Day64_Kafka(二)
第二讲 Kafka架构
| 课程大纲 |
课程内容 |
学习效果 |
掌握目标 |
| Kafka架构 |
Kafka就 |
掌握 |
|
| Kafka ack |
|||
| Exactly once |
|||
| Kafka log |
Kafka log |
掌握 |
|
| Kafka log合并 |
|||
| Flume消息flush和Retention |
|||
| Kafka Leader Election |
Kafka Leader Election |
掌握 |
|
| Kafka高性能之道 |
高性能原因 |
掌握 |
|
| 性能影响因子 |
一、Kafka架构
(一)、Kafka架构
通常,一个典型的Kafka集群中包含若干Producer,若干broker(Kafka支持水平扩展,一般broker数量越多,集群吞吐率越高),若干Consumer Group,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息,如下图2-1所示。

(二)、Kafka分布式模型
kafka分布式主要是指分区被分布在多台server(broker)上,同时每个分区都有leader和follower(不是必须),即老大和小弟的角色,这儿是老大负责处理,小弟负责同步,小弟可以变成老大,形成分布式模型。
kafka的分区日志(message)被分布在kafka集群的服务器上,每一个服务器处理数据和共享分区请求。每一个分区是被复制到一系列配置好的服务器上来进行容错。
每个分区有一个server节点来作为leader和零个或者多个server节点来作为followers。leader处理指定分区的所有读写请求,同时follower被动复制leader。如果leader失败,follwers中的一个将会自动地变成一个新的leader。每一个服务器都能作为分区的一个leader和作为其它分区的follower,因此kafka集群能被很好地平衡。kafka集群是一个去中心化的集群。如上信息参考官网:Apache Kafka。
kafka消费的并行度就是kaka topic分区的个数,或者分区的个数决定了同一时间同一消费者组内最多可以有多少个消费者消费数据。
如下图2-2所示。

在kafka集群中,分单个broker和多个broker。每个broker中有多个topic,topic数量可以自己设定。在每个topic中又有1到多个partition,每个partition为一个分区。kafka分区命名规则为topic的名称+有序序号,这个序号从0开始依次增加。
每个partition中有多个segment file。创建分区时,默认会生成一个segment file,kafka默认每个segment file的大小是1G。当生产者往partition中存储数据时,内存中存不下了,就会往segment file里面刷新。在存储数据时,会先生成一个segment file,当这个segment file到1G之后,再生成第二个segment file 以此类推。每个segment file对应两个文件,分别是以.log结尾的数据文件和以.index结尾的索引文件。在服务器上,每个partition是一个目录,每个segment是分区目录下的一个文件。
每个segment file也有自己的命名规则,每个名字有20个字符,不够用0填充。每个名字从0开始命名,下一个segment file文件的名字就是,当前segment file中.log文件中第一条数据的offset。
在.index文件中,存储的是key-value格式的,key代表在.log中按顺序开始第n条消息,value代表该消息的位置偏移。但是在.index中不是对每条消息都做记录,它是每隔一些消息记录一次,避免占用太多内存。即使消息不在index记录中,在已有的记录中查找,范围也大大缩小了。
.index中存放的消息索引是一个稀疏索引列表。
(四)、topic中的partition
1、为什么要分区
可以想象,如果一个topic就一个分区,要是这个分区有1T数据,那么kafka就想把大文件划分到更多的目录来管理,这就是kafka所谓的分区。
2、分区的好处
- 方便在集群中扩展。因为一个topic由一个或者多个partition构成,而每个节点中通常可以存储多个partition,这样就方便分区存储与移动,也就增加其扩展性。同时也可以增加其topic的数据量。
- 可以提高并发。因为一个主题多个partition,而每个主题读写数据时,其实就是读写不同的partition,所以增加其并发。
3、单节点partition的存储分布
Kafka集群只有一个broker,默认/var/log/kafka-log为数据文件存储根目录,在Kafka broker中server.properties文件配置(参数log.dirs=/home/offcn/data/kafka),例如创建2个topic名称分别为test-1、test-2, partitions数量都为partitions=4
存储路径和目录规则为:
|--test-1-0
|--test-1-1
|--test-1-2
|--test-1-3
|--test-2-0
|--test-2-1
|--test-2-2
|--test-2-3
在Kafka文件存储中,同一个topic下有多个不同partition,每个partition为一个目录,partiton命名规则为:topic名称+分区编号(有序),第一个partiton序号从0开始,序号最大值为partitions数量减1。
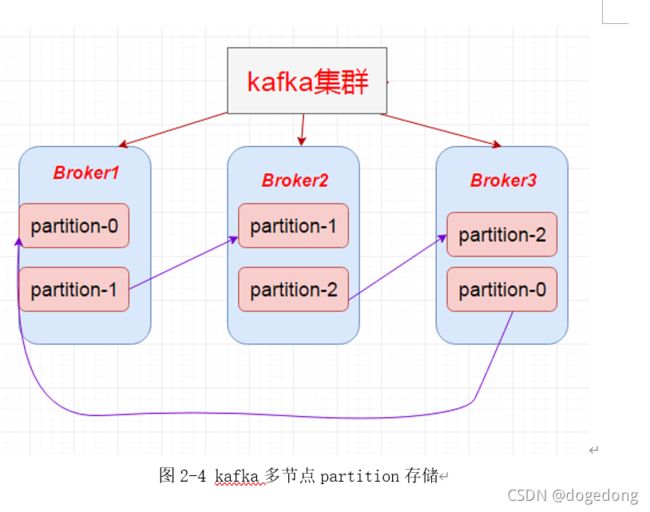
4、多节点partition存储分布
Kafka多节点partition存储分布如下图2-4所示。
5、分区分配策略
- 将所有broker(n个)和partition排序
- 将第i个Partition分配到第(i mode n)个broker上
分区策略举例
test3的topic,4个分区,2个副本。
kafka-topics.sh --describe --zookeeper bd-offcn-01:2181/kafka --topic test3
Topic:test3 PartitionCount:4 ReplicationFactor:2 Configs:
Topic: test3 Partition: 0 Leader: 1 Replicas: 1,3 Isr: 1,3
Topic: test3 Partition: 1 Leader: 2 Replicas: 2,1 Isr: 1,2
Topic: test3 Partition: 2 Leader: 3 Replicas: 3,2 Isr: 2,3
Topic: test3 Partition: 3 Leader: 1 Replicas: 1,2 Isr: 1,2
第1个Partition分配到第(1 mode 3)= 1个broker上
第2个Partition分配到第(2 mode 3)= 2个broker上
第3个Partition分配到第(3 mode 3)= 3个broker上。
第4个Partition分配到第(4 mode 3)= 1个broker上
6、副本分配策略
- 在Kafka集群中,每个Broker都有均等分配Partition的Leader机会。
- 上述图2-4 Broker Partition中,箭头指向为副本。
- 上述图2-4 中每个Broker(按照BrokerId有序)依次分配主Partition,下一个Broker为副本,如此循环迭代分配,多副本都遵循此规则。
副本分配算法:
- 将所有N Broker和待分配的i个Partition排序。
- 将第i个Partition分配到第(i mod n)个Broker上。
- 将第i个Partition的第j个副本分配到第((i + j) mod n)个Broker上。
- 同时也要兼顾复杂均衡,尽量在所有的节点里面都保存相同多的分区及其副本。
分区及副本分配举例
kafka-topics.sh --describe --zookeeper node01:2181/kafka --topic test1 Topic:test1 PartitionCount:3 ReplicationFactor:2 Configs:
Topic: test1 Partition: 0 Leader: 3 Replicas: 3,1 Isr: 3,1
Topic: test1 Partition: 1 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: test1 Partition: 2 Leader: 2 Replicas: 2,3 Isr: 2,3
第0个paritition分配到第(0%3)个broker上,即分配到第1个broker上。0分区的第1个副本在((0+1)%3)=1个broker
第1个paritition分配到第(1%3)个broker上,即分配到第2个broker上。
第2个paritition分配到第(2%3)个broker上,即分配到第3个broker上。
7、数据分配策略
前面已经讲过了。
- 如果指定了partition,进入该partition
- 如果没有指定该partition,但是指定key,通过key的字节数组信息的hashcode值和partition数求模确定partition
- 如果都没有指定,通过轮询方式进入对应的partition。
(五)、partition中文件存储
如下图2-5是一个partition-0的一个存储示意图。

- 每个分区一个目录,该目录中是一堆segment file(默认一个segment是1G),该目录和file都是物理存储于磁盘。
- 每个partion(目录)相当于一个巨型文件被平均分配到多个大小相等segment(段)数据文件中。但每个段segment file消息数量不一定相等,这种特性方便old segment file快速被删除。
- 每个partiton只需要支持顺序读写就行了,segment文件生命周期由服务端配置参数决定。
- 这样做的好处就是能快速删除无用文件,有效提高磁盘利用率。
(六)、kafka分区中的segemnt
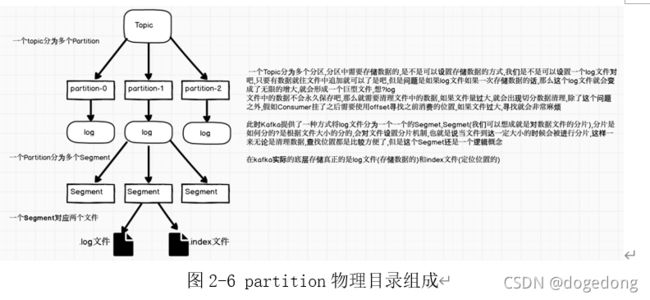
通过上一节我们知道Kafka文件系统是以partition方式存储,下面深入分析partitiion中segment file组成和物理结构,如图2-6和2-7。
索引文件与数据文件的关系
既然它们是一一对应成对出现,必然有关系。索引文件中元数据指向对应数据文件中message的物理偏移地址
比如索引文件中3,497代表:数据文件中的第三个message,它的偏移地址为497。再来看数据文件中,Message 368772表示:在全局partiton中是第368772个message。
注:segment index file采取稀疏索引存储方式,它减少索引文件大小,通过mmap可以直接内存操作,稀疏索引为数据文件的每个对应message设置一个元数据指针,它比稠密索引节省了更多的存储空间,但查找起来更耗时.

通过上面两张图,我们已经知道topic、partition、segment、.log、.index等文件的关系,下面深入看看segment相关组成原理。
segment file组成:
由2大部分组成,分别为index file和log file(即数据文件),这2个文件一一对应,成对出现,后缀".index"和“.log”分别表示为segment索引文件、数据文件。
segment文件命名规则:
partition全局的第一个segment从0开始,后续每个segment文件名为当前segment文件第一条消息的offset值数值最大为64位long大小,20位数字字符长度,不够的左边用0填充
查看segment文件内容
查看.log
${KAFKA_HOME}/bin/kafka-run-class.sh kafka.tools.DumpLogSegments \结果:
Starting offset: 0
offset: 0 position: 0 CreateTime: 1577994283622 isvalid: true keysize: -1 valuesize: 1 magic: 2 compresscodec: NONE producerId: -1 producerEpoch: -1 sequence: -1 isTransactional: false headerKeys: [] payload: a
offset: 1 position: 69 CreateTime: 1577994466159 isvalid: true keysize: -1 valuesize: 1 magic: 2 compresscodec: NONE producerId: -1 producerEpoch: -1 sequence: -1 isTransactional: false headerKeys: [] payload: 1
offset: 2 position: 138 CreateTime: 1577994474463 isvalid: true keysize: -1 valuesize: 1 magic: 2 compresscodec: NONE producerId: -1 producerEpoch: -1 sequence: -1 isTransactional: false headerKeys: [] payload: 4
查看.index
${KAFKA_HOME}/bin/kafka-run-class.sh kafka.tools.DumpLogSegments \结果:
Dumping 00000000000000000000.index
offset: 0 position: 0
segment文件的物理结构:
如下图2-8,索引文件存储大量元数据,数据文件存储大量消息,索引文件中元数据指向对应数据文件中message的物理偏移地址。

举例:上述索引文件中元数据6-->266为例,依次在数据文件中表示第6个message(在全局partiton表示第23066个message)、以及该消息的物理偏移地址为266。
segment物理组成及其具体参数详解
一个segment data file由许多message组成,一个message物理结构具体如下图2-9:

参数解释
| 关键字 |
解释说明 |
| 8 byte offset |
在parition(分区)内的每条消息都有一个有序的id号,这个id号被称为偏移(offset),它可以唯一确定每条消息在parition(分区)内的位置。即offset表示partiion的第多少message |
| 4 byte message size |
message大小 |
| 4 byte CRC32 |
用crc32校验message |
| 1 byte “magic" |
表示本次发布Kafka服务程序协议版本号 |
| 1 byte “attributes" |
表示为独立版本、或标识压缩类型、或编码类型。 |
| 4 byte key length |
表示key的长度,当key为-1时,K byte key字段不填 |
| K byte key |
可选 |
| value bytes payload |
表示实际消息数据。 |
(七)、Kafka中的push和pull
一个较早问题是我们应该考虑是消费者从broker中pull数据还是broker将数据push给消费者。kakfa遵守传统设计和借鉴很多消息系统,这儿kafka选择producer向broker去push消息,并由consumer从broker pull消息。一些logging-centric system,比如Facebook的Scribe和Cloudera的Flume,采用非常不同的push模式。事实上,push模式和pull模式各有优劣。
push模式很难适应消费速率不同的消费者,因为消息发送速率是由broker决定的。push模式的目标是尽可能以最快速度传递消息,但是这样很容易造成consumer来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而pull模式则可以根据consumer的消费能力以适当的速率消费消息。
pull模式不足之处是,如果kafka没有数据,消费者可能会陷入循环中,一直返回空数据。针对这一点,Kafka的消费者在消费数据时会传入一个时长参数timeout,如果当前没有数据可供消费,consumer会等待一段时间之后再返回,这段时长即为timeout。
(八)、kafka中数据发送保障
为保证producer发送的数据,能可靠的发送到指定的topic,topic的每个partition收到producer发送的数据后,都需要向producer发送ack(acknowledgement确认收到),如果producer收到ack,就会进行下一轮的发送,否则重新发送数据,如下图2-10所示。

副本数据同步策略
| 方案 |
优点 |
缺点 |
| 半数以上完成同步,就发送ack |
延迟低 |
选举新的leader时,容忍n台节点的故障,需要2n+1个副本 |
| 全部完成同步,才发送ack |
选举新的leader时,容忍n台节点的故障,需要n+1个副本 |
延迟高 |
Kafka选择了第二种方案,原因如下:
- 同样为了容忍n台节点的故障,第一种方案需要2n+1个副本,而第二种方案只需要n+1个副本,而Kafka的每个分区都有大量的数据,第一种方案会造成大量数据的冗余。
- 虽然第二种方案的网络延迟会比较高,但网络延迟对Kafka的影响较小。
- ISR
采用第二种方案之后,设想以下情景:leader收到数据,所有follower都开始同步数据,但有一个follower,因为某种故障,迟迟不能与leader进行同步,那leader就要一直等下去,直到它完成同步,才能发送ack。这个问题怎么解决呢?
Leader维护了一个动态的in-sync replica set (ISR),意为和leader保持同步的follower集合。当ISR中的follower完成数据的同步之后,leader就会给follower发送ack。如果follower长时间未向leader同步数据,则该follower将被踢出ISR,该时间阈值由replica.lag.time.max.ms参数设定。Leader发生故障之后,就会从ISR中选举新的leader。
需要注意的是:
- 生产者发送到特定主题分区的消息是将按照发送的顺序来追加。也就是说,如果消息M1和消息M2由相同的生产者发送,并且M1是先发送的,那么M1的偏移量将比M2低,并出现在日志的前面。
- 消费者是按照存储在日志中记录顺序来查询消息。
- 对于具有n个副本的主题,我们将容忍最多N-1个服务器失败故障,从而不会丢失提交到日志的任何消息记录。
(九)、ack应答机制
对于某些不太重要的数据,对数据的可靠性要求不是很高,能够容忍数据的少量丢失,所以没必要等ISR中的follower全部接收成功。
所以Kafka为用户提供了三种可靠性级别,用户根据对可靠性和延迟的要求进行权衡,选择以下的配置,如图2-11所示。

故障处理细节
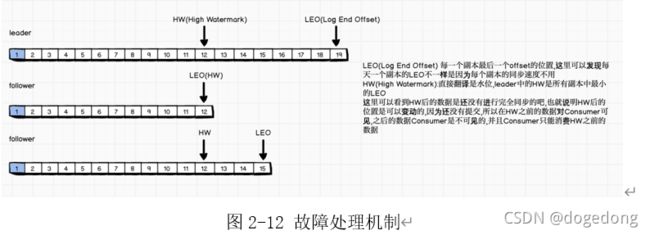
故障机制分为了follower和leader故障,如上图2-12所示的,具体解释如下:
follower故障
follower发生故障后会被临时踢出ISR,待该follower恢复后,follower会读取本地磁盘记录的上次的HW,并将log文件高于HW的部分截取掉,从HW开始向leader进行同步。
等该**follower的LEO大于等于该Partition的HW**,即follower追上leader之后,就可以重新加入ISR了。
leader故障
leader发生故障之后,会从ISR中选出一个新的leader,之后,为保证多个副本之间的数据一致性,其余的follower会先将各自的log文件高于HW的部分截掉,然后从新的leader同步数据。
注意:这只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复。
二、Kafka log
(一)、Kafka log
1、kafka log的写
日志允许序列追加,总是追加到最后一个文件。当该文件达到可配置的大小(比如1GB)时,就会将其刷新到一个新文件。日志采用两个配置参数:M和S,前者给出在强制将文件刷新到磁盘之前要写入的消息数量(条数),后者给出多少秒之后被强制刷新。这提供了一个持久性保证,在系统崩溃的情况下最多丢失M条消息或S秒的数据。
2、kafka log的读
- 读取的实际过程是:首先根据offset去定位数据文件中的log segment文件,然后从全局的offset值中计算指定文件offset,然后从指定文件offset读取消息。查找使用的是二分查找(基于快排队segment文件名进行排序),每一个文件的范围都被维护到内存中。
- 读取是通过提供消息的64位逻辑偏移量(8字节的offset)和s字节的最大块大小来完成。
- 读取将返回一个迭代器包含有s字节的缓冲区,缓冲区中含有消息。S字节应该比任何单个消息都大,但是在出现异常大的消息时,可以多次重试读取,每次都将缓冲区大小加倍,直到成功读取消息为止。
- 可以指定最大的消息和缓冲区大小,以使服务器拒绝的消息大于某个大小,并为客户机提供其获得完整消息所需的最大读取量。
3、kafka log的删除
- 删除log segment即数据被删除。
- 日志管理器允许可插拔删除策略去选择那些最符合删除的文件来删除。
- 当前删除策略是修改时间超过N天以前的数据,但保留最近N GB的策略也很有用。
4、Kafka log的保障
- 日志提供了一个配置参数M,该参数控制在强制刷新磁盘之前写入的消息的最大数量(M条)。
- 启动日志恢复去处理最近消息在总消息中是否有效,使用crc32来校验,如果消息长度和offset总和小于文件长度且crc32和存储的消息能匹配上,则表示有效。
- 请注意:必须处理两种类型的损坏:中断(由于崩溃而丢失未写的块)和损坏(向文件添加无意义块)。
(二)、Kafka log compaction
1、log compaction简介
Kafka中的Log Compaction是指在默认的日志删除(Log Deletion)规则之外提供的一种清理过时数据的方式。如下图所示,Log Compaction对于有相同key的的不同value值,只保留最后一个版本。如果应用只关心key对应的最新value值,可以开启Kafka的日志清理功能,Kafka会定期将相同key的消息进行合并,只保留最新的value值。
log压缩的逻辑结构如图2-13所示:

Log Head: 日志记录的头部,97代表是刚写的一条日志记录。
Log Tail: 日志记录的尾部
压缩日志前后
日志压缩主要是后台独立线程去定期清理log segment,将相同的key的值保留一个最新版本,压缩将不会堵塞读,并且可以进行节流,最多使用可配置的I/O吞吐量,以避免影响生产者和消费者,压缩向如下图2-14一样。

2、log compaction保障
日志压缩保障如下:
- 被写在日志头部的任何一条消息对于任何一个消费者都能获取。这些消息都有一个连续的offset。主题的min.compaction.log.ms是消息被写进来后,日志压缩的最小时间。比如,消息被写进来后,时长小于该属性的值,那么该日志不会被压缩。
- 消息总是被维持有序,压缩将绝不会对消息进行重排序,仅仅是移除。
- 消息的offset将绝不会被改变,这个在日志中是一个永久的标识。
- 消费者能够看到日志头部的所有记录的最终状态,另外,所有被删除记录的删除标记都会被看见,前提是,被提供给消费者的记录是小于主题delete.retention.ms设置的时长的所有删除标记才能被看见(默认是24小时)。换句话说:由于删除标记的删除与读取同时进行,因此,如果删除标记的延迟超过了delete.retention.ms,消费者就有可能遗漏删除标记。
3、log compaction流程
日志cleaner(清理器)处理日志压缩,它是一个后台线程池,用于重新复制segment文件,删除其键出现在日志头部的记录。每个压缩线程的工作流程如下:
- 它选择具有极高比例从日志头到日志尾的日志。
- 为日志头的每一个key创建一个偏移量汇总。
- 重新负责从头到尾记录日志,删除日志中靠后出现的键。新的、干净的segment会立即交换到日志中,因此所需的额外磁盘空间只是一个额外的segment(而不是日志的完整副本)。
- 头部日志的汇总实质上只是一个空间紧凑的哈希表。它每个日志准确地使用24个字节。因此,若使用8GB的cleaner缓冲区,大约可以清理366 GB的头部日志(假设1k一条消息)。
4、log 的清空器
日志清理器默认是开启的。这将开启一个清理器线程池。对于特定主体开启各日志清理,你能添加指定的属性,该属性当主题被创建或者是主题被修改的时候所使用。具体属性如下:
log.cleanup.policy=compact
日志清理器能配置头部日志不被压缩的最小时间。这可以通过配置compaction time log来开启,具体属性如下:
log.cleaner.min.compaction.log.ms
这个可以用于阻止新消息被更早的压缩,如果不设置,所有的log segment将都会被压缩,除最后一个log segment外。
如果一个segment正在被写,那么该激活的segment将不被压缩尽管它的所有消息时长都超过被压缩的最小时间(避免线程安全问题)。
(三)、Kafka msg flush and retention
1、Flush策略
############### Log Flush Policy #####################
# Messages are immediately written to the filesystem but by default we only fsync() to sync
# the OS cache lazily. The following configurations control the flush of data to disk.
# There are a few important trade-offs here:
# 1. Durability: Unflushed data may be lost if you are not using replication.
# 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush.
# 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to excessive seeks.
# The settings below allow one to configure the flush policy to flush data after a period of time or
# every N messages (or both). This can be done globally and overridden on a per-topic basis.
# The number of messages to accept before forcing a flush of data to disk
## 每当每一个topic接收到10000条message的时候,就会将数据flush到磁盘
log.flush.interval.messages=10000
# The maximum amount of time a message can sit in a log before we force a flush
#每隔1s flush一次数据
log.flush.interval.ms=1000为了提供kafka的读写数据能力,首先接收数据到kafka内存,不可能无限制的保存在内存,所以必然会将数据flush到磁盘(partition的segement)文件,在flush的时候做了Durability(持久性)和Latency(延迟)和Throughput(吞吐量)的权衡与取舍。
2、Retention策略
############################# Log Retention Policy #############################
# The following configurations control the disposal of log segments. The policy can
# be set to delete segments after a period of time, or after a given size has accumulated.
# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
# from the end of the log.
# The minimum age of a log file to be eligible for deletion due to age
# 日志最小的保留时间:7天,超过这个时间,数据可能会被清理掉
log.retention.hours=168
#log.retention.days=7
# A size-based retention policy for logs. Segments are pruned(裁剪) from the log unless the remaining
# segments drop below log.retention.bytes. Functions independently of log.retention.hours.
## segement文件如果超过log.retention.bytes的配置,将会可能被裁剪,直到小于log.retention.bytes配置
#log.retention.bytes=1073741824
# The maximum size of a log segment file. When this size is reached a new log segment will be created.
# 一个segment文件最大的大小,超过log.segment.bytes一个G,将会创建一个新的segment文件
log.segment.bytes=1073741824
# The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
## 每隔5分钟,检测一次retention策略是否达到
log.retention.check.interval.ms=300000partition对应的文件,就保存在一个个的segment文件中,每一个文件默认大小是1G,但是log.retention.check.interval.ms监测频率是5分钟一次,
所以segment文件可能会超过1G,此时就会启动retion策略,将文件裁剪到log.retention.bytes配置,如果超过了log.segment.bytes=1G配置,将会创建一个新的segment文件;默认情况,segment文件会保留7天。
三、Kafka高性能之道
(一)Zookeeper在Kafka中的作用
Kafka集群中有一个broker会被选举为Controller,负责管理集群broker的上下线,所有topic的分区副本分配和leader选举等工作。
Controller的管理工作都是依赖于Zookeeper的。
以下为partition和Controller的leader选举过程如下图2-15所示:

只有KafkaController Leader会向zookeeper上注册Watcher,其他broker几乎不用监听zookeeper的状态变化。
Kafka集群中多个broker,有一个会被选举为controller leader(谁先到就是谁),负责管理整个集群中分区和副本的状态,比如partition的leader 副本故障,由controller 负责为该partition重新选举新的leader 副本;当检测到ISR列表发生变化,有controller通知集群中所有broker更新其MetadataCache信息;或者增加某个topic分区的时候也会由controller管理分区的重新分配工作。
当broker启动的时候,都会创建KafkaController对象,但是集群中只能有一个leader对外提供服务,这样每个节点上的KafkaController会在指定的zookeeper路径下创建临时节点,只有第一个成功创建的节点的KafkaController才可以成为leader,其余的都是follower。当leader故障后,所有的follower会收到通知,再次竞争在该路径下创建节点从而选举新的leader。
(二)Kafka高性能原因
1、高效使用磁盘
- 顺序写磁盘,顺序写磁盘性能高于随机写内存
- Append Only 数据不更新,无记录级的数据删除(只会整个segment删除)
- 读操作可直接在page cache内进行。如果进程重启,JVM内的cache会失效,但page cache仍然可用
- 充分利用Page Cache
I/O Scheduler将连续的小块写组装成大块的物理写从而提高性能
I/O Scheduler会尝试将一些写操作重新按顺序排好,从而减少磁盘头的移动时间
5、充分利用所有空闲内存(非JVM内存)
应用层cache也会有对应的page cache与之对应,直接使用page cache可增大可用cache,如使用heap内的cache,会增加GC负担
6、可通过如下参数强制flush,但并不建议这么做
log.flush.interval.messages=10000
log.flush.interval.ms=1000
7、支持多Directory(目录)
2、零拷贝
传统模式下数据从文件传输到网络需要4次数据拷贝,4次上下文切换和2次系统调用。
3、批处理和压缩
- Producer和Consumer均支持批量处理数据,从而减少了网络传输的开销
- Producer可将数据压缩后发送给broker,从而减少网络传输代价。目前支持Snappy,Gzip和LZ4压缩
4、Partition
- 通过Partition实现了并行处理和水平扩展
- Partition是Kafka(包括kafka Stream)并行处理的最小单位
- 不同Partition可处于不同的Broker,充分利用多机资源
- 同一Broker上的不同Partition可置于不同的Directory
5、ISR
1)ISR(in-sync-replica)实现了可用性和一致性的动态平衡
#如果这个时间内follower没有发起fetch请求,被认为dead,从ISR移除
replica.log.time.max.ms=10000
#如果follower相比leader落后这么多以上消息条数,会被从ISR移除
replica.log.max.messages=4000
2)ISR可容忍更多的节点失败
Majority Quorum如果要容忍f个节点失败,至少需要2f+1个节点(zookeeper,journalnode)
ISR如果要容忍f个节点失败,至少需要f+1个节点
3)如何处理Replica Crach
Leader crash后,ISR中的任何replica皆可竞选称为Leader
如果所有replica都crash,可选择让第一个recover的replica或者第一个在ISR中的replica成为leader
unclean.leader.election.enable=true
(三)、Kafka性能影响因子
1、性能影响因子

如图2-18所示,producer个数和吞吐量成正比。
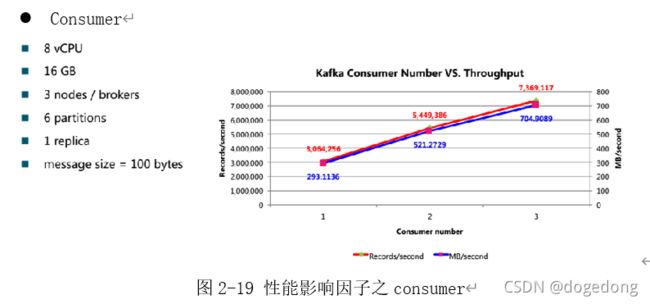
如图2-19所示,consumer个数在没有达到partition个数之前,和消费的吞吐量成正比。
Partition

如图2-20所示,分区个数和生产的吞吐量,在一定范围内,先增长,当达到某一个值之后趋于稳定,在上下浮动。
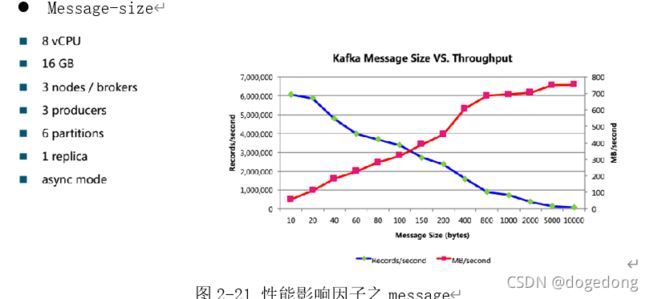
如图2-21所示,随着message size的增大,生产者对应的每秒生成的记录数在成下降趋势,生产的数据体积成上升趋势。
Replication

如图2-22所示,副本越大,自然需要同步数据的量就越多,自然kafka的生成的吞吐量就越低。
2、性能检测方式
可以借助kafka脚本来查看kafka集群性能。
kafka-producer-perf-test.sh
通过该脚本查看kafka生产者的性能,如下图2-23所示。

bin/kafka-producer-perf-test.sh --topic spark \
--num-records 100000 \ -->测试生成多少条记录
--throughput 10000 \ --->生产者的吞吐量,约等于messages/sec
--record-size 10 \ -->每条消息的大小
--producer.config config/producer.properties
kafka-consumer-perf-test.sh

图2-24 生产性能评估
读取到的结果
start.time=2019-08-06 02:31:23:738 --->开始时间
end.time=2019-08-06 02:31:24:735 --->结束时间
data.consumed.in.MB=0.9534 --->总共消费的数据体积
MB.sec=0.9562 --->每秒钟消费数据体积
data.consumed.in.nMsg=100000 --->总共消费的数据记录数
nMsg.sec=100300.9027 --->每秒钟消费记录数
rebalance.time.ms=47 --->进行rebalance的时间
fetch.time.ms=950 --->抓取这10w条数据总共花费多长时间
fetch.MB.sec=1.0035 --->每秒钟抓取数据体积
fetch.nMsg.sec=105263.1579 --->每秒钟抓取数据记录数