prometheus+grafana+alertmanager服务器运维监控并实现钉钉报警
背景:
监控对it运维来说到底有多重要?“因为你是我的眼,让我看见这世界就在我眼前”,这是一首耳熟能详的歌曲《你是我的眼》。监控,对于it运维工程师来说就是眼睛,如果没有监控,it运维工作就无从谈起;如果没有监控,it运维工程师就成了盲人。
一个良好的监控系统可以快速地发现并定位问题,减少宕机时间,提高故障处理速度,减轻it运维工作压力,甚至可以促进家庭和谐。
技术选型调研:
Prometheus有Google与Kubernetes 社区强力支持,尽快告警功能简单,但是开源社区异常火爆,作为CNCF第二开源项目(第一开源项目Kubernetes Borg的开源版本),Google Borgmon的开源版本(用于监控Borg),未来发展前景看好
TICK 由InfluxData公司支持,高可用、水平扩展、高级备份恢复等功能需要企业License。
Open-falcon最初为小米公司开发,采用多模块架构,初始部署比较复杂,监控功能相对完善,不过目前有开源社区人员维护,版本迭代无法保证,且国际化不够。
Zabbix 传统企业级监控方案,由Zabbix公司支持。监控功能全面,缺点在于存储限制与不支持水平扩展。
综上所述,我们选择Prometheus!
Prometheus简介:
Prometheus(普罗米修斯)是一套开源的监控&报警&时间序列数据库的组合,起始是由SoundCloud公司开发的。随着发展,越来越多公司和组织接受采用Prometheus,社会也十分活跃,他们便将它独立成开源项目,并且有公司来运作。Google SRE的书内也曾提到跟他们BorgMon监控系统相似的实现是Prometheus。现在最常见的Kubernetes容器管理系统中,通常会搭配Prometheus进行监控。
Prometheus基本原理是通过HTTP协议周期性抓取被监控组件的状态,这样做的好处是任意组件只要提供HTTP接口就可以接入监控系统,不需要任何SDK或者其他的集成过程。这样做非常适合虚拟化环境比如VM或者Docker 。
Prometheus应该是为数不多的适合Docker、Mesos、Kubernetes环境的监控系统之一。
输出被监控组件信息的HTTP接口被叫做exporter 。目前互联网公司常用的组件大部分都有exporter可以直接使用,比如Varnish、Haproxy、Nginx、MySQL、Linux 系统信息 (包括磁盘、内存、CPU、网络等等),具体支持的源看:https://github.com/prometheus。
与其他监控系统相比,Prometheus的主要特点是:
- 一个多维数据模型(时间序列由指标名称定义和设置键/值尺寸)。
- 非常高效的存储,平均一个采样数据占~3.5bytes左右,320万的时间序列,每30秒采样,保持60天,消耗磁盘大概228G。
- 一种灵活的查询语言。
- 不依赖分布式存储,单个服务器节点。
- 时间集合通过HTTP上的PULL模型进行。
- 通过中间网关支持推送时间。
- 通过服务发现或静态配置发现目标。
- 多种模式的图形和仪表板支持。
架构预览:

开始安装:
注意⚠️本文所有操作使用docker, 请参考 docker安装及简单命令
docker pull prom/node-exporter
docker pull prom/prometheus
docker pull grafana/grafanadocker images可查看下载的镜像:

其中node_exporter – 用于机器系统数据收集
docker run -d -p 9100:9100 -v /proc:/host/proc:ro -v /sys:/host/sys:ro -v /:/rootfs:ro prom/node-exporter查看运行状态:
http://121.41.18.234:9100/metrics

prometheus
vi /opt/prometheus/prometheus.yml
global:
scrape_interval: 60s
evaluation_interval: 60s
scrape_configs:
- job_name: prometheus
static_configs:
- targets: ['121.41.18.234:9090']
labels:
instance: prometheus
- job_name: linux
static_configs:
- targets: ['121.41.18.234:9100']
labels:
instance: localhost运行:
docker run -d -p 9090:9090 -v /opt/prometheus:/etc/prometheus prom/prometheushttp://121.41.18.234:9090/graph

grafana
chmod 777 /data/grafana
docker run -d -p 3000:3000 --name=grafana -v /opt/grafana-storage:/var/lib/grafana grafana/grafana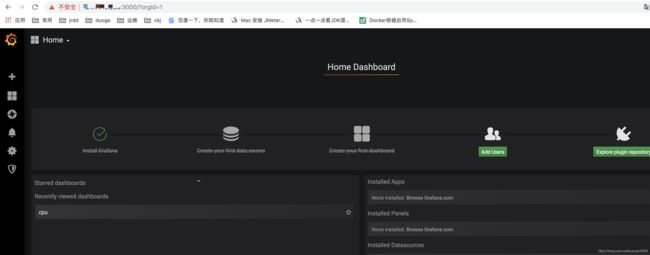

至此,简单的监控已经完成了,图形界面的设置可自行百度,网上有很多。
系统默认推荐11074
docker run -d --name mysql_exporter --restart always -p 9104:9104 -e DATA_SOURCE_NAME="root:yunkun920801@(121.41.19.237:3306)/" prom/mysqld-exportermysql(推荐7362、12650)
钉钉报警:
首先钉钉建立一个群聊,然后通过智能群助手新建机器人获取Webhook
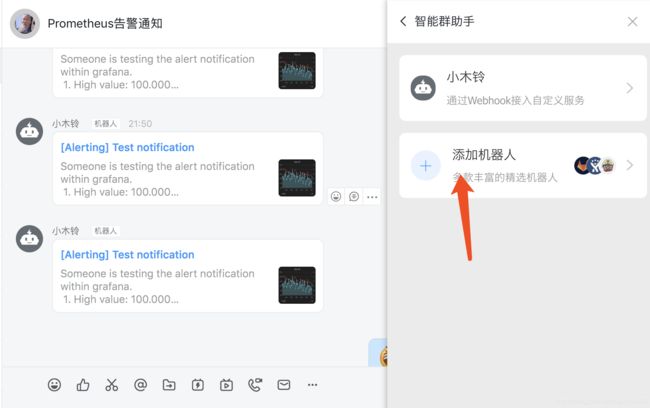

docker run -d --restart always -p 8060:8060 timonwong/prometheus-webhook-dingtalk:v0.3.0 --ding.profile="webhook1=刚才的webhook"altermanager:
[root@iZbp155czz7lmsi13r3qmqZ prometheus]# vi /opt/alertmanager/alertmanager.yml
global:
resolve_timeout: 5m
route:
receiver: webhook
group_wait: 30s
group_interval: 1m
repeat_interval: 4h
group_by: [alertname]
routes:
- receiver: webhook
group_wait: 10s
receivers:
- name: webhook
webhook_configs:
- url: http://121.41.18.234:8060/dingtalk/webhook1/send
send_resolved: true
~运行
docker run -d -p 9093:9093 -v /opt/alertmanager/:/etc/alertmanager/ --name alertmanager prom/alertmanager 新增告警规则:
[root@iZbp155czz7lmsi13r3qmqZ prometheus]# vi /opt/prometheus/rules.yml
groups:
- name: host_monitoring
rules:
- alert: 内存报警
expr: netdata_system_ram_MiB_average{chart="system.ram",dimension="free",family="ram"} < 800
for: 2m
labels:
team: node
annotations:
Alert_type: 内存报警
Server: '{{$labels.instance}}'
#summary: "{{$labels.instance}}: High Memory usage detected"
explain: "内存使用量超过90%,目前剩余量为:{{ $value }}M"
#description: "{{$labels.instance}}: Memory usage is above 80% (current value is: {{ $value }})"
- alert: CPU报警
expr: netdata_system_cpu_percentage_average{chart="system.cpu",dimension="idle",family="cpu"} < 20
for: 2m
labels:
team: node
annotations:
Alert_type: CPU报警
Server: '{{$labels.instance}}'
explain: "CPU使用量超过80%,目前剩余量为:{{ $value }}"
#summary: "{{$labels.instance}}: High CPU usage detected"
#description: "{{$labels.instance}}: CPU usage is above 80% (current value is: {{ $value }})"
- alert: 磁盘报警
expr: netdata_disk_space_GiB_average{chart="disk_space._",dimension="avail",family="/"} < 4
for: 2m
labels:
team: node
annotations:
Alert_type: 磁盘报警
Server: '{{$labels.instance}}'
explain: "磁盘使用量超过90%,目前剩余量为:{{ $value }}G"
- alert: 服务告警
expr: up == 0
for: 2m
labels:
team: node
annotations:
Alert_type: 服务报警
Server: '{{$labels.instance}}'
explain: "netdata服务已关闭"[root@iZbp155czz7lmsi13r3qmqZ prometheus]# vi /opt/prometheus/prometheus.yml
global:
scrape_interval: 60s
evaluation_interval: 60s
# Alertmanager配置
alerting:
alertmanagers:
- static_configs:
- targets: ["121.41.18.234:9093"]
# rule配置,首次读取默认加载,之后根据evaluation_interval设定的周期加载
rule_files:
- "rules.yml"
scrape_configs:
- job_name: prometheus
static_configs:
- targets: ['121.41.18.234:9090']
labels:
instance: prometheus
- job_name: linux
static_configs:
- targets: ['121.41.18.234:9100']
labels:
instance: localhost配置完成后重启prometheus

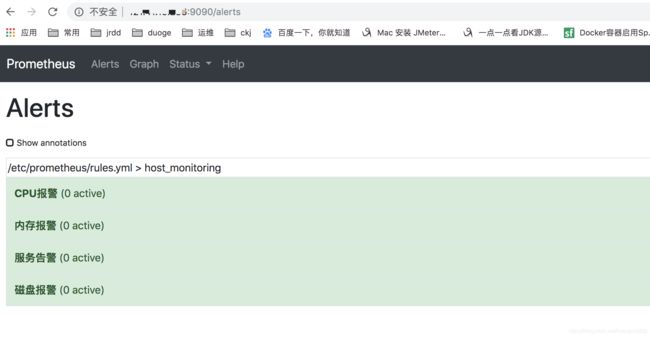
测试报警:关闭export

等两分钟可发现
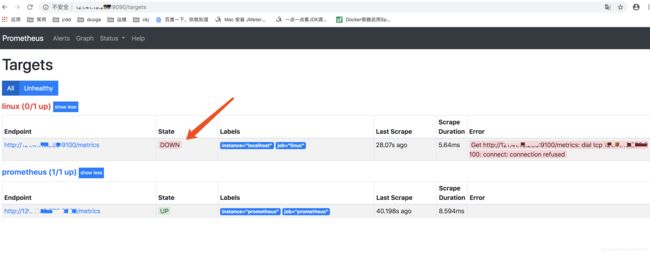

此时还未报警,状态需要持续一会,继续等待……

变成这个状态就发送了
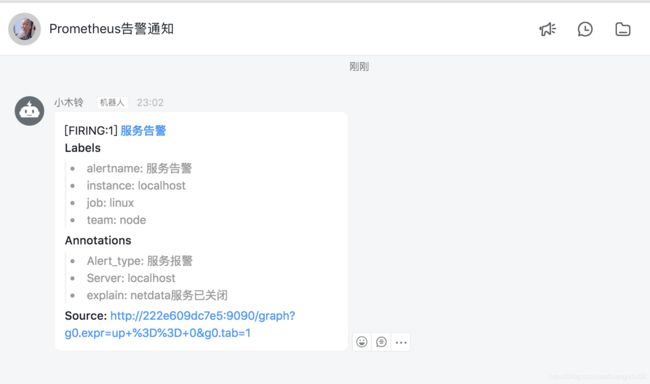
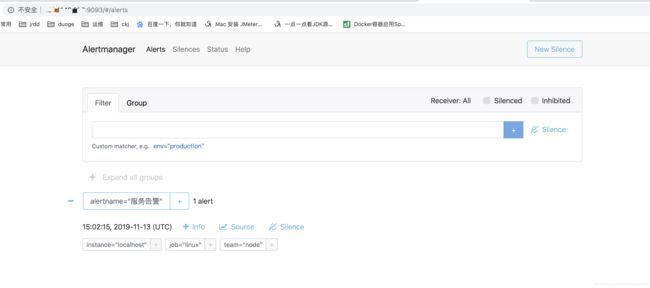
再重启export
稍等一会,告警消失


收到恢复消息,至此本文结束!
欢迎关注公众号《JAVA拾贝》
