Python学了基本语法 下一步该干什么 ?
刚入门Python,学习了基本语法后,你可以开始编写简单的程序了。接下来,你可以学习Python的标准库和第三方库,掌握更多的编程技巧和知识,提高自己的编程能力。同时,也可以通过实践项目来巩固所学知识,提高自己的实战能力。
学习Python基本语法是入门的第一步,接下来你可以考虑以下几个方向:
1、数据结构和算法:学习常用的数据结构和算法,如链表、栈、队列、二叉树、排序算法等,这些知识对于编写高效的Python程序非常重要。
2、Web开发:学习Python的Web框架,如Django、Flask等,掌握Web开发的基本流程和技术。
3、数据分析和机器学习:Python在数据分析和机器学习领域有广泛的应用,学习相关的库和算法,如NumPy、Pandas、Scikit-learn等。
4、爬虫:学习如何使用Python编写爬虫程序,获取网站上的数据。
5、游戏开发:学习如何使用Python编写游戏,如Pygame等。
无论你选择哪个方向,都需要不断地练习和实践,不断地提高自己的编程能力。
Python学数据采集怎么样
Python是一种非常流行的编程语言,也是数据采集和数据分析的常用工具之一。Python有许多强大的库和框架,可以帮助你进行数据采集,例如Requests、BeautifulSoup、Scrapy等等。学习Python数据采集需要一定的编程基础,但是对于初学者来说也是可行的。以下是一些学习Python数据采集的建议:
1、学习Python基础知识,包括语法、数据类型、控制流等等。
2、学习Python的常用库和框架,例如Requests、BeautifulSoup、Scrapy等等。
3、学习HTML、CSS和JavaScript等前端知识,这些知识对于理解网页结构和网页交互非常有帮助。
4、实践项目,例如爬取网站数据、分析数据等等,通过实践来巩固所学知识。
总的来说,学习Python数据采集需要一定的时间和精力,但是对于想要从事数据分析和数据科学的人来说,是非常有用的技能。
Python如何采集数据
在Python中,有几种常用的方法可以进行数据采集:
1、网络爬虫:使用网络爬虫可以访问网页并提取所需的数据。你可以使用Python库(如Requests、BeautifulSoup、Scrapy)来发送HTTP请求、解析HTML内容,并从网页中提取和处理数据。
2、API访问:许多网站和在线服务提供API(Application Programming Interface),允许开发者通过编程方式获取数据。你可以使用Python库(如Requests、httplib2)来与API进行通信,并解析返回的数据。
3、数据库操作:Python可以连接和操作多种类型的数据库(如MySQL、PostgreSQL、MongoDB),通过执行SQL查询、插入、更新和删除数据进行数据采集。
4、文件读写:使用Python的内置文件操作函数,你可以读取和写入各种文件格式的数据(如文本文件、CSV、Excel文件等),然后进一步处理和分析数据。
5、其他数据源:使用相应的第三方库和工具,Python也可以从其他数据源(如传感器、硬件设备、Web服务等)进行数据采集。
在实际的数据采集项目中,通常需要结合上述方法来获取、处理和存储数据。这可能涉及到发送HTTP请求、解析返回的数据、清洗和转换数据、存储到数据库或文件等操作。根据具体的需求和数据来源,选择适当的方法。
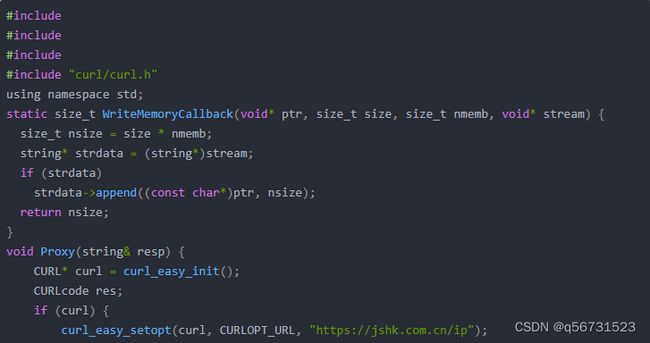
附上代码
以下是一个基于Python的数据采集代码示例,使用了Requests库发送HTTP请求和BeautifulSoup库解析HTML:
import requests
from bs4 import BeautifulSoup
# 发送HTTP请求获取网页内容
url = '目标网页的URL' # 替换为目标网页的实际URL
response = requests.get(url)
# 解析网页内容
soup =.text, 'html.parser')
# 提取所需数据
data_list = []
# 根据网页结构和标签查找目标数据
target_elements = soup.find_all('div', class_='target-class')
for element in target_elements:
# 提取需要的数据字段
data = element.text.strip() # 做适当的文本清洗处理
data_list.append(data)
# 打印提取的数据
for data in data_list:
print(data)
请将上述示例中的 ‘目标网页的’ 替换为你要采集数据的实际目标网页URL。另外,根据你所需的数据和目标网页的结构,请调整选择要提取的标签和类名。
这只是一个简单的示例,实际应用中可能需要根据具体需求进行更复杂的解析和处理。同时,在进行网络数据采集时,请遵守相关网站的使用条款,并确保符合法律规定。