python自动化办公——定制化读取Excel数据并写入到word表格
Python自动化办公——Excel写word表格
文章目录
- Python自动化办公——Excel写word表格
-
- 一、引言
- 二、数据准备
- 三、python代码
-
- 1、方法一
- 2、方法二
- 3、方法三
一、引言
最近到了毕业设计答辩的时候,老师让我帮毕业生写一段毕业设计的功能就是提供一个学士学位授予申请表,根据定制化需求,编写定制化代码。
二、数据准备
docx格式的word如下图。
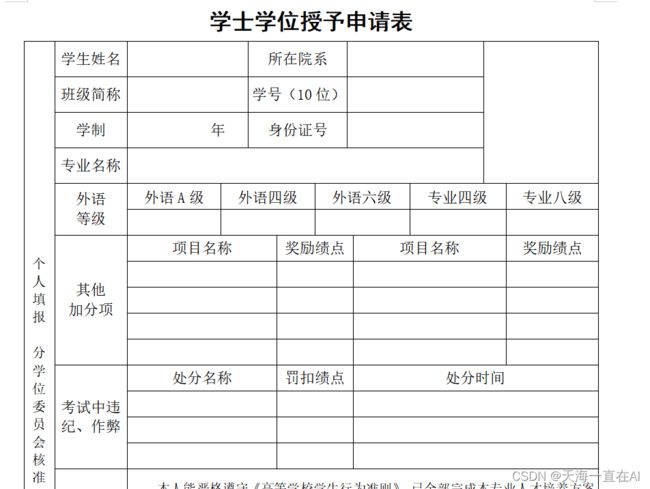
再提供一个Excel表格,要求可以直接读取表格里的对应内容,填入到word表格里的对应位置。表格是我自己定义的如下表:
| 学生姓名 | 所在院系 | 班级简称 | 学号(10位) | 学制 | 身份证号 | 专业名称 | 外语A级 | 外语四级 | 外语六级 | 专业四级 | 专业八级 | 项目名称1 | 项目名称2 | 项目名称3 | 项目名称4 | 项目名称5 | 项目名称6 | 项目名称7 | 项目名称8 | 奖励绩点1 | 奖励绩点2 | 奖励绩点3 | 奖励绩点4 | 奖励绩点5 | 奖励绩点6 | 奖励绩点7 | 奖励绩点8 | 处分名称1 | 处分名称2 | 处分名称3 | 罚扣绩点1 | 罚扣绩点2 | 罚扣绩点3 | 处分时间1 | 处分时间2 | 处分时间3 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 天海 | 电子与信息工程学院 | 智能BG201 | 744411115555 | 4 | 52013145555 | 人工智能 | √ | √ | √ | 智慧农业可视化 | 计算机视觉教辅 | 计赛国家一等奖 | 互联网+省二等奖 | 0.2 | 0.2 | 0.4 | 0.1 | 偷吃老师抽屉的饼干 | 撒谎的人要吞一千根针哦 | 0.1 | 0.9 | 2023年6年15日 | 2022年12月14日 |
三、python代码
那么根据定制化需求,我制作了三套代码。
1、方法一
我们的逻辑是:
- 读取Excel文件
- 找准word中表格对应位置与顺序
- 插入读取到Excel中的数据到word表格中
先展示最终嵌入到项目中的代码吧.
首先需要引入docx的库和pandas库,注意由于docx库的版本不同使用的方法也有一定差异
import docx
from docx.enum.text import WD_ALIGN_PARAGRAPH
import pandas as pd
接下来进行第一步,读取表格数据,并打开word
#打开或创建word文档
doc_name = "test.docx"
doc = docx.Document(doc_name)
# 读取Excel数据
df = pd.read_excel('source.xlsx', sheet_name='info')
content = [list(row) for _, row in df.iterrows()]
print(content)
人为分析了word的表格索引位置,并写入index中
table = doc.tables[0]
index = [[0,3],[0,12],[1,3],[1,12],[2,3],[2,12],[5,3],
[5,5],[5,10],[5,13],[5,16],[7,7],[7,16],[8,7],[8,16],
[9,7],[9,16],[10,7],[10,16],[12,3],[12,7],[12,11],
[13,3],[13,7],[13,11],[14,3],[14,7],[14,11]]
写入28条数据并将空的数据输入空格,设置居中和宋体字体,随后将输出的word保存为学号+.docx
for i in range(0,28):
cell = table.cell(index[i][0],index[i][1])
cell.text = str(content[0][i])
if cell.text == 'nan':
cell.text = ' '
print('%d:'%i,cell.text)
cell.paragraphs[0].alignment = WD_ALIGN_PARAGRAPH.CENTER
for par in cell.paragraphs:
for run in par.runs:
run.font.size = docx.shared.Pt(12)
run.font.name = '宋体'
filename = str(df.iloc[0, 3])
doc.save(filename + '.docx')
完整代码如下:
import docx
from docx.enum.text import WD_ALIGN_PARAGRAPH
import pandas as pd
#打开或创建word文档
doc_name = "test.docx"
doc = docx.Document(doc_name)
# 读取Excel数据
df = pd.read_excel('source.xlsx', sheet_name='info')
content = [list(row) for _, row in df.iterrows()]
print(content)
table = doc.tables[0]
index = [[0,3],[0,12],[1,3],[1,12],[2,3],[2,12],[5,3],
[5,5],[5,10],[5,13],[5,16],[7,7],[7,16],[8,7],[8,16],
[9,7],[9,16],[10,7],[10,16],[12,3],[12,7],[12,11],
[13,3],[13,7],[13,11],[14,3],[14,7],[14,11]]
for i in range(0,28):
cell = table.cell(index[i][0],index[i][1])
cell.text = str(content[0][i])
if cell.text == 'nan':
cell.text = ' '
print('%d:'%i,cell.text)
cell.paragraphs[0].alignment = WD_ALIGN_PARAGRAPH.CENTER
for par in cell.paragraphs:
for run in par.runs:
run.font.size = docx.shared.Pt(12)
run.font.name = '宋体'
filename = str(df.iloc[0, 3])
doc.save(filename + '.docx')
2、方法二
使用的方法二就是精简版的方法一,原理就是不考虑word表格分布写入数据,而是自己在代码里写一个新的word表格进行插入数据。
具体步骤如下:
- 读取Excel数据
- 生成、配置word的表格和名称
- 填写表格
- 保存word
代码如下:
这里我就是定义了两个循环来生成简单的37行2列的表格并填写数据
import pandas as pd
from docx import Document
from docx.shared import Inches
# 读取Excel数据
df = pd.read_excel('source.xlsx', sheet_name='info')
# 获取表格标题和内容
header = list(df.columns)
content = [list(row) for _, row in df.iterrows()]
# 生成Word文件名
filename = df.iloc[0, 3]
# 配置Word
document = Document('output.docx')
table = document.add_table(rows=37, cols=2, style='Table Grid')
# 填写表格
for i, text in enumerate(header):
table.cell(i, 0).text = text
for i, row in enumerate(content):
for j, text in enumerate(row):
table.cell(j, i+1).text = str(text)
# 保存Word文件
document.save(f'{filename}.docx')
3、方法三
使用字符串匹配来进行变量的写入,缺点:无法进行表格写入,可以在无表格的word文章中发挥很大优势。
可以使用pyqt5来制作一个小工具进行文字替换。这里我也实现了,但由于代码量过大,这里不做介绍啦,有需要的可以私信我,再进行更新。
