【python爬虫】top250 title and rate
文章目录
-
- 地址
- 寻找标题与评分
- 代码
- 输出
- 进一步
地址
https://movie.douban.com/

第一页只有25条记录,翻页之后url改变。

寻找标题与评分
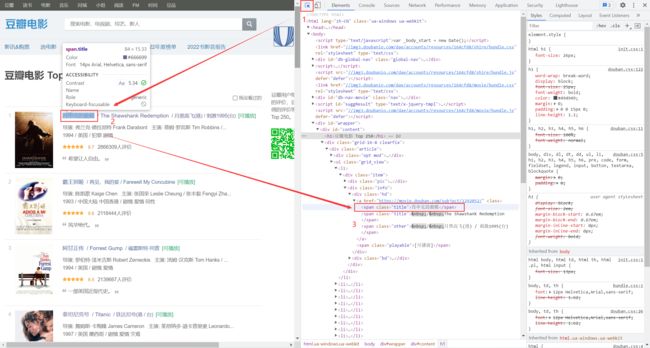
标题
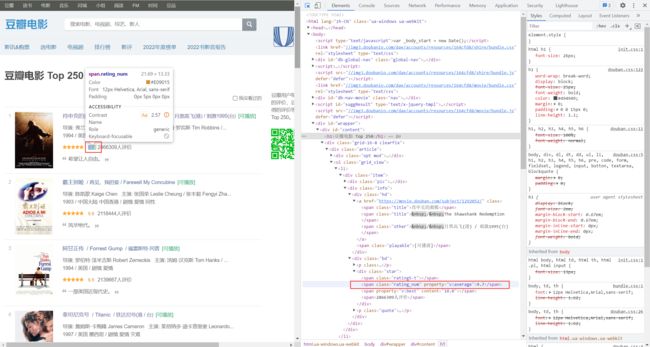
评分
代码
from bs4 import BeautifulSoup
import requests
import pandas as pd
import time
time_start = time.time() # 记录开始时间
# 伪造headers来绕过 反爬机制
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 SLBrowser/8.0.1.4031 SLBChan/105"
}
## 存title与rate
title_list = []
rate_list = []
## 循环获取页面
for start_num in range(0,250,25):
response = requests.get(f'https://movie.douban.com/top250/?start={start_num}', headers = headers)
html = response.text
soup = BeautifulSoup(html,'html.parser')
all_title = soup.findAll("span",attrs={'class':'title'}) # 找到所有title
all_rate = soup.findAll("span",attrs={'class':'rating_num'}) #找到所有rate
for title in all_title:
title_string = title.string
if "/" not in title_string: #去除有/的title
title_list.append(title_string)
# print("top",num,"\t :\t ",title_string)
for rate in all_rate:
rate_string = rate.string
rate_list.append(rate_string)
# print(title_list)
# print(rate_list)
# 存入csv
df = pd.DataFrame({'标题':title_list,'评分':rate_list})
df.to_csv('./Douban_top250.csv',encoding='utf-8')
print("总计", len(title_list), "条记录存入csv文件中")
time_end = time.time() # 记录结束时间
time_sum = time_end - time_start # 计算的时间差为程序的执行时间,单位为秒/s
print("程序运行时间",time_sum,'s')
输出
总计 250 条记录存入csv文件中
程序运行时间 3.1357240676879883 s
Douban_top250.csv 内容如下:

进一步
正则表达式
多线程爬虫