【读点论文】RTMDet: An Empirical Study of DesigningReal-TimeObjectDetectors.2023年的YOLOv4,很强的工程经验,让智能走出实验室
RTMDet: An Empirical Study of Designing Real-Time Object Detectors
Abstract
-
在本文中的目标是设计一个高效的实时目标检测器,它超越了YOLO系列(yolov8,yolo-nas没比较),并且易于扩展到许多目标识别任务,如实例分割和旋转目标检测。为了获得更有效的模型架构,探索了一种在主干和颈部具有兼容能力的架构,该架构由由大核深度卷积组成的基本构建块构建。在动态标签分配中,进一步在计算匹配代价时引入软标签,以提高准确性。结合更好的训练技术,最终的目标检测器RTMDet在NVIDIA 3090 GPU上实现了52.8%的AP和300+ FPS,优于目前主流的工业检测器。
-
RTMDet在各种应用场景中实现了微型/小型/中型/大型/超大模型尺寸的最佳参数精度权衡,并在实时实例分割和旋转目标检测方面获得了最新的性能。希望实验结果可以为设计多用途实时目标检测器提供新的见解,用于许多目标识别任务。
-
代码和模型发布在 mmdetection/configs/rtmdet at 3.x · open-mmlab/mmdetection · GitHub 。
-
官方开源地址: https://github.com/open-mmlab/mmdetection/blob/3.x/configs/rtmdet/README.md
-
论文地址:[2212.07784] RTMDet: An Empirical Study of Designing Real-Time Object Detectors (arxiv.org)
-
openmmlabB站视频讲解:【OpenMMLab 2.0 系列直播】RTMDet_哔哩哔哩_bilibili
-
在调研了当前 YOLO 系列的诸多改进模型后,MMDetection 核心开发者针对这些设计以及训练方式进行了经验性的总结,并进行了优化,推出了高精度、低延时的单阶段目标检测器 RTMDet, Real-time Models for Object Detection (Release to Manufacture)。随着新技术(训练,推理,数据增强,损失函数设计,模块设计,模型配置思路)的出现,还会有新的“RTMDet”。
Introduction
-
最优的效率一直是目标检测的首要追求,特别是在自动驾驶、机器人和无人机的现实世界感知中。为了实现这一目标,YOLO系列探索了不同的模型架构和训练技术,以不断提高一级目标检测器的精度和效率。
-
在本报告中,本文的目标是推动YOLO系列的极限,并为目标检测提供一个新的实时模型系列,名为RTMDet,它还能够进行实例分割和旋转目标检测,这是以前的工作没有探索过的。吸引人的改进主要来自大核深度卷积的更好表示和动态标签分配中软标签的更好优化。
-
具体来说,首先在模型的主干和颈部的基本构建块中利用大核深度卷积,这提高了模型捕获全局上下文的能力。由于直接在构建块中放置深度卷积会增加模型深度从而减慢推理速度,因此进一步减少构建块的数量以减少模型深度并通过增加模型宽度来补偿模型容量。还观察到,在颈部添加更多的参数并使其容量与骨干兼容可以实现更好的速度精度权衡。模型架构的整体修改使得RTMDet的推理速度更快,而不依赖于模型的重新参数化。
-
进一步重新审视训练策略以提高模型的准确性。除了更好地结合数据增强、优化和训练计划外,还通过经验发现,在匹配ground truth boxes和模型预测时,通过引入软目标而不是硬标签,可以进一步改进现有的动态标签分配策略。这样的设计提高了成本矩阵的判别性,实现了高质量的匹配,同时也降低了标签分配的噪声,从而提高了模型的精度。
-
RTMDet是通用的,可以很容易地扩展到实例分割和旋转对象检测,几乎没有修改。通过简单地添加一个内核和一个掩码特征生成头[Sparse instance activation for real-time instance segmentation,Conditional convolutions for instance segmentation],RTMDet只需要大约10%的额外参数就可以执行实例分割。对于旋转对象检测,RTMDet只需要扩展盒回归层的维度(从4到5),并切换到旋转盒解码器。还观察到,在一般目标检测数据集上的预训练有利于空中场景下的旋转目标检测。
-
进行了大量的实验来验证RTMDet的有效性,并按比例缩放模型尺寸,为各种应用场景提供微型/小型/中型/大型/超大型模型。如下图所示,RTMDet比以往的方法实现了更好的参数-精度权衡,性能优于以往的模型[3,21,25,65]。具体来说,RTMDet-tiny在1020 FPS下,仅用4.8M参数就实现了41.1%的AP。rtmdet - 5的AP率为44.6%,FPS率为819,超过了之前最先进的小型机型。当扩展到实例分割和旋转对象检测时,RTMDet在两个基准测试的实时场景中都获得了新的最先进的性能,在COCO val集上,180 FPS下的掩码AP为44.6%,在DOTA v1.0上,AP为81.33%。
-

-
参数与精度的比较。(a) RTMDet与其他最先进的实时物体探测器的比较。(b) RTMDet-Ins与其他单阶段实例分割方法的比较。
-
-
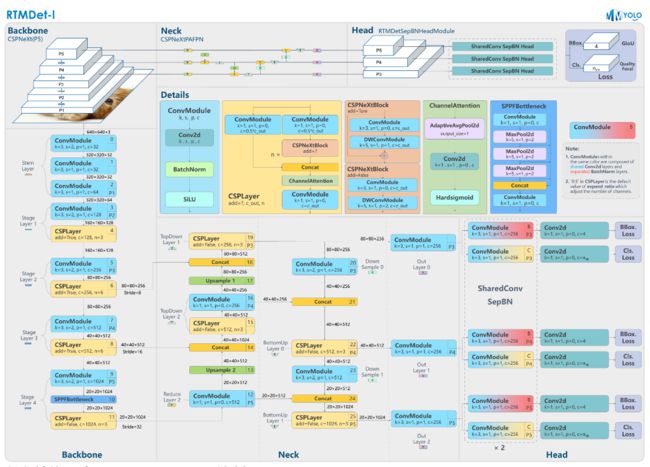
实现的目标是高性能,低延时的单阶段目标检测器RTMDet 原理和实现全解析 — MMYOLO 0.5.0 文档。下图由 RangeKing@github 绘制。
-
RTMDet 采用了多种数据增强的方式来增加模型的性能,主要包括单图数据增强和混合类数据增强:
-
RandomResize 随机尺度变换;
-
RandomCrop 随机裁剪;
-
HSVRandomAug 颜色空间增强;
-
RandomFlip 随机水平翻转。
-
Mosaic 马赛克
-
MixUp 图像混合
-
-
数据增强流程如下:
-

-
其中 RandomResize 超参在大模型 M,L,X 和小模型 S, Tiny 上是不一样的,大模型由于参数较多,可以使用 large scale jitter 策略即参数为 (0.1,2.0),而小模型采用 stand scale jitter 策略即 (0.5, 2.0) 策略。下面将具体介绍混合类数据增强的具体实现。
-
与 YOLOv5 不同的是,YOLOv5 认为在 S 和 Nano 模型上使用 MixUp 是过剩的,小模型不需要这么强的数据增强。而 RTMDet 在 S 和 Tiny 上也使用了 MixUp,这是因为 RTMDet 在最后 20 epoch 会切换为正常的 aug, 并通过训练证明这个操作是有效的。 并且 RTMDet 为混合类数据增强引入了 Cache 方案,有效地减少了图像处理的时间, 和引入了可调超参
max_cached_images,当使用较小的 cache 时,其效果类似repeated augmentation。
-
-
Mosaic&MixUp 涉及到多张图片的混合,它们的耗时会是普通数据增强的 K 倍(K 为混入图片的数量)。 如在 YOLOv5 中,每次做 Mosaic 时, 4 张图片的信息都需要从硬盘中重新加载。 而 RTMDet 只需要重新载入当前的一张图片,其余参与混合增强的图片则从缓存队列中获取,通过牺牲一定内存空间的方式大幅提升了效率。 另外通过调整 cache 的大小以及 pop 的方式,也可以调整增强的强度。
-

-
cache 队列中预先储存了 N 张已加载的图像与标签数据,每一个训练 step 中只需加载一张新的图片及其标签数据并更新到 cache 队列中(cache 队列中的图像可重复,如图中出现两次 img3),同时如果 cache 队列长度超过预设长度,则随机 pop 一张图(为了 Tiny 模型训练更稳定,在 Tiny 模型中不采用随机 pop 的方式, 而是移除最先加入的图片),当需要进行混合数据增强时,只需要从 cache 中随机选择需要的图像进行拼接等处理,而不需要全部从硬盘中加载,节省了图像加载的时间。
-
cache 队列的最大长度 N 为可调整参数,根据经验性的原则,当为每一张需要混合的图片提供十个缓存时,可以认为提供了足够的随机性,而 Mosaic 增强是四张图混合,因此 cache 数量默认 N=40, 同理 MixUp 的 cache 数量默认为20, tiny 模型需要更稳定的训练条件,因此其 cache 数量也为其余规格模型的一半( MixUp 为10,Mosaic 为20)。
-
Related Work
-
目标检测的高效神经结构。目标检测的目的是识别和定位场景中的目标。对于实时应用,现有工作主要探索基于锚的[Focal loss for dense object detection,SSD,yolov2]或无锚的[FCOS,Objects as points]一级检测器,而不是两级检测器[ Cascade R-CNN,Fast R-CNN,Libra R-CNN,Faster R-CNN]。为了提高模型效率,通过手工设计或神经结构搜索[DetNAS,SpineNet,NAS-FPN,NAS-FCOS],探索了高效的骨干网络和模型缩放策略[YOLOv4,Yolov7]以及多尺度特征的增强[Feature pyramid grids,NAS-FPN,GiraffeDet,Feature pyramid networks for object detection,Path aggregation network for instance segmentation,EfficientDet]。最近的进展还探讨了模型的重新参数化[RepVGG,Yolov6,Yolov7,PP-YOLOE],以提高模型部署后的推理速度。在本文中,提供了一个在主干和颈部具有兼容能力的整体架构,该架构由一个具有大核深度卷积的新基本构建块构建,以实现更高效的目标检测器。
-
用于目标检测的标签分配。改进目标检测器的另一个方面是标签分配和训练损失的设计。先锋方法[Cascade R-CNN,Focal loss,SSD,Faster R-CNN]使用IoU作为匹配标准,在标签分配中将地面真值盒与模型预测或锚点进行比较。后来的实践[37,FCOS,Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection,Objects as points]进一步探索了不同的匹配标准,如对象中心[FCOS,Objects as points]。还探索了辅助探测头[Probabilistic anchor assignment with iou prediction for object detection,Yolov7],以加快和稳定训练。受端到端目标检测的匈牙利分配[DETR]的启发,动态标签分配[TOOD,Ota,YOLOX]被探索,显著提高了收敛速度和模型精度。与这些使用与损失完全相同的匹配代价函数的策略不同,建议在计算匹配代价时使用软标签来扩大高质量和低质量匹配之间的区别,从而稳定训练并加速收敛。
-
实例分割。实例分割旨在预测每个感兴趣对象的逐像素掩码。先进的方法探索了不同的范式来解决这一任务,包括掩模分类[Learning to segment object candidates,Learning to refine object segments.],“自上而下”[Hybrid task cascade for instance segmentation,Mask R-CNN]和“自下而上”方法[Deep watershed transform for instance segmentation,Instancecut,Instance segmentation by jointly optimizing spatial embeddings and clustering bandwidth]。最近的尝试在一个阶段执行实例分割或没有边界框。这些尝试的代表是基于动态核,它学习从学习参数或密集特征映射中生成动态核,并使用它们与掩模特征映射进行卷积。受这些工作的启发,通过内核预测和掩码特征头来扩展RTMDet来进行实例分割。
-
旋转对象检测。旋转物体检测的目的是除了物体的位置和类别之外,进一步预测物体的方向。在现有的通用目标检测器(如RetinaNet或Faster R-CNN)的基础上,提出了不同的特征提取网络来缓解物体旋转引起的特征不对齐。还有各种旋转框的表示(例如,高斯分布和凸集)来缓解旋转边界框回归任务。与这些方法正交,本文仅对一般目标检测器进行了最小修改(即增加角度预测分支,用旋转IoU loss代替GIoU损失)的扩展,并揭示了高精度一般目标检测器通过模型架构和在一般检测数据集上学习的知识为高精度旋转目标检测铺平了道路。
Methodology
- 在这项工作中,本文建立了一个新的实时对象检测模型家族,称为RTMDet。RTMDet的宏架构是一个典型的单阶段对象检测器。本文通过在主干和颈部的基本构建块中探索大核卷积来提高模型效率,并相应地平衡模型的深度、宽度和分辨率。进一步探索了动态标签分配策略中的软标签,以及更好地结合数据增强和优化策略来提高模型精度。RTMDet是一个通用的目标识别框架,可以扩展到实例分割和旋转目标检测任务,修改很少。
Macro Architecture
-
本文将单阶段目标检测器的宏观架构分解为主干、颈部和头部,如下图所示。YOLO系列的最新进展[YOLOv4,YOLOX]通常采用CSPDarkNet作为骨干架构,该架构包含四个阶段,每个阶段都堆叠了几个基本构建块。颈部从骨干提取多尺度特征金字塔,使用与骨干相同的基本构件,自下而上和自上而下的特征传播来增强金字塔特征图。最后,检测头根据每个尺度的特征映射预测目标边界框及其类别。这种架构通常适用于一般和旋转对象,并且可以通过内核和掩码特征生成头扩展到实例分割。
-

-
宏观的架构。使用具有大内核深度卷积层的CSP-blocks来构建主干。从骨干网络中提取C3、C4、C5等多层特征,融合到与骨干网络组成相同块的CSP-PAFPN中。然后,使用具有共享卷积权值和分离批归一化(BN)层的检测头来预测(旋转)边界盒检测的分类和回归结果。可以添加额外的头来为实例分割任务生成动态卷积核和掩码特征。
-
-
为了充分利用宏观体系结构的潜力,本文首先研究更强大的基本构建块。然后研究了结构上的计算瓶颈,平衡了主干和颈部的深度、宽度和分辨率。
-
RTMDet 模型整体结构和 YOLOX 几乎一致,由
CSPNeXt+CSPNeXtPAFPN+共享卷积权重但分别计算 BN 的 SepBNHead构成。内部核心模块也是CSPLayer,但对其中的Basic Block进行了改进,提出了CSPNeXt Block。 -
CSPNeXt整体以CSPDarknet为基础,共 5 层结构,包含 1 个Stem Layer和 4 个Stage Layer:-
Stem Layer是 3 层 3x3 kernel 的ConvModule,不同于之前的Focus模块或者 1 层 6x6 kernel 的ConvModule。 -
Stage Layer总体结构与已有模型类似,前 3 个Stage Layer由 1 个ConvModule和 1 个CSPLayer组成。第 4 个Stage Layer在ConvModule和CSPLayer中间增加了SPPF模块(MMDetection 版本为SPP模块)。 -
如模型图 Details 部分所示,
CSPLayer由 3 个ConvModule+ n 个CSPNeXt Block(带残差连接) + 1 个Channel Attention模块组成。ConvModule为 1 层 3x3Conv2d+BatchNorm+SiLU激活函数。Channel Attention模块为 1 层AdaptiveAvgPool2d+ 1 层 1x1Conv2d+Hardsigmoid激活函数。
-
Model Architecture
-
基本构建块。骨干中较大的有效接受野有利于对象检测和分割等密集预测任务,因为它有助于更全面地捕获和建模图像上下文。然而,之前的尝试(例如,扩展卷积和非局部块)计算成本很高,限制了它们在实时目标检测中的实际应用。最近的研究[Scaling up your kernels to 31x31,A convnet for the 2020s]重新审视了大核卷积的使用,表明可以通过深度卷积以合理的计算成本扩大接受场。受这些发现的启发,在CSPDarkNet的基本构建块中引入5×5深度卷积,以增加有效的接受场(见下图b)。这种方法允许更全面的上下文建模,并显著提高准确性。
-

-
不同的基本构建模块。(a)DarkNet基本瓶颈块。(b)采用大核深度卷积层的瓶颈块。©使用重新参数化卷积的PPYOLO-E的瓶颈块。(d) YOLOv6的基本单位。
-
Darknet (图 a)使用 1x1 与 3x3 卷积的
Basic Block。YOLOv6 、YOLOv7 、PPYOLO-E (图 b & c)使用了重参数化 Block。但重参数化的训练代价高,且不易量化,需要其他方式来弥补量化误差。 RTMDet 则借鉴了最近比较热门的 ConvNeXt 、RepLKNet 的做法,为Basic Block加入了大 kernel 的depth-wise卷积(图 d),并将其命名为CSPNeXt Block。
-
-
值得注意的是,最近的一些实时目标检测器在基本构建块中探索了重新参数化的3×3卷积(上图.c&d)。虽然重新参数化的3×3卷积被认为是在推理过程中提高准确性的免费增益,但它也带来了副作用,例如较慢的训练速度和增加的训练内存。它还增加了模型量化到较低位后的误差间隙,需要通过重新参数化优化器和量化感知训练进行补偿。与重新参数化3×3卷积相比,大核深度卷积是一种更简单、更有效的基本构建块选择,因为它们需要更少的训练成本,并且在模型量化后产生更小的误差。
-
模型宽度和深度的平衡。在大核深度卷积之后,由于额外的点向卷积,基本块中的层数也增加了(上图.b)。这阻碍了每层的并行计算,从而降低了推理速度。为了解决这个问题,本文减少了每个骨干阶段的块数量,并适度扩大了块的宽度,以增加并行化并保持模型容量,最终在不牺牲精度的情况下提高了推理速度。
-
主干网络和颈部的平衡。多尺度特征金字塔是检测不同尺度目标的关键。为了增强多尺度特征,以前的方法要么使用更大的骨干和更多的参数,要么使用更重的颈部[GiraffeDet,EfficientDet],更多的特征金字塔之间的连接和融合。然而,这些尝试也增加了计算和内存占用。因此,本文采用另一种策略,通过增加颈部基本块的扩展比,将更多的参数和计算量从骨干转移到颈部,使它们具有相似的容量,从而获得更好的计算精度权衡。
-
共享检测头。实时目标检测器通常针对不同的特征尺度使用单独的检测头,以增强模型的能力以获得更高的性能,而不是在多个尺度上共享一个检测头[Focal loss for dense object detection,FCOS]。在本文中,比较了不同的设计选择,并选择跨尺度共享检测头参数,但采用不同的批归一化(Batch Normalization, BN)层,以减少检测头的参数量,同时保持精度。BN也比其他归一化层(如Group normalization)更有效,因为在推理中它直接使用了训练中计算的统计量。
Training Strategy
-
标签分配和损失。为了训练单阶段目标检测器,每个尺度的密集预测将通过不同的标签分配策略与GT值边界框进行匹配。最近的进展通常采用动态标签分配策略[DETR,Ota,YOLOX],使用与训练损失一致的成本函数作为匹配标准。然而,发现它们的成本计算有一定的局限性。因此,本文提出了一种基于SimOTA的动态软标签分配策略,其成本函数表示为:
- C = λ 1 C c l s + λ 2 C r e g + λ 3 C c e n t e r , ( 1 ) C=\lambda_1C_{cls}+\lambda_2C_{reg}+\lambda_3C_{center},(1) C=λ1Ccls+λ2Creg+λ3Ccenter,(1)
- 其中 C c l s C_{cls} Ccls、 C c e n t e r C_{center} Ccenter和 C r e g C_{reg} Creg分别对应分类代价、区域先验代价和回归代价,λ1 = 1、λ2 = 3、λ3 = 1是这三个代价默认的权值。这三项loss的计算说明如下。以前的方法通常使用二元标签来计算分类成本 C c l s C_{cls} Ccls,这种方法允许使用高分类分数但不正确的边界框来实现低分类成本的预测,反之亦然。为了解决这个问题,在Ccls中引入了软标签
- C c l s = C E ( P , Y s o f t ) ∗ ( Y s o f t − P ) 2 , ( 2 ) C_{cls}=CE(P,Y_{soft})*(Y_{soft}-P)^2,(2) Ccls=CE(P,Ysoft)∗(Ysoft−P)2,(2)
- 这种修改受到GFL的启发,GFL使用预测框和真实框之间的IoU作为软标签yst来训练分类分支。分配中的软分类代价不仅对不同回归质量的匹配代价进行了重新加权,而且避免了二元标签带来的噪声和不稳定匹配。
-
当使用广义IoU作为回归代价时,最佳匹配与最差匹配的最大差值小于1。这使得很难区分高质量的匹配和低质量的匹配。为了使不同gt -预测对的匹配质量更具判别性,使用IoU的对数作为回归成本,而不是在损失函数中使用GIoU,这放大了IoU值较低的匹配成本。回归代价 C r e g C_{reg} Creg的计算公式为
- C r e g = − l o g ( I o U ) , ( 3 ) C_{reg}=-log(IoU),(3) Creg=−log(IoU),(3)
-
对于区域成本Ccenter,使用软中心区域成本代替固定中心先验来稳定动态成本的匹配,如下所示
-
C c e n t e r = α ∣ x p r e d − x g t ∣ − β , ( 4 ) C_{center}=\alpha^{|x_{pred}-x_{gt}|-\beta},(4) Ccenter=α∣xpred−xgt∣−β,(4)
-
其中α和β为软中心区域的超参数。默认设置α = 10, β = 3。
-
-
缓存马赛克和混合。交叉样本增强如MixUp和CutMix在最近的目标检测器中被广泛采用。这些增强功能很强大,但也带来了两个副作用。首先,在每次迭代中,他们需要加载多个图像来生成一个训练样本,这引入了更多的数据加载成本并减慢了训练速度。其次,生成的训练样本是“有噪声的”,可能不属于数据集的真实分布,从而影响模型学习。
-
通过缓存机制改进了MixUp和Mosaic,从而减少了对数据加载的需求。通过使用缓存,可以将训练管道中混合图像的时间成本显著降低到处理单个图像的水平。缓存操作由缓存长度和弹出方法控制。大的缓存长度和随机弹出方法可以看作相当于原始的非缓存的MixUp和Mosaic操作。同时,较小的缓存长度和先进先出(FIFO)弹出方法可以看作类似于重复增强,允许在相同或连续批次中混合使用不同数据增强操作的同一图像。
-
两级训练。为了通过强数据增强来减少“噪声”样本的副作用,YOLOX探索了一种两阶段的训练策略,其中第一阶段使用强数据增强,包括马赛克、MixUp和随机旋转和剪切,第二阶段使用弱数据增强,如随机调整大小和翻转。由于初始训练阶段的强增强包括随机旋转和剪切,这会导致输入与转换后的框注释之间的不对齐,YOLOX在第二阶段添加L1损失来微调回归分支。为了解耦数据增强和损失函数的使用,排除了这些数据增强,并在280个epoch的第一个训练阶段将每个训练样本中的混合图像数量增加到8个,以补偿数据增强的强度。在最后的20个epoch中,切换到Large Scale Jittering (LSJ),允许在更接近真实数据分布的域中对模型进行微调。为了进一步稳定训练,采用AdamW作为优化器,它在卷积目标检测器中很少使用,但在视觉transformer中是默认的。
Extending to other tasks
-
实例分割。本文通过一个简单的修改(表示为RTMDet- ins)来启用RTMDet实例分割。如下图所示,在RTMDet的基础上,增加了一个分支,由一个核预测头和一个掩码特征头组成,类似于CondInst。掩码特征头包括4个卷积层,从多级特征中提取8个通道的掩码特征。核预测头为每个实例预测一个169维的向量,并将其分解为三个动态卷积核,通过与掩码特征和坐标特征交互生成实例分割掩码。为了进一步挖掘蒙版标注中固有的先验信息,本文在计算动态标签分配中的软区域先验时使用蒙版的质量中心而不是框中心。使用dice loss作为遵循典型惯例的实例掩码的监督。
-

-
实例分割分支在RTMDet-Ins。掩膜特征头有4个卷积层,从颈部提取的多级特征中预测8个通道的掩膜特征。两个相对坐标特征与掩码特征相连接以生成实例掩码。内核头为每个实例预测一个169维的向量。向量被分成三部分(长度分别为88、72和9),用来形成三个动态卷积层的核。
-
-
旋转对象检测。由于旋转目标检测与一般(水平)目标检测之间的内在相似性,RTMDet适应旋转目标检测器只需要3个步骤,即RTMDet- r:
-
(1)在回归分支处添加1×1卷积层来预测旋转角度;
-
(2)修改边界框编码器以支持旋转框;
-
(3)将GIoU损失替换为旋转IoU损失。
-
-
RTMDet高度优化的模型架构保证了RTMDet- r在旋转目标检测任务上的高性能。此外,由于RTMDetR具有RTMDet的大部分参数,因此在一般检测数据集(如COCO数据集)上预训练的RTMDet模型权值可以作为旋转目标检测的良好初始化。
Experiments
Implementation Details
-
目标检测和实例分割。在COCO数据集上进行实验,其中train2017集包含约118K张图像,val2017集包含约5K张图像,分别用于训练和验证。对于消融研究,在train2017集上训练了300个epoch的模型,并在val2017集上进行了验证。超参数如下表所示。所有的目标检测和实例分割模型都是在8个NVIDIA A100 gpu上训练的。分别通过bbox AP和mask AP评估了模型在目标检测和实例分割方面的性能。
-

-
训练对象检测,实例分割和旋转对象检测的设置。
-
-
在进行对象检测测试时,在非极大抑制(NMS)之前,将过滤边界框的得分阈值设置为0.001,保留前300个框进行验证。为了公平比较,这一设置与以往的研究一致。然而,为了加速消融研究中的度量计算,将评分阈值设置为0.05,保留结果的数量设置为100,这可能会使准确性降低约0.3% AP
-
旋转对象检测。在DOTA数据集上进行了实验,该数据集包含2.8K航空图像和188K实例,这些数据来自不同分辨率的不同传感器。超参数如表1所示。对于单尺度训练和测试,将原始图像裁剪成1024×1024块,重叠256像素。对于多尺度训练和测试,将原始图像按0.5、1.0和1.5的比例调整大小,然后裁剪成重叠500像素的1024×1024块。除了大型模型使用2个NVIDIA V100 GPU外,大多数旋转目标检测器都使用1个NVIDIA V100 GPU进行训练。对于评价指标,采用与PASCAL VOC2007相同的mAP计算方法,但使用旋转IoU来计算匹配对象。
-
指标设置。所有模型的延迟都是在NVIDIA 3090 GPU上使用TensorRT 8.4.3和cuDNN 8.2.0在半精度浮点格式(FP16)下测试的。推理批大小为1。
Benchmark Results
-
对象检测。将RTMDet与之前的实时目标检测器进行了比较,包括YOLOv5、YOLOX、YOLOv6、YOLOv7和PPY OLOE。为了公平比较,所有模型都是在300个epoch上进行训练,没有进行蒸馏和修剪,并且延迟计算中不包括非最大抑制(NMS)的时间。
-
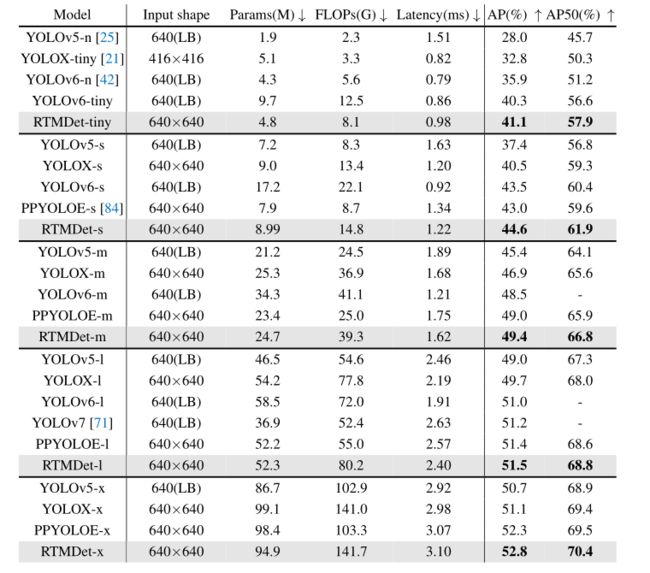
如下表和下图 (a)所示,RTMDet比以前的方法实现了更好的参数-精度权衡。RTMDet-tiny仅用480万个参数就实现了41.1%的AP,比其他类似尺寸的模型高出5%以上的AP。RTMDet-s具有更高的精度,其参数和计算成本仅为YOLOv6s的一半。RTMDet-m和RTMDet-l在类似的类模型中也取得了优异的成绩,AP分别为44.6%和49.4%。RTMDet-x的AP率为52.8%,FPS为300+,优于当前主流检测器。值得注意的是,YOLOv5和YOLOv7在数据增强后都使用掩码注释来细化边界框,从而获得了约0.3%的AP增益。在不依赖于框注释之外的额外信息的情况下获得了更好的结果。
-
-
RTMDet与以前在参数数量、FLOPS、延迟和准确度方面的比较。为了公平的比较,所有的模型都训练了300个epoch,而不使用额外的检测数据或知识蒸馏。在相同的环境下测量了所有模型的推理速度。(LB)表示中提出的LetterBox调整大小。提出的RTMDet的结果用灰色标记。最好的结果是加粗的。
-

-
参数与精度的比较。(a) RTMDet与其他最先进的实时物体探测器的比较。(b) RTMDet-Ins与其他单阶段实例分割方法的比较。
-
-
实例分割。为了评估本文的标签分配策略和损失的优越性,首先将RTMDet-Ins与使用标准ResNet50-FPN骨干和经典多尺度3x调度的传统方法进行了比较。为了更快的收敛速度和与CondInst的公平比较,采用了辅助的语义分割头。RTMDet比CondInst的性能高出1.5% mask AP(下表中的第一行)。然而,在从头开始训练RTMDet时,不使用语义分割分支,因为辅助分支带来了边际改进。
-

-
RTMDet-Ins与以往实例分割方法在参数数量、FLOPS、延迟和准确度方面的比较。(LB)表示中提出的LetterBox调整大小。建议的rtmdet - in的结果用灰色标记。最好的结果是大胆的。与目标检测模型不同,速度测量中包含箱体NMS和前100位掩码的后处理
-
-
最后,使用与RTMDet相同的数据增强和优化超参数,在COCO数据集上训练了300个epoch的RTMDet- ins tiny/s/m/l/x。RTMDet-Ins-x达到44.6%掩码AP,比之前的最佳实践YOLOv5-seg-x高出3.2% AP,并且仍然实时运行(上表第二行)。
-
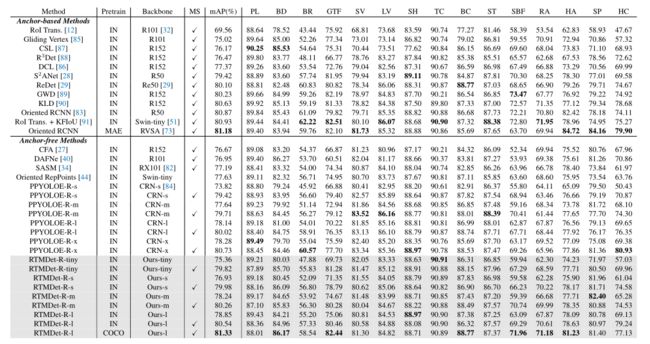
旋转对象检测。将RTMDet-R与DOTA v1.0数据集上的先前技术状态进行比较,如下表所示。在单尺度训练和测试的情况下,RTMDet-R-m和RTMDet-R-l的mAP分别达到78.24%和78.85%,优于之前几乎所有的方法。通过多尺度训练和测试,RTMDet-R-m和RTMDet-R-l的mAP分别达到80.26%和80.54%。此外,rtmdet - r - 1 (COCO预训练)在DOTA-v1.0数据集上创造了新的记录(81.33% mAP)。通过更简单的修改,RTMDet-R在所有模型大小的情况下也始终优于PPYOLOE-R。注意,RTMDet-R避免在体系结构中使用特殊操作符来实现高精度,这使得它可以很容易地部署在各种硬件上。还在附录中的HRSC2016和DOTA-v1.5数据集上,将RTMDet-R与其他方法进行了比较,RTMDet-R也取得了更优的性能。
-
-
在DOTA-v1.0测试集上,rtmdt - r与以前的旋转目标检测方法在参数数量、FLOPs、延迟和精度方面的比较IN和COCO分别表示ImageNet预训练和COCO预训练。MAE是指在MillionAID上进行的MAE无监督预训练。R50和X50表示ResNet-50和ResNeXt-50 (R101, R152和X101也是如此)。Re50表示reesnet -50, RVSA表示RVSA- vitae - b, CRN表示CSPRepResNet。MS意味着多尺度的训练和测试。DOTA-v1.0有15个不同的对象类别:飞机(PL)、棒球场(BD)、桥梁(BR)、田径场(GTF)、小型车辆(SV)、大型车辆(LV)、船舶(SH)、网球场(TC)、篮球场(BC)、储油罐(ST)、足球场(SBF)、环形交叉路口(RA)、港口(HA)、游泳池(SP)、直升机(HC)。列出了每个类别的AP。粗体表示最佳性能。提出的RTMDet-R的结果用灰色标记。
-
Ablation Study of Model Arhitecture
-
大内核很重要。首先比较了不同内核大小在CSPDarkNet基本构建块中的有效性[3],内核大小范围从3×3到7×7。3×3卷积和5×5内核大小深度卷积的组合实现了最佳的速度精度权衡(下表a)。
-

-
COCO val2017集模型架构的消融研究。本文提出的设置用灰色标记
-
-
多个特征尺度的平衡。使用深度卷积也增加了深度,降低了推理速度。因此,减少了第二和第三阶段的区块数量。如上表b所示,将块数量从9个减少到6个,延迟减少了20%,但准确性降低了0.5% AP。为了弥补这种精度上的损失,在每个阶段的末尾加入了信道注意(CA),实现了更好的速度-精度权衡。具体来说,与在第二和第三阶段使用9个块的检测器相比,准确性降低了0.1% AP,但延迟提高了7%。总的来说,本文的修改成功地减少了探测器的延迟,而没有牺牲太多的精度。
-
主干网络和颈部的平衡。使用与主干相同的基本块来构建颈部。实证研究了在颈部进行更多的计算是否更经济。如上表c所示,在小型和大型实时探测器中,使颈部具有与骨干相似的容量,而不是增加骨干的复杂性,可以实现更快的速度和相似的精度。
-
探测头。在上表d中,比较了多尺度特征下检测头的不同共享策略。结果表明,由于不同特征尺度之间的统计差异,将批处理归一化(Batch Normalization, BN)纳入共享权检测头会导致性能下降。针对不同的特征尺度使用不同的检测头可以解决这个问题,但会显著增加参数数量。对不同的特征尺度使用相同的权重,但不同的BN统计数据产生最佳的参数-精度权衡。
Ablation Study of Training Strategy
-
标签分配。然后,验证了所提出的动态软标签分配策略中每个组件的有效性。按照之前的惯例,使用SimOTA作为基准,并使用与训练损失相同的FocalLoss和GIoU作为代价矩阵。如下表a所示,的基线版本可以在ResNet50上实现39.9%的AP。在分类成本中引入IoU作为软标签,准确率提高0.4% AP,达到40.3% AP。将固定的3×3中心先验替换为软化中心先验,准确率进一步提高到40.8% AP。通过将GIoU成本替换为对数IoU成本,模型得到41.3%的AP。
-

-
COCO val2017集标签赋值的消融研究。建议的设置用灰色标记
-
-
所提出的标签分配策略在相同的模型架构上以相同的损失比其他高性能策略高出0.5% AP(上表b)。当使用更长的训练计划和更强的数据增强训练时,所提出的动态软标签分配以及损失在rtmet -s上超过SimOTA 1.3% AP(上表c)。
-
数据增强。然后,本文在不同的训练阶段研究不同的数据增强组合。第一和第二训练阶段分别为280和20次。当这两个阶段的数据增强量相同时,本质上就形成了一个单阶段训练。在YOLOX之后,Mosaic中对于微型和小型模型的随机调整大小的范围为(0.5,2.0),而对于较大的模型则使用(0.1,2.0)。如下表a所示,在所有阶段使用大规模抖动(largescale jittering, LSJ)比使用MixUp和Mosaic好0.4% AP。当有足够的缓存样本时,缓存的Mosaic和MixUp的效果与原始效果一致。尽管如此,缓存机制将Mosaic和MixUp的速度分别提高了~ 3.6倍和~ 1.5倍(下表b)。
-

-
COCO val2017集数据增强消融研究。本文提出的设置用灰色标记
-
-
在第二阶段使用LSJ而不是Mosaic和MixUp,分别为rtmdet和rtmdet - 1带来2%的AP和1.5%的改进。这表明Mosaic和MixUp是比LSJ更强的增强,但也在训练中引入了更多的噪声,这些噪声应该在第二阶段抛出。还观察到,如果将缓存大小减少到大约10张图像,并应用先进先出(FIFO)弹出方法,则可以在同一批中混合使用具有不同数据增强操作的相同图像,这可能具有与重复增强[2]相似的效果,并且可以略微改善微小和小型模型(大约0.5% AP)。
-
与YOLOX相比,在第一个训练阶段避免了随机旋转和剪切,因为它们会导致框注释与输入之间的不对齐。相反,将每个训练样本中的混合图像数量从5个增加到8个,以保持第一阶段数据增强的强度。总体而言,本文探索的新数据增强组合在不同模型尺寸下均优于YOLOX组合见上表7c。
-
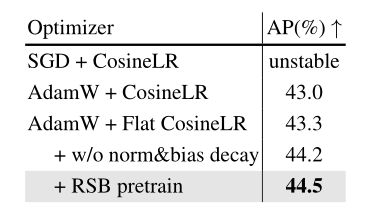
优化策略。最后对优化策略进行了实验。下表的结果表明,在训练中,随着数据的大量增加,SGD会导致不稳定的收敛过程。因此,选择了具有0.05权重衰减的AdamW和余弦退火LR作为本文的基线。为了避免由于余弦退火快速降低学习率而在早期或中期训练过程中过度拟合,采用了一种平坦余弦方法,在训练周期的前半部分使用固定的学习率,然后在后半部分使用余弦退火。这种修改使性能提高了0.3% AP。此外,根据以前的实践,抑制归一化层和偏差上的权重衰减可带来0.9%的AP改善。最后,通过RSB训练策略应用预训练的ImageNet主干可使AP进一步增加0.3%。上述方法协同可显著提高1.5%的AP。
-
-
基于RTMDet-s的优化策略的消融研究。建议的设置用灰色标记
-

-
Step-by-step Results
-
如下表所示,对YOLOX-s进行了连续的修改。通过改进优化策略,模型精度提高了0.4%。新架构具有相似的主干和颈部容量,由具有大核深度卷积的新基本构建块构建,以边际延迟成本将模型精度提高1.2% AP。使用具有共享权重的检测头可以在不影响精度的情况下显著减少参数的数量。随后对标签分配策略和训练损失的改进使性能提高了1.1%。数据增强和骨干预训练的新组合分别使性能提高了1.3%和0.3%。这些修改的协同作用产生了rtmdet - 5,其性能比基线高出4.3%。
-

-
从YOLOX-s基线到RTMDet-s的逐步改进。本文提出的设置用灰色标记
-
Conclusion
- 在本文中,经验和全面地研究了实时目标检测器中的每个关键组件,包括模型架构,标签分配,数据增强和优化。进一步探索高精度实时对象检测器对实时实例分割和旋转对象检测的最小适应性。研究结果产生了一个新的对象检测实时模型家族,名为RTMDet,及其衍生产品,用于不同的对象识别任务。RTMDet在工业级应用程序中展示了精度和速度之间的优越权衡,对于不同的对象识别任务具有不同的模型大小。希望RTMDet可以通过实验结果为未来实时目标识别任务的研究和工业发展铺平道路。
Appendix
Benchmark Results
-
与PPYOLOE-R的比较。进一步对RTMDet-R与PPYOLOE-R进行了详细比较,RTMDet-R在准确率和推理速度上更具竞争力,如下表A1所示。更令人惊讶的是,RTMDet-R-m和rtmdet - r - 1分别比ppyoloe - r - 1和PPYOLOE-R-x快18.5%和20.8%。RTMDet-R的代码和模型在MMRotate上发布。
-

-
RTMDet-R与PPYOLOE-R在参数数量、FLOPs、延迟和精度方面的比较。在相同的环境下测量了所有模型的推理速度。提出的RTMDet-R的结果用灰色标记。最好的结果是加粗的。
-
-
DOTA-v1.5的结果。进一步验证了RTMDet-R在DOTA-v1.5数据集上的有效性。DOTA-v1.5包含与DOTA-v1.0相同的图像,但注释了非常小的实例(小于10像素),添加了215k个实例,这使得它更具挑战性。对于DOTAv1.5数据集,使用4个NVIDIA A100 gpu进行训练。由于发现COCO预训练显著改善了DOTA-v1.5上的结果,所以默认使用COCO预训练。其他设置与DOTA-v1.0一致。如表A2所示,rtmdet - r - 1比之前的最佳方法ReDet高出1.32% mAP。
-

-
与最先进的方法在DOTA v1.5数据集上的比较。MS意味着多尺度的训练和测试。对于DOTA-v1.5数据集,使用4个NVIDIA A100 gpu进行训练。由于发现COCO预训练显著改善了DOTA-v1.5上的结果,所以默认使用COCO预训练。DOTA-v1.5有16个不同的对象类别:飞机(PL)、棒球场(BD)、桥梁(BR)、田径场(GTF)、小型车辆(SV)、大型车辆(LV)、船舶(SH)、网球场(TC)、篮球场(BC)、储油罐(ST)、足球场(SBF)、环岛(RA)、港口(HA)、游泳池(SP)、直升机(HC)和集装箱起重机(CC)。列出了每个类别的AP。粗体表示最佳性能。提出的RTMDet-R的结果用灰色标记。
-
-
HRSC2016结果。还在HRSC2016数据集上验证了RTMDet-R, HRSC2016数据集包含从Google Earth收集的1K张图像和总共2.9K艘船舶。对于HRSC2016数据集,不改变图像的长宽比。对HRSC2016数据集的所有模型进行了108个epoch的训练。其他设置与DOTA-v1.0保持一致。RTMDet-R还获得了新的最先进的性能,实现了90.6%的mAP07(下表A3)。
-

-
基于HRSC2016数据集的最新方法比较。mAP07和mAP12分别以VOC2007和VOC2012指标(%)对结果进行评价。报告这两个结果是为了公平比较。提出的RTMDet-R的结果用灰色标记。提出的RTMDet的结果用灰色标记。最好的结果是加粗的。
-
-
Backbone 与 Neck 之间的参数量和计算量的均衡,EfficientDet 、NASFPN 等工作在改进 Neck 时往往聚焦于如何修改特征融合的方式。 但引入过多的连接会增加检测器的延时,并增加内存开销。所以 RTMDet 选择不引入额外的连接,而是改变 Backbone 与 Neck 间参数量的配比。该配比是通过手动调整 Backbone 和 Neck 的
expand_ratio参数来实现的,其数值在 Backbone 和 Neck 中都为 0.5。expand_ratio实际上是改变CSPLayer中各层通道数的参数(具体可见模型图CSPLayer部分)。如果想进行不同配比的实验,可以通过调整配置文件中的 backbone {expand_ratio} 和 neck {expand_ratio} 参数完成。 -
正负样本匹配策略或者称为标签匹配策略
Label Assignment是目标检测模型训练中最核心的问题之一, 更好的标签匹配策略往往能够使得网络更好学习到物体的特征以提高检测能力。早期的样本标签匹配策略一般都是基于空间以及尺度信息的先验来决定样本的选取。 典型案例如下:-
FCOS中先限定网格中心点在GT内筛选后然后再通过不同特征层限制尺寸来决定正负样本 -
RetinaNet则是通过Anchor与GT的最大IOU匹配来划分正负样本 -
YOLOV5的正负样本则是通过样本的宽高比先筛选一部分, 然后通过位置信息选取GT中心落在的Grid以及临近的两个作为正样本 -
但是上述方法都是属于基于
先验的静态匹配策略, 就是样本的选取方式是根据人的经验规定的。 不会随着网络的优化而进行自动优化选取到更好的样本, 近些年涌现了许多优秀的动态标签匹配策略:-
OTA提出使用Sinkhorn迭代求解匹配中的最优传输问题 -
YOLOX中使用OTA的近似算法SimOTA,TOOD将分类分数以及IOU相乘计算Cost矩阵进行标签匹配等等
-
-
-
这些算法将
预测的 Bboxes 与 GT 的 IOU和分类分数或者是对应分类 Loss和回归 Loss拿来计算Matching Cost矩阵再通过top-k的方式动态决定样本选取以及样本个数。通过这种方式, 在网络优化的过程中会自动选取对分类或者回归更加敏感有效的位置的样本, 它不再只依赖先验的静态的信息, 而是使用当前的预测结果去动态寻找最优的匹配, 只要模型的预测越准确, 匹配算法求得的结果也会更优秀。但是在网络训练的初期, 网络的分类以及回归是随机初始化, 这个时候还是需要先验来约束, 以达到冷启动的效果。 -
RTMDet作者也是采用了动态的SimOTA做法,不过其对动态的正负样本分配策略进行了改进。 之前的动态匹配策略(HungarianAssigner、OTA)往往使用与Loss完全一致的代价函数作为匹配的依据,但经过实验发现这并不一定时最优的。 使用更多Soften的Cost以及先验,能够提升性能。 -
RTMDet 的 BBox Coder 采用的是
mmdet.DistancePointBBoxCoder。编码器将 gt bboxes (x1, y1, x2, y2) 编码为 (top, bottom, left, right),并且解码至原图像上。-
def bbox2distance(points: Tensor, bbox: Tensor, ...) -> Tensor: """ points (Tensor): 相当于 scale 值 stride ,且每个预测点仅为一个正方形 anchor 的 anchor point [x, y],Shape (n, 2) or (b, n, 2). bbox (Tensor): Bbox 为乘上 stride 的网络预测值,格式为 xyxy,Shape (n, 4) or (b, n, 4). """ # 计算点距离四边的距离 left = points[..., 0] - bbox[..., 0] top = points[..., 1] - bbox[..., 1] right = bbox[..., 2] - points[..., 0] bottom = bbox[..., 3] - points[..., 1] ... return torch.stack([left, top, right, bottom], -1) def distance2bbox(points: Tensor, distance: Tensor, ...) -> Tensor: """ 通过距离反算 bbox 的 xyxy points (Tensor): 正方形的预测 anchor 的 anchor point [x, y],Shape (B, N, 2) or (N, 2). distance (Tensor): 距离四边的距离。(left, top, right, bottom). Shape (B, N, 4) or (N, 4) """ # 反算 bbox xyxy x1 = points[..., 0] - distance[..., 0] y1 = points[..., 1] - distance[..., 1] x2 = points[..., 0] + distance[..., 2] y2 = points[..., 1] + distance[..., 3] bboxes = torch.stack([x1, y1, x2, y2], -1) ... return bboxes
-
-
RTMDet提出了Dynamic Soft Label Assigner来实现标签的动态匹配策略, 该方法主要包括使用 位置先验信息损失 , 样本回归损失 , 样本分类损失 , 同时对三个损失进行了Soft处理进行参数调优, 以达到最佳的动态匹配效果。该方法 Matching Cost 矩阵由如下损失构成:(见上文)-
cost_matrix = soft_cls_cost + iou_cost + soft_center_prior
-
-
通过计算上述三个损失的和得到最终的
cost_matrix后, 再使用SimOTA决定每一个GT匹配的样本的个数并决定最终的样本。具体操作如下所示:-
首先通过自适应计算每一个
gt要选取的样本数量: 取每一个gt与所有bboxes前13大的iou, 得到它们的和取整后作为这个gt的样本数目, 最少为1个, 记为dynamic_ks。 -
对于每一个
gt, 将其cost_matrix矩阵前dynamic_ks小的位置作为该gt的正样本。 -
对于某一个
bbox, 如果被匹配到多个gt就将与这些gts的cost_marix中最小的那个作为其label。
-
-
在网络训练初期,因参数初始化,回归和分类的损失值
Cost往往较大, 这时候IOU比较小, 选取的样本较少,主要起作用的是Soft_center_prior也就是位置信息,优先选取位置距离GT比较近的样本作为正样本,这也符合人们的理解,在网络前期给少量并且有足够质量的样本,以达到冷启动。 当网络进行训练一段时间过后,分类分支和回归分支都进行了一定的优化后,这时IOU变大,** 选取的样本也逐渐增多,这时网络也有能力学习到更多的样本**,同时因为IOU_Cost以及Soft_Cls_Cost变小,网络也会动态的找到更有利优化分类以及回归的样本点。 -
参与 Loss 计算的共有两个值:
loss_cls和loss_bbox,其各自使用的 Loss 方法如下:loss_cls:mmdet.QualityFocalLoss;loss_bbox:mmdet.GIoULoss。权重比例是:loss_cls:loss_bbox=1 : 2。 -
推理和后处理过程
-
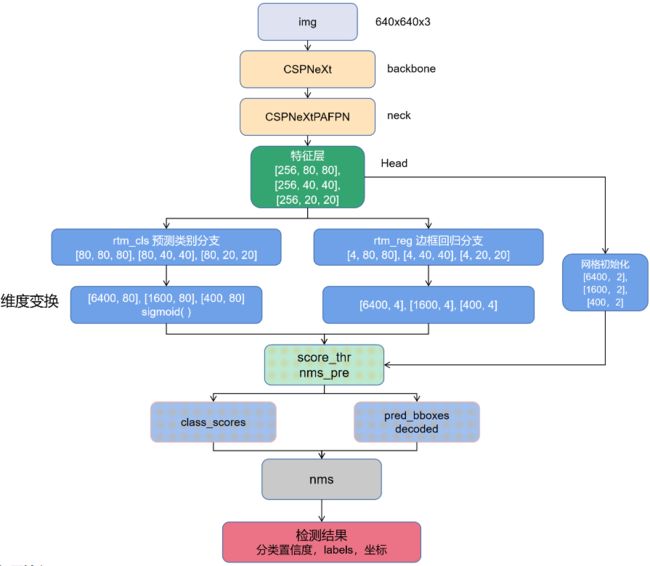
-
预测的图片输入大小为 640 x 640, 通道数为 3 ,经过 CSPNeXt, CSPNeXtPAFPN 层的 8 倍、16 倍、32 倍下采样得到 80 x 80, 40 x 40, 20 x 20 三个尺寸的特征图。以 rtmdet-l 模型为例,此时三层通道数都为 256,经过
bbox_head层得到两个分支,分别为rtm_cls类别预测分支,将通道数从 256 变为 80,80 对应所有类别数量;rtm_reg边框回归分支将通道数从 256 变为 4,4 代表框的坐标。 -
根据特征图尺寸初始化三个网格,大小分别为 6400 (80 x 80)、1600 (40 x 40)、400 (20 x 20),如第一个层 shape 为 torch.Size([ 6400, 2 ]),最后一个维度是 2,为网格点的横纵坐标,而 6400 表示当前特征层的网格点数量。
-
经过
_predict_by_feat_single函数,将从 head 提取的单一图像的特征转换为 bbox 结果输入,得到三个列表cls_score_list,bbox_pred_list,mlvl_priors,详细大小如图所示。之后分别遍历三个特征层,分别对 class 类别预测分支、bbox 回归分支进行处理。以第一层为例,对 bbox 预测分支 [ 4,80,80 ] 维度变换为 [ 6400,4 ],对类别预测分支 [ 80,80,80 ] 变化为 [ 6400,80 ],并对其做归一化,确保类别置信度在 0 - 1 之间。 -
先使用一个
nms_pre操作,先过滤大部分置信度比较低的预测结果(比如score_thr阈值设置为 0.05,则去除当前预测置信度低于 0.05 的结果),然后得到 bbox 坐标、所在网格的坐标、置信度、标签的信息。经过三个特征层遍历之后,分别整合这三个层得到的的四个信息放入 results 列表中。 -
最后将网络的预测结果映射到整图当中,得到 bbox 在整图中的坐标值
-
进行 nms 操作,最终预测得到的返回值为经过后处理的每张图片的检测结果,包含分类置信度,框的 labels,框的四个坐标
4,80,80 ] 维度变换为 [ 6400,4 ],对类别预测分支 [ 80,80,80 ] 变化为 [ 6400,80 ],并对其做归一化,确保类别置信度在 0 - 1 之间。
-