【技术新趋势】面向图像文档的版面智能分析与理解
目录
- 一、什么是OCR?什么是版面分析理解?
- 二、文档版面分析
- 2.1、版面布局类型
- 2.2、面向文档图像版面分析的实例分割
- 2.3、逻辑结构分析
- 三、文档版面理解
- 3.1、位置嵌入
- 3.2、表格数据提取
- 四、智能文档处理技术新解决方案
人类撰写文档是为了记录和保存信息,作为信息载体,长期以来,大量信息被记录和保存在书本、报纸、期刊及特定的报表中。
然而,随着计算机技术的发展,电子格式存储方式越来越多。相对于纸质印刷文本,采用电子格式存储文本具有许多优点:如存储空间小、受存储环境影响小、易于检索和备份等。
这种转变很大程度上避免了纸质存储方式不易检索、不易保存及不便携带等缺点,并显著提高了日常工作和学习效率。因此,将纸质印刷品转换为电子文本或数字图形处理领域数字化纸张信息已成为热门研究内容之一。

在OCR系统中,纸质文档被相机拍摄成文档图像后,首先要进行版面分析、版面理解,从文字、表格、图形图像等多个维度进行解码重构,之后才能正式数字化为电子文档。
本篇文章将关注面向文档图像的版面分析与理解方向,并讨论这些任务的目前的优秀技术和方法。
一、什么是OCR?什么是版面分析理解?
OCR技术指的是光学字符识别技术,其通过对图像中字符的识别和转换为文本形式来实现文字信息处理。而版面分析则是对于整个文档或者页面进行结构化分析,以便更好地进行信息提取和利用。版面分析与理解作为构建于OCR之上的前置任务,与传统的OCR既有密不可分的联系,在表现形式和具体的方法论上又有着巨大的区别:
- 联系在于其与OCR的目标都是旨在构建一种感官到理性的空间映射,简单来说,都是在教会计算机如何“看”人类特有的知识表达方式。
- 区别在于OCR的粒度较粗,仅在于识别出单个文字的象形含义,而版面分析与识别则是建立在整篇文章或者整个段落之上的语义方面的深层表达挖掘工具。

在技术层面上来看,OCR技术能够构建从视觉感性空间(视觉效果)到理性知识空间(文字的具体表示和内在含义)特征映射关系的特性。而版面分析理解则更注重于整个文档或页面的结构和排版特征。它可以通过对整个页面进行布局分析、元素定位等方式,将不同部分所包含的内容分类并提取出来。同时还可以根据字体大小、样式等特征进行文字区块划分及分类。
在功能层面上来看,OCR技术通常作为一个辅助手段来使用,在扫描或拍摄到纸质文档后使用OCR软件进行文字转换,而文档版面分析与理解技术更关注于整体排版效果及各种元素之间的联系与相互影响,在金融、医疗、保险、能源、物流等多个行业都有不同类型的应用,不仅可以为机器获取更复杂的文章语义信息添砖铺路,还可以解放人类劳动力,使得文章的阅读过程进一步自动化和智能化,更是能够利用机器阅读的中间产物(如标注能力等)为其他的研究任务提供有力支持,进一步推动整个人工智能领域的发展。
二、文档版面分析
文档版面分析是对图片或页面扫描图像上感兴趣的区域进行定位和分类的过程,版面分析的目的是让机器“看懂”文档结构,即将文档图像分割成不同类型内容的区域,并分析区域之间的关系,这是内容识别之前的关键步骤。从广义上讲,大多数方法可以提炼为页面分割和逻辑结构分析。
- 页面分割方法侧重于外观,并使用视觉线索将页面划分为不同的区域;最常见的是文本、图形、图像和表格。
- 逻辑结构分析侧重于为这些区域提供更细粒度的语义分类,即识别作为段落的文本区域,并将其与标题或文档标题区分开来。

2.1、版面布局类型
随着信息展现形式的发展和变化,文本图像的内容从简单的文字,发展成为包含文本、表格、图形和图片等多种复杂展现形式的内容,版面的排版样式也由最初的横、纵向简单排列发展成为包括图文环绕、图表混合等多种情形的复杂样式。这些样式在改变人们阅读习惯的同时,也增加了文档图像版面分析的难度。
根据Koichi Kise在2014年提出,如下图所示,印刷文件可分为六种类型:(a)矩形,(b)曼哈顿,©非曼哈顿,(d)多柱曼哈顿,(e)水平重叠,(f)对角线重叠。

其中矩形版面指的是由水平和垂直方向的单列或多列大型矩形版面;每一栏只有一个段落。而类似的具有多个段落的文档来源可以被归类为曼哈顿布局;非曼哈顿版面则指那些具有非矩形形状区域的布局版面;多柱曼哈顿版面则指包含多个垂直或者水平柱子且依然以直角或者直线为主要元素排列而成的版本;水平重叠和对角线重叠都属于一些复杂型格式。
2.2、面向文档图像版面分析的实例分割
面向文档图像版面分析的实例分割是指在对文档图像进行版面分析时,同时进行实例级别的目标分割,它负责检测和注释文档的物理结构,将文档图像中不同语义类别的物体进行精确、有效地分割,其主要目的是将文本、图片、表格等不同类型的内容从背景中区分出来,以便更好地理解和处理这些信息。大多数在页面分割上的工作可以分为两类:自底向上和自顶向下的方法。
- 自底向上的方法首先基于局部特征(黑白像素或者连通区域)检测单词,然后顺序地将成群的单词组合成文本行和段落。然而,这种方法在连通区域的识别和组合时十分费时。
- 自顶向下的方法将一个页面迭代地分割成列、块、文本行和单词。这两种方法都很难正确的分割复杂布局的文档,例如一个有非矩形图片的文档。
一个常见的实例分割算法是Mask R-CNN,它基于深度学习技术并引入了掩码预测模块,在检测任务中可以直接输出每个物体所在位置及其对应的掩码信息。通过训练模型,我们可以获得一个能够自动识别并定位不同物体,并将它们精确提取出来的系统。
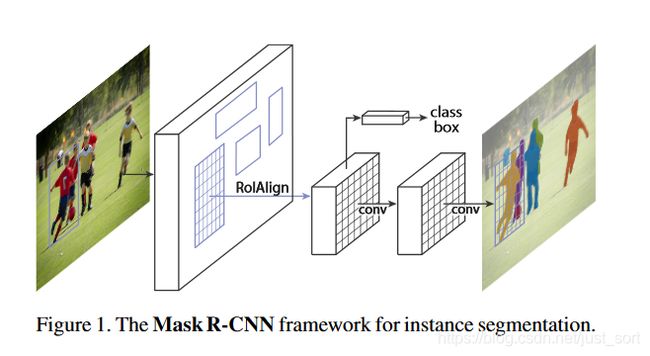
如上图所示:首先输入预处理后的原始图片,并将其送入特征提取网络中,以获得特征图。然后,在每个像素位置设定固定数量的ROI或Anchor,并将这些ROI区域送入RPN网络进行二分类(前景和背景)以及坐标回归,从而获取经过精炼处理的ROI区域。
接下来,需要对这些ROI区域执行论文提出的ROIAlign操作。该操作包括两个主要部分:首先是对应匹配原图和feature map各自在相同位置上的像素点;接着是将feature map与固定的feature进行对应。
最终,在完成前面所有步骤之后,多个经过筛选、匹配和调整过程形成的ROI区域需进行多类别分类、候选框回归并引入FCN生成Mask等措施来完成实际分割任务。
在LayoutLM中,作者描述了一种端到端神经网络,在编码器-解码器架构中同时结合文本和视觉特征,并融入无监督预训练网络,其通过多模态的方式首次将text、layout以及style信息融合在单一模型中进行联合优化与预测,用到了NLP领域中利用大规模无标签数据做模型自监督训练的pretrain范式。在推理过程中,他们的方法使用下采样池化层级联编码视觉信息,然后输入对称上采样级联进行解码。在每个级联水平上,所产生的编码也直接传递到相应的解码块中,连接向下和向上采样表示。这种架构确保了在编码和解码过程中考虑不同分辨率水平处视觉特征信息。
这种编码-解码模型结构简单,效果强大,利用大规模无标注文档数据集进行文本与版面的联合预训练,为后面该系列模型的持续改良优化提供了有力的支撑。
2.3、逻辑结构分析
针对版面分析问题,逻辑结构分析从图像的像素分布角度区分解决方案,大致可分为以下几类:
- 分类定位法:该方法主要通过判断独立像素块的分类归属来对图像中的像素块进行二分类过程。然后再通过二分类的
IOU计算确定像素块之间的联通关系,并将具有确定性关系的像素块进行融合,最终从“分->总”的角度对具体联通的像素块进行组合重建。此外,还可以根据Softmax获取组合之后像素块的分类标签信息。 - 像素级语义分割法:通过对每个像素点进行分类,并最终将所有经过聚合处理后得到所述目标物体区域(即“框”)。
- 基于内容的图像检索法:该方法主要从内容描述角度出发,利用一些描述性特征(如布局、上下文相关性等),来处理文档或者其他图片中各个区域所包含信息并进行匹配和搜索。
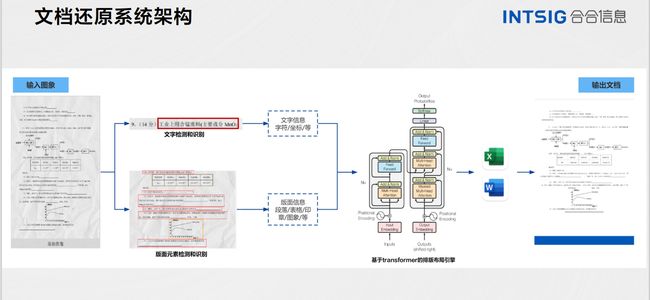
针对文档版面分析这一难题,合合信息技术人员使用基于深度学习的方法,结合文本区域的几何坐标、视觉特征、文本语义等多种模态信息对文本阅读顺序进行预测,显著提升分类结果。
三、文档版面理解

3.1、位置嵌入
二维位置嵌入是指将文本和其他元素(如图片、表格等)在文档中的位置信息转化为一个二维坐标系上的点,通过识别页面边界和页面内部元素(如标题、段落、图片等),将它们在页面上的位置信息转化为二维坐标系上的点,并根据它们之间在坐标系上的相对位置关系,理解文档元素。
目前已经有多种序列标注方法被提出,他们通过嵌入2D边界框的属性并将其与文本嵌入相结合来了解上下文和空间位置以提取信息。虽然这些策略已经取得了成功,但在仅依赖于行号或边界框坐标时可能会导致误导性结果,在不平整表面上扫描文件时可能会使曲线文本产生歧义 ,此外基于边界框的嵌入仍会错过重要视觉信息如加粗、斜体之类以及图像如商标之类. 因此需要使用Faster R-CNN模型裁剪与感兴趣令牌相对应的图像区域来创建Token图像嵌入,并将其与2D位置嵌入组合起来使用以克服这些问题。
3.2、表格数据提取
表格是各类文档中常见的对象,其结构化的组织形式方便人们进行信息理解和提取。
表格提取问题包括表格检测和表结构识别,需要将行、列和单元格信息提取为通用格式,通过对表本身的单元格进行分类来理解结构信息和内容,由于文本和视觉特征对于正确提取和理解表同样重要,因此提出了许多不同的方法来执行此任务。
传统的机器学习规则方法是基于一些启发式的规则和图像处理方法,主要利用表格线或者文本块之间的空白分隔区域来确定单元格区域,通过腐蚀、膨胀,找连通区域,检测线段、直线,求交点,合并猜测框等,一般利用典型的分类算法高斯分析判别来进行表格检测任务的流程建立。
其在高斯分析的求解框架背景下,确定两个先验假设:一方面是样本数据的分类体系分布标签服从伯努利分布;另一方面是在不同类别标签上的样本数据特征分别服从高斯多元分布。通过上述两种分布概率函数的求解,使得无参数、无训练集或是小参数、小训练集合的表格检测任务求解有可行性,从而从分布拟合角度上解决因数据量不足而造成欠拟合问题。

TUTA模型提出使用基于树的转换器进行表理解语言模型预训练的三个新目标。为预训练引入的目标旨在帮助模型在令牌、单元格和表级别上理解表。
作者根据模型要预测的表单元格屏蔽一定比例的令牌,随机屏蔽特定的单元格标题,以便模型根据其位置预测标题字符串,并为表提供上下文,例如表标题或描述,这些内容可能与模型相关联,也可能不相关联,以便模型识别哪些上下文元素与表呈正相关。根据一个单元与另一个单元的层次距离,通过限制对项目的注意连接,对变压器架构进行了修改,以减少对注意力的干扰。TUTA已经在多个数据集上展示了最先进的性能。

合合信息技术人员提出一种表格结构解析方法,在逻辑版面分析中也发挥了重要作用,主要包括自上而下的方法、自下而上的方法以及端到端图像到标记的方法等。在财报相关表格识别测试中,有线表识别单元格结构准确率高于98%;无线表识别中,在保证表格区域内容的完整性的同时,检测准确率较传统方法显著提升。
四、智能文档处理技术新解决方案
2023年度视觉与学习青年学者研讨会 (Vision And Learning SEminar, VALSE)在无锡太湖国际博览中心举行,本次论坛由中国人工智能学会、中国图象图形学学会主办,江南大学、无锡高新区管委会承办。
会议呈上了3 个大会主旨报告、4个大会特邀报告、12个年度进展报告(APR)报告、4场讲习班(Tutorial)、20场研讨会(Workshop)、186篇顶会顶刊论文墙报展示,涵盖了计算机视觉、图像处理、模式识别与机器学习领域的大部分热点研究方向,研讨了国内外前沿进展。
专注于深度学习、图文识别和人工智能的合合信息科技发展有限公司,亮相VALSE大会并在现场为我们带来了一场版面分析与理解的技术分享报告。
作为成熟的人工智能解决方案服务的提供方,合合信息研发的办公文档识别服务,支持超50种语言识别,可对办公文档的图片版面进行分析,输出图、表、列表、文本、水印、页眉页脚、印章、公式的位置及文字,并输出分版块内容的OCR识别结果。
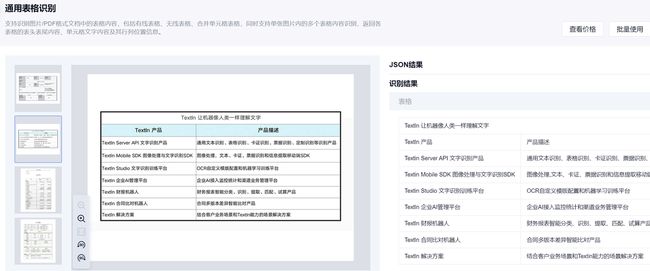
而其通用表格识别产品支持识别图片/PDF格式文档中的表格内容,包括有线表格、无线表格、合并单元格表格,同时支持单张图片内的多个表格内容识别,返回各表格的表头表尾内容、单元格文字内容及其行列位置信息。
除此之外,其基于智能文字识别技术的场景智能文字识别引擎,为行业提供场景智能文字识别服务,可广泛用于200+国内外常见卡证、票据、行业单据、定制场景等高精准度不同行业和场景,并支持安全稳定的云端服务、端侧SDK、私有化部署等多种服务形式。