ClickHouse学习笔记(四):MergeTree 系列表引擎
文章目录
- 1、总述
- 2、MergeTree
-
- 2.1、数据TTL
- 2.1、存储策略
- 3、ReplacingMergeTree
- 4、SummingMergeTree
- 5、AggregatingMergeTree
- 5、CollapsingMergeTree
- 6、VersionedCollapsingMergeTree
1、总述
MergeTree 有两层含义:
- 一:标识合并树表引擎家族
- 二:标识合并树家族中最基础的 MergeTree 表引擎。
MergeTree 有很多变种,常用的表引擎还有 ReplacingMergeTree、SummingMergeTree、AggregatingMergeTree、CollapsingMergeTree 和 VersionedCollapsingMergeTree。每一种合并树的变种,在集成了基础 MergeTree 的能力之后又增加了独有特性。
- MergeTree 家族的继承关系示意图:
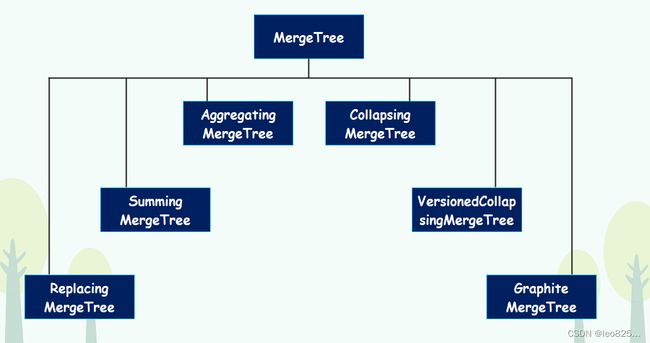
- MergeTree 各种表引擎的逻辑部分

可以看到在具体的实现部分,7 种 MergeTree 共用一个主体,而在触发 Merge 动作时,它们调用了各自独有的合并逻辑。
- 组合表引擎
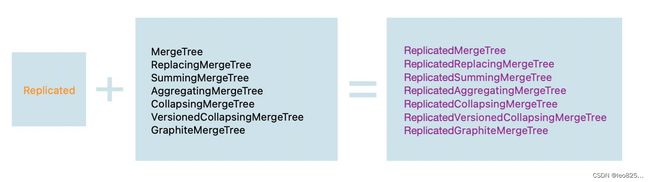
当我们为 7 种 MergeTree 加上 Replicated 前缀之后,又能组合出 7 种新的表引擎,而这些 ReplicatedMergeTree 拥有副本协同的能力。
2、MergeTree
MergeTree 作为家族系列最基础的表引擎,提供了数据分区、一级索引和二级索引等功能等。还有数据 TTL 和 存储策略。
2.1、数据TTL
TTL (Time To Live)表示数据的存活时间。
(1) 列级别 TTL
需要在定义表字段的时候,为它们声明了 TTL 表达式,主键字段不能被声明 TTL。
CREATE TABLE ttl_table_v1 (
id String,
create_time DateTime,
code String TTL create_time + INTERVAL 10 SECOND,
type UInt8 TTL create_time + INTERVAL 10 SECOND
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(create_time)
ORDER BY id
(2) 表级别 TTL
CREATE TABLE ttl_table_v2 (
id String,
create_time DateTime,
code String TTL create_time + INTERVAL 1 MINUTE,
type UInt8
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(create_time)
ORDER BY create_time
TTL create_time + INTERVAL 1 DAY
建表的时候增加表级别的 TTL ,当触发 TTL 清理时,那些满足过期时间的数据行将被整行删除。TTL 支持修改,例如:
ALTER TABLE ttl_table_v2 MODIFY TTL create_time INTERVAL + 3 DAY
表级别的 TTL 不支持取消。
2.1、存储策略
ClickHouse 19.15 版本之前,MergeTree 只支持但路径存储,所有的数据都会被写入 config.xml 配置中 path 指定的路径下,即使服务器挂载了多块磁盘,也无法有效利用这些存储空间。19.15版本之后 MergeTree 实现了自定义存储策略的功能,支持以数据分区为最小移动单位,将分区目录写入多块磁盘目录。
三大存储侧策略:
- 默认策略:MergeTree 原本的存储策略,无须任何配置,所有分区会自动保存到 config.xml 配置中 path 指定的路径下。
- JBOD 策略:这种策略适合服务器挂载了多块磁盘,但没有做 RAID 的场景。数据可靠性需要利用副本机制保障。
- HOT/COLD 策略:这种策略适合服务器挂载了不同类型磁盘的场景。HOT 区域使用 SSD 这类高性能存储媒介,注重存储性能;COLD 区域使用 HDD 这类高容量存储媒介,注重存取经济性。数据会先写入 HOT 累积到阈值之后自行移动到 COLD 区。
3、ReplacingMergeTree
MergeTree 拥有主键,但没有唯一约束,如果不希望数据表中有重复数据的场景可以使用 ReplacingMergeTree ,它可以在合并分区时删除重复的数据。
语法规则:
ENGINE = ReplacingMergeTree(ver)
里面的参数 ver 是选填的,最常见的是使用 create_time 作为版本号,合并数据的时候取最新的时间去重。
创建一个数据表:
CREATE TABLE replace_table (
id String,
code String,
create_time DateTime
) ENGINE = ReplacingMergeTree()
PARTITION BY toYYYYMM(create_time)
ORDER BY (id, code)
PRIMARY KEY id
这里的 ORDER BY 是去除重复数据的关键,不是 PRIMARY KEY,ORDERR BY 声明的表达式是后续判断数据是否重复的依据。
触发所有分区合并:
optimize TABLE table_name FINAL
处理逻辑小结:
(1) 使用 ORDER BY 排序键作为判断数据重复的唯一键;
(2) 当导入同一分区目录时,会直接进行去重;
(3) 当导入不同分区目录时,不会进行去重,只有当分区目录合并时,属于同一分区内的重复数据才会去重;但是不同分区内的重复数据不会被删除;
(4) 在进行数据去重时,因为分区内的数据已经是基于 ORDER BY 排好序的,所以能很容易地找到那些相邻的重复的数据;
(5) 数据去重策略有两种:如果没有设置 ver 版本号,则保留同一组重复数据中的最后一条;如果设置了 ver 版本号,则保留同一组重复数据中 ver 字段取值最大的那一行。
4、SummingMergeTree
SummingMergeTree 能够在合并分区的时候按照预先定义的条件聚合汇总数据,将同一分组下的多行数据汇合并成一行,这样既减少了数据行,又降低了后续汇总查询的开销。主要使用的场景是用户只关心汇总结果,不关心明细数据,并且数据汇总条件是预先明确的场景(GROUP BY 条件明确,且不会随意改变)。
语法规则
ENGINE = SummingMergeTree((col1, col2, col3, ...))
其中 col1、col2 为 columns 参数值,这是一个选填参数,用于设置除主键外的其它数值类型字段,以指定被 SUM 汇总的列字段。如果不填写此参数,则会将所有非主键的数值类型字段进行汇总,下面就来创建一张 SummingMergeTree 表:
CREATE TABLE summing_table (
id String,
city String,
v1 UInt32,
v2 Float64,
create_time DateTime
) ENGINE = SummingMergeTree()
PARTITION BY toYYYYMM(create_time)
PRIMARY KEY id
ORDER BY (id, city)
如果导入同一分区目录的数据有重复的,那么直接就聚合了,不同分区目录则不会聚合,而是在合并生成新分区目录的时候,再对属于同一分区的多个分区目录里的数据进行聚合。另外 SummingMergeTree 也支持嵌套类型的字段,在使用嵌套类型字段时,需要被 SUM 汇总的字段必须以以 Map 后缀结尾。
处理逻辑小结:
(1)只有 ORDER BY 排序键作为聚合数据的条件 Key
(2)写入同一分区目录的数据会聚合之后在写入,而属于同一分区的不同分区目录的数据,则会在合并触发时进行汇总
(3)不同分区的数据不会汇总到一起
(4)如果在定义引擎时指定了 columns 汇总列(非主键的数值类型字段),则 SUM 会汇总这些列字段;如果未指定,则聚合所有非主键的数值类型字段
(5)在进行数据汇总时,因为分区内的数据已经基于 ORDER BY 进行排序,所以很容易找到相邻也拥有相同 Key 的数据
(6)在汇总数据时,同一分区内相同聚合 key 的多行数据会合并成一行,其中汇总字段会进行 SUM 计算;对于那些非汇总字段,则会使用第一行数据的取值
(7)支持嵌套结构,但列字段名称必须以 Map 后缀结尾,并且默认以第一个字段作为聚合 Key。并且除了第一个字段以外,任何名称以 key、Id 或者 Type 为后缀结尾的字段都会和第一个字段组成复合 Key
5、AggregatingMergeTree
AggregatingMergeTree 是 SummingMergeTree 升级版,有些数据立方体的意思,核心思想是以空间换时间的方法提升查询性能。首先,它能够在合并分区的时候按照预先定义的条件聚合数据。同时,根据预先定义的聚合函数计算数据并通过二进制的格式存入表内。通过将同一分组下的多行数据预先聚合成一行,既减少了数据行,又降低了后续聚合查询的开销。
语法规则:
ENGINE = AggregatingMergeTree()
AggregatingMergeTree 没有任何额外的设置参数,在分区合并时,在每个数据分区内,会按照 ORDER BY 聚合。经常结合物化视图方式实现,首先创建底表:
CREATE TABLE agg_table_basic (
id String,
city String,
code String,
value UInt32
) ENGINE = MergeTree()
PARTITION BY city
ORDER BY (id, city)
通常使用 MergeTree 作为底表,用于存储全量的明细数据,并以此对外提供实时查询。接着,创建一张物化视图:
CREATE MATERIALIZED VIEW agg_view
ENGINE = AggregatingMergeTree()
PARTITION BY city
ORDER BY (id, city)
AS SELECT
id, city,
uniqState(code) AS code,
sumState(value) AS value
FROM agg_table_basic
GROUP BY id, city
物化视图使用 AggregatingMergeTree 表引擎,用于特定场景的数据查询,相比 MergeTree,它拥有更高的性能。数据会自动同步到物化视图,并按照 AggregatingMergeTree 的引擎的规则进行处理,查询只对 agg_view 查询即可。
5、CollapsingMergeTree
CollapsingMergeTree(折叠合并树) 就是一种通过以增代删的思路,支持行级数据修改和删除的表引擎。它通过定义一个 sign 标记位字段,记录数据行的状态。如果 sign 标记为 1,则表示这是一行有效数据;如果 sign 标记为 -1,则表示这行数据要被删除。当 CollapsingMergeTree 分区合并时,同一数据分区内,sign 标记为 1 和 -1 的一组数据(ORDER BY 字段对应的值相同)会被抵消删除。
语法规则
ENGINE = CollapsingMergeTree(sign)
sign 用于指定一个 Int8 类型的标志位字段,一个完整的 CollapsingMergeTree 数据表声明如下:
CREATE TABLE collapse_table (
id String,
code Int32,
create_time DateTime,
sign Int8
) ENGINE = CollapsingMergeTree(sign)
PARTITION BY toYYYYMM(create_time)
ORDER BY id
CollapsingMergeTree 在折叠数据时遵循如下规则:
(1)如果 sign = 1 比 sign = -1 的数据多一行,则保留最后一行 sign = 1 的数据
(2)如果 sign = -1 比 sign = 1 的数据多一行,则保留第一行 sign = -1 的数据
(3)如果 sign = 1 和 sign = -1 的数据行一样多,并且最后一行是 sign = 1,则保留第一行 sign = -1 和最后一行 sign = 1 的数据
(4)如果 sign = 1 和 sign = -1 的数据行一行多,并且最后一行是 sign = -1,则什么也不保留
(5)其余情况,ClickHouse 会打印告警日志,但不会报错,在这种情形下打印结果不可预知
当然折叠数据并不是实时触发的,和所有的其它 MergeTree 变种表引擎一样,这项特性只有在多个分区目录合并的时候才会触发,触发时属于同一分区的数据会进行折叠。而在分区合并之前,用户还是可以看到旧数据的,就像上面演示的那样。
如果不想看到旧数据,那么可以在聚合的时候可以改变一下策略:
-- 原始 SQL 语句
SELECT id, sum(code), count(code), avg(code), uniq(code)
FROM collapse_table GROUP BY id
-- 改成如下
SELECT id, sum(code * sign), count(code * sign), avg(code * sign), uniq(code * sign)
FROM collapse_table GROUP BY id HAVING sum(sign) > 0
或者在查询数据之前使用 optimize TABLE table_name FINAL 命令强制分区合并,但是这种方法效率极低,在实际生产环境中慎用。
注意:
CollapsingMergeTree 的处理机制所要求 sign = 1 和 sign = -1 的数据相邻,而分区内的数据严格按照
ORDER BY 排序,要实现 sign = 1 和 sign = -1 的数据相邻,则只能严格按照顺序写入。
如果数据的写入顺序是单线程执行的,则能够比较好的控制写入顺序;但如果需要处理的数据量很大,数据的写入程序通常是多线程的,那么此时就不能保障数据的写入顺序了。而在这种情况下,CollapsingMergeTree 的工作机制就会出现问题
6、VersionedCollapsingMergeTree
VersionedCollapsingMergeTree 表引擎的作用和 CollapsingMergeTree 完全相同,它们的不同之处在于 VersionedCollapsingMergeTree 对数据的写入顺序没有要求,在同一个分区内,任意顺序的数据都可以完成折叠操作。那么 VersionedCollapsingMergeTree 是如何做到这一点的呢?其实从它的名字就能看出来,因为相比 CollapsingMergeTree 多了一个 Versioned,那么显然就是通过版本号(version)解决的。
在定义 VersionedCollapsingMergeTree 数据表的时候,除了指定 sign 标记字段之外,还需要额外指定一个 UInt8 类型的 ver 版本号字段。
ENGINE = VersionedCollapsingMergeTree(sign, ver)
一个完整的 VersionedCollapsingMergeTree 表定义如下:
CREATE TABLE ver_collapse_table (
id String,
code Int32,
create_time DateTime,
sign Int8,
ver UInt8
) ENGINE = CollapsingMergeTree(sign, ver)
PARTITION BY toYYYYMM(create_time)
ORDER BY id
提问:VersionedCollapsingMergeTree 是如何使用版本号字段的呢?
答:在定义 ver 字段之后,VersionedCollapsingMergeTree 会自动将 ver 作为排序条件并增加到 ORDER BY 的末端。以上面的 ver_collapse_table 为例,在每个分区内,数据会按照 ORDER BY id, ver DESC 排序。所以,无论写入时数据的顺序如何,在折叠处理时,都能回到正确的顺序。