python计算precision@k、recall@k和f1_score@k
sklearn.metrics中的评估函数只能对同一样本的单个预测结果进行评估,如下所示:
from sklearn.metrics import classification_report
y_true = [0, 5, 0, 3, 4, 2, 1, 1, 5, 4]
y_pred = [0, 2, 4, 5, 2, 3, 1, 1, 4, 2]
print(classification_report(y_true, y_pred))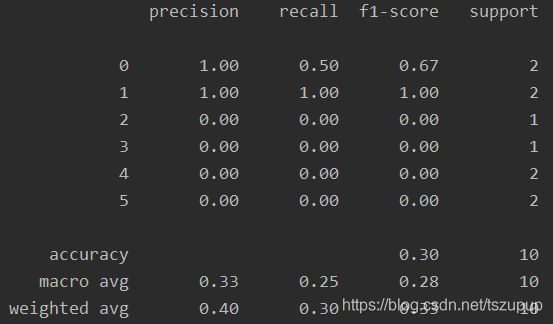
而我们经常会遇到需要对同一样本的top-k个预测结果进行评估的情况,此时算法针对单个样本的预测结果是一个按可能性排序的列表,如下所示:
y_true = [0, 5, 0, 3, 4, 2, 1, 1, 5, 4]
y_pred = [[0, 0, 2, 1, 5],
[2, 2, 4, 1, 4],
[4, 5, 1, 3, 5],
[5, 4, 2, 4, 3],
[2, 0, 0, 2, 3],
[3, 3, 4, 1, 4],
[1, 1, 0, 1, 2],
[1, 4, 4, 2, 4],
[4, 1, 3, 3, 5],
[2, 4, 2, 2, 3]]针对以上这种情况,我们要如何评估算法的好坏呢?我们需要precision@k、recall@k和f1_score@k等指标,下面给出计算这些指标的函数及示例。
from _tkinter import _flatten
# 统计所有的类别
def get_unique_labels(y_true, y_pred):
y_true_set = set(y_true)
y_pred_set = set(_flatten(y_pred))
unique_label_set = y_true_set | y_pred_set
unique_label = list(unique_label_set)
return unique_label
# y_true: 1d-list-like
# y_pred: 2d-list-like
# k:针对top-k各结果进行计算(k <= y_pred.shape[1])
def precision_recall_fscore_k(y_trues, y_preds, k=3, digs=2):
# 取每个样本的top-k个预测结果!
y_preds = [pred[:k] for pred in y_preds]
unique_labels = get_unique_labels(y_trues, y_preds)
num_classes = len(unique_labels)
# 计算每个类别的precision、recall、f1-score、support
results_dict = {}
results = ''
for label in unique_labels:
current_label_result = []
# TP + FN
tp_fn = y_trues.count(label)
# TP + FP
tp_fp = 0
for y_pred in y_preds:
if label in y_pred:
tp_fp += 1
# TP
tp = 0
for i in range(len(y_trues)):
if y_trues[i] == label and label in y_preds[i]:
tp += 1
support = tp_fn
try:
precision = round(tp/tp_fp, digs)
recall = round(tp/tp_fn, digs)
f1_score = round(2*(precision * recall) / (precision + recall), digs)
except ZeroDivisionError:
precision = 0
recall = 0
f1_score = 0
current_label_result.append(precision)
current_label_result.append(recall)
current_label_result.append(f1_score)
current_label_result.append(support)
# 输出第一行
results_dict[str(label)] = current_label_result
title = '\t' + 'precision@' + str(k) + '\t' + 'recall@' + str(k) + '\t' + 'f1_score@' + str(
k) + '\t' + 'support' + '\n'
results += title
for k, v in sorted(results_dict.items()):
current_line = str(k) + '\t' + str(v[0]) + '\t' + str(v[1]) + '\t' + str(v[2]) + '\t' + str(v[3]) + '\n'
results += current_line
sums = len(y_trues)
# 注意macro avg和weighted avg计算方式的不同
macro_avg_results = [(v[0], v[1], v[2]) for k, v in sorted(results_dict.items())]
weighted_avg_results = [(v[0]*v[3], v[1]*v[3], v[2]*v[3]) for k, v in sorted(results_dict.items())]
# 计算macro avg
macro_precision = 0
macro_recall = 0
macro_f1_score = 0
for macro_avg_result in macro_avg_results:
macro_precision += macro_avg_result[0]
macro_recall += macro_avg_result[1]
macro_f1_score += macro_avg_result[2]
macro_precision /= num_classes
macro_recall /= num_classes
macro_f1_score /= num_classes
# 计算weighted avg
weighted_precision = 0
weighted_recall = 0
weighted_f1_score = 0
for weighted_avg_result in weighted_avg_results:
weighted_precision += weighted_avg_result[0]
weighted_recall += weighted_avg_result[1]
weighted_f1_score += weighted_avg_result[2]
weighted_precision /= sums
weighted_recall /= sums
weighted_f1_score /= sums
macro_avg_line = 'macro avg' + '\t' + str(round(macro_precision, digs)) + '\t' + str(
round(macro_recall, digs)) + '\t' + str(round(macro_f1_score, digs)) + '\t' + str(sums) +'\n'
weighted_avg_line = 'weighted avg' + '\t' + str(round(weighted_precision, digs)) + '\t' + str(
round(weighted_recall, digs)) + '\t' + str(round(weighted_f1_score, digs)) + '\t' + str(sums)
results += macro_avg_line
results += weighted_avg_line
return results
if __name__ == '__main__':
y_true = [0, 5, 0, 3, 4, 2, 1, 1, 5, 4]
y_pred = [[0, 3, 2, 1, 5],
[2, 0, 4, 1, 3],
[4, 5, 1, 3, 0],
[5, 4, 2, 0, 3],
[2, 0, 1, 3, 5],
[3, 0, 4, 1, 2],
[1, 0, 4, 2, 3],
[1, 4, 5, 2, 3],
[4, 1, 3, 2, 0],
[2, 0, 1, 3, 4]]
res = precision_recall_fscore_k(y_true, y_pred, k=5, digs=2)
print(res)我们分别取k=1、k=2、k=3、k=4和k=5,看一下效果。
k=1时:
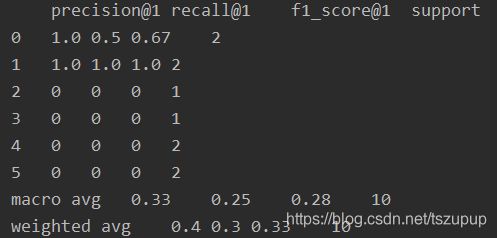
k=3时:
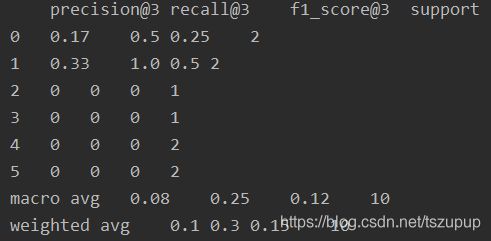
k=5时:
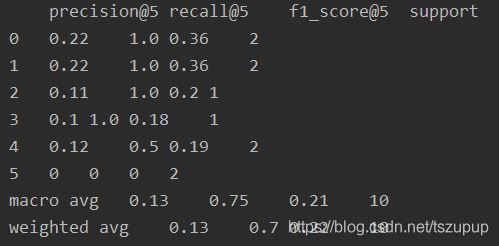
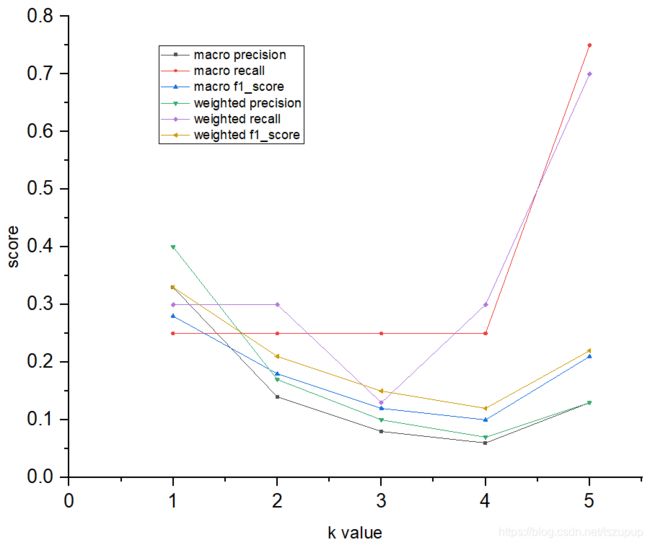
我们进一步看一下随着k值的增大,precision@k、recall@k和f1_score@k值的变化:
写作过程参考了
https://blog.csdn.net/dipizhong7224/article/details/104579159
https://blog.csdn.net/ybdesire/article/details/96507733