shardingsphere第二课-shardingsphere-jdbc的基本使用及各种分片策略
第一章介绍
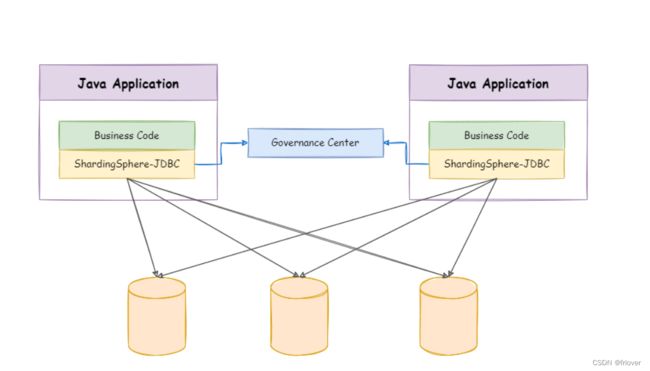
一、ShardingJDBC客户端分库分表
ShardingSphere-JDBC 定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
- 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template
或直接使用JDBC; - 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, HikariCP 等;
- 支持任意实现 JDBC 规范的数据库,目前支持 MySQL,PostgreSQL,Oracle,SQLServer 以及任何可使用JDBC
访问的数据库。
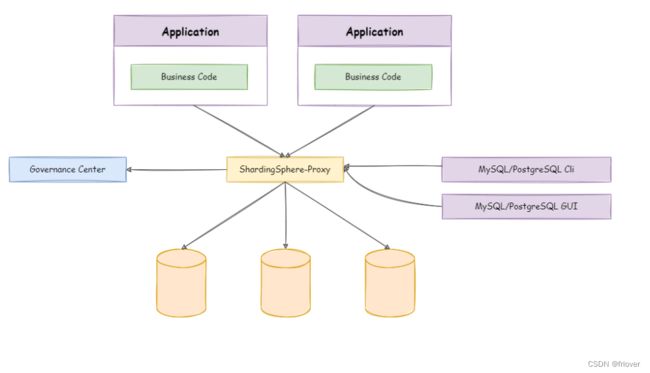
二、ShardingProxy服务端分库分表
ShardingSphere-Proxy 定位为透明化的数据库代理端,通过实现数据库二进制协议,对异构语言提供支持。 目前提供 MySQL 和 PostgreSQL 协议,透明化数据库操作,对 DBA 更加友好。
- 向应用程序完全透明,可直接当做 MySQL/PostgreSQL 使用;
- 兼容 MariaDB 等基于 MySQL 协议的数据库,以及 openGauss 等基于 PostgreSQL 协议的数据库;
- 适用于任何兼容 MySQL/PostgreSQL 协议的的客户端,如:MySQL Command Client, MySQL Workbench,Navicat 等。
三、ShardingSphere混合部署架构
这两个产品都各有优势。ShardingJDBC跟客户端在一起,使用更加灵活。而ShardingProxy是一个独立部署的服务,所以他的功能相对就比较固定。他们的整体区别如下:
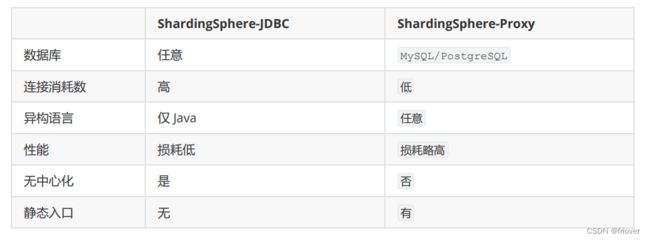
另外,在产品图中,Governance Center也是其中重要的部分。他的作用有点类似于微服务架构中的配置中心,可以使用第三方服务统一管理分库分表的配置信息,当前建议使用的第三方服务是Zookeeper,同时也支持Nacos,Etcd等其他第三方产品。
由于ShardingJDBC和ShardingProxy都支持通过Governance Center,将配置信息交个第三方服务管理,因此,也就自然支持了通过Governance Center进行整合的混合部署架构。

第二章搭建
用最常用的SpringBoot+MyBatis+MyBatis-plus快速搭建一个可以访问数据的简单应用,以这个应用作为我们分库分表的基础。
- step1: 在数据库中创建course表,建表语句如下:
CREATE TABLE course (
`cid` bigint(0) NOT NULL AUTO_INCREMENT,
`cname` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`user_id` bigint(0) NOT NULL,
`cstatus` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
PRIMARY KEY (`cid`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
- step2: 搭建一个Maven项目,在pom.xml中加入依赖,其中就包含访问数据库最为简单的几个组件。
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>ShardingDemoV5artifactId>
<groupId>com.roygroupId>
<version>1.0version>
parent>
<modelVersion>4.0.0modelVersion>
<artifactId>ShardingartifactId>
<properties>
<maven.compiler.source>8maven.compiler.source>
<maven.compiler.target>8maven.compiler.target>
properties>
<dependencies>
<dependency>
<groupId>org.apache.shardingspheregroupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starterartifactId>
<version>5.2.1version>
<exclusions>
<exclusion>
<artifactId>snakeyamlartifactId>
<groupId>org.yamlgroupId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>org.yamlgroupId>
<artifactId>snakeyamlartifactId>
<version>1.33version>
dependency>
<dependency>
<groupId>org.apache.shardingspheregroupId>
<artifactId>shardingsphere-transaction-xa-coreartifactId>
<version>5.2.1version>
<exclusions>
<exclusion>
<artifactId>transactions-jdbcartifactId>
<groupId>com.atomikosgroupId>
exclusion>
<exclusion>
<artifactId>transactions-jtaartifactId>
<groupId>com.atomikosgroupId>
exclusion>
exclusions>
dependency>
<dependency>
<artifactId>transactions-jdbcartifactId>
<groupId>com.atomikosgroupId>
<version>5.0.8version>
dependency>
<dependency>
<artifactId>transactions-jtaartifactId>
<groupId>com.atomikosgroupId>
<version>5.0.8version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starterartifactId>
<exclusions>
<exclusion>
<artifactId>snakeyamlartifactId>
<groupId>org.yamlgroupId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>druidartifactId>
<version>1.1.20version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
dependency>
<dependency>
<groupId>com.baomidougroupId>
<artifactId>mybatis-plus-boot-starterartifactId>
<version>3.4.3.3version>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-jar-pluginartifactId>
<version>3.2.0version>
<executions>
<execution>
<id>ShardingSPIDemoid>
<phase>packagephase>
<goals>
<goal>jargoal>
goals>
<configuration>
<classifier>spiextentionclassifier>
<includes>
<include>com/roy/shardingDemo/algorithm/*include>
<include>META-INF/services/*include>
includes>
configuration>
execution>
executions>
plugin>
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
<version>2.3.1.RELEASEversion>
<configuration>
<mainClass>com.roy.shardingDemo.ShardingJDBCApplicationmainClass>
configuration>
<executions>
<execution>
<goals>
<goal>repackagegoal>
goals>
execution>
executions>
plugin>
plugins>
build>
project>
- step3: 使用MyBatis-plus的方式,直接声明Entity和Mapper,映射数据库中的course表。
public class Course {
private Long cid;
private String cname;
private Long userId;
private String cstatus;
//省略。getter ... setter ....
}
public interface CourseMapper extends BaseMapper<Course> {
}
- step4: 增加SpringBoot启动类,扫描mapper接口
@SpringBootApplication
@MapperScan("com.roy.jdbcdemo.mapper")
public class App {
public static void main(String[] args) {
SpringApplication.run(App.class,args);
}
}
- step5: 在springboot的配置文件application.properties中增加数据库配置
@SpringBootTest
@RunWith(SpringRunner.class)
public class JDBCTest {
@Resource
private CourseMapper courseMapper;
@Test
public void addcourse() {
for (int i = 0; i < 10; i++) {
Course c = new Course();
c.setCname("java");
c.setUserId(1001L);
c.setCstatus("1");
courseMapper.insert(c);
//insert into course values ....
System.out.println(c);
}
}
@Test
public void queryCourse() {
QueryWrapper<Course> wrapper = new QueryWrapper<Course>();
wrapper.eq("cid",1L);
List<Course> courses = courseMapper.selectList(wrapper);
courses.forEach(course > System.out.println(course));
}
}
自此基本的springboot项目搭建完成
二、开始引入ShardingSphere分库分表
1、先引入ShardingSphere依赖,上面pom已有
2、在对应数据库里创建分片表,按照上面的sql,但是去掉auto自增
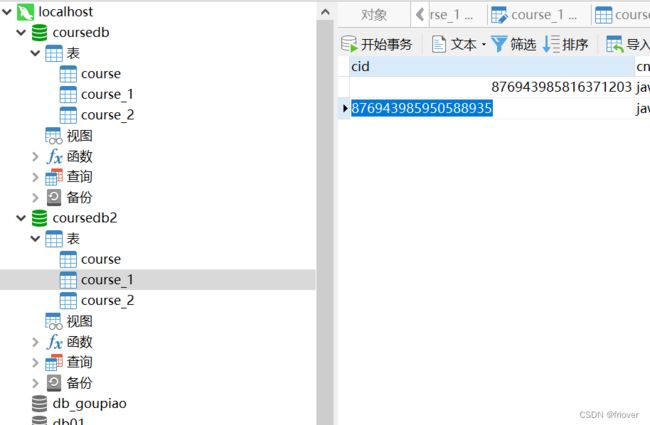
3、增加ShardingJDBC的分库分表配置
# 打印SQL
spring.shardingsphere.props.sqlshow = true
spring.main.allowbeandefinitionoverriding = true
# 数据源配置
# 指定对应的真实库
spring.shardingsphere.datasource.names=m0,m1
# 配置真实库
spring.shardingsphere.datasource.m0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m0.driverclassname=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m0.url=jdbc:mysql://localhost:3306/coursedb?serverTimezone=UTC
spring.shardingsphere.datasource.m0.username=root
spring.shardingsphere.datasource.m0.password=root
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driverclassname=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/coursedb2?serverTimezone=UTC
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=root
#分布式序列算法配置
# 雪花算法,生成Long类型主键。
spring.shardingsphere.rules.sharding.keygenerators.alg_snowflake.type=SNOWFLAKE
spring.shardingsphere.rules.sharding.keygenerators.alg_snowflake.props.worker.id=1
# 指定分布式主键生成策略
spring.shardingsphere.rules.sharding.tables.course.keygeneratestrategy.column=cid
spring.shardingsphere.rules.sharding.tables.course.keygeneratestrategy.keygenerator-name=alg_snowflake
#配置实际分片节点
spring.shardingsphere.rules.sharding.tables.course.actualdatanodes=m$>{0..1}.course_$>{1..2}
#配置分库策略,按cid取模
spring.shardingsphere.rules.sharding.tables.course.databasestrategy.standard.sharding-column=cid
spring.shardingsphere.rules.sharding.tables.course.databasestrategy.standard.sharding-algorithmname=course_db_alg
spring.shardingsphere.rules.sharding.shardingalgorithms.course_db_alg.type=MOD
spring.shardingsphere.rules.sharding.shardingalgorithms.course_db_alg.props.sharding-count=2
#给course表指定分表策略 standard按单一分片键进行精确或范围分片
spring.shardingsphere.rules.sharding.tables.course.tablestrategy.standard.shardingcolumn=cid
spring.shardingsphere.rules.sharding.tables.course.tablestrategy.standard.shardingalgorithmname=course_tbl_alg
# 分表策略INLINE:按单一分片键分表
spring.shardingsphere.rules.sharding.shardingalgorithms.course_tbl_alg.type=INLINE
spring.shardingsphere.rules.sharding.shardingalgorithms.course_tbl_alg.props.algorithmexpression=course_$>{cid%2+1}

接下来再次执行addcourse的单元测试,就能看到,十条课程信息被按照cid的奇偶,拆分到了m0.course_1和m1.course_2两张表中。
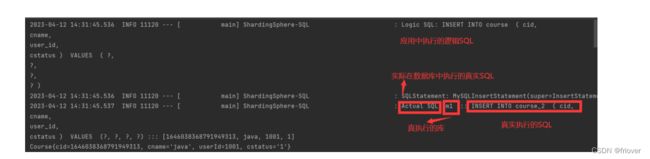
- 这个示例中,course信息只能平均分到两个表中,而无法均匀分到四个表中。这其实是根据cid进行计算的结果。而将course_tbl_alg的计算表达式改成 course_$->{((cid+1)%4).intdiv(2)+1} 后,理论上,如果cid是连续 递增的,就可以将数据均匀分到四个表里。但是snowsake雪花算法生成的ID并不是连续的,所以有时候还 是无法分到四个表。
#spring.shardingsphere.rules.sharding.sharding-algorithms.course_tbl_alg.props.algorithm-expression=course_$->{((cid+1)%4).intdiv(2)+1}
补充:尽量不要使用批量插入。

三、理解ShardingSphere的核心概念
- 虚拟库: ShardingSphere的核心就是提供一个具备分库分表功能的虚拟库,他是一个ShardingSphereDatasource实例。应用程序只需要像操作单数据源一样访问这个ShardingSphereDatasource即可。
- 真实库: 实际保存数据的数据库。这些数据库都被包含在ShardingSphereDatasource实例当中,由ShardingSphere决定未来需要使用哪个真实库。
- 逻辑表: 应用程序直接操作的逻辑表。
- 真实表: 实际保存数据的表。这些真实表与逻辑表表名不需要一致,但是需要有相同的表结构,可以分布在不同的真实库中。应用可以维护一个逻辑表与真实表的对应关系,所有的真实表默认也会映射成为ShardingSphere的虚拟表。
- 分布式主键生成算法: 给逻辑表生成唯一主键。由于逻辑表的数据是分布在多个真实表当中的,所有,单表的索引就无法保证逻辑表的ID唯一性。ShardingSphere集成了几种常见的基于单机生成的分布式主键生成器。比如SNOWFLAKE,COSID_SNOWFLAKE雪花算法可以生成单调递增的long类型的数字主键,还有UUID,NANOID可以生成字符串类型的主键。当然,ShardingSphere也支持应用自行扩展主键生成算法。比如基于Redis,Zookeeper等第三方服务,自行生成主键。
- 分片策略: 表示逻辑表要如何分配到真实库和真实表当中,分为分库策略和分表策略两个部分。分片策略由分片键和分片算法组成。分片键是进行数据水平拆分的关键字段。如果没有分片键,ShardingSphere将只能进行全路由,SQL执行的性能会非常差。分片算法则表示根据分片键如何寻找对应的真实库和真实表。简单的分片策略可以使用Groovy表达式直接配置,当然,ShardingSphere也支持自行扩展更为复杂的分片算法。
四、ShardingJDBC深入实战
1、简单INLINE分片算法
我们之前配置的简单分库分表策略已经可以根据自动生成的cid,将数据插入到不同的真实库当中。那么当然也支持按照cid进行数据查询。
/**
* 针对分片键进行精确查询,都可以使用表达式控制
* 对于in查询,4.x遇到混合分片结果,会直接走全分片路由。 新版本会进行精确分片
* select * from course where cid=xxx
*/
@Test
public void queryCourse() {
QueryWrapper<Course> wrapper = new QueryWrapper<Course>();
wrapper.eq("cid",3L);
// wrapper.in("cid",851198095084486657L,851198095139012609L,851198095180955649L,4L);
//带上排序条件不影响分片逻辑
wrapper.orderByDesc("user_id");
List<Course> courses = courseMapper.selectList(wrapper);
courses.forEach(course -> System.out.println(course));
}
像= 和 in 这样的操作,可以拿到cid的精确值,所以都可以直接通过表达式计算出可能的真实库以及真实表,ShardingSphere就会将逻辑SQL转去查询对应的真实库和真实表。这些查询的策略,只要配置了sql-show参数,都会打印在日志当中。
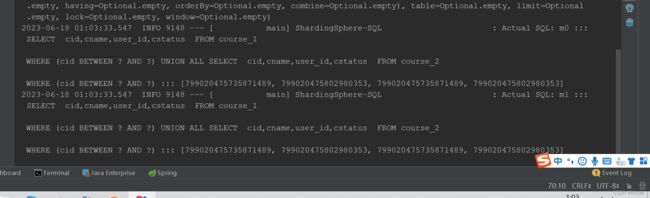
2、STANDARD标准分片算法
应用当中我们可能对于主键信息不只是进行精确查询,还需要进行范围查询。例如:
@Test
public void queryCourseRange(){
//select * from course where cid between xxx and xxx
QueryWrapper<Course> wrapper = new QueryWrapper<>();
wrapper.between("cid",799020475735871489L,799020475802980353L);
List<Course> courses = courseMapper.selectList(wrapper);
courses.forEach(course -> System.out.println(course));
}
这时,如果直接执行,那么由于ShardingSphere无法根据配置的表达式计算出可能的分片值,所以执行时他就会抛出一个异常。
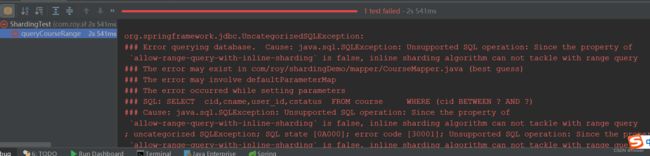
需要配置强行开始
spring.shardingsphere.rules.sharding.sharding-algorithms.course_tbl_alg.props.allow-range-query-with-inline-sharding=true
加上这个参数后,就可以进行查询了。但是这样就可以了吗?观察一下Actual SQL的执行方式,你会发现这时SQL还是按照全路由的方式执行的。之前一直强调过,这是效率最低的一种执行方式。那么有没有办法通过查询时的范围下限和范围上限自己计算出一个目标真实库和真实表呢?当然是支持的。记住这个问题。
3、COMPLEX_INLINE复杂分片算法
/**
* 使用COMPLEX_INLINE策略,使用多个分片键进行组合路由
* cid和user_id进行组合分片
*/
@Test
public void queryCourseComplexSimple(){
QueryWrapper<Course> wrapper = new QueryWrapper<Course>();
// wrapper.orderByDesc("user_id");
wrapper.in("cid",851198095084486657L,851198095139012609L);
// wrapper.between("cid",799020475735871489L,799020475802980353L);
wrapper.eq("user_id",1001L);
List<Course> course = courseMapper.selectList(wrapper);
//select * fro couse where cid in (xxx) and user_id between(8,3)
System.out.println(course);
}
执行一下,这当然是可以的。但是有一个小问题,user_id查询条件只能参与数据查询,但是并不能参与到分片算
法当中。例如在我们的示例当中,所有的user_id都是1001L,这其实是数据一个非常明显的分片规律。如果user_id的查询条件不是1001L,那这时其实不需要到数据库中去查,我们也能知道是不会有结果的。有没有办法让user_id也参与到分片算法当中呢?
当然是可以的, 不过STANDARD策略就不够用了。这时候就需要引入COMPLEX_INLINE策略。注释掉之前给course表配置的分表策略,重新分配一个新的分表策略:

#给course表指定分表策略 complex-按多个分片键进行组合分片
spring.shardingsphere.rules.sharding.tables.course.table-strategy.complex.sharding-columns=cid,user_id
spring.shardingsphere.rules.sharding.tables.course.table-strategy.complex.sharding-algorithm-name=course_tbl_alg
# 分表策略-COMPLEX:按多个分片键组合分表
spring.shardingsphere.rules.sharding.sharding-algorithms.course_tbl_alg.type=COMPLEX_INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.course_tbl_alg.props.algorithm-expression=course_$->{(cid+user_id)%2+1}
4、CLASS_BASED自定义分片算法
我们测试数据中的user_id都是固定的1001L,那么接下来我就可以希望在对user_id进行范围查询时,能够提前判断一些不合理的查询条件。而具体的判断规则,比如在对user_id进行between范围查询时,要求查询的下限不能超过查询上限,并且查询的范围必须包括1001L这个值。如果不满足这样的规则,那么就希望这个SQL语句就不要去数据库执行了。因为明显是不可能有数据的,还非要去数据库查一次,明显是浪费性能。
虽然对于COMPLEX_INLINE策略,也支持添加allow-range-query-with-inline-sharding参数让他能够支持分片键的范围查询,但是这时这种复杂的分片策略就明显不能再用一个简单的表达式来忽悠了。
package com.roy.shardingDemo.algorithm;
import com.google.common.collect.Range;
import org.apache.shardingsphere.sharding.api.sharding.complex.ComplexKeysShardingAlgorithm;
import org.apache.shardingsphere.sharding.api.sharding.complex.ComplexKeysShardingValue;
import org.apache.shardingsphere.sharding.exception.syntax.UnsupportedShardingOperationException;
import java.util.*;
/**
* 实现自定义COMPLEX分片策略
* 声明算法时,ComplexKeysShardingAlgorithm接口可传入一个泛型,这个泛型就是分片键的数据类型。
* 这个泛型只要实现了Comparable接口即可。
* 但是官方不建议声明一个明确的泛型出来,建议是在doSharding中再做类型转换。这样是为了防止分片键类型与算法声明的类型不符合。
* @auth roykingw
*/
public class MyComplexAlgorithm implements ComplexKeysShardingAlgorithm<Long> {
private static final String SHARING_COLUMNS_KEY = "sharding-columns";
private Properties props;
//保留配置的分片键。在当前算法中其实是没有用的。
private Collection<String> shardingColumns;
@Override
public void init(Properties props) {
this.props = props;
this.shardingColumns = getShardingColumns(props);
}
/**
* 实现自定义分片算法
* @param availableTargetNames 在actual-nodes中配置了的所有数据分片
* @param shardingValue 组合分片键
* @return 目标分片
*/
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, ComplexKeysShardingValue<Long> shardingValue) {
//select * from cid where cid in (xxx,xxx,xxx) and user_id between {lowerEndpoint} and {upperEndpoint};
Collection<Long> cidCol = shardingValue.getColumnNameAndShardingValuesMap().get("cid");
Range<Long> userIdRange = shardingValue.getColumnNameAndRangeValuesMap().get("user_id");
//拿到user_id的查询范围
Long lowerEndpoint = userIdRange.lowerEndpoint();
Long upperEndpoint = userIdRange.upperEndpoint();
//如果下限 》= 上限
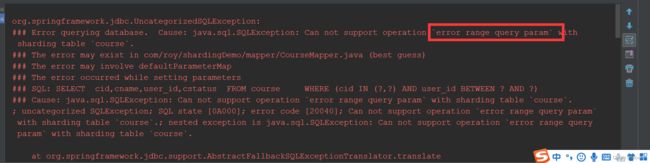
if(lowerEndpoint >= upperEndpoint){
//抛出异常,终止去数据库查询的操作
throw new UnsupportedShardingOperationException("empty record query","course");
//如果查询范围明显不包含1001
}else if(upperEndpoint<1001L || lowerEndpoint>1001L){
//抛出异常,终止去数据库查询的操作
throw new UnsupportedShardingOperationException("error range query param","course");
// return result;
}else{
List<String> result = new ArrayList<>();
//user_id范围包含了1001后,就按照cid的奇偶分片
String logicTableName = shardingValue.getLogicTableName();//操作的逻辑表 course
for (Long cidVal : cidCol) {
String targetTable = logicTableName+"_"+(cidVal%2+1);
if(availableTargetNames.contains(targetTable)){
result.add(targetTable);
}
}
return result;
}
}
private Collection<String> getShardingColumns(final Properties props) {
String shardingColumns = props.getProperty(SHARING_COLUMNS_KEY, "");
return shardingColumns.isEmpty() ? Collections.emptyList() : Arrays.asList(shardingColumns.split(","));
}
public void setProps(Properties props) {
this.props = props;
}
@Override
public Properties getProps() {
return this.props;
}
@Override
public String getType(){
return "MYCOMPLEX";
}
}
#给course表指定分表策略 complex-按多个分片键进行组合分片
spring.shardingsphere.rules.sharding.tables.course.table-strategy.complex.sharding-columns=cid,user_id
spring.shardingsphere.rules.sharding.tables.course.table-strategy.complex.sharding-algorithm-name=course_tbl_alg
# 分表策略-COMPLEX:按多个分片键组合分表
#spring.shardingsphere.rules.sharding.sharding-algorithms.course_tbl_alg.type=COMPLEX_INLINE
#spring.shardingsphere.rules.sharding.sharding-algorithms.course_tbl_alg.props.algorithm-expression=course_$->{(cid+user_id)%2+1}
# 扩展自定义的复杂分片算法- 模仿COMPLEX_INLINE的实现方式。
spring.shardingsphere.rules.sharding.sharding-algorithms.course_tbl_alg.type=MYCOMPLEX
# 使用CLASS_BASED分片算法- 不用配置SPI扩展文件
#spring.shardingsphere.rules.sharding.sharding-algorithms.course_tbl_alg.type=CLASS_BASED
# 指定策略 STANDARD|COMPLEX|HINT
spring.shardingsphere.rules.sharding.sharding-algorithms.course_tbl_alg.props.strategy=COMPLEX
# 指定算法实现类。这个类必须是指定的策略对应的算法接口的实现类。 STANDARD-> StandardShardingAlgorithm;COMPLEX->ComplexKeysShardingAlgorithm;HINT -> HintShardingAlgorithm
spring.shardingsphere.rules.sharding.sharding-algorithms.course_tbl_alg.props.algorithmClassName=com.roy.shardingDemo.algorithm.MyComplexAlgorithm
5、HINT_INLINE强制分片算法
接下来我们把查询场景再进一步,需要查询所有cid为奇数的课程信息。这要怎么查呢?
public interface CourseMapper extends BaseMapper<Course> {
@Select("select * from course where MOD(cid,2)=1")
List<Long> unsupportSql();
}
@Test
public void unsupportTest(){
//select * from course where mod(cid,2)=1
List<Long> res = courseMapper.unsupportSql();
res.forEach(System.out::println);
}
执行结果当然是没有问题。但是你会发现,分片的问题又出来了。在我们当前的这个场景下,course的信息就是按照cid的奇偶分片的,所以自然是希望只去查某一个真实表就可以了。这种基于虚拟列的查询语句,对于ShardingSphere来说实际上是一块难啃的骨头。因为他很难解析出你是按照cid分片键进行查询的,并且不知道怎么组织对应的策略去进行分库分表。所以他的做法只能又是性能最低的全路由查询。
HINT强制路由可以用一种与SQL无关的方式进行分库分表。
注释掉之前给course表分配的分表算法,重新分配一个HINT_INLINE类型的分表算法
/**
* 使用HINT强制路由策略。
* 脱离SQL自己指定分片策略。
* 强制查询course_1表
*/
@Test
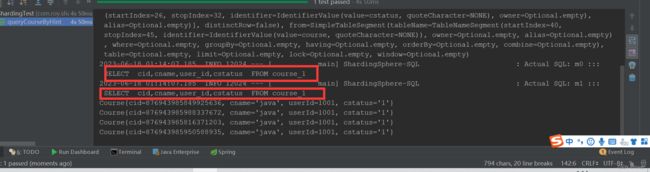
public void queryCourseByHint(){
//强制只查course_1表
HintManager hintManager = HintManager.getInstance();
//注意这两个属性,dataSourceBaseShardingValue用于强制分库
// 强制查course_1表
// hintManager.setDatabaseShardingValue(1L);
hintManager.addTableShardingValue("course","1");
//select * from course;
List<Course> courses = courseMapper.selectList(null);
courses.forEach(course -> System.out.println(course));
//线程安全,所有用完要注意关闭。
hintManager.close();
//hintManager关闭的主要作用是清除ThreadLocal,释放内存。HintManager实现了AutoCloseable接口,所以建议使用try-resource的方式,用完自动关闭。
//try(HintManager hintManager = HintManager.getInstance()){ xxxx }
}
#给course表指定分表策略 hint-与SQL无关的方式进行分片
spring.shardingsphere.rules.sharding.tables.course.table-strategy.hint.sharding-algorithm-name=course_tbl_alg
# 分表策略-HINT:用于SQL无关的方式分表,使用value关键字。
spring.shardingsphere.rules.sharding.sharding-algorithms.course_tbl_alg.type=HINT_INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.course_tbl_alg.props.algorithm-expression=course_$->{value}
五、总结
在之前的示例中就介绍了ShardingSphere提供的MOD、HASH-MOD这样的简单内置分片策略,standard、complex、hint三种典型的分片策略以及CLASS_BASED这种扩展分片策略的方法。为什么要有这么多的分片策略,其实就是以为分库分表面临的业务场景其实是很复杂的。即便是ShardingSphere,也无法真的像MySQL、Oracle这样的数据库产品一样,完美的兼容所有的SQL语句。因此,一旦开始决定用分库分表,那么后续业务中的每一个SQL语句就都需要结合分片策略进行思考,不能像操作真正数据库那样随心所欲了。