Python 组合数据类型详细笔记
文章目录
- 概述
- 列表
-
- 列表创建
- 列表访问
-
- 访问列表元素
- 添加列表元素
- 修改列表元素
- 删除列表元素
- 列表复制和删除
-
- 列表复制
- 列表删除
- 列表运算
- 列表统计
- 列表查找与排序
-
- 列表元素查找
- 列表元素排序
- 元组
-
- 元组创建
- 元组访问
- 元组复制和删除
- 元组运算
- 元组统计
- 字典
-
- 字典创建
- 字典访问
-
- 访问字典
- 添加字典元素
- 修改字典元素
- 删除字典元素
- 字典复制和删除
- 集合
-
- 集合创建
- 集合访问
-
- 访问集合元素
- 添加和修改集合元素
- 删除集合元素
- 集合复制和删除
- 集合运算
- 集合统计
- 嵌套组合数据
- 推导式
概述
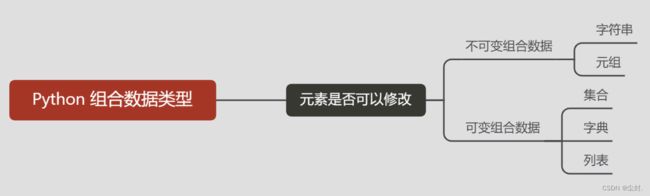
Python 中的组合数据类型类似于其他编程语言中的数组等,但是类型更多、功能更强大。在Python 中,除字符串外,组合数据类型主要包括列表、元组、集合和字典等。
组合数据类型还可以按照下面的方式区分:

列表
概念:列表是写在[ ]之间、用逗号隔开的元素集合。
应用:是Python 中使用最频繁、灵活性最好的数据类型,可以完成大多数集合类的数据结构实现。
特性:
- 列表中的元素可以是零个或多个。只有零个元素的列表称为空列表[]
- 列表中元素可以相同,也可以不相同。
- 列表中的元素可以类型相同,如[1,1,2,3];也可以类型不同,如[‘python’,14];还可以是更复杂的数据类型,如[(1,3),(4,‘timi’)]
- 列表和字符串一样都支持元素的双向索引。
列表创建
通常使用 [ ] 运算符或 list() 函数创建列表。
- 使用 [ ] 运算符创建列表
'''
一般格式: 列表名 = [元素1, 元素2, 元素3, ...]
元素: 可以是相同类型,也可以是不同类型,简单数据或组合数据
'''
list1 = [] # 空列表
list2 = [1.25, 21, -0.3, ] # 元素为实数
list3 = ["石油", "汽车", "cache"] # 元素为字符串
list4 = ['Alice', 16, 'jay', 2002] # 元素为数字和字符串混合
- 使用 list() 函数创建列表
'''
一般格式:列表 = list(sequence)
seqence: 可以是字符串、元组、集合或 range() 函数返回结果等迭代对
'''
list1 = list() # 空列表
list2 = list(("李白", "杜甫", "白居易")) # list() 参数为元组, ["李白", "杜甫", "白居易"]
list3 = list("素质教育") # list() 参数为字符串, ['素', '质', '教', '育']
list4 = list(range(3)) # list() 参数为range() 函数返回值, [0, 1, 2]
列表访问
访问列表元素
- 访问列表及元素
'''
可以使用列表名访问整个列表,也可以通过 list[ index ] 访问索引为 index 的元素。
'''
>>> carList = ["Java", "Python", "C", "C++"]
>>> print(carList)
['Java', 'Python', 'C', 'C++']
>>> print(carList[2])
C
>>> print(carList[-2])
C
carList = ["奔驰", "大众", "福特", "宝马", "奥迪", "雪佛兰"]
print("carList:",carList)
print("carList[2]:",carList[2])
- 列表切片
'''
Python 支持是用切片访问列表指定范围的元素,语法和字符串切片访问相同
'''
carList = ["奔驰", "大众", "福特", "宝马", "奥迪", "雪佛兰"]
print("carList[2:5]:",carList[2:5])
print("carList[2:5:2]:",carList[2:5:2])
print("carList[:]:",carList[:])
print("carList[:5]:",carList[:5])
print("carList[2:-1]:",carList[2:-1])
- 遍历列表
'''
可以使用 for 循环遍历列表,即逐个访问列表中的每个元素
'''
carList = ["奔驰", "大众", "福特", "宝马", "奥迪", "雪佛兰"]
print("世界汽车品牌: ",end=' ')
for car in carList:
print(car, end=' ')
添加列表元素
'''
列表创建后,可以使用列表函数或切片为列表添加新的元素。
list.append(newItem):在列表末尾添加新元素 newItem
list.insert(index, newItem):在索引为 index 的位置插入新元素 newItem
list.extend(seq): 在列表末尾添加迭代对象 seq 中的所有元素作为列表新元素
list[len(list):] = newList: 使用切片在列表 List 末尾添加新元素(newList 中的元素)
'''
list = ['sichuan', 'chongqing', 'guangdong', 'hunan']
list.append('jiangsu')
list.insert(2, "杭州")
list.extend(["重庆", "武汉"])
list[len(list):] = ['ningxia']
修改列表元素
'''
列表创建后,可以对列表中单个元素或指定范围元素(切片)进行修改
list[index] = newValue: 对指定索引 index 的列表元素进行修改
list[::] = newList: 对指定范围的列表元素进行修改
'''
list = ['sichuan', 'chongqing', 'guangdong', 'hunan']
list[0] = ''
list[1:3] = ["芒果", "木瓜"]
删除列表元素
'''
列表创建后,可以根据需要使用列表函数等删除指定元素或所有元素。
del list[index]: 删除索引为 index 的元素
list.pop():删除列表末尾的元素
list.pop(index):删除索引为 index 的元素
list.remove(item):删除列表元素 item
list.clear():删除列表中的所有元素
list[::] = []:对指定范围的列表元素进行删除
'''
'''
注意:
list.pop() 意为取出元素,即该元素在列表中删除的同时可以赋值给某个变量从而继续使用
list.remove() 中的参数是列表中实际存在的元素,而非元素下标
'''
# 列表删除
numlist = [1, 3, 7, 2, 5, 3, 4, ]
numlist.pop() # 取出末尾的元素
numlist.pop(3) # 取出元素下标为 3 的
del numlist[1] # 删除元素下标为 1 的
print(numlist)
numlist.remove(5) # 删除元素下标为 0 的
numlist[1:3] = [] # 删除元素下标为 1, 2 的
print(numlist)
numlist.clear() # 删除所有元素
print(numlist)
列表复制和删除
列表复制
在此处,涉及关于复制的类型是何种:深浅拷贝、浅拷贝、赋值
'''
1. 深拷贝(deepcopy)
list_copy = list: 列表深复制。当列表 list 改变时,list_copy 中的元素也会随之变化
2. 浅拷贝(shallow copy)
list_copy = list.copy(): 列表浅复制。当列表 list 改变时, list_copy 中的元素不会随之变化。
3. 赋值
在内存层面来看:
'''
列表删除
当列表不再使用后,可以使用 del 语句删除列表
'''
一般格式为:del list
'''
# 使用 del 删除列表
capital_List = ['beijing', 'bali']
print("capital_List = ", capital_List)
del capital_List # 删除整个列表,即内存中不存在
print("capital_List = ", capital_List) # 此时会发现系统报错,因为找不到一个叫做 capital_List 的变量,它已经被从内存中删去了
列表运算
| 运算符 | 含义 |
|---|---|
| + | 将多个列表组合成一个新列表,新列表中的元素是多个列表元素的有序组合 |
| * | 将整数 n 和列表相乘可以得到一个将原列表元素重复 n 次的新列表 |
| in | 用于判断给定对象是否在列表中,如果在则返回 True,否则返回 False |
| not in | 用于判断给定对象是否不在列表中,如果在则返回 True,否则返回 False |
| 关系运算符 | 两个列表之间可以使用 <、> 等关系运算符进行比较操作。规则是:从两个列表的第一个元素开始比较,如果比较有结果则结束,否则继续比较两个列表后面对应位置的元素 |
# 列表的运算
num_ls = [1, 2, 3, 4, 6]
str_ls = ['python', 'love']
connect_ls = num_ls + str_ls
print("num_ls + str_ls = ", connect_ls)
print("str_ls * 3 = ", str_ls * 3)
print("Yes! '1' in num_ls") if '1' in num_ls else print("Yes! '1' not in num_ls")
print("Yes! '1' not in num_ls") if '1' not in num_ls else print("Yes! '1' in num_ls")
print("Yes!") if str_ls[0] > str_ls[1] else print("No!")
列表统计
Python 中用于列表统计的常用函数如下:
| 函数名及用法 | 功能 |
|---|---|
| len(list) | 用于返回列表 list 中元素的个数 |
| max(list) | 返回列表 list 中元素的最大值 |
| min(list) | 返回列表 list 中元素的最小值 |
| sum(list) | 用于返回列表 list 中所有元素的和 |
| list.count(key) | 返回关键字 Key 在列表中出现的次数 |
# 列表统计
ls = [3, 2, 1, 3, 3, 33, 7, 6, 6, 4, 3, 23, 123, 56]
ls_len = len(ls)
ls_max = max(ls) # 会报错,因为只能在纯数字列表中使用,不能比较‘int’ 和 ‘str’
ls_min = min(ls) # 会报错,因为只能在纯数字列表中使用,不能比较‘int’ 和 ‘str’
ls_sum = sum(ls)
count_3 = ls.count(3)
print(ls_len, ls_max, ls_min, ls_sum, count_3)
列表查找与排序
列表元素查找
| 函数 | 功能 | 参数说明 |
|---|---|---|
| list.index(key) | 用于查找并返回关键字在列表中第1次出现的位置 | key 为要在列表中查找的元素 |
# 列表元素查找
ls = ['tiger', 'elephont', 'lion']
print('lion 第一次出现的位置是: ', ls.index('lion'))
列表元素排序
| 函数及用法 | 功能 |
|---|---|
| list.sort() | 对列表 list 中的元素按照一定的规则排序 |
| list.reverse() | 对列表 list 中的元素按照一定的规则反向排序 |
| sorted(list) | 对列表 list 中的元素进行临时排序,返回副本,但原列表中的元素次序不变 |
'''
tips:
1. sort函数为内部排序,没有返回值,所以在有些输入情况下会出现结果为 None
2. sort函数是永久性排序,会直接对原列表的排序内容进行更改
3. sorted函数则是临时性排序,不会对原本的列表内容进行更改,只会返回一个排序后的副本
4. reverse函数是永久性排序,会对原列表进行更改,返回值为 None
5.
'''
# 列表元素排序(sort)
ls = ['xiaoming', 'Jack', 'Mark', 'Baby']
ret = ls.sort()
print("sort 函数返回值为: ", ret) # None
print("排序后的结果为: ", ls) # 排序后的结果为: ['Baby', 'Jack', 'Mark', 'xiaoming']
# 对列表元素进行翻转
ls = ['xiaoming', 'Jack', 'Mark', 'Baby']
re_ls = ls.reverse()
print("reverse 函数返回值为: ", re_ls) # None
print("翻转后的列表为: ", ls) # 翻转后的列表为: ['Baby', 'Mark', 'Jack', 'xiaoming']
# 列表元素排序(sorted)
ls = ['xiaoming', 'Jack', 'Mark', 'Baby']
re_ls = sorted(ls)
print("sorted 函数返回值为: ", re_ls) # sorted 函数返回值为: ['Baby', 'Jack', 'Mark', 'xiaoming']
print("排序后的原列表为: ", ls) # 原列表不会发生改变
元组
- 元组(Tuple)是写在小括号内、用逗号隔开的元素集合。
- 元组创建后,对其中的元素不能修改,即元组创建后不能添加新元素、删除元素或修改其中的元素,也不能对元组进行排序等操作。
- 元组中的元素类型可以相同或不同,其中的元素可以重复或不重复,可以是简单或组合数据类型。
- 元组下标从0开始,支持双向索引。
元组创建
- 使用小括号 () 创建元组。
| 一般格式 | 参数说明 |
|---|---|
| 元组名 = (元素1,元素2,元素3,…) | 元素:可以是相同或不同类型,简单数据类型或组合数据类型 |
tuple1 = ()
tuple2 = (1, 8, 27, 64, 125)
tuple3 = ("计算机科学", "生物信息", "电子工程")
tuple4 = ("华为", 701, "中兴", 606)
- 使用 tuple() 函数创建元组。
| 一般格式 | 参数说明 |
|---|---|
| 元组名 = tuple(sequence) | sequence:可以是字符串、元组、列表或 range() 函数返回值等迭代对象 |
tuple5 = tuple(["莎士比亚", "托尔斯泰", "但丁", "雨果", "歌德"])
tuple6 = tuple("理想是人生的太阳")
tuple7 = tuple(range(1,6))
元组访问
- 访问元组及指定元素
'''
1、使用元组名访问
2、通过 tuple[index]访问指定索引为 index 的元组元素
'''
# 元组访问
city = ('beijing', 'shanghai', 'ningxia', 'chongqing')
print("中国部分城市名称: ", city) # 全部访问
print("第二个城市名是: ", city[1]) # 访问特定的元素
- 元组切片
city = ('beijing', 'shanghai', 'ningxia', 'chongqing')
print("中间两个城市名称是: ", city[1:3])
print("倒序输出: ", city[::-1])
print("除去最后一个城市后的城市:", city[:-1])
- 遍历元组
'''
可以使用for语句遍历元组,逐个访问元组中的每个元素
'''
# 元组遍历
city = ('beijing', 'shanghai', 'ningxia', 'chongqing')
print("中国部分城市名称: ", end=' ')
for name in city:
print(name, end=' ')
元组复制和删除
- 元组使用 = 运算符直接进行复制
- 使用 del 进行删除元组
# 元组复制
city = ('beijing', 'shanghai', 'ningxia', 'chongqing')
cp_city = city
print(cp_city) # ('beijing', 'shanghai', 'ningxia', 'chongqing')
# 元组删除
del cp_city
print(cp_city) # 报错,因为已经删除
元组运算
| 运算符 | 含义 |
|---|---|
| + | 将多个元组组合成一个新元组,新元组中的元素是多个元组元素的有序组合 |
| * | 将整数 n 元组y相乘可以得到一个将原元组元素重复 n 次的新元组 |
| in | 用于判断给定对象是否在元组中,如果在则返回 True,否则返回 False |
| not in | 用于判断给定对象是否不在元组中,如果在则返回 True,否则返回 False |
| 关系运算符 | 两个元组之间可以使用 <、> 等关系运算符进行比较操作。规则是:从两个元组的第一个元素开始比较,如果比较有结果则结束,否则继续比较两个元组后面对应位置的元素 |
# 元组运算
num_tuple = (1, 2, 3, 4, 6)
str_tuple = ('python', 'love')
connect_tuple = num_tuple + str_tuple
print("num_tuple + str_tuple = ", connect_tuple)
print("str_tuple * 3 = ", str_tuple * 3)
print("Yes! '1' in num_tuple") if '1' in num_tuple else print("Yes! '1' not in num_tuple")
print("Yes! '1' not in num_tuple") if '1' not in num_tuple else print("Yes! '1' in num_tuple")
print("Yes!") if str_tuple[0] > str_tuple[1] else print("No!")
元组统计
| 函数名及用法 | 功能 |
|---|---|
| len(tuple) | 用于返回元组tuple 中元素的个数 |
| max(tuple) | 返回元组tuple 中元素的最大值 |
| min(tuple) | 返回元组tuple 中元素的最小值 |
| sum(tuple) | 用于返回元组tuple 中所有元素的和 |
| tuple.count(key) | 返回关键字 Key 在元组中出现的次数 |
# 元组的统计与计算
pellTuple = (0, 1, 2, 5, 12, 29, 70, 169, 408, 985)
print("元组中元素最大值:", max(pellTuple))
print("元组中元素最小值:", min(pellTuple))
print("元组所在元素的和:", sum(pellTuple))
print("元素 %d 在元组中出现次:%d次." % (5, pellTuple.count(5)))
print("元组中的元素个数: %d" % (len(pellTuple)))
# 使用 index() 查找关键字在元组中第一次出现的位置
print("12 出现的第一次位置是:", pellTuple.index(12) + 1)
字典
- 字典是一种映射类型,用 { } 标识,是一个无序的“键(key) : 值(value)”对集合。
- 键(key) 是不可变类型(不可以改哦,只能直接删去再添加(删前面先保存值)),如:字符串、数字等
- 值(value) 可以是简单数据或组合数据等不同类型
- ==同一个字典中,键(key) 必须是唯一的,值(value) 可以是不唯一的
- 字典不通过索引(index) 访问和操作元素,通过键来访问和操作元素
字典创建
- 使用 { } 运算符创建字典
'''
一般格式: 字典名 = {key1:value1, key2:value2, key3:value3, ...}
'''
# 创建字典
dict1 = {} # 空字典
dict2 = {'name': 'xiaoming', 'age': 23, } # 非空字典
- 使用 dict() 函数创建字典
'''
1. dict(**kwarg):以关键字创建字典, **kwargs 为关键字。
2. dict(mapping, **kwarg): 以映射函数方式构造字典。mapping 为元素的容器。
3. dict(iterable, **kwarg): 以可迭代对象方式构造字典,iterable 为可迭代对象。
'''
# 创建字典
dict1 = dict() # 空字典
dict2 = dict(name = 'xiaoming', age = 16, weight = 51) # 以关键字创建字典
dict3 = dict(zip(["name", "age", "height"], ["Jack", 13, 20])) # 映射方式,用到了 zip 函数
dict4 = dict([('name', 'red'), ('size', 120)]) # 以迭代对象方式创建
字典访问
访问字典
- 可以通过字典名访问字典。
- 通过 " dict[key] "或 " dict.get(key) " 访问指定元素。
- 可以遍历字典中所有元素。遍历字典会用到如下函数:
| 形式 | 功能 |
|---|---|
| dict.items() | 以列表形式(中括号)返回字典中所有的 “键/值” 对,每个 “键/值” 以元组形式(小括号)存在 |
| dict.keys() | 以列表形式返回字典中所有的键 |
| dict.values() | 以列表形式返回字典中所有的值 |
"""访问字典里的值"""
dict1 = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}
print("dict1: ", dict1)
print("dict1 的个数: ", len(dict1))
print("dict1['Name']:", dict1['Name'])
print("dict1['Age']:", dict1['Age'])
print("Name:", dict1.get("Name"))
# 字典遍历
LSZ_dict = {"姓名": "李时珍", "出生时间": 1518, "籍贯": "湖北", "职业": "医生"}
print("字典里的所有键-值: ", end="")
for key, value in LSZ_dict.items():
print(key, value, end=", ")
print()
print("字典中所有的键: ", end="")
for key in LSZ_dict.keys():
print(key, end=', ')
print()
print("字典中所有的值: ", end='')
for value in LSZ_dict.values():
print(value, end=', ')
print()
添加字典元素
向字典添加新元素的方式是增加新的 “键/值” 对。
"""增加新的键/值对,修改或删除已有键/值对"""
dict1 = {} # 空字典
dict1['Age'] = 8
dict1['School'] = "DPS School"
print("dict1['Age']:", dict1['Age'])
print("dict1['School']:", dict1['School'])
修改字典元素
修改字典元素的方法是:给字典元素赋予新的值,dict[key] = value
# 修改字典元素
dict1 = {'name': 'xiaohua', 'Ssex': 'man', }
print("修改前 dict1[name]: ", dict1['name'])
dict1['name'] = 'Jack'
print("修改后 dict1[name]: ", dict1['name'])
删除字典元素
| 函数 | 功能 |
|---|---|
| del dict[key] | 删除关键字为 key 的元素 |
| dict.pop(key) | 删除关键字为 key 的元素 |
| dict.popitem() | 随即删除字典中的元素 |
| dict.clear() | 删除字典中所有的元素 |
| del dict | 删除字典 |
"""删除字典"""
dict1 = {"姓名": "李时珍", "出生时间": 1518, "籍贯": "湖北", "职业": "医生"}
del dict1['姓名'] # 删除键是’Name‘的条目
print('删去后的 dict1 :', dict1) # 删去后的 dict1 : {'出生时间': 1518, '籍贯': '湖北', '职业': '医生'}
dict1.pop('职业')
print('删去后的 dict1 :', dict1) # 删去后的 dict1 : {'出生时间': 1518, '籍贯': '湖北'}
dict1.popitem()
print('删去后的 dict1 :', dict1) # 删去后的 dict1 : {'出生时间': 1518}
dict1.clear() # 清空词典所有条目
print('删去后的 dict1 :', dict1) # 删去后的 dict1 : {}
del dict1 # 删除词典
print('删去后的 dict1 :', dict1) # 字典整体被删除,不存在,所以报错
字典复制和删除
- 浅复制:使用 dict.copy() 函数
- 深复制:使用 = 运算符
- 删除字典,使用 del dict ,上文提到过
在这里插入代码片
集合
-
集合(Set) 是一个放置在小括号() 之间、用逗号分隔、无序且不重复(集合中所有的元素均只能出现一次,可参考数学中的集合概念)的元素集合。
-
不可以为集合创建索引或执行切片操作。
-
也没有键可用来获取集合中的元素的值。
集合创建
- 使用 { } 运算符创建集合(这种方法其实不常、甚至不使用,因为字典的创建也可以通过这种方式,所以 python 默认这种方式创建的类型是字典,集合多使用第二种方式创建)
'''
一般形式:集合名 = {元素1, 元素2, 元素3,…}
元素:可以是相同或不同类型,简单数据类型或组合数据类型
'''
# 集合元素的创建
set1 = {1, 3, 4, 23, 55} # 一种元素类型
set2 = {'python', 'love', 1, 'str', (5, 4)} # 多种元素类型
- 使用 set() 函数创建集合
'''
一般格式:集合名 = set(sequence)
sequence:可以是字符串、元组、列表或 range() 函数返回值等迭代对象
'''
# 集合元素的创建
set3 = set() # 空集合
set4 = set([1, 2, 3, 1, 2, 3, 5]) # 列表转换为集合
set5 = (range(1, 10, 3)) # range() 函数转化集合
集合访问
访问集合元素
- 集合中的元素无序,因此不能通过索引访问指定元素。
- 访问指定元素可以先将集合转化为列表元组等数据类型再进行索引访问。
- 但是可以通过集合名访问整个集合,还可以遍历集合中的所有元素。
# 集合元素的访问
tourismSet = {"beijing", 'shanghai', 'chongqing'}
print("city name : ", tourismSet)
print("city name : ", end='')
for name in tourismSet:
print(name, end=' ')
添加和修改集合元素
| 函数 | 功能 |
|---|---|
| set.add(item) | 在集合中添加新元素 item |
| set.update(sequence) | 在集合中添加或修改元素。sequence 可以是列表、元组和集合等 |
# 集合元素的添加和修改
phoneSet = {"华为", "苹果"}
print("手机品牌: ", phoneSet)
phoneSet.add("小米")
print("set.add()添加元素后: ", phoneSet)
phoneSet.update(["华为", "Oppo", "Vivo"])
print("set.update()添加元素后: ", phoneSet)
删除集合元素
| 函数 | 功能 |
|---|---|
| set.remove(item) | 删除指定元素 item |
| set.discard(item) | 删除指定元素 item |
| set.pop() | 随机删除集合中的元素 |
| set.clear() | 清空集合中的 所有元素 |
# 集合元素的删除
word_tournament_set = {"世界杯排球赛", "世界乒乓球锦标赛", "世界篮球锦标赛", "世界足球锦标赛"}
print("世界大赛:", word_tournament_set)
word_tournament_set.remove("世界足球锦标赛") # 删除指定集合元素,discard 同理
print("set.remove()删除元素后:", word_tournament_set)
word_tournament_set.pop() # 随机删除集合元素
print("set,pop()删除元素后: ", word_tournament_set)
word_tournament_set.clear() # 清空集合元素
print("set.clear()清空元素后: ", word_tournament_set)
集合复制和删除
- 对集合也可以进行浅复制(使用 set.copy() 函数)和深复制(使用 = 运算符)。
- 当不需要集合时,可以使用 del 语句删除集合。
在这里插入代码片
集合运算
可以参考数学中对集合的运算规则。
| 形式1 | 形式2 | 含义 |
|---|---|---|
| set1.union(set2) | set1 | set2 | 并集运算,结果为在集合 set1 或在集合 set2 中的所有元素 |
| set1.intersection(set2) | set1 & set2 | 交集运算,结果为同时在集合 set1 和 set2 中的所有元素 |
| set1.difference(set2) | set1 - set2 | 差集运算,结果为在集合 set1 但不在集合 set2 中的所有元素 |
| set1.issubset(set2) | set1 < set2 | 子集运算,如果集合 set1 是 set2 的子集则返回 True,否则返回 False |
| item in set | item not in set | 成员运算,判断 item 是否在集合 set 中的成员,是则返回True,否则返回 False |
# 集合元素的并、交、差操作
a_set = set([8, 9, 10, 11, 12, 13])
b_set = {0, 1, 2, 3, 7, 8}
c_set = {1, 3}
"""并集"""
print(a_set | b_set)
print(a_set.union(b_set))
"""交集"""
print(a_set & b_set)
print(a_set.intersection(b_set))
"""差集"""
print(a_set - b_set)
print(a_set.difference(b_set))
"""自己运算"""
print(c_set < b_set)
"""成员运算"""
print('3' in b_set)
集合统计
| 函数名及用法 | 功能 |
|---|---|
| len(Set) | 用于返回集合Set 中元素的个数 |
| max(Set) | 返回集合Set 中元素的最大值 |
| min(Set) | 返回集合Set 中元素的最小值 |
| sum(Set) | 用于返回集合Set 中所有元素的和 |
# 集合统计
num_set = {1, 3, 6, 10, 15, 21, 28, 36, 45, 55}
print("集合中元素最大值: ", max(num_set))
print("集合中元素最小值: ", min(num_set))
print("集合中所有元素的和: ", sum(num_set))
print("集合中元素的个数: %d 个 " % (len(num_set)))
嵌套组合数据
当组合数据中的元素为组合数据时,称为嵌套组合数据,如嵌套列表中的元素是列表、元组、字典和集合等,嵌套字典中的元素是列表、字典、元组和集合等。
在这里插入代码片
推导式
'''
通过推导式可以快速的创建列表、元组、字典和集合等。
推导式一般在 for 之后跟一个表达式,后面有领导多个 for 或 if 字句
一般格式(列表): [表达式 for 变量 in 列表 [if 条件]]
其中:if 条件表示对列表中元素的过滤、可选
元组、字典、集合等推导式的创建与列表创建类似,只需要将外层 [] 替换成相应的 () 或 {}
'''
# 使用推导式创建列表
list1 = [x ** 2 for x in range(6)]
list2 = [[x, pow(10, x)] for x in range(4)]
list3 = [abs(x) for x in [1, -2, 3, -4, 5, -6] if x < 0]
list4 = [1, 2, 3]
list5 = [4, 5, 6]
list6 = [(x, y) for x in list4 for y in list5]
# 使用推导式创建集合
list1 = [1, 2, 3, 3, 2, 4]
set1 = {item for item in list1}
set2 = {str.title() for str in {'chinese', 'america', 'england'}} # 首字母大写
# 使用推导式创建字典
dict1 = {i: i % 3 == 0 for i in range(1, 11)}
chineseList = ['运动', '饮食', '营养']
englishList = ['motion', 'diet', 'nutrition']
dict2 = {chineseList[i]: englishList[i] for i in range(len(chineseList))}
# 使用推导式创建元组
questionList = ['name', 'profession', 'favorite']
answerList = ['Linda', 'programming', 'music']
tp1 = tuple(zip(questionList, answerList))
写在最后:
首先,如果本篇文章有任何错误,烦请读者告知!不胜感激!
其次,本篇文章仅用于日常学习以及学业复习,如需转载等操作请告知作者(我)一声!
最后,本文会持续修改和更新,如果对本分栏的其他知识也感兴趣,可以移步目录导航专栏,查看本分栏的目录结构,也更方便对于知识的系统总结!
兄弟姐妹们,点个赞呗!
感谢!笔芯!