python爬虫获取试题(仅提供逻辑和部分代码,不提供完整实例)
本文实现了爬取了某网站上的数学学科的试题题目,包含但不限题干,答案,解析,分析,题目难度等字段(其他学科教材等都一样)
根据爬取经验来看,单个普通账号只能爬取5页(50道题)试题,单个vip账号可爬取20页(200道)题目,超过的部分网站会提供错误的试题,第二天恢复正常。因此自行提供账号。 仅作为学习交流,禁止用于商业使用
简单实现逻辑(以数学为例)
- 账密登录
- 获得数学学科教材章节对应的key值
- 通过章节key值获取该章节所有试题列表(可设置筛选条件如单选,填空等)
- 试题列表中获取试题id
- 通过试题id进入试题详情页,即可根据需求自行爬取对应字段(数学公式的解析可以通过菁优网的页面展示规则,自定义自己的规则)
1.账密登录
在浏览器上登录菁优网,查看登录请求提交了哪些数据
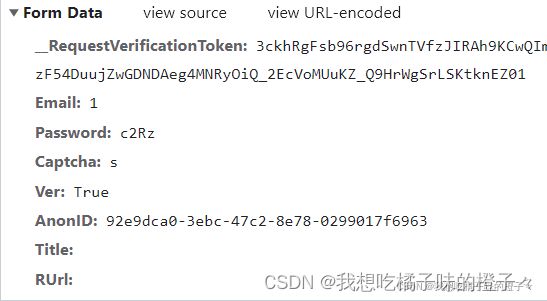
如图请求的数据包含__RequestVerificationToken,Email,Password,Captcha,Ver,AnonID,Title,RUrl
多请求几次即可发现Ver,Title,RUrl是不变的,因此我们不考虑这几个数据,只需要找到其他数据提交给登录接口即可
通过分析页面可知,AnonID,Captcha是请求loginform接口得到的,而页面上我们并不能得到loginform接口的url,但是菁优网给我们一个新的接口iframelogin,请求该接口,返回的数据就是loginform接口的url
# 请求iframelogin接口,获取到loginform接口的url
def anonid_url_get():
url_anonid = 'https://www.jyeoo.com/api/iframelogin?t=&u=&r={}'.format(random.uniform(0, 1))
url_anonid_res = session.get(url_anonid)
soup_url_anonid = BeautifulSoup(url_anonid_res.text, 'lxml')
url_id = soup_url_anonid.find(id='mf').get('src') # 获取到loginform接口的url
return url_id
然后我们请求loginform接口,即可得到相关数据
def get_anonid():
url = anonid_url_get() # loginform接口的url
res_id = session.get(url) # 请求该接口
soup1 = BeautifulSoup(res_id.text, 'lxml')
AnonID = soup1.find(name='input', attrs={'id': 'AnonID'}).get('value') # 获取Anonid
Token = soup1.find(name='input', attrs={'name': '__RequestVerificationToken'})
requestVerificationToken = Token.get('value') # 获取__RequestVerificationToken
img_url = soup1.find(id='capimg').get('src') # 获取验证码的url
return requestVerificationToken, AnonID, img_url
所有需要提交的数据获得后,即可请求登录接口
def login_request(email, password):
requestVerificationToken, anonid, img= get_anonid()
cap = get_captcha(img) # 获取验证码,该函数是接码平台
form_data = {
"__RequestVerificationToken": requestVerificationToken,
"Email": email,
"Password": password,
"Captcha": cap,
"Ver": "True",
"AnonID": anonid,
"Title": "",
"RUrl": ""
}
form_data["Password"] = base64.b64encode(form_data["Password"].encode()).decode() # 密码需要bs4转化
url = "https://www.jyeoo.com/account/loginform"
res = session.post(url, data=form_data) # 请求登录接口
soup_res = BeautifulSoup(res1.text, 'lxml')
divLEMsg = soup_res.find(id='divLEMsg').get_text()
# 登录成功divLEMsg为长度唯一的空白字符串,否则为错误信息,如验证码计算错误或账密错误
if len(divLEMsg) == 1:
divLEMsg = "登录成功"
# print(divLEMsg)
return cookie_get, divLEMsg, session # 返回登录成功后的cookie,即认证信息,供后续获取试题使用
2.获取章节
这部分比较简单,我们只需要找到获取章节的请求接口即可
def get_chapters(): # 章节获取
url_chap = 'http://www.jyeoo.com/physics2/ques/partialcategory?q=61d2b57e-7f3b-4384-bb98-4316fae290d9~88542894-5ee0-4349-8536-f9a080e2fda7~34113'
headers = {} # 浏览器上复制header即可
data = {
"a": "61d2b57e-7f3b-4384-bb98-*******",
"f": "0",
"cb": "_setQ",
"r": "0.7286671658019062"
} # 不同的数据对应不同的教材和学科,接口不变
res = requests.post(url_chap, headers=headers, data=data)
# print(res.text)
soup = BeautifulSoup(res.text, 'lxml')
chara = soup.find(id='JYE_POINT_TREE_HOLDER')
for i in chara.select('body > ul > li'):
i_nm = i.get("nm")
print(i_nm) # 大章节
for j in i.select_one('ul'):
j_nm = j.get("nm")
print(j_nm) # 中章节
for q in j.select_one('ul'):
q_nm = q.get("nm")
print(q_nm) # 小章节
qq = q.select_one('ul')
if qq: # 如果有小小章节
for x in qq:
print(x)
x_nm = x.get("nm")
x_pk = x.get("pk")
print(x_nm) # 对应各章节
print(x_pk) # 章节id值
else:
q_pk = q.get("pk") #小章节id值
print(q_pk)
3.通过章节key值获取该章节所有试题列表(可设置筛选条件如单选,填空等)
下次再写,累了