第3章“程序的机器级表示”:异类的数据结构
文章目录
- 概述
-
- 3.9.1 结构
- 3.9.2 联合
概述
C提供了两种将不同类型的对象结合到一起来创建数据类型的机制:结构(structure),用关键字 struct 来声明,将多个对象集合到一个单位中;联合(union),用关键字 union 来声明,允许用几种不同的类型来引用一个对象。
3.9.1 结构
C 的 struct 声明创建一个数据类型,将可能不同类型的对象聚合到一个对象中。结构的各个组成部分是用名字来引用。结构的实现类似于数组的实现,因为结构的所有组成部分都存放在存储器中连续的区域内,而指向结构的指针就是结构第一个字节的地址。 编译器保存关于每个结构类型的信息,指示每个域(field)的字节偏移。它以这些偏移作为存储器引用指令中的位移,从而产生对结构元素的引用。
将指向结构的指针从一个地方传递到另一个地方,而不是拷贝它们,是很常见的。
举个例子,看如下的结构声明:
struct rec {
int i;
int j;
int a[3];
int *p;
};
这个结构包括四个域——两个 4 字节 int、一个由三个 4 字节 int 组成的数组和一个 4 字节的整数指针,总共24个字节:

注意,数组 a 是嵌入到这个结构中的。上图中顶部的数字给出的是各个域相对结构开始处的字节偏移。
为了访问结构的域,编译器产生的代码要将结构的地址加上适当的偏移。例如,假设 struct rec * 类型的变量 r 放在寄存器 %edx 中。然后,下面的代码将元素 r->i 拷贝到元素 r->j:
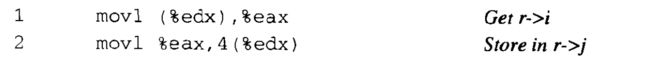
因为域 i i i 的偏移量为0,所以这个域的地址就是 r r r 的值。为了存储到域 j j j,代码要将 r r r 的地址加上偏移量 4。
要产生一个指向结构内部对象的指针,只需将结构的地址加上该域的偏移量。例如,只用加上偏移量8 + 4 x 1 = 12,就可以得到指针 &(r->a[1])。对于在寄存器 %eax 中的指针 r 和 在寄存器 %edx 中的整数变量 i i i,可以用一条指令产生指针 &(r->a[i]) 的值:
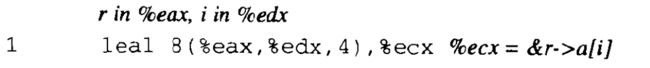
还有最后一个例子,下面的代码实现的是语句:
r->p = &r->a[r->i + r->j];
开始时 r r r 在寄存器 %edx 中:

正如这些示例表明的那样,对结构的各个域的选取完全是在编译时处理的。机器代码不包含关于域声明或域名字的信息。
3.9.2 联合
联合提供了一种方式,能够规避 C 的类型系统,允许以多种类型来引用一个对象。联合声明的语法与结构的语法一样,只不过语义相差比较大。它们不是用不同的域来引用不同的存储器块,而是引用的同一存储器块。
看如下的声明:
struct S3 {
char c;
int i[2];
double v;
};
union U3 {
char c;
int i[2];
double v;
};
域的偏移数据类型 S3 和 U3 的整个大小如下表所示:
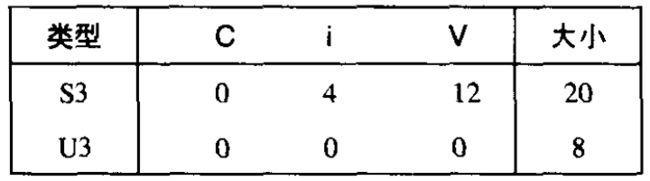
(稍后会看到为什么 S3 中的 i i i 的偏移量为 4,而不是 1。)对于类型 union U3 * 的指针 p p p,p->c、p->i[0] 和 p->v 引用的都是数据结构的起始位置。还要注意,一个联合的总的大小等于它最大域的大小。
在一些情况中,联合十分有用。但是,它也引起了一些讨厌的错误,因为它们绕过了 C 类型系统提供的安全措施。一种应用情况是,事先知道对一个数据结构中的两个不同域的使用是互斥的,那么将这两个域作为联合的一部分,而不是结构的一部分,会减小分配空间的总量。
如,假设想实现一个二叉树的数据结构,每个叶子节点都有一个 double 的数据值,而每个内部节点都有指向两个孩子节点的指针,但是没有数据。如果像这样声明:
struct Node {
struct Node *left;
struct Node *right;
double data;
};
那么每个节点需要 16 个字节,每种类型的节点都要浪费一半的字节。相反,如果这样来声明一个节点:
union Node {
struct {
union Node *left;
union Node *right;
} internal;
double data;
};
那么,每个节点就只需要 8 个字节。如果 n n n 是一个指针,指向 union Node * 类型的节点,用 n->data 来引用叶子节点的数据,而用 n->internal.left 和 n->internal.right 来引用内部节点的孩子。
不过,如果这样编码,就无法确定一个给定的节点到底是叶子节点还是内部节点。通常的方法是引入一个附加的标志域:
struct Node {
int is_leaf;
union {
struct {
struct Node *left;
struct Node *right;
} internal;
double data;
} info;
};
这里,对叶子节点来说,域 is_leaf 是 1,而对内部节点来说,该域的值是 0。这个结构总共需要 12 个字节:is_leaf 要 4 个,info.internal.left 和 info.internal.right 各要 4 个,或者 info.data 要 8 个。在这种情况中,相对于给代码造成的麻烦,使用联合带来的好处是很小的。对于有较多域的数据结构,这样的节省会更加吸引人一些。
联合还可以用来访问不同数据类型的位的形式。例如,下面这段代码返回一个 float 作为 unsigned 的位表示:
unsigned float2bit(float f)
{
union {
float f;
unsigned u;
} temp;
temp.f = f;
return temp.u;
}
在这段代码中,以一种数据类型来存储联合中的参数,又以另一种数据类型来访问它。有趣的是,为此过程产生的代码与为下面这个过程产生的代码是一样的:
unsigned copy(unsigned u)
{
return u;
}
这两个过程的主体只有一条指令:
![]()
这就证明汇编代码中缺乏类型信息。无论参数是一个 float,还是一个 unsigned,它都在相对于 %ebp 偏移量为 8 的地方。过程只是简单地将它的参数拷贝到返回值,不修改任何位。
当用联合来将各种不同大小的数据类型结合到一起时,字节顺序问题就变得很重要了。如假设写了一个过程,它会以两个 4 字节的 unsigned 的位的形式,创建一个 8 字节的 double:
double bit2double(unsigned word0, unsigned word1)
{
union {
double d;
unsigned u[2];
} temp;
temp.u[0] = word0;
temp.u[1] = word1;
return temp.d;
}
在像 IA32 这样的小端法(little-endian)机器上,参数 word0 会是 d d d 的低位四个字节,而 word1 会是高位四个字节。在大端法(big-endian)机器上,这两个参数的角色刚好相反。