多模态之论文笔记BLIP,BLIP2,Instruct BLIP
文章目录
- BLIP
-
- 一. 简介
-
- 1.1 摘要与引言
- 1.2 相关工作
- 1.3 方法
-
- 模型结构
- 预训练目标函数
- CapFilt噪声过滤
- 1.4 实验以及讨论
-
- 实验设置
- CapFilt的讨论
- BLIP2
-
- 一. 简介
-
- 1.1 摘要与引言
- 1.2 相关工作
- 1.3 方法
-
- 模型结构
- 第一阶段 Bootstrap Vision-Language Representation Learning from a Frozen Image Encoder
- 第二阶段 Bootstrap Vision-to-Language Generative Learning from a Frozen LLM
- 模型预训练
- Instruct BLIP
-
- 一. 简介
-
- 1.1 摘要与引言
- 1.2 Vision-Language Instruction Tuning
- 1.3 Tasks and Datasets
- 1.3 Training and Evaluation Protocols
- 1.3 Instruction-aware Visual Feature Extraction
- 1.4 Training Dataset Balancing
- 1.5 Inference Methods
- 1.5 Implementation Details
- 1.6 Results and Analysis
- 1.7 Ablation Study on Instruction Tuning Techniques
- 1.7 Qualitative Evaluation
BLIP
一. 简介
题目: BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
机构:salesforce research
论文: https://arxiv.org/pdf/2201.12086.pdf
代码:https://github.com/salesforce/BLIP
任务: 视觉语言预训练
特点: 联合视觉语言理解以及生成,web 文本数据bootstrapping
方法: 模型侧设计了MED,数据侧用captioner以及filter进行文本的生成以及噪声过滤
前置相关工作:ALBEF
1.1 摘要与引言
视觉语言预训练(VLP)在许多视觉语言任务上取得了很好的表现。但现有的预训练模型大多数仅在基于理解的任务或者基于生成的任务取得了进展。除此之外,通过网上收集带噪声的海量图文尽管能够带来效果的提升,但往往是一个次优的监督数据源。本文中,我们提出了BLIP方法,一个新的视觉语言预训练框架,能够很灵活地迁移到视觉语言理解以及生成的任务。BLIP能够通过bootstrap文本描述来有效地利用带噪声的web数据,具体而言,使用一个captioner来生成新的文本描述以及用一个filter来剔除噪声文本描述。在许多视觉语言任务上取得了SOTA的结果,比如图文检索 +2.7% recall@1,image caption +2.8% CIDEr,VQA +1.6% acc。当用一种zero shot的方式直接迁移到视频语言任务,BLIP也表现出强大的泛化能力。代码,模型,数据集都进行了开源。
在引言部分,论文从模型的角度,对现有方法进行了划分:
encoder based: ALBEF 2021 ,CLIP 2021
encoder decoder model: VL-T5 2021, SimVLM 2021
对于encoder based的方法不太能直接迁移到caption等任务,对于encoder decoder的方法,也不能很好地适用于图文检索的任务。从数据的角度,比如CLIP,ALBEF,SimVLM用web的图像文本对进行预训练,尽管这种扩充数据的方式能带来效果上提升,但作者表明web的文本往往是对于视觉文本学习是次优的。
本文提出的BLIP从模型以及数据的角度做了如下的两点贡献:
【1】Multimodal mixture of Encoder-Decoder(MED):一个新的模型框架,用于有效的多任务学习以及灵活的迁移学习。一个MED可以既是一个单模态的encoder也可以是一个image-grounded text encoder或者一个image-grounded text decoder。模型是用三个视觉语言预训练目标来进行预训练的:图文对比学习,图文匹配,基于图像的语言建模。
【2】Captioning and Filtering(CapFilt): 一个新的数据集bootstraping算法来从带噪声的图文对中学习。我们用一个预训练好的MED在两个模块进行finetune:一个captioner来对web图像生成新的caption,一个filter来剔除带噪声的caption(无论是原始web文本还是说生成的新文本)。
通过captioner以及filter的合作,不仅能用bootstraping的caption取得下游任务的提升,也发现能生存更多样的captions。BLIP在图文检索,图像文本描述,视觉问答,视觉推理,视觉对话等任务上取得了SOTA的结果。并且在zero-shot迁移到视频文本任务:文本视频检索,视频QA上也取得了很好的结果。
1.2 相关工作
UNITER(2020), Oscar(2020), ALBEF(2021) 用web的图像文本对,Conceptual captions(2018),Conceptual 12M,Scaling up visual and vision-language representation learning with noisy text supervision(2021)尽管用了一些规则来进行过滤,但是噪声的负面影响还是被大多数工作忽略了。也有许多多任务统一的工作,比如 Unified vision-language pre-training for image captioning and VQA,2020,
Unifying vision and language tasks via text generation 2021,Simvlm: Simple visual language model pretraining with weak supervision 2021,作者理解的understanding task: 图文检索,generation task: image caption。相关工作还提到了知识蒸馏,数据增强
1.3 方法
模型结构

ViT做图像的encoder,将图像分为patches,然后编码为序列的特征,并用[CLS] token来表征全局图像特征。其中ALBEF以及ViLT也是用的ViT当作视觉encoder。为了让模型既有理解以及生成的能力,提出了multimodal mixture of encoder-decoder(MED),一个多任务模型能够实现下面的一些功能:
- 单模态encoder,文本编码器用的是BERT,也是用「CLS] token来表征文本的全局特征。
- Image-grounded text encoder: 将视觉信息进入注入,实现的方式是在文本编码器的每一层transfomer block里面的self-attention(SA)以及FFN之间插入一个cross-attention(CA)层。设计了一个[Encoder] token来表征图文对的多模态表征。
- Image-grounded text decoder: 将image-grounded text encoder中的双向self-attention layers替换为了causal self-attention layers. 一个[Decode] token被用于标识序列的开始,一个EOS被用于标示序列的结束。
预训练目标函数
在预训练的时候,联合训练了三个目标函数,其中两个是基于理解的,一个是基于生成的。每一个图像文本对会经过一次forward pass(visual transformer)以及三个forward pass (text transformer),这样通过计算下面的三个损失函数,不同的功能能够被激活。
Image-Text Contrastive Loss (ITC) 激活unimodal encoder. 它旨在对齐视觉transformer以及文本transformer的特征空间,利用postive的图文对相对于negative的图文对具有更相似的表征。在CLIP,以及ALBEF中都被证明是一种能够有效提升视觉语言理解的目标函数。本文用到的是ALBEF中的ITC损失函数,其中一个momentum encoder被引入来生成特征,soft labels被momentum encoder生成,并作为, and soft labels are created from the momentum encoder as training targets to account for the potential positives in the negative pairs.
Image-Text Matching Loss(ITM) 激活的是image-grounded text encoder. 它旨在学习图文多模态表征,并且捕获视觉文本中的细粒度对齐。ITM是一个二分类任务,用多模态表征过一个二分类的头,输出图文对是否是匹配的关系。为了寻找更有信息量的negatives,我们采用了ALBEF中的难例挖掘策略,即一个batch中有更高对比相似度的难例越有可能被选择来计算loss。(看样子上面都是albef的工作)
Language Modeling Loss(LM) 激活的是image grounded text decoder,它旨在生成给定图像的文本描述。它用一种自回归的方式来实现最大似然,优化交叉熵。采取了label smoothing的策略,参数是0.1,相比于在VLP中常用到的MLM的损失函数,LM能够让模型在将视觉信息转化为文本描述的时候有更好的泛化能力。
为了更好的用多任务进行预训练,text encoder和text decoder除了SA层之外共享所有的参数。原因是encoding和decoding task的编码区别主要体现在SA层。具体而言,encoder用了一种双向的self-attention来表征当前输入的token,而decoder采用的是causal self-attention来预测下一个token。另一个方面,embedding layer, CA layers, FFN在encoding和decoding任务中是比较相似的作用,因此选择共享用以提升训练的效率以及有利于多任务学习。
CapFilt噪声过滤

提出的主要目的是提升web图文对中text corpus的质量。其中captioner以及filter都是初始化于预训练的MED, 然后各自在coco上finetune。(finetune是一个非常轻量级的步骤)。具体而言,这个captioner是一个image grounded text decoder,它用LM目标函数来finetune。对于Iw生成Ts。这个Filter是一个image-grounded text encoder,它用ITC以及ITM来finetune,判断图文是否匹配。并对Tw和Ts中的噪声进行剔除。如果一个文本与一个图像被模型判定为不匹配的,那么这个文本将会被视作噪声。最终,用filtered的图文对以及人类标注的图文对构建了一个新的数据集,用于预训练一个新的模型。
1.4 实验以及讨论
实验设置
PyTorch
2个16 GPU的节点进行训练
ViT用的是ImageNet预训练过的
text transformer用的是BERT base. 探索了ViT base以及ViT large,如果不特殊说明,文中报的结果都是base的
batch size 2880(ViT base), 2400 (ViT large)
训练20个epoch
AdamW,weight decay 0.05.
learning rate: 3e-4 base, 2e-4 large, lr decay 0.85
预训练的时候224 * 224(随机crop),finetune的时候384*384。
预训练用了与ALBEF同样的14M数据,包括两个人类标注的数据,COCO以及VG,还有三个web的数据集Conceptual Captions,Conceptual 12M,SBU captions . 与此同时,也使用了LAION数据集,115M.(只下载了laion里面shorter size > 256的数据),因为laion的数据量很大,在预训练的时候,每个epoch也只用了1/5的数据。
CapFilt的讨论
capfilt在更大的数据集以及更大的视觉backbone上,性能能有更大的提升。
BLIP2
一. 简介
题目: BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
机构:salesforce research
论文: https://arxiv.org/pdf/2301.12597.pdf
代码:https://github.com/salesforce/LAVIS/tree/main/projects/blip2
任务: 视觉语言预训练
特点: 利用现有的frozen视觉以及LLM模型
方法: Q-Fomer,两阶段预训练
前置相关工作:BLIP, Flamingo80B, Frozen
1.1 摘要与引言
用end2end训练大模型的方式会导致VLP训练变得成本很高。因此这篇文章提出了BLIP2模型,它是通用且有效的,主要采用的方式是用现有的frozen pre-trained image encoders和frozen large language models来增强视觉语言预训练。BLIP2用了一个轻量的Querying Transformer来连接两个模态之间的鸿沟。第一阶段用frozen image encoder来增强视觉语言表征学习。第二阶段用frozen language model来增强视觉到语言的生成学习。BLIP2在许多视觉语言任务上取得了SOTA的结果,尽管相对于现有的许多方法,有更少的训练参数。比如,相比于Flaming80B在VQAv2上有8.7%zero shot的提升,但是只用了1/54的训练参数。本文也证明了模型具备遵循自然语言指令所表现出来的zero-shot的图像到文本的生成能力。
如果说BLIP解决的是数据集质量的问题,那么BLIP2主要针对的就是训练的成本问题,focus的点就是end2end训练大模型成本很高。因为视觉语言任务本身就是NLP与CV的交叉任务,因此我们自然而言,希望能够借力于现有的视觉或者NLP的单模态模型能力。因此本文提出了一个通用的并且计算效率高的BLIP2方法,用视觉模型来提供高质量的视觉表征,用LLM模型来提供强大的语言生成能力以及zero-shot迁移能力。为了减少计算代价以及避免灾难遗忘,单模态的预训练模型在训练的时候参数是固定的。
那么如何连接两个单模态呢?比如LLM模型是并没有见过图像的(在它自己的预训练阶段),当前的一些方法,比如Frozen以及Flamingo采用的是一个图像到文本生成的loss监督,我们发现,这样一个方式来架起不同模态横沟的桥梁是不够有效的。
因此本文提出的了一个Querying Transformer (Q- Former),(用一个两阶段的预训练方式),如图1所示,Q-Former是一个轻量级的transformer结构,用一组可学习的query vectors来从frozen的image encoder里面提取视觉特征。它扮演的是在冻住的image encoder和冻住的LLM之间充当信息瓶颈的角色。将最有用的视觉特征提供给LLM来生成合适的文本。在第一阶段的预训练阶段,我们旨在进行视觉语言表征学习,来让Q-Former学习与文本最相关的视觉特征。在第二阶段的预训练,我们旨在学习视觉到文本的生成能力,来连接起Q-Former的输出到一个冻住的LLM,这样Q-Forme输出的视觉特征能够被LLM理解。
LLM包含(OPT, FlanT5)等,借助LLM的能力,在自然语言的指令下,BLIP2能够在视觉推理,视觉对话等任务上提升zero-shot的图像到文本的生成能力。
OPT: open pre-trained transformer language models
Scaling instruction-finetuned language models.
1.2 相关工作
相关工作:
- End-to-end Vision-Language Pre-training
- Modular Vision-Language Pre-training
VLP常见的预训练loss,图文对比学习,图文匹配,(masked)语言建模。
基于模块化的VLP的关键,就是用一个冻住的LLM来与映射到文本空间的视觉特征对齐。
比如Frozen用的方式是finetune image encoders,其视觉输出直接当作soft prompts作为LLM的输入。
Flamingo是在LLM中插入一个新的cross attention层来注入视觉特征。然后用上百万的图文对来预训练这些新的层。
1.3 方法
关键词:Q-Former,两阶段
模型结构
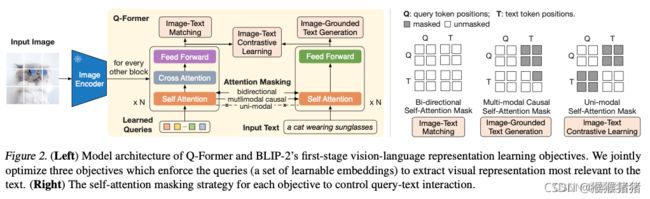
从上图可以看到,Q-Fomer包含两个transformer结构,其共享相同的self-attention layers。(1)一个图像transformer来从frozen的图像encoder里面提取视觉特征(2)一个文本transformer来充当文本编码器以及文本解码器的角色。我们创造了一系列的可学习的query embedding来作为image transformer的输入,这些queries在self-attention layers中彼此交互,然后与frozen image features在cross-attention layers产生交互。这些queries也能够与文本通过相同的self-attention layers产生交互。我们用Bert base来初始化Q-Former,cross-attention layers是随机初始化的。Q-Former总计188M训练参数,其中queries也被视作训练参数。
在文中的实验中,采用的是32个queries的设置,每个query的维度是768(与Q-Former的hidden dimension相同),query representation Z 32 ∗ 768 32 * 768 32∗768相比于frozen image features 257 ∗ 1024 257 * 1024 257∗1024 (ViT-L/14)来说,还是相对较小的,这个bottle-neck的结构在预训练目标函数的作用下同时起作用来让queries来提取与文本最相关的视觉信息。
Q: 如果理解这些Queries的作用?如果不用这种方式是否可以?
第一阶段 Bootstrap Vision-Language Representation Learning from a Frozen Image Encoder
与BLIP一样,用到了三个预训练目标函数,每一个目标函数采取了不同的attention mask策略来控制queries与文本的交互。具体见上图。
Image-Text Contrastive Learning (ITC) 旨在对齐图文特征来让它们的互信息最大,它用postive图文对的相似度比negative图文对的相似度高来实现,将来自image transformer的query特征Z和来自text transformer的text特征t进行对齐。其中后者是[CLS]这个token的embedding,因为Z包含了多个输出特征(一个query一个特征),因此首先计算每个query输出与t的相似度,然后选择相似度最好的那个得分作为图文相似度,为了避免信息泄漏,我们采用了一个unimodal self-attention mask,其中queries和文本彼此之间都不可见。因为采用的是一个冻住参数的image encoder,因此我们能够单GPU喂更多的样本,所以用in-batch negative而不是类似BLIP一样的momentum queue。
**Image-grounded Text Generation (ITG)**训练Q-Former来根据图像生成文本,因为Q-Former的结果不允许frozen image encoder和文本token产生直接的交互,因此生成文本的信息是由queries来抽取的,然后在self-attention层与文本token进行交互,因此queries需要去提取与文本相关的所有视觉信息,我们采取了一个多模态casual self-attention mask来控制query-text的交互。与UniLM一样,这些queries能够attend彼此,但是不能看到text token,每一个文本token能够看到所有的queries以及它前面的text tokens,我们替换了[CLS]为「DEC]来表示标明这个decoding任务的第一个文本token。
Image-Text Matching (ITM) 旨在学习图文特征之间的细粒度对齐,它是一个二分类任务。我们用一个双向的self-attention mask,其中所有的queries以及文本都能彼此attend。这样Z就能获取得到多模态信息,我们将每一个query embedding输入一个二分类器,然后得到一个logit,这样所有queries的logits得到它们的平均得到最终的匹配得分。像ALBEF一样,也采用了难例挖掘的策略来生成更好的负例。
第二阶段 Bootstrap Vision-to-Language Generative Learning from a Frozen LLM
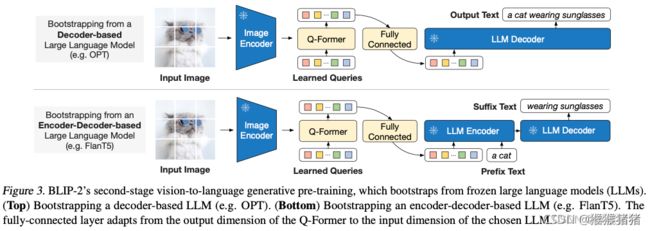
如上图所示,我们用了一个全连接层来将queries线性映射到与LLM text embedding一样的维度,这个映射之后的queries特征被prepend(前置)到文本特征之前。它们起到一种soft visual prompts的作用。因为Q-Former在第一阶段已经学习了这样一种图文的对齐,并且能够有效地提取与文本最相关的视觉信息,这样LLM也避免了去学习这样一种视觉文本的对齐,已经避免灾难遗忘的问题。
我们实验了两种类型的LLM,decoder-based以及encoder-deocder based,前者直接基于queries生成文本,后者用prefix language loss来预训练,我们将文本分为两个part,prefix text被concat在视觉特征后面,一起输入encoder,然后decoder输出suffix text。
模型预训练
数据:与BLIP一样,129M(COCO, VG, CC3M, CC12M, SBU, 115M from LAION400M),对于web images也采用了capFilt方法来创造生成的captions,每张图生成10个caption(用BLIP large),然后对11个caption做一个排序(基于图文相似度),然后保留了top2作为每张图的训练数据,在每一个预训练的step中随机sample。
预训练的图像encoder和LLM,前者探索了两个模型:(1) ViT-L/14 from CLIP, (2) ViT-g/14 from EVA-CLIP,去除了ViT的最后一层,用的是倒数第二层(有更好一点的表现),对于LLM,用OPT来做decoder-based的LLM,以及FlanT5作为encoder-decoder based LLM。
第一阶段250K
第二阶段80K
a batch size of 2320/1680 for ViT-L/ViT-g in the first stage and a batch size of 1920/1520 for OPT/FlanT5 in the second stage.
During pre-training, we convert the frozen ViTs’ and LLMs’ parameters into FP16, except for FlanT5 where we use BFloat16. We found no performance degradation compared to using 32-bit models. Due to the use of frozen models, our pre-training is more computational friendly than existing large-scale VLP methods. For example, using a single 16-A100(40G) machine, our largest model with ViT-g and FlanT5-XXL requires less than 6 days for the first stage and less than 3 days for the second stage.
The same set of pre-training hyper-parameters are used for all models. We use the AdamW (Loshchilov & Hutter, 2017) optimizer with 1 = 0.9, 1 = 0.98, and a weight decay of 0.05. We use a cosine learning rate decay with a peak learning rate of 1e-4 and a linear warmup of 2k steps. The minimum learning rate at the second stage is 5e-5. We use images of size 224⇥224, augmented with random resized cropping and horizontal flipping.
Instruct BLIP
一. 简介
题目: InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning
机构:salesforce research
论文: https://arxiv.org/pdf/2305.06500v1.pdf
代码:https://github.com/salesforce/LAVIS/tree/main/projects/instructblip
任务:
特点:
方法:
前置相关工作:BLIP, BLIP2,Flamingo
1.1 摘要与引言
通过预训练然后intruction微调的pipeline,通用目的的语言模型能够解决很多语言域的任务。然而,构建通用目的的视觉语言模型往往是有挑战的,因为额外的视觉输入往往增加了任务的差异(discrepancy)。虽然视觉语言预训练已经被广泛地探索,但是instruction微调却是相对少地被研究的。在这篇文章里面,我们基于BLIP2做了系统(systematic)且全面(comprehensive)的视觉语言instruction tuning的研究。我们采集了26个公开的数据集,将他们转化为instruction tuning的格式,并且将它们分类为两个clusters for held-in instruction tuning and held-out zero-shot evaluation。除此之外,我们引入了对instruction有感知的视觉特征抽取,在给定的instruction下,能够让模型抽取最有信息的视觉特征。在13个held-out的数据集上,Instruct BLIP展示出了sota的zero shot能力,超过了BLIP2以及更大的Flamingo。我们的模型finetune在独立的下游任务时,也取得了sota的结果,比如在ScienceQA IMG上取得了90.7%的准确率。除此之外,我们也定性地展示了InstructBLIP与现有的多模态模型相比的优势。所有的InstructBLIP模型都已经进行了开源。
通用的AI一直是我们所长期追求的,能够用一个统一的模型去处理不同的任务。在NLP领域,instruction tuning已经在这个目标上取得了可喜的成功。通过自然语言描述的instruction,让LLM在各种下游的任务上finetune,instruction tuning能够使得模型处理一系列novel的instructions。最近,instruction-tuned LLMs被用于视觉语言任务,比如BLIP2采用一个固定住的instruction-tuned LLMs去理解视觉输入,这能够保留原始的能力,即遵循指令来做图像到文本的生成。
然而,不同于NLP的任务,视觉语言任务天然是更加多样的,因为视觉的输入往往来自多个域,这也使得构建一个统一的模型然后泛化到一系列视觉语言任务上是有挑战的。之前的模型要么是通过一种多任务训练的方式(VL-T5 https://github.com/j-min/VL-T5)要么是直接诉诸于LLMs内在的泛化能力,比如Flamingo和BLIP2)。尽管如此,多任务训练,即使用了一个统一的输入输出格式,但还是不同很好地处理各种任务之间的差异性。在另外一方面,LLMs tuned on instructions在NLP任务上的zero-shot能力泛化性更好,但是在视觉语言任务上往往并没有表现出更好的结果。
为了处理之前提到的挑战,这篇文章提出了InstructBLIP,一个视觉语言instrcution tuning的框架,能够使得通过一个统一的自然语言接口,通用目的的模型来解决一系列的视觉任务。InstructBLIP是初始化于BLIP2(包含一个图像encoder,一个LLM以及两者之间的桥梁Q-Former。)在instruction tuning的过程当中,我们finetune了Q-Former然而保持图像encoder和LLM的参数固定。我们的论文做了如下主要的贡献:
- 我们做了广泛且系统的视觉语言instruction tuning的研究,我们将26个数据集转换为instruction tuning的格式,然后将他们划分为11个任务类别。其中,13个用于instruction tuning,然后13个被用于zerp shot的评测。除此之外,4个任务被专门保留,用于zero-shot的评测,大量定性以及定量的对比,展示了InstructBLIP在zero-shot视觉语言任务上的泛化性。
- 我们提出了instruction-aware的视觉特征抽取模块,能够基于instruction抽取有信息的视觉特征。值得一提的是,这个instruction不仅仅只用于给到frozen的LLM作为文本生成的条件,还给到Q-Former作为从frozen的image encoder抽取特征的条件。
- 我们评估并且开源了一套InstructBLIP模型,用了两个流派的LLM (1) FlanT5(一个encoder-decoder的LLM finetuned from T5),(2)Vicuna,一个decoder-only的LLM finetuned from LLaMA。InstrcutBLIP模型在很多视觉语言任务上取得了zero-shot的SOTA的结果。并且在各种独立的下游任务上,也取得了SOTA的fiunetune表现。
1.2 Vision-Language Instruction Tuning
首先:
- 介绍instruction-tuning data是如何构建的?
- 训练以及评价的方式
- 我们从数据和模型两个角度,介绍两个方法来提升instruction-tuning的表现。
1.3 Tasks and Datasets
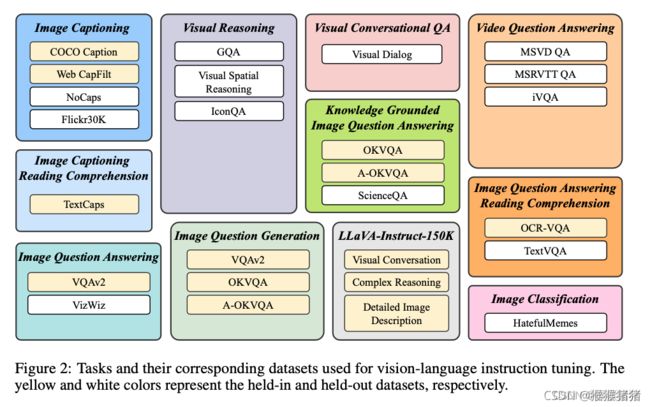 上图中,黄色代表held-in的13个数据集,白色代表held-out的数据集
上图中,黄色代表held-in的13个数据集,白色代表held-out的数据集
为了保证insctrution data的多样性,并且是可以获取得到,我们广泛收集了各种开源的视觉语言数据集,并且将它们转化成了instruction-tuning的格式。如上图所示,28个数据集被划分成了11个任务类别,包含Image Captioning,Image Captioning Reading Comprehension,Visual Reasoning,image question answering ,knowledge-grounded image question answering,image question answering with reading comprehension ,image question generation (inversed from the QA datasets),video question answering,visual conversational question answering,image classification,LLaVA-Instruct-150K。
对于每一个任务,我们用自然语言精心制作了(meticulously craft)了10到15个不同的instruction模版。这些模版作为构建tuning data的基础,阐明(articulates)任务并描绘(delineates)目标。因为公开的数据集往往倾向于更加短的response,我们用形如short以及briefly的字样加入到它们相应的instruction模版当中来避免模型过拟合总是生成非常短的response。对于LLaVA-Instrcuct-150K三个优化用户,我们没有添加其他额外的指令模板,因为它天然就是一种结构化的指令格式。
1.3 Training and Evaluation Protocols
为了包含(encompass)一系列任务来训练,但是也保留足够数量未见过的数据来做zero-shot的评测,我们将26个数据集划分为13个held-in和13个held-out的数据集,在上图分别是黄色和白色。我们将held-in数据集中的训练集用于instruction tuning,然后利用它们各自的验证集来做held-in的验证。
对于held-out的评估,我们的目标是理解instruction tuning是如何提高模型在未见数据上zero-shot的泛化性。在本文,我们定义了两种类型的held-out数据,(1)数据集并没有暴露给模型,在训练阶段的时候,但是部分任务是在held-in的cluster里面 (2)数据集和它们的任务都完全在训练阶段是没有见过的。处理第一种类型的held-out评价是非平凡的(nontrival)的,因为图像的分布漂移在held-in和held-out数据集之间。对于第二种类型,我们完全held-out了几个任务,包括visual-reasoning, video question answering, visual conversational QA以及image classification。
数据集是仔细挑选过的用于避免数据污染(contamination),即没有验证数据出现在held-in的训练cluster中,在instruction tuning的过程中,我们混合了所有的head-in训练集然后对每一个数据集均匀采样instruction模版。模型用标准的language modeling损失来训练,在给定instruction的基础上,直接预测response。除此之外,对于包含场景文本的数据集,我们加入了OCR的token来作为instrcution的附加信息。
1.3 Instruction-aware Visual Feature Extraction
现有的zero-shot图像到文本的生成方式,包含BLIP2在内,采用的是一个指令不可知( instruction-agnostic)的方法来进行视觉特征的抽取。即输入LLM的视觉信息是没有感知到instruction的,这也损害了模型跨任务的灵活性。与之形成对比的是,对instruction有感知的视觉模型,是能够提高模型学习以及遵循不同指令的能力的。可以想一下面的这些例子,给定一张相同的图,让模型完成两个不同的任务,以及给定两个不同的图,让模型完成同样的任务,第一个例子,一个instruction-aware的视觉模型能够抽取得到不同的特征(对于相同的图),得到更有信息的特征来处理不同的任务,对于第二个例子,一个instruction-aware的视觉模型能够利用包含在instruction中的共有知识来抽取两个不同图像的特征,这样更容易在不同的图像之间进行知识迁移。
通用BLIP2的Q-Fomer,InstructBLIP提出了一个instruction-aware 的视觉特征抽取方法。
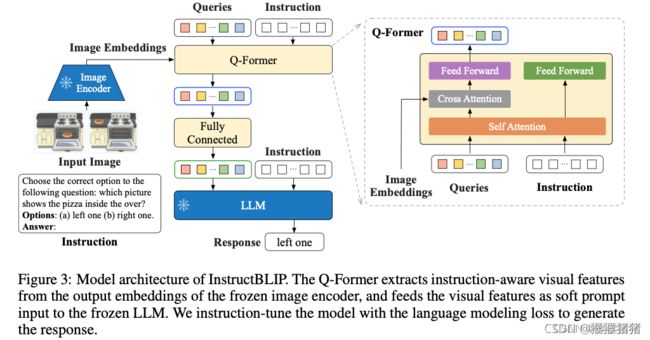
上图是InstructBLIP的模型结构,Q-Former能够从frozen的image encoder抽取得到与instruction相关的视觉特征,然后将这些视觉特征当作soft的prompts输入给frozen的LLM。我们基于language modeling的loss来instruction-tune这个模型去生成response。
具体而言,一系列可学习的query embedding通过cross-attention layer来与frozen image encoder产生交互,输出的queries然后被映射,并且作为frozen LLM的视觉prompts输入。BLIP2的Q-former是经过它原始的两阶段预训练的,因此它能够抽取与文本对齐的视觉特征并且能够很容易被LLM所吸收。在推理的时候,一个instruction被append到visual prompts的后面来引导LLM在不同的任务上起作用。
在InstructBLIP中,这个instrcution文本不仅仅作为LLM的输入,而且也作为Q-Former的输入。instruction通过self-attention层来与queries产生交互。来提出与instruction更有信息量的视觉特征。让LLM得到更有用的视觉信息来完成这个任务。在表2中,我们证明了感知指令的视觉特征提取为保留和保留评估提供了不平凡的性能改进。
1.4 Training Dataset Balancing
由于训练集数目很多,而每一个数据集样本数目是有比较大差别的。因此将它们均匀混合会让小的数据集过拟合,但是大的数据集欠拟合。为了缓解这个问题,我们提出了根据数据集规模来采样的算法( with a square root smoothing)。对于给定的D个数据集,它们的规模是 S 1 , S 2 , . . . . , S D {S_1, S_2, ...., S_D} S1,S2,....,SD,对于数据集d中的样本被采样到的概率是 p d = S d ∑ i = 1 D S d p_d = \frac{\sqrt{S_d}}{ \sum_{i=1}^{D}\sqrt{S_d}} pd=∑i=1DSdSd,除了这个加权的公式外,我们也手动地做了一些数据集权重的调整来加速收敛。这是有必要的,因为即使数据集有相同的尺寸,由于各个数据集内在的不同,也会导致它们需要不同的训练强度来训练。具体而言,我们下调了A-OKVQA (multi-choice) 的权重,但是增加了OKVQA的权重。在表2中,我们也表明了数据均衡的策略有利于提升held-in的验证表现,以及held-out的泛化表现。
1.5 Inference Methods
在推理的时候,我们采用了两个略微不同的生成方法来在不同的数据集上面做评估。对于大多数的数据集,比如image caption和开放性的VQA,instruction-tuned的模型是直接prompted去生成repsonses,这能够直接和gt做对比来计算指标。在另一方面,对于分类和多选QA任务,我们采取了一个词表排序的方法(类似的策略,在BLIP等方法中也用到过)。具体而言,会限制模型生成的答案在一系列的选项当中。然后我们计算每一个选项的log似然,并选择一个最高的值作为预测的结果。排序的方法被用在ScienceQA, IconQA, A-OKVQA (multiple-choice), HatefulMemes, and Visual Dialog datasets当中,除此之外,对于二分类的任务,也用yes/true,以及no/false来放在词表里面。
对于video QA任务,我们对于每个视频用了四个均匀采样的帧。每个帧,各自经过流程,然后它们的query embedding被concat起来作为LLM的输入。
1.5 Implementation Details
模型结构:
用LAVIS的工程来实现InstructBLIP,非常感谢BLIP2的模块化设计,让我们能够很快地将模型适配不同的LLM。我们采用了4个BLIP-2 的变种(相同的image encoder,ViT- g/14),但是不同的frozen LLMs,包含FlanT5-XL (3B), FlanT5-XXL (11B), Vicuna-7B and Vicuna-13B。在训练的时候,只微调Q-Former,至于image-encoder和LLM都保持不变。因为原始BLIP2是没有包含Vicuna的,因为本文也用BLIP2同样的流程来用Vicuna预训练。
训练和超参数:
60K steps训练,每隔3K进行一次验证,batch_size 192,128,64(3B, 7B, and 11/13B ),AdamW优化器, linear warmup lr(initial 1K steps, increasing from 10−8 to 10−5),然后进行cosine decay到0,16台A100 (40G)来进行训练,可以在两天以内完成整个训练。
1.6 Results and Analysis
Zero-shot Evalatuion

- 相对BLIP2, InstructBLIP FlanT5XL - BLIP-2 FlanT5XL = 15% in average
- instruction tuning提升了在未见任务上的zero-shot表现,比如video QA.上取得了47.1%的相对提升
- InstructBLIP FlanT5XL with 4B相比于Flamingo-80B也取得了24.8%的相对提升。
1.7 Ablation Study on Instruction Tuning Techniques
