详细讲解分类模型评价指标(混淆矩阵)python示例
前言
1、回归模型(regression):
对于回归模型的评估方法,通常会采用平均绝对误差(MAE)、均方误差(MSE)、平均绝对百分比误差(MAPE)等方法。
2、聚类模型(clustering):
对于聚类模型的评估方法,较为常见的一种方法为轮廓系数(Silhouette Coefficient ),该方法从内聚度和分离度两个方面入手,用以评价相同数据基础上不同聚类算法的优劣。
3、分类模型(classification):
本文主要讲解分类模型评价的一种方法---混淆矩阵。混淆矩阵是评判模型结果的指标,属于模型评估的一部分。此外,混淆矩阵多用于判断分类器(Classifier)的优劣,适用于分类型的数据模型,如分类树(Classification Tree)、逻辑回归(Logistic Regression)、线性判别分析(Linear Discriminant Analysis)等方法。
在分类型模型评判的指标中,常见的方法有如下三种:

对于二分类问题,除了计算正确率方法外,我们常常会定义正类和负类,由真实类别(行名)与预测类别(列名)构成混淆矩阵。首先直观的来看看如下表格图(混淆矩阵图):

文字详细说明:
TN:将负类预测为负类(真负类)真实值是negative,模型认为是negative的数量
FN:将正类预测为负类(假负类)真实值是positive,模型认为是negative的数量
TP:将正类预测为正类(真正类)真实值是positive,模型认为是positive的数量
FP:将负类预测为正类(假正类)真实值是negative,模型认为是positive的数量
二级指标
最后根据混淆矩阵得出分类模型常用的分类评估指标:
准确率(Accuracy)—— 针对整个模型
精确率(Precision)
灵敏度(Sensitivity):就是召回率(Recall)
特异度(Specificity)
上述对应指标计算公式和定义如下面表格:

通过上面的四个二级指标,可以将混淆矩阵中数量的结果转化为0-1之间的比率。便于进行标准化的衡量。在这四个指标的基础上在进行拓展,会产令另外一个三级指标
三级指标
这个指标叫做F1 Score。他的计算公式是:

其中,P代表Precision,R代表Recall。
F1-Score指标综合了Precision与Recall的产出的结果。F1-Score的取值范围从0到1的,1代表模型的输出最好,0代表模型的输出结果最差。
混淆矩阵用途
混淆矩阵能够帮助我们迅速可视化各种类别误分为其它类别的比重,这样能够帮我们调整后续模型,比如一些类别设置权重衰减等在一些论文的实验分析中,可以列出混淆矩阵,行和列均为 label 种类,可以通过该矩阵验证自己 model 预测复杂 label 的能力是否强于其他 model,只要自己 model 将复杂 label 误判为其它类别比其他 model 误判的少,就可以说明自己 model 预测复杂 label 的能力强于其他 model。
Python代码示例
scikit-learn 准确率的计算方法:sklearn.metrics.accuracy_score(y_true, y_pred)
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_predict)scikit-learn 精确率的计算方法:sklearn.metrics.precision_score(y_true, y_pred)
from sklearn.metrics import precision_score
precision_score(y_test, y_predict)scikit-learn 召回率(灵敏度)的计算方法:sklearn.metrics.recall_score(y_true, y_pred)
from sklearn.metrics import recall_score
recall_score(y_test, y_predict)scikit-learn F1的计算方法:sklearn.metrics.f1_score(y_true, y_pred)
from sklearn.metrics import f1_score
f1_score(y_test, y_predict)ROC
曲线由两个变量TPR和FPR组成,这个组合以FPR(横轴)对TPR(纵轴),即是以代价(costs)对收益(benefits)。
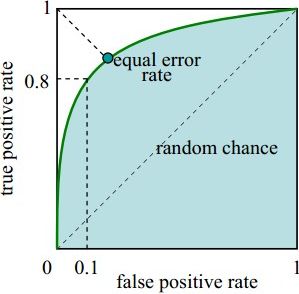
x轴为假阳性率(FPR):在所有的负样本中,分类器预测错误的比例

y轴为真阳性率(TPR):在所有的正样本中,分类器预测正确的比例(等于Recall)

由图可得:
当 FPR=0,TPR=0 时,意味着将每一个实例都预测为负例。
当 FPR=1,TPR=1 时,意味着将每一个实例都预测为正例。
当 FPR=0,TPR=1 时,意味着为最优分类器点。
所以一个优秀的分类器对应的ROC曲线应该尽量靠近左上角,越接近45度直线时效果越差。
scikit-learn ROC曲线的计算方法:
sklearn.metrics.roc_curve(y_true, y_score)AUC
AUC 的全称为 Area Under Curve,意思是曲线下面积,即 ROC 曲线下面积 。通过AUC我们能得到一个准确的数值,用来衡量分类器好坏。AUC图反映的是两个类的重叠程度,AUC的面积反应了分类的好坏。
AUC=1:最佳分类器。
0.5 AUC=0.5:分类器和随机猜测的结果接近。 AUC<0.5:分类器比随机猜测的结果还差。 scikit-learn AUC的计算方法:sklearn.metrics.auc(y_true, y_score)from matplotlib import pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_curve
from sklearn.metrics import auc
model = LogisticRegression()
model.fit(X_train,y_train.ravel())
y_score = model.decision_function(X_test) # model训练好的分类模型
fpr, tpr, _ = roc_curve(y_test, y_score) # 获得FPR、TPR值
roc_auc = auc(fpr, tpr) # 计算AUC值
plt.plot(fpr, tpr, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', linestyle='--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.legend()
plt.show()