Redis从入门到精通【进阶篇】之数据类型Stream详解和使用示例
文章目录
- 0.前言
- 1. 基本概念
-
- 1.1. Stream的结构
- 1.2. 持久化
- 1.3. Stream的消费者组
- 2.实现原理
-
- 2.1. Stream的数据结构
- 2.2. Stream的消息追加
- 2.3. Stream的消费
- 2.4. Stream的消费者组
- 3.Redis Stream底层原理
-
- 3.1. 基数树(Radix Tree)
- 3.2. listpacks
-
- 小结
- 4.命令和操作示例
-
- 4.1 Streams命令
- 4.2. 操作示例
-
- 4.2.1 Jedis工程
- 4.2.2. RedisTemplate工程
- 总结
- 5. 系列文章

简介:大家好,我是冰点,从业11年,目前在物流独角兽企业从事技术管理和架构设计方面工作,之前的把博客作为技术流水账在写。现在准备把多年的积累整理一下,成体系的分享给大家,也算是对多年开发生涯的总结。如果你在工作和学习中遇到问题也可反馈给我(iceicepip), 路漫漫其修远兮,吾将上下而求索。
️2023计划:
1. 将多年来整理的Redis学习和实践笔记整理并发布成专栏。
2. 将最近2年在groovy实践应用上的沉淀的初稿,发布成书籍。
3. 将多年来整理的MySQL学习研究笔记整理并发布成专栏。
4. 根据技术交流群答疑的问题,整理成博客文章发布分享。
我陆续将我整理的Redis精选比较,分享给大家,今天分享的是Redis底层数据结构简单动态字符串(SDS)。我们从数据结构解析,包括Redis5和Redis6的SDS结构差异分析。这样设计的优势,如果有不对的地方,请大家指正。加粗样式
0.前言
Redis的Stream是一种新的数据类型,于Redis 5.0版本中引入。它是一个有序、持久化、可重复读的消息流,可以用于实现消息队列、日志系统等应用场景。本文将从底层实现的角度对Redis的Stream进行详解。其实就我主观而言,Redis之所以要搞Stream 是为了解决之前版本的发布和订阅(pub/sub)这种有点鸡肋的消息模式。我们可以从如下几个点了解一下,或者直接参阅我之前的博文《Redis 从入门到精通之Redis 订阅与发布》。
- 可靠性问题。Redis的pub/sub机制是异步的,即发布者发送消息后并不会等待订阅者的响应,因此可能存在消息丢失的风险。此外,如果订阅者在消息发布前未完成订阅操作,也可能会导致消息丢失。
- 订阅者的可用性问题。如果某个订阅者出现故障或者网络问题,可能会导致该订阅者无法接收到消息,从而影响系统的正常运行。
- 扩展性问题。Redis的pub/sub机制是基于单个Redis实例的,如果需要扩展到多个Redis实例,可能需要使用其他技术来实现。
- 高并发场景下的性能问题。虽然Redis的pub/sub机制采用了异步IO和多线程等技术来提高性能,但在高并发场景下,仍然可能出现性能瓶颈。
- 消息的过期机制问题。Redis的pub/sub机制不支持消息过期机制,即消息无法设置过期时间,这可能会导致内存占用过高。
所以基于以上Redis 发布和订阅模式的鸡肋的问题。Redis 在经过大家诟病之后在5.0版本推出了Stream 。其实关于Stream 我说只能是稍微强一点的消息队列,只能解决部分场景。并且也存在很多问题。好咱们今天就聊聊Stream 看看他比pub/sub强在哪。
有的描述仅为个人观点,如果你要杠,那就是你说的对。
1. 基本概念
1.1. Stream的结构
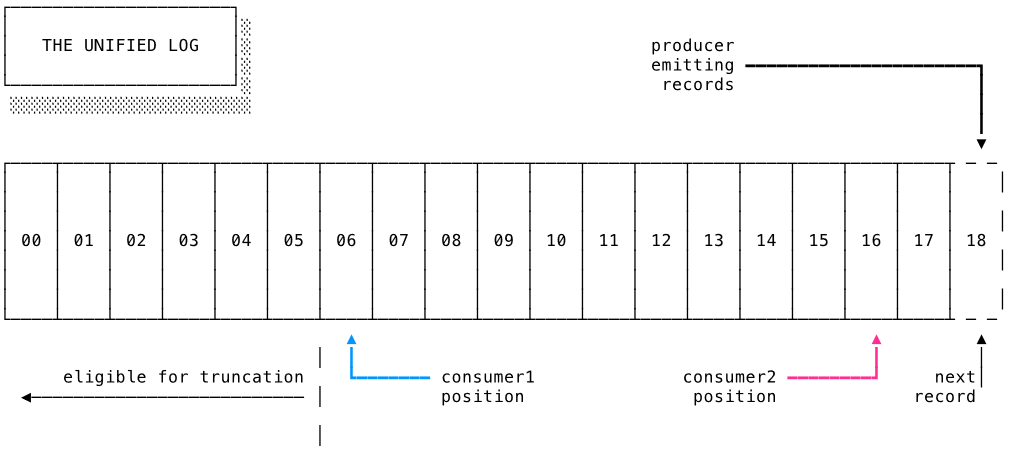
Redis的Stream由多个消息构成,每个消息包含了一个唯一的ID和一个键值对数据。Stream中的消息是有序的,每个消息都有一个唯一的ID,ID是一个自增的64位整数。Stream中的每个消息都可以包含多个键值对数据,这些数据是以键值对的形式存储的。
1.2. 持久化
Redis的Stream支持持久化,即可以将Stream中的消息保存到磁盘中,以便在Redis重启后能够恢复数据。
虽然Stream 数据类型被作为消息中间件使用。它的持久化也是大家关心的,毕竟关系着数据是否丢失的问题。其实Stream 持久化方式也是依赖RDB和AOF,这个我在Redis进阶讲持久化那个章节讲解了,本次不详细展开。其中RDB是Redis自身的快照持久化方式,可以将整个Redis服务器的状态保存到磁盘中,包括了Stream中的消息。而AOF则是Redis的命令日志持久化方式,可以将所有的写命令以类似于MySQL的binlog的方式保存到磁盘中,以便在Redis重启后能够通过回放日志的方式恢复数据。
对于Stream来说,RDB持久化方式的效率相对较高,但是数据的实时性相对较差,因为Redis默认情况下是每隔一段时间才会进行一次RDB快照持久化。而AOF持久化方式可以保证数据的实时性,但是对于大量的写操作,可能会影响Redis的性能,因为每个写操作都需要写入到AOF文件中。因此,根据实际的应用场景和需求,可以选择适合的持久化方式。
1.3. Stream的消费者组
Redis的Stream支持消费者组,多个消费者可以组成一个消费者组,每个消费者可以独立地消费Stream中的消息。当一个消费者组中的某个消费者消费了一个消息后,其他消费者将无法再消费该消息,其实对MQ有一定基础的同学看完这个也就不需要看下面了,其实通俗讲就是Redis提供了一种Work模式或者叫任务队列模式,他们有个共同特征叫做资源竞争,如果没有MQ基础知识的同学,可以整体看完后参阅我之前写的一篇博客《RabbitMQ的工作模式》。
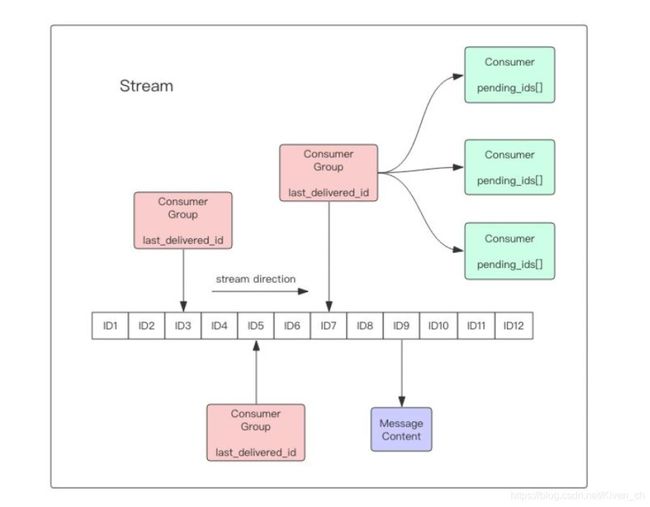
Stream的消费者组是一种机制,可以让多个消费者同时消费同一个Stream中的消息,并且每个消息只会被消费一次。消费者组由一个或多个消费者组成,每个消费者都有自己的ID,用于在消费者组内唯一标识自己。消费者组内的消费者可以共同处理Stream中的消息,每个消费者只会处理其中的一部分消息。
当消费者组中的某个消费者开始消费Stream中的消息时,它会从Stream的最早未被消费的消息开始消费,直到消费到最新的消息为止。消费者可以消费完所有消息后退出,也可以在消费完成之前随时退出。当某个消费者退出消费组时,其他消费者会接管其正在处理的消息,保证每个消息只会被消费一次。
消费者组的使用可以在多个场景中体现出优势,例如消息队列、实时数据处理等,可以提高消息的处理效率和可靠性。
2.实现原理
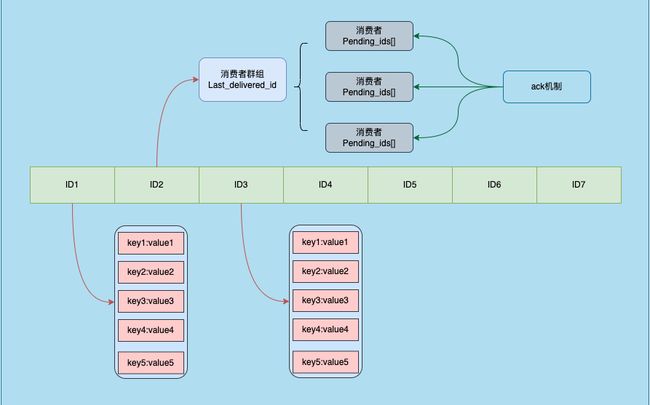
2.1. Stream的数据结构
Stream数据结构由两个部分组成,一个是消息ID的有序集合,另一个是消息的哈希表。
Stream的消息ID有序集合中,每个元素都是一个消息的ID,按照递增的顺序排列。有序集合中的分值为消息的ID,成员为NULL。
Stream的消息哈希表中,每个消息都用一个哈希表表示,哈希表的键是消息的ID,值是一个由多个键值对数据组成的字典。
2.2. Stream的消息追加
当向Stream中追加新消息时,Redis会将新消息的ID插入到消息ID有序集合中,并将新消息的键值对数据插入到对应的哈希表中。如果新消息的ID已经存在于消息ID有序集合中,则插入操作会失败。
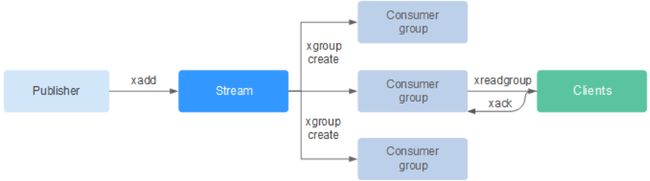
2.3. Stream的消费
当一个消费者要消费Stream中的消息时,它需要指定一个起始ID,Redis会将起始ID对应的消息之后的所有消息都返回给该消费者。消费者可以使用XRANGE命令获取消息。
当一个消费者消费了一个消息之后,Redis会将该消息的ID从消息ID有序集合中删除,并将该消息从消息哈希表中删除。如果该消息是该消费者组中的最后一个消息,则该消费者组的消费者将无法再消费该消息之前的消息。
2.4. Stream的消费者组
当一个消费者组中的某个消费者消费了一个消息之后,Redis会将该消息的ID从消费者组的"pending"列表中删除,并将该消息从消息哈希表中删除。如果该消费者是该消费者组中的最后一个消费者,则该消费者组的"pending"列表将被删除。
当某个消费者组中的所有消费者都没有消费一个特定的消息时,该消息的ID将存储在该消费者组的"pending"列表中。"pending"列表是一个有序集合,其中每个元素都是一个消息的ID,按照消息的时间戳排序。有序集合中的分值为消息的时间戳,成员为消息的ID。
3.Redis Stream底层原理
Redis Stream的底层数据结构是基数树和listpack,这使得Redis Stream具有高效的空间和时间复杂度,同时允许通过ID进行随机访问。在Redis Stream中,每个条目都有一个唯一的ID,以实现排序。这使得可以按照时间戳或其他自定义标准对数据进行范围查询。每个Stream可以有多个消费者组,每个消费者组中可以有多个消费者,消费者组可以将Stream分配给不同的消费者,以均匀地分配负载。
3.1. 基数树(Radix Tree)
基数树(Radix Tree)是一种多叉树,用于存储有序数据集合。在Redis中,基数树被用于实现有序集合和Stream中的消息ID有序集合。
基数树的每个节点都包含一个字符和多个子节点。通过不断遍历基数树的子节点,可以找到一个字符串在基数树中的位置。例如,在Redis中,有序集合中的一个元素可以表示为一个字符串和一个分值,Redis会将这个元素的字符串按照字符拆分成多个节点,每个节点对应一个字符,最终将这个元素的分值存储在基数树的叶子节点上。
基数树的优点是支持快速的前缀匹配和范围查找。例如,在Redis中,有序集合的ZRANGEBYLEX命令就是基于基数树实现的,可以快速地按照字典序查找有序集合中的元素。
3.2. listpacks
Listpacks的数据结构
![]()
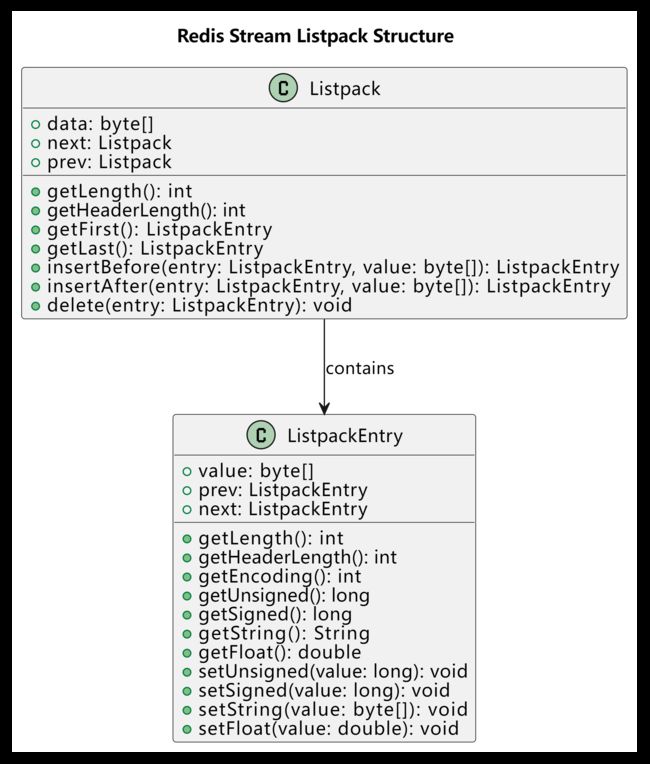
使用了两个类来表示 Listpack 和 ListpackEntry。Listpack 类包含了 ListpackEntry
类的引用,表示它包含了若干个 ListpackEntry 实例。ListpackEntry
类包含了一个字节数组(value)和两个指针(prev 和 next),表示它存储了一个具体的消息记录以及前后消息记录的链接关系。在ListpackEntry 类中还定义了一些方法,用来获取和设置消息记录的具体内容,例如 getUnsigned()、setString() 等。
listpacks的一个特点是支持高效的元素访问、插入和删除操作。listpacks会将多个元素紧密地排列在一起,每个元素占用的空间大小是可变的,因此可以根据实际需求灵活地分配空间。同时,listpacks可以按照元素索引快速地定位某个元素,也可以在任意位置快速地插入或删除元素。
在Redis Stream中,消息哈希表中的每个元素都是一个键值对数据,这些数据会被序列化成二进制格式,然后存储在一个listpack中。当需要访问某个键值对数据时,Redis会根据该数据在listpack中的位置,快速地定位并反序列化出该数据。
基数树和listpacks是Redis中两个重要的底层数据结构,它们为Redis提供了高效、可扩展、有序、紧凑的数据存储能力。深入理解这些数据结构的实现原理,可以帮助开发者更好地理解Redis的底层实现,从而优化应用程序的性能和可扩展性。
小结
我们可以看出来其实Redis就是实现了一个增强的发布-订阅模式,基本上实现延时队列,消息广播,死信队列等。但是像点到点不支持,规则路由支持的不是很灵活,包括消息监控等配套都不是很成熟,所以如果只是轻量级使用可以,如果大型和高并发的消息队列可能不适用,所以在技术选型上可以适当考虑Stream,但是还是要结合自身公司的技术积累和实践。
4.命令和操作示例
4.1 Streams命令
- XADD:向指定的Stream中添加一条消息。
- XLEN:获取指定Stream中的消息数量。
- XRANGE:按照ID范围查询Stream中的消息。
- XREVRANGE:按照ID范围反向查询Stream中的消息。
- XREAD:从多个Stream中连续读取多条消息。
- XACK:确认接收并处理一条或多条消息。
- XDEL:删除指定Stream中的一条或多条消息。
- XGROUP:管理Stream的消费者组。
- XREADGROUP:从指定的Stream中连续读取多条消息,并将消息分配给指定的消费者组。
这些命令一起构成了Redis Streams的基本操作集合,可以对Stream中的消息进行读写、查询、删除、确认处理等各种操作。通过这些命令,开发者可以轻松地构建出高效、可扩展、高可用的实时应用程序。
4.2. 操作示例
我们分别用jedis 和 SpringBoot 实现
4.2.1 Jedis工程
首先创建一个Maven项目,在pom.xml文件中添加以下依赖:
<dependency>
<groupId>redis.clientsgroupId>
<artifactId>jedisartifactId>
<version>3.6.3version>
dependency>
然后创建一个名为JedisDemo的Java类,实现Redis Streams的基本操作:
import redis.clients.jedis.Jedis;
import redis.clients.jedis.StreamEntry;
import java.util.AbstractMap;
import java.util.Collections;
import java.util.List;
import java.util.Map;
/**
* Redis 从入门到精通 代码示例 Stream流
* @author 冰点
* @date 2023-6-1 23:43:47
*/
public class JedisDemo {
public static void main(String[] args) {
Jedis jedis = new Jedis("localhost");
// 添加消息
String response = jedis.xadd("stream1", "*", "name", "John", "age", "30");
System.out.println(response);
// 获取消息数量
Long len = jedis.xlen("stream1");
System.out.println(len);
// 查询消息
List<StreamEntry> entries = jedis.xrange("stream1", "1000-2000");
for (StreamEntry entry : entries) {
System.out.println(entry);
}
// 反向查询消息
List<StreamEntry> entries2 = jedis.xrevrange("stream1", "+", "-", 10);
for (StreamEntry entry : entries2) {
System.out.println(entry);
}
// 连续读取消息
List<Map.Entry<String, List<StreamEntry>>> results = jedis.xread(10, 5000, new AbstractMap.SimpleEntry<>("stream1", "0"), new AbstractMap.SimpleEntry<>("stream2", "0"));
for (Map.Entry<String, List<StreamEntry>> result : results) {
System.out.println(result.getKey() + ": " + result.getValue());
}
// 确认处理消息
Long count = jedis.xack("stream1", "consumer1", "1001", "1002");
System.out.println(count);
// 删除消息
Long count2 = jedis.xdel("stream1", "1001", "1002");
System.out.println(count2);
// 管理消费者组
String result = jedis.xgroupCreate("stream1", "consumer1", "0", true);
System.out.println(result);
// 读取并分配消息
List<Map.Entry<String, List<StreamEntry>>> results2 = jedis.xreadGroup("consumer1", "consumer1-1", 10, 5000, true, new AbstractMap.SimpleEntry<>("stream1", ">"));
for (Map.Entry<String, List<StreamEntry>> result2 : results2) {
System.out.println(result2.getKey() + ": " + result2.getValue());
}
jedis.close();
}
}
运行JedisDemo类,可以看到输出了Redis Streams的基本操作结果。
4.2.2. RedisTemplate工程
首先创建一个Maven项目,在pom.xml文件中添加以下依赖:
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-redisartifactId>
<version>2.5.0version>
dependency>
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.ApplicationContext;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.connection.stream.MapRecord;
import org.springframework.data.redis.connection.stream.ReadOffset;
import org.springframework.data.redis.connection.stream.RecordId;
import org.springframework.data.redis.connection.stream.StreamOffset;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.SessionCallback;
import org.springframework.data.redis.core.StreamOperations;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.data.redis.core.types.RedisClientInfo;
import org.springframework.util.CollectionUtils;
import java.time.Duration;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* Redis 从入门到精通 代码示例 Stream流
* @author 冰点
* @date 2023-6-1 23:43:47
*/
@SpringBootApplication
public class RedisTemplateDemo {
public static void main(String[] args) {
ApplicationContext context = SpringApplication.run(RedisTemplateDemo.class, args);
RedisTemplate<String, String> redisTemplate = context.getBean(StringRedisTemplate.class);
// 添加消息
redisTemplate.opsForStream().add("stream1", Collections.singletonMap("name", "John"), Collections.singletonMap("age", "30"));
// 获取消息数量
Long len = redisTemplate.opsForStream().size("stream1");
System.out.println(len);
// 查询消息
List<MapRecord<String, String, String>> records= redisTemplate.opsForStream().range("stream1", Range.unbounded());
for (MapRecord<String, String, String> record : records) {
System.out.println(record);
}
// 反向查询消息
List<MapRecord<String, String, String>> records2 = redisTemplate.opsForStream().reverseRange("stream1", Range.unbounded());
for (MapRecord<String, String, String> record : records2) {
System.out.println(record);
}
// 连续读取消息
Map<StreamOffset<String>, ReadOffset> streams = new HashMap<>();
streams.put(StreamOffset.create("stream1", ReadOffset.from("0")), ReadOffset.lastConsumed());
List<MapRecord<String, String, String>> results = redisTemplate.opsForStream().read(streams, Duration.ofMillis(5000));
for (MapRecord<String, String, String> result : results) {
System.out.println(result);
}
// 确认处理消息
redisTemplate.execute(new SessionCallback<>() {
@Override
public <K, V> Object execute(RedisOperations<K, V> operations) throws DataAccessException {
operations.watch("stream1");
RecordId id1 = RecordId.of("1001");
RecordId id2 = RecordId.of("1002");
String key = "stream1";
StreamOperations<String, String, String> ops = operations.opsForStream();
List<MapRecord<String, String, String>> records = ops.range(key, Range.closed(id1, id2));
if (!CollectionUtils.isEmpty(records)) {
RedisConnectionFactory factory = operations.getConnectionFactory();
RedisClientInfo info = factory.getConnection().getClientList().get(0);
ops.acknowledge(key, info.getAddress(), id1, id2);
}
return null;
}
});
// 删除消息
Long count = redisTemplate.opsForStream().delete("stream1", "1001", "1002");
System.out.println(count);
// 管理消费者组
redisTemplate.opsForStream().createGroup("stream1", "consumer1");
// 读取并分配消息
MapRecord<String, String, String> record = redisTemplate.opsForStream().read("consumer1", StreamOffset.lastConsumed("stream1"));
if (record != null) {
System.out.println(record);
redisTemplate.opsForStream().acknowledge("stream1", "consumer1", record.getId());
}
}
}
我列举的都是基础示例,其实Redis Stream 支持的场景很多,比如死信队列,延迟队列 ,规则路由
总结
Redis的Stream是一种有序、持久化、可重复读的消息流数据类型,非常适合用于实现消息队列、日志系统等应用场景。Stream的数据结构由消息ID有序集合和消息哈希表两部分组成,消息ID有序集合用于维护消息的顺序,消息哈希表用于存储消息的键值对数据。Stream支持消费者组,多个消费者可以组成一个消费者组,每个消费者可以独立地消费Stream中的消息。Redis将Stream持久化到磁盘中的方式是将消息ID有序集合和消息哈希表分别保存到两个独立的RDB文件中。当Redis重启后,它会从这两个文件中重新加载Stream数据。Stream的底层实现非常高效,可以支持非常大的消息流数据。
5. 系列文章
《Redis从入门到精通【高阶篇】之底层数据结构简单动态字符串(SDS)详解》
《Redis从入门到精通【高阶篇】之底层数据结构压缩列表(ZipList)详解》

参考资料:
- 陈雷老师的《Redis5设计与源码分析 》
- Redis 6.0源码