应的 undo log;如果事务执行失败或调用了 rollback,导致事务需要回滚,便可以利用 undo log 中的信息将数据回滚到修改之前的样子。undo log 属于逻辑日志,它记录的是 sql 执行相关的信息。当发生回滚时,InnoDB 会根据 undo log 的内容做与之前相反的工作:对于每个 insert,回滚时会执行 delete;对于每个 delete,回滚时会执行 insert;对于每个 update,回滚时会执行一个相反的 update,把数据改回去。
2.实现持久性
持久性的实现靠的是 redo log(重做日志)
redo log:当执行修改数据操作时,先会将语句保存到redo log中,即使突然断电,正常后也可以通过日志恢复数据。
redo log 叫做重做日志,是保证事务持久性的重要机制。当 mysql 服务器意外崩溃或者宕机后,保证已经提交的事务,确定持久化到磁盘中的一种措施。
innodb 是以页为单位来管理存储空间的,任何的增删改差操作最终都会操作完整的一个页,会将整个页加载到 buffer pool 中,然后对需要修改的记录进行修改,修改完毕不会立即刷新到磁盘,而且仅仅修改了一条记录,刷新一个完整的数据页的话过于浪费了。但是如果不立即刷新的话,数据此时还在内存中,如果此时发生系统崩溃最终数据会丢失的,因此权衡利弊,引入了 redo log,也就是说,修改完后,不立即刷新,而是记录一条日志,日志内容就是记录哪个页面,多少偏移量,什么数据发生了什么变更。这样即使系统崩溃,再恢复后, 也可以根据 redo 日志进行数据恢复。另外,redo log 是循环写入固定的文件,是顺序写入磁盘的。
3.隔离性实现原理(MVVC)
MVCC是什么?
是一种基于多版本的并发控制协议,只有在innodb引擎下存在。
它是mysql提高性能的一种方式,配合undo log日志和版本链,让不同事务的读-写,写-读操作可以并发执行,从而提高系统性能。
MVCC可以实现读操作不对数据加锁,即普通的select请求不会加锁,提高了数据库的并发处理能力。
借助MVCC中的版本链数据库可以实现READ COMMITTED读已提交、REPEATABLE TEAD可重复读的隔离级别。
MVCC如何实现?
InnoDB 的 MVCC 是通过在每行记录后面保存两个隐藏的列来实现的。一个保存了行的事务ID trx_id,一个保存了行的回滚指针roll_pt.
trx_id:每次对某记数据行改动时,都会把对应的事务 id 赋值给 trx_id 隐藏列。
roll_pt:每次对数据进行改动时,都会把旧的版本写入到 undo 日志中,然后这个隐藏列就相当于一个指针,可以通过它来找到该记录修改前的信息。连接的多了,就形成了版本链。
版本链:是roll_pt的产物,我们对某条数据更新后,都会将旧值放到一条undolog回滚日志中,就算是该记录的一个旧版本,随着更新次数的增多,所有版本都会被roll_pt属性连接成一个链表,我们把这个链表称之为版本链,版本链的头节点就是当前记录的最新值,另外,每个版本中还包含生成该版本时对应的事务id,这个信息很重要。
读已提交实现
读已提交和可重复读两个隔离级别实现依靠的是MVVC,即通过版本链实现
读已提交:只要别的事务提交了,那么另一个事务就可以看到
特点:每次读到的都是最新的数据。
当前读:每次读时,都会给版本链拍照,所以读到的数据是最新的(前提是已提交的数据)
可重复读的实现
可重复读:B事务开启后,第一次读到数据后,就定格下来,后面的读操作读到的就和这个数据一致,即使这个过程中别的事务可能已经对数据修改过了。所以叫做可重复读,因为你不论读多少次,都是第一次读的结果,可以重复读。
也可以叫快照读,因为第一次读的时候,会把版本链拍照,下次读时,从版本快照中读,所以第一次和第二次读到数据是一致的。
串行化实现依靠锁
4.事务一致性的实现则直接由其他三个特性来保证
本文总结:本篇讲了事务是什么?详细介绍了事务的四种特性,以及四种特性如何实现?还有特性之一的隔离性中的隔离级别都有什么?几种隔离级别依靠什么原理实现?如MVCC和版本链。
总之,事务是数据库很重要的一部分,我们对事务的学习是很必要的,对事物的介绍如有不全之处欢迎友友们在评论区补充哦~