AI实战营:MMSegmentation代码实现
目录
安装配置环境MMSegmentation
安装配置
检查安装成功
下载MMSegmentation
下载素材
预训练语义分割模型预测-单张图像-命令行
PSPNet语义分割算法
编辑 SegFormer
Mask2Former
ADE20K语义分割数据集
预训练语义分割模型预测-单张图像-Python API
Cityscapes数据集
预训练语义分割模型预测-视频
视频预测-命令行 不推荐,慢
视频预测-Python API(推荐,快)
Kaggle实战-迪拜卫星航拍多类别语义分割
下载整理好的数据集: https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20230130-mmseg/dataset/Dubai-dataset.zip
可视化探索数据集
mask灰度图标注含义
准备config配置文件
可视化训练日志
用训练得到的模型预测
测试集性能评估
测试集精度指标
速指标-FPS
安装配置环境MMSegmentation
安装配置
pip install openmim
mim install mmengine
mim install mmcv
mim install mmdet
mim install mmsegmentation 检查安装成功
# 检查 Pytorch
import torch, torchvision
print('Pytorch 版本', torch.__version__)
print('CUDA 是否可用',torch.cuda.is_available())
# 检查 mmcv
import mmcv
from mmcv.ops import get_compiling_cuda_version, get_compiler_version
print('MMCV版本', mmcv.__version__)
print('CUDA版本', get_compiling_cuda_version())
print('编译器版本', get_compiler_version())
# 检查 mmsegmentation
import mmseg
from mmseg.utils import register_all_modules
from mmseg.apis import inference_model, init_model
print('mmsegmentation版本', mmseg.__version__)下载MMSegmentation
git clone [email protected]:open-mmlab/mmsegmentation.git -b dev-1.x 下载素材
伦敦街景图片 上海驾车街景视频 街拍视频
设置Matplotlib中文字体
下载SimHei字体 到Miniconda3\Lib\site-packages\matplotlib\mpl-data\fonts\ttf路径下
import matplotlib
import matplotlib.pyplot as plt
matplotlib.rc("font",family='SimHei') # 中文字体
plt.plot([1,2,3], [100,500,300])
plt.title('matplotlib中文字体测试', fontsize=25)
plt.xlabel('X轴', fontsize=15)
plt.ylabel('Y轴', fontsize=15)
plt.show() 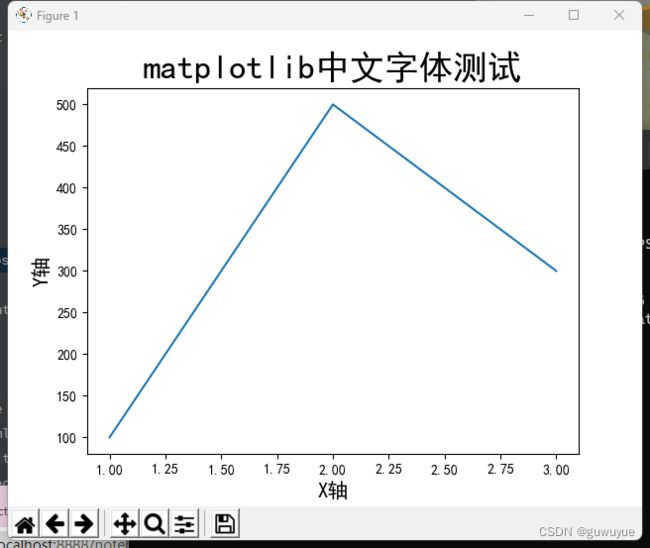
常用config和checkpoint文件
configs/pspnet/pspnet_r50-d8_4xb2-40k_cityscapes-512x1024.py
https://download.openmmlab.com/mmsegmentation/v0.5/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth
configs/segformer/segformer_mit-b5_8xb1-160k_cityscapes-1024x1024.py
https://download.openmmlab.com/mmsegmentation/v0.5/segformer/segformer_mit-b5_8x1_1024x1024_160k_cityscapes/segformer_mit-b5_8x1_1024x1024_160k_cityscapes_20211206_072934-87a052ec.pth
configs/mask2former/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024.py
https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024_20221202_141901-28ad20f1.pth
预训练语义分割模型预测-单张图像-命令行
PSPNet语义分割算法
python .\demo\image_demo.py .\data\street_uk.jpeg .\configs\pspnet\pspnet_r50-d8_4xb2-40k_cityscapes-512x1024.py https://download.openmmlab.com/mmsegmentation/v0.5/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth --out-file .\outputs\B1_uk_pspnet.jpg --device cuda:0 --opacity 0.5
from PIL import Image
Image.open('outputs/B1_uk_pspnet.jpg')SegFormer
python .\demo\image_demo.py .\data\street_uk.jpeg .\configs\segformer\segformer_mit-b5_8xb1-160k_cityscapes-1024x1024.py https://download.openmmlab.com/mmsegmentation/v0.5/segformer/segformer_mit-b5_8x1_1024x1024_160k_cityscapes/segformer_mit-b5_8x1_1024x1024_160k_cityscapes_20211206_072934-87a052ec.pth --out-file .\outputs\B1_uk_segformer.jpg --opacity 0.5
from PIL import Image
Image.open('outputs/B1_uk_segformer.jpg')Mask2Former
python .\demo\image_demo.py .\data\street_uk.jpeg .\configs\mask2former\mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024.py https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024_20221202_141901-28ad20f1.pth --out-file outputs/B1_uk_Mask2Former.jpg --device cuda:0 --opacity 0.5
from PIL import Image
Image.open('outputs/B1_uk_Mask2Former.jpg')ADE20K语义分割数据集
mmsegmentation/mmseg/datasets/ade.py
关于ADE20K的故事:语义分割该如何走下去? - 知乎
python .\demo\image_demo.py .\data\street_uk.jpeg .\configs\segformer\segformer_mit-b5_8xb2-160k_ade20k-512x512.py https://download.openmmlab.com/mmsegmentation/v0.5/segformer/segformer_mit-b5_640x640_160k_ade20k/segformer_mit-b5_640x640_160k_ade20k_20220617_203542-940a6bd8.pth --out-file outputs/B1_Segformer_ade20k.jpg --device cuda:0 --opacity 0.5
Image.open('outputs/B1_Segformer_ade20k.jpg')
预训练语义分割模型预测-单张图像-Python API
Cityscapes数据集
Cityscapes语义分割数据集:https://www.cityscapes-dataset.com
超详细!手把手带你轻松用 MMSegmentation 跑语义分割数据集
19个类别 'road', 'sidewalk', 'building', 'wall', 'fence', 'pole', 'traffic light', 'traffic sign', 'vegetation', 'terrain', 'sky', 'person', 'rider', 'car', 'truck', 'bus', 'train', 'motorcycle', 'bicycle'
import mmcv
import torch
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
from mmseg.datasets import cityscapes
from mmengine.model.utils import revert_sync_batchnorm
from mmseg.apis import inference_model, init_model, show_result_pyplot
from mmseg.utils import register_all_modules
register_all_modules()
# 载入测试图像
img_path = 'data/street_uk.jpeg'
img_pil = Image.open(img_path)
# 载入模型
# 模型 config 配置文件
# config_file = 'configs/pspnet/pspnet_r50-d8_4xb2-40k_cityscapes-512x1024.py'
config_file = 'configs/mask2former/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024.py'
# 模型 checkpoint 权重文件
# checkpoint_file = 'https://download.openmmlab.com/mmsegmentation/v0.5/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth'
checkpoint_file = 'https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024_20221202_141901-dc2c2ddd.pth'
model = init_model(config_file, checkpoint_file, device='cuda:0')
# 运行语义分割预测
if not torch.cuda.is_available():
model = revert_sync_batchnorm(model)
result = inference_model(model, img_path)
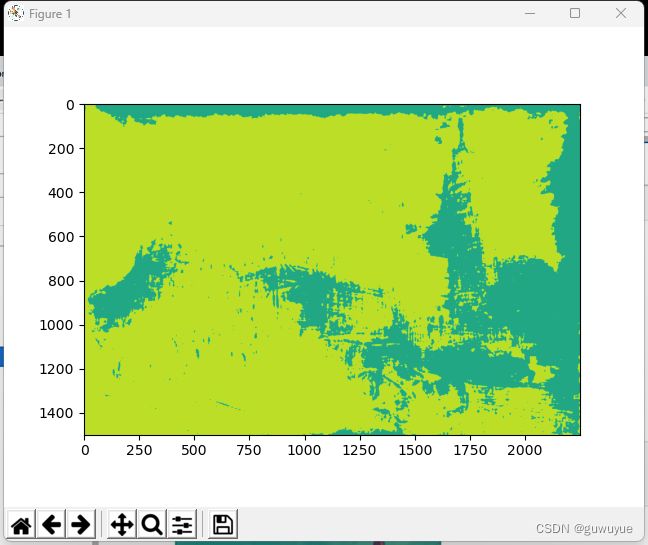
class_map = result.pred_sem_seg.data[0].detach().cpu().numpy()
plt.imshow(class_map)
plt.show()
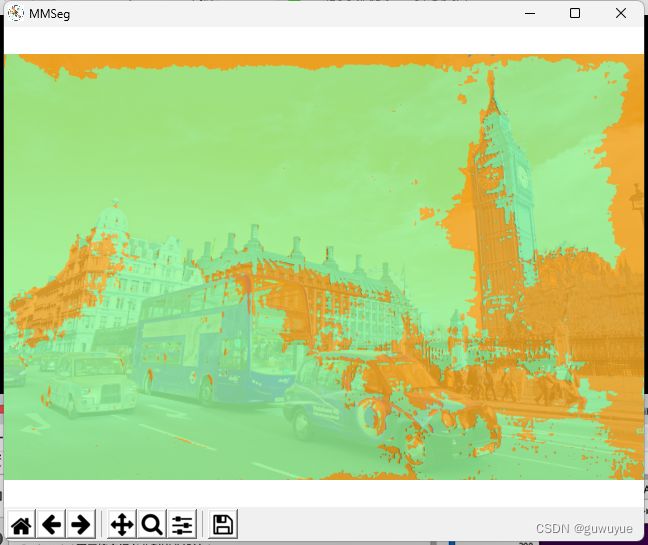
# 可视化语义分割预测结果-方法一
visualization = show_result_pyplot(
model,
img_path,
result,
opacity=0.8,
title='MMSeg',
out_file='outputs/B2.jpg')
plt.imshow(mmcv.bgr2rgb(visualization))
plt.show()
Image.open('outputs/B2.jpg')
# 可视化语义分割预测结果-方法二
# 获取类别名和调色板
classes = cityscapes.CityscapesDataset.METAINFO['classes']
palette = cityscapes.CityscapesDataset.METAINFO['palette']
opacity = 0.15 # 透明度,越大越接近原图
# 将分割图按调色板染色
# seg_map = result[0].astype('uint8')
seg_map = class_map.astype('uint8')
seg_img = Image.fromarray(seg_map).convert('P')
seg_img.putpalette(np.array(palette, dtype=np.uint8))
from matplotlib import pyplot as plt
import matplotlib.patches as mpatches
plt.figure(figsize=(14, 8))
im = plt.imshow(
(
(np.array(seg_img.convert('RGB'))) *
(1 - opacity) + mmcv.imread(img_path) * opacity) / 255)
# 为每一种颜色创建一个图例
patches = [
mpatches.Patch(color=np.array(palette[i]) / 255., label=classes[i])
for i in range(18)
]
plt.legend(
handles=patches,
bbox_to_anchor=(1.05, 1),
loc=2,
borderaxespad=0.,
fontsize='large')
plt.show()
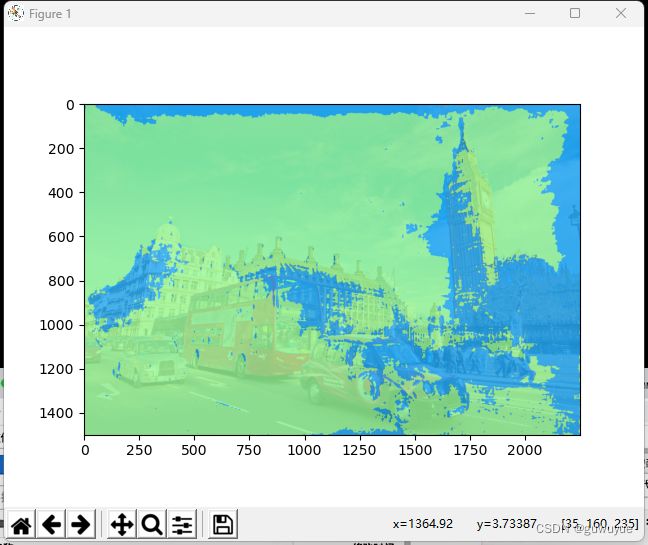
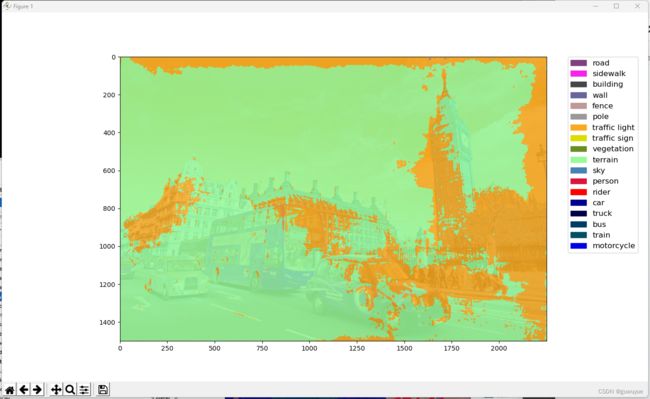
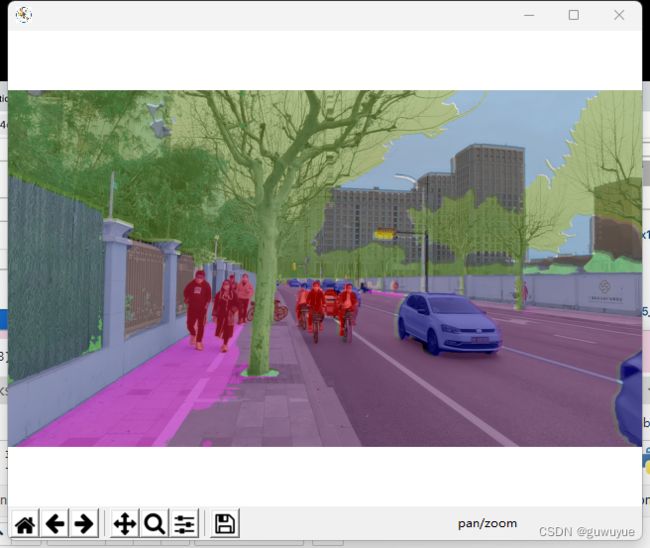
预训练语义分割模型预测-视频
视频预测-命令行 不推荐,慢
python .\demo\video_demo.py .\data\street_20220330_174028.mp4 .\configs\
mask2former\mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024.py https://download.openmmlab.c
om/mmsegmentation/v0.5/mask2former/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024/mask2for
mer_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024_20221202_141901-28ad20f1.pth --device cuda:0 --output-file outputs/B3_video.mp4 --opacity 0.5
视频预测-Python API(推荐,快)
# 工具包
import numpy as np
import time
import shutil
import torch
from PIL import Image
import cv2
import os
import mmcv
import mmengine
from mmseg.apis import inference_model
from mmseg.utils import register_all_modules
register_all_modules()
from mmseg.datasets import CityscapesDataset
# 载入模型
# 模型 config 配置文件
config_file = 'configs/mask2former/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024.py'
# 模型 checkpoint 权重文件
checkpoint_file = 'https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024_20221202_141901-28ad20f1.pth'
from mmseg.apis import init_model
model = init_model(config_file, checkpoint_file, device='cuda:0')
from mmengine.model.utils import revert_sync_batchnorm
if not torch.cuda.is_available():
model = revert_sync_batchnorm(model)
# 载入视频路径
# input_video = 'data/traffic.mp4'
input_video = 'data/street_20220330_174028.mp4'
# 创建临时文件夹,存放每帧结果
temp_out_dir = time.strftime('%Y%m%d%H%M%S')
os.mkdir(temp_out_dir)
print('创建临时文件夹 {} 用于存放每帧预测结果'.format(temp_out_dir))
# 视频单帧预测
# 获取 Cityscapes 街景数据集 类别名和调色板
from mmseg.datasets import cityscapes
classes = cityscapes.CityscapesDataset.METAINFO['classes']
palette = cityscapes.CityscapesDataset.METAINFO['palette']
def pridict_single_frame(img, opacity=0.2):
result = inference_model(model, img)
# 将分割图按调色板染色
seg_map = np.array(
result.pred_sem_seg.data[0].detach().cpu().numpy()).astype('uint8')
seg_img = Image.fromarray(seg_map).convert('P')
seg_img.putpalette(np.array(palette, dtype=np.uint8))
show_img = (np.array(
seg_img.convert('RGB'))) * (1 - opacity) + img * opacity
return show_img
# 视频逐帧预测
# 读入待预测视频
imgs = mmcv.VideoReader(input_video)
prog_bar = mmengine.ProgressBar(len(imgs))
# 对视频逐帧处理
for frame_id, img in enumerate(imgs):
## 处理单帧画面
show_img = pridict_single_frame(img, opacity=0.15)
temp_path = f'{temp_out_dir}/{frame_id:06d}.jpg' # 保存语义分割预测结果图像至临时文件夹
cv2.imwrite(temp_path, show_img)
prog_bar.update() # 更新进度条
# 把每一帧串成视频文件
mmcv.frames2video(
temp_out_dir, 'outputs/B3_video.mp4', fps=imgs.fps, fourcc='mp4v')
shutil.rmtree(temp_out_dir) # 删除存放每帧画面的临时文件夹
print('删除临时文件夹', temp_out_dir)
运行结果 https://live.csdn.net/v/304335
Kaggle实战-迪拜卫星航拍多类别语义分割
下载整理好的数据集: https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20230130-mmseg/dataset/Dubai-dataset.zip
kaggle原版数据集: Semantic segmentation of aerial imagery | Kaggle
可视化探索数据集
# 导入工具包
import os
import cv2
import numpy as np
from PIL import Image
from tqdm import tqdm
import matplotlib.pyplot as plt
# 查看单张图像及其语义分割标注
# 指定单张图像路径
img_path = 'data/Dubai-dataset/img_dir/train/14.jpg'
mask_path = 'data/Dubai-dataset/ann_dir/train/14.png'
img = Image.open(img_path)
mask = Image.open(mask_path)
# img.show()
# mask.show()
img = cv2.imread(img_path)
mask = cv2.imread(mask_path)
print(img.shape, mask.shape)
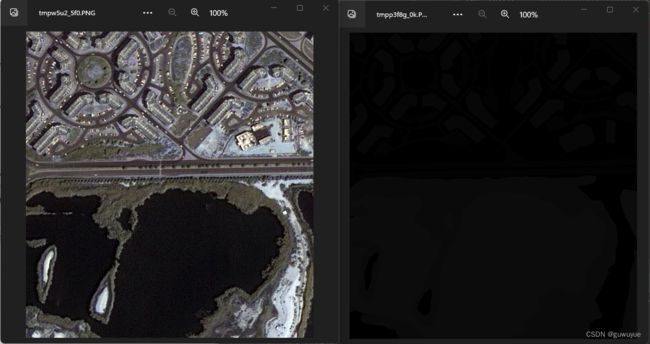
mask灰度图标注含义
# mask 语义分割标注,与原图大小相同
np.unique(mask) # array([0, 1, 2, 3, 4], dtype=uint8)
# 类别编号 类别名称
# 0 Land
# 1 Road
# 2 Building
# 3 Vegetation
# 4 Water
# 5 Unlabeled
# 可视化语义分割标注
plt.imshow(mask[:,:,0])
plt.show()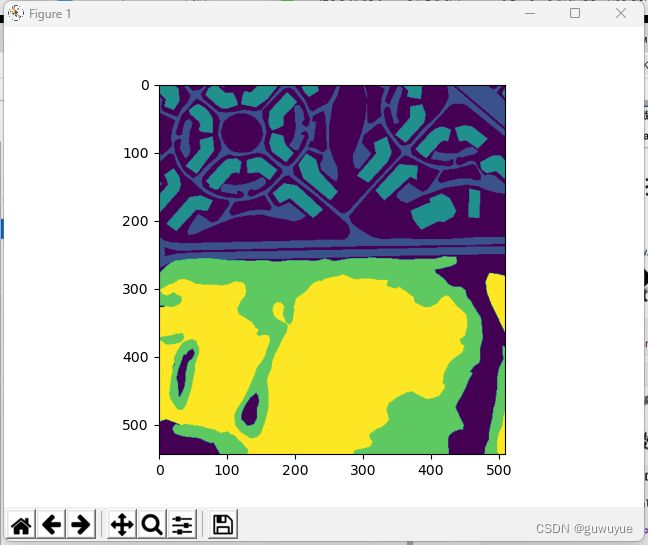
叠加在原图上显示
plt.imshow(img[:,:,::-1])
plt.imshow(mask[:,:,0], alpha=0.4) # alpha 高亮区域透明度,越小越接近原图
plt.axis('off')
plt.show()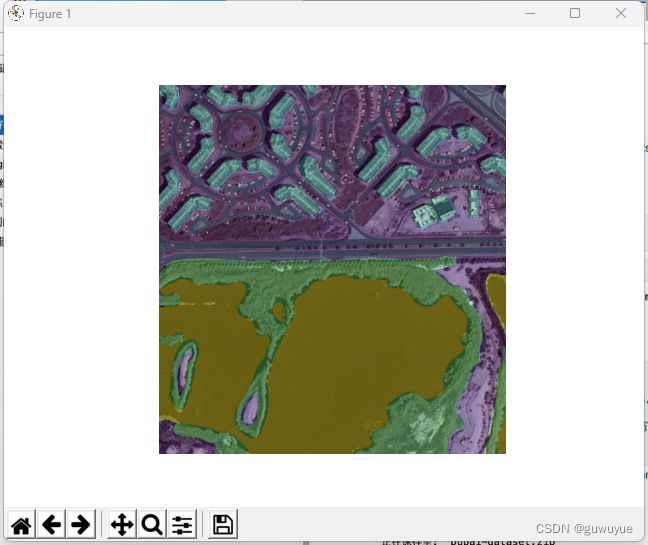
批量可视化图像和标注
# 指定图像和标注路径
PATH_IMAGE = 'data/Dubai-dataset/img_dir/train'
PATH_MASKS = 'data/Dubai-dataset/ann_dir/train'
# n行n列可视化
n = 5
# 标注区域透明度
opacity = 0.5
fig, axes = plt.subplots(nrows=n, ncols=n, sharex=True, figsize=(12, 12))
for i, file_name in enumerate(os.listdir(PATH_IMAGE)[:n ** 2]):
# 载入图像和标注
img_path = os.path.join(PATH_IMAGE, file_name)
mask_path = os.path.join(PATH_MASKS, file_name.split('.')[0] + '.png')
img = cv2.imread(img_path)
mask = cv2.imread(mask_path)
# 可视化
axes[i // n, i % n].imshow(img)
axes[i // n, i % n].imshow(mask[:, :, 0], alpha=opacity)
axes[i // n, i % n].axis('off') # 关闭坐标轴显示
fig.suptitle('Image and Semantic Label', fontsize=30)
plt.tight_layout()
plt.show()准备config配置文件
定义数据集类(各类别名称及配色),下载 到mmseg/datasets
注册数据集类 下载 到mmseg/datasets
定义训练及测试pipeline 下载 到 configs/_base_/datasets
下载模型config配置文件 下载 到 configs/pspnet
# 载入config配置文件
from mmengine import Config
cfg = Config.fromfile('configs/pspnet/pspnet_r50-d8_4xb2-40k_DubaiDataset.py')
# 修改config配置文件
cfg.norm_cfg = dict(type='BN', requires_grad=True) # 只使用GPU时,BN取代SyncBN
cfg.crop_size = (256, 256)
cfg.model.data_preprocessor.size = cfg.crop_size
cfg.model.backbone.norm_cfg = cfg.norm_cfg
cfg.model.decode_head.norm_cfg = cfg.norm_cfg
cfg.model.auxiliary_head.norm_cfg = cfg.norm_cfg
# modify num classes of the model in decode/auxiliary head
# 模型 decode/auxiliary 输出头,指定为类别个数
cfg.model.decode_head.num_classes = 6
cfg.model.auxiliary_head.num_classes = 6
cfg.train_dataloader.batch_size = 8
cfg.test_dataloader = cfg.val_dataloader
# 结果保存目录
cfg.work_dir = './work_dirs/DubaiDataset'
# 训练迭代次数
cfg.train_cfg.max_iters = 3000
# 评估模型间隔
cfg.train_cfg.val_interval = 400
# 日志记录间隔
cfg.default_hooks.logger.interval = 100
# 模型权重保存间隔
cfg.default_hooks.checkpoint.interval = 1500
# 随机数种子
cfg['randomness'] = dict(seed=0)
# 查看完整config配置文件
print(cfg)
# 保存config配置文件
cfg.dump('pspnet-DubaiDataset_20230617.py')
开始训练:
如果遇到报错`CUDA out of memeory`,可尝试以下步骤:
1. 调小 batch size
2. 左上角`内核-关闭所有内核`
3. 重启实例,或者使用显存更高的实例即可。
python .\tools\train.py .\configs\pspnet\pspnet_r50-d8_4xb2-40k_DubaiDataset.py 06/17 14:42:01 - mmengine - INFO - Saving checkpoint at 40000 iterations
06/17 14:42:06 - mmengine - INFO - per class results:
06/17 14:42:06 - mmengine - INFO -
+------------+-------+-------+
| Class | IoU | Acc |
+------------+-------+-------+
| Land | 62.02 | 78.81 |
| Road | 37.13 | 47.63 |
| Building | 25.75 | 38.49 |
| Vegetation | 25.39 | 36.1 |
| Water | 69.79 | 98.09 |
| Unlabeled | 0.0 | 0.0 |
+------------+-------+-------+
06/17 14:42:06 - mmengine - INFO - Iter(val) [15/15] aAcc: 67.0100 mIoU: 36.6800 mAcc: 49.8500 data_time: 0.0027 time: 0.2232
可视化训练日志
训练模型时在work_dirs目录生成记录训练日志,解析其中损失函数、评估指标等信息,并可视化。
设置Matplotlib中文字体
# # windows操作系统
plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
# Linux操作系统,例如 云GPU平台:https://featurize.cn/?s=d7ce99f842414bfcaea5662a97581bd1
# 如果遇到 SSL 相关报错,重新运行本代码块即可
#!wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20220716-mmclassification/dataset/SimHei.ttf -O /environment/miniconda3/lib/python3.7/site-packages/matplotlib/mpl-data/fonts/ttf/SimHei.ttf
#!rm -rf /home/featurize/.cache/matplotlib
import matplotlib
import matplotlib.pyplot as plt
matplotlib.rc("font",family='SimHei') # 中文字体
plt.plot([1,2,3], [100,500,300])
plt.title('matplotlib中文字体测试', fontsize=25)
plt.xlabel('X轴', fontsize=15)
plt.ylabel('Y轴', fontsize=15)
plt.show()import pandas as pd
import matplotlib.pyplot as plt
plt.rc("font",family='SimHei') # 中文字体
# 载入训练日志
log_path = 'work_dirs/pspnet_r50-d8_4xb2-40k_DubaiDataset/20230617_133058/vis_data/scalars.json'
with open(log_path, 'r') as f:
json_list = f.readlines()
print(len(json_list))
print(eval(json_list[4]))
df_train = pd.DataFrame()
df_test = pd.DataFrame()
for each in json_list[:-1]:
if 'aAcc' in each:
df_test = df_test.append(eval(each), ignore_index=True)
else:
df_train = df_train.append(eval(each), ignore_index=True)
print(df_train)
print(df_test)
# 导出训练日志表格
df_train.to_csv('训练日志-训练集.csv', index=False)
df_test.to_csv('训练日志-测试集.csv', index=False)
# 可视化辅助函数
from matplotlib import colors as mcolors
import random
random.seed(124)
colors = ['b', 'g', 'r', 'c', 'm', 'y', 'k', 'tab:blue', 'tab:orange', 'tab:green', 'tab:red', 'tab:purple', 'tab:brown', 'tab:pink', 'tab:gray', 'tab:olive', 'tab:cyan', 'black', 'indianred', 'brown', 'firebrick', 'maroon', 'darkred', 'red', 'sienna', 'chocolate', 'yellow', 'olivedrab', 'yellowgreen', 'darkolivegreen', 'forestgreen', 'limegreen', 'darkgreen', 'green', 'lime', 'seagreen', 'mediumseagreen', 'darkslategray', 'darkslategrey', 'teal', 'darkcyan', 'dodgerblue', 'navy', 'darkblue', 'mediumblue', 'blue', 'slateblue', 'darkslateblue', 'mediumslateblue', 'mediumpurple', 'rebeccapurple', 'blueviolet', 'indigo', 'darkorchid', 'darkviolet', 'mediumorchid', 'purple', 'darkmagenta', 'fuchsia', 'magenta', 'orchid', 'mediumvioletred', 'deeppink', 'hotpink']
markers = [".",",","o","v","^","<",">","1","2","3","4","8","s","p","P","*","h","H","+","x","X","D","d","|","_",0,1,2,3,4,5,6,7,8,9,10,11]
linestyle = ['--', '-.', '-']
def get_line_arg():
'''
随机产生一种绘图线型
'''
line_arg = {}
line_arg['color'] = random.choice(colors)
# line_arg['marker'] = random.choice(markers)
line_arg['linestyle'] = random.choice(linestyle)
line_arg['linewidth'] = random.randint(1, 4)
# line_arg['markersize'] = random.randint(3, 5)
return line_arg
# 训练集损失函数
metrics = ['loss', 'decode.loss_ce', 'aux.loss_ce']
plt.figure(figsize=(16, 8))
x = df_train['step']
for y in metrics:
plt.plot(x, df_train[y], label=y, **get_line_arg())
plt.tick_params(labelsize=20)
plt.xlabel('step', fontsize=20)
plt.ylabel('loss', fontsize=20)
plt.title('训练集损失函数', fontsize=25)
plt.savefig('训练集损失函数.pdf', dpi=120, bbox_inches='tight')
plt.legend(fontsize=20)
plt.show()
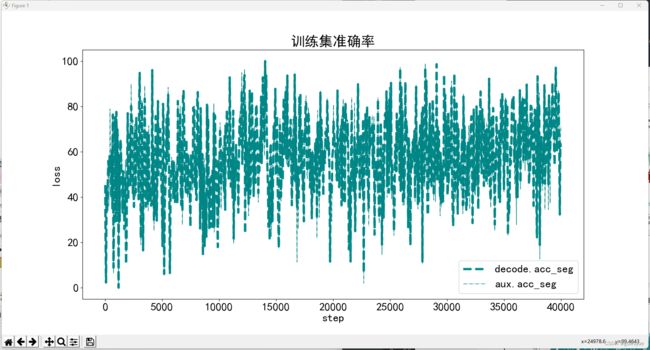
# 训练集准确率
print(df_train.columns)
metrics = ['decode.acc_seg', 'aux.acc_seg']
plt.figure(figsize=(16, 8))
x = df_train['step']
for y in metrics:
plt.plot(x, df_train[y], label=y, **get_line_arg())
plt.tick_params(labelsize=20)
plt.xlabel('step', fontsize=20)
plt.ylabel('loss', fontsize=20)
plt.title('训练集准确率', fontsize=25)
plt.savefig('训练集准确率.pdf', dpi=120, bbox_inches='tight')
plt.legend(fontsize=20)
plt.show()
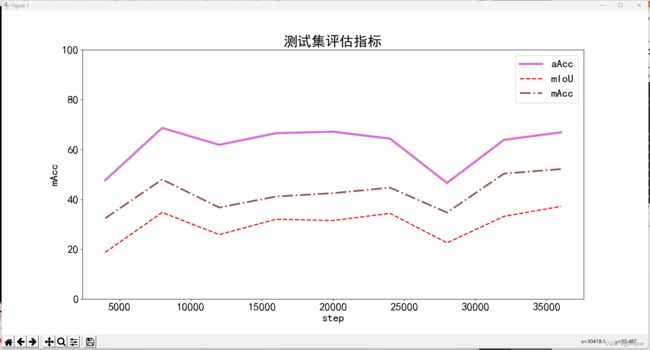
# 测试机评估指标
print(df_test.columns)
metrics = ['aAcc', 'mIoU', 'mAcc']
plt.figure(figsize=(16, 8))
x = df_test['step']
for y in metrics:
plt.plot(x, df_test[y], label=y, **get_line_arg())
plt.tick_params(labelsize=20)
plt.ylim([0, 100])
plt.xlabel('step', fontsize=20)
plt.ylabel(y, fontsize=20)
plt.title('测试集评估指标', fontsize=25)
plt.savefig('测试集分类评估指标.pdf', dpi=120, bbox_inches='tight')
plt.legend(fontsize=20)
plt.show()

用训练得到的模型预测
import numpy as np
import matplotlib.pyplot as plt
from mmseg.apis import init_model, inference_model, show_result_pyplot
import mmcv
import cv2
# 载入 config 配置文件
from mmengine import Config
cfg = Config.fromfile('configs/pspnet/pspnet_r50-d8_4xb2-40k_DubaiDataset.py')
from mmengine.runner import Runner
from mmseg.utils import register_all_modules
# register all modules in mmseg into the registries
# do not init the default scope here because it will be init in the runner
register_all_modules(init_default_scope=False)
cfg['work_dir'] = 'work_dirs'
runner = Runner.from_cfg(cfg)
# 载入模型
checkpoint_path = 'work_dirs/pspnet_r50-d8_4xb2-40k_DubaiDataset/iter_40000.pth'
model = init_model(cfg, checkpoint_path, 'cuda:0')
# 载入图像
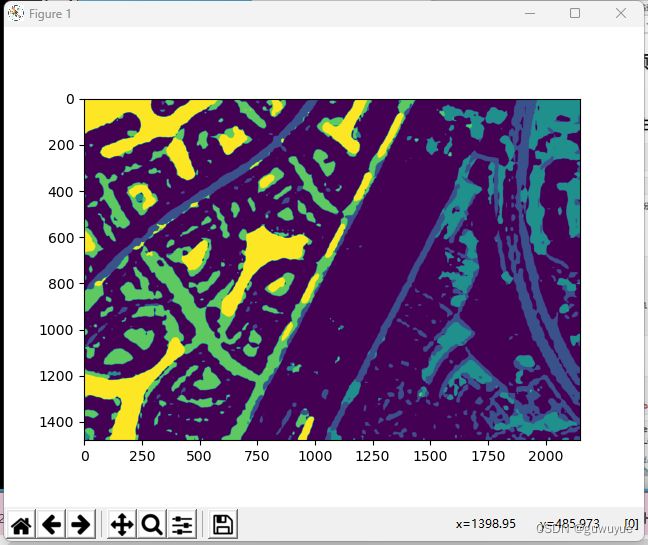
img = mmcv.imread('data/Dubai-dataset/img_dir/val/71.jpg')
# 语义分割预测
result = inference_model(model, img)
print(result.keys())
pred_mask = result.pred_sem_seg.data[0].cpu().numpy()
print(pred_mask.shape)
print(np.unique(pred_mask))
# 可视化语义分割预测结果
plt.imshow(pred_mask)
plt.show()
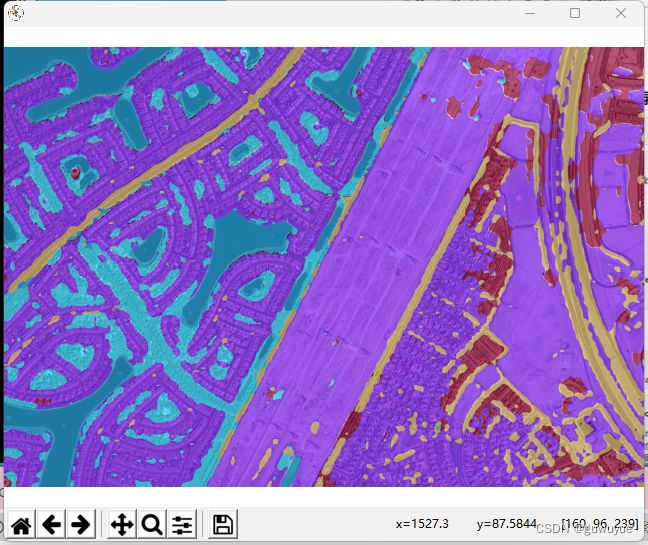
# 可视化预测结果
visualization = show_result_pyplot(model, img, result, opacity=0.7, out_file='pred.jpg')
plt.imshow(mmcv.bgr2rgb(visualization))
plt.show()
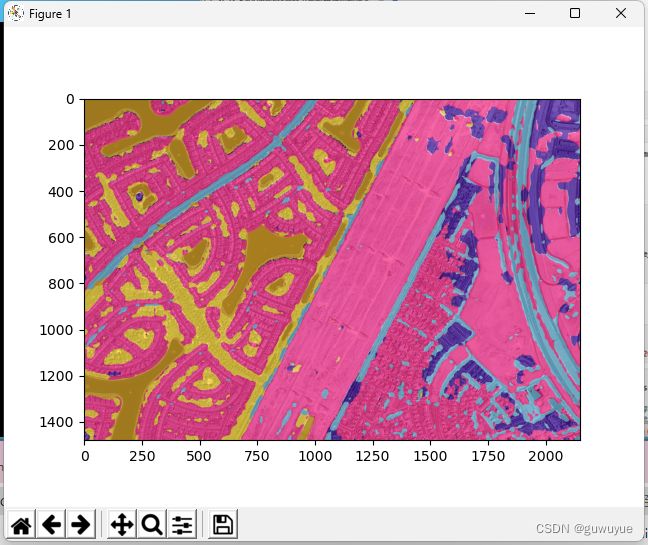
# 获取测试标注
label = mmcv.imread('data/Dubai-dataset/ann_dir/val/71.png')
print(label.shape)
# 三个通道全部一样,只取一个通道作为标注即可。
label_mask = label[:,:,0]
print(label_mask.shape)
print(np.unique(label_mask))
plt.imshow(label_mask)
plt.show()

# 对比测试集标注和语义分割预测结果
# 测试集标注
print(label_mask.shape)
# 语义分割预测结果
print(pred_mask.shape)
# 真实为前景,预测为前景
TP = (label_mask == 1) & (pred_mask==1)
# 真实为背景,预测为背景
TN = (label_mask == 0) & (pred_mask==0)
# 真实为前景,预测为背景
FN = (label_mask == 1) & (pred_mask==0)
# 真实为背景,预测为前景
FP = (label_mask == 0) & (pred_mask==1)
plt.imshow(TP)
plt.show() 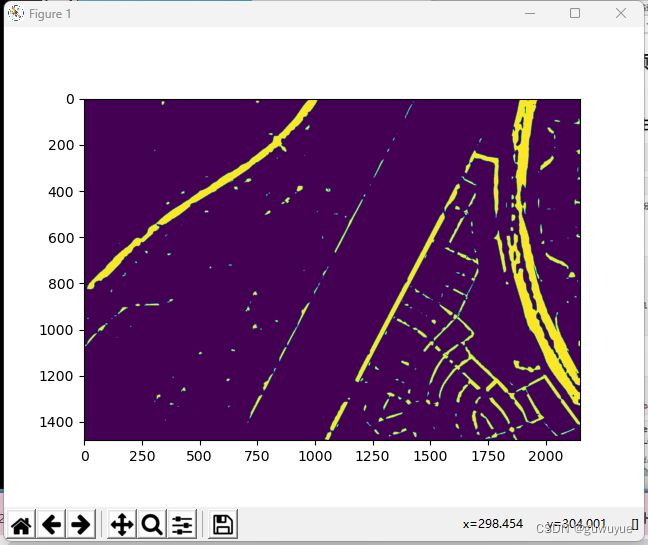
confusion_map = TP * 255 + FP * 150 + FN * 80 + TN * 30
plt.imshow(confusion_map)
plt.show()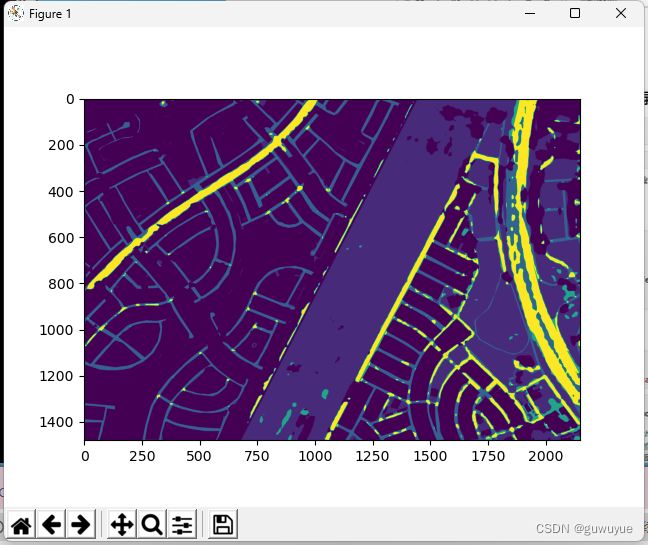
# 混淆矩阵
from sklearn.metrics import confusion_matrix
confusion_matrix_model = confusion_matrix(label_mask.flatten(), pred_mask.flatten())
print(confusion_matrix_model)
import itertools
def cnf_matrix_plotter(cm, classes, cmap=plt.cm.Blues):
"""
传入混淆矩阵和标签名称列表,绘制混淆矩阵
"""
plt.figure(figsize=(10, 10))
plt.imshow(cm, interpolation='nearest', cmap=cmap)
# plt.colorbar() # 色条
tick_marks = np.arange(len(classes))
plt.title('Confusion Matrix', fontsize=30)
plt.xlabel('Pred', fontsize=25, c='r')
plt.ylabel('True', fontsize=25, c='r')
plt.tick_params(labelsize=16) # 设置类别文字大小
plt.xticks(tick_marks, classes, rotation=90) # 横轴文字旋转
plt.yticks(tick_marks, classes)
# 写数字
threshold = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > threshold else "black",
fontsize=12)
plt.tight_layout()
plt.savefig('混淆矩阵.pdf', dpi=300) # 保存图像
plt.show()
classes = ['Land', 'Road', 'Building', 'Vegetation', 'Water', 'Unlabeled']
cnf_matrix_plotter(confusion_matrix_model, classes, cmap='Blues')
# Unlabeled类别,既无预测结果,也无标签,因此混淆矩阵中不显示。
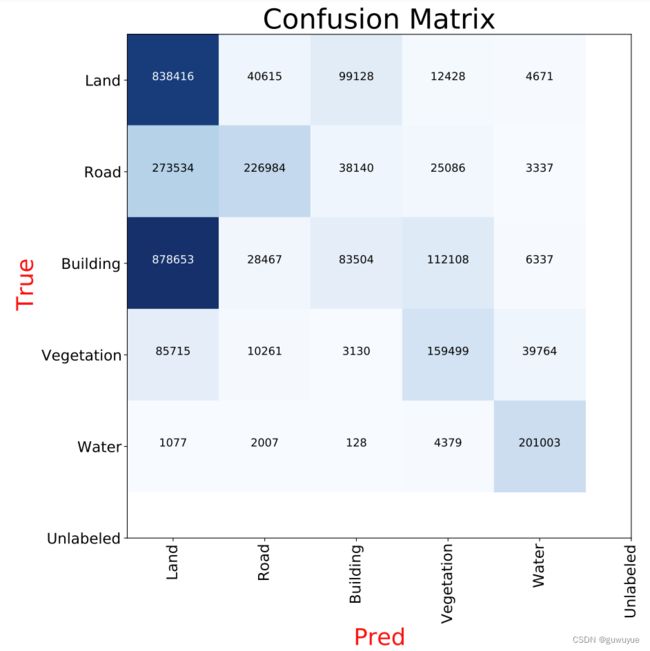
测试集性能评估
测试集精度指标
python .\tools\test.py configs/pspnet/pspnet_r50-d8_4xb2-40k_DubaiDataset.py work_dirs/pspnet_r50-d8_4xb2-40k_DubaiDataset/iter_40000.pth06/17 15:17:12 - mmengine - WARNING - The prefix is not set in metric class IoUMetric.
Loads checkpoint by local backend from path: work_dirs/pspnet_r50-d8_4xb2-40k_DubaiDataset/iter_40000.pth
06/17 15:17:14 - mmengine - INFO - Load checkpoint from work_dirs/pspnet_r50-d8_4xb2-40k_DubaiDataset/iter_40000.pth
06/17 15:18:08 - mmengine - INFO - per class results:
06/17 15:18:08 - mmengine - INFO -
+------------+-------+-------+
| Class | IoU | Acc |
+------------+-------+-------+
| Land | 62.02 | 78.81 |
| Road | 37.13 | 47.63 |
| Building | 25.75 | 38.49 |
| Vegetation | 25.39 | 36.1 |
| Water | 69.79 | 98.09 |
| Unlabeled | 0.0 | 0.0 |
+------------+-------+-------+
06/17 15:18:08 - mmengine - INFO - Iter(test) [15/15] aAcc: 67.0100 mIoU: 36.6800 mAcc: 49.8500 data_time: 0.9267 time: 3.5725
速指标-FPS
python .\tools\analysis_tools\benchmark.py configs/pspnet/pspnet_r50-d8_4xb2-40k_DubaiDataset.py work_dirs/pspnet_r50-d8_4xb2-40k_DubaiDataset/iter_40000.pth