【量化交易笔记】7.基于随机森林预测股票价格
前言
机器学习在量化交易主要有两方面的应用,第一就是用时间序列的日频数据来预测未来的股价,第二 用截面数据来预测收益,现在量化基因的因子都基于这个模型。
接下来,我分别来说明,机器学习分成预测结果分成分类和回归。本章,就以随机森林来做未来某天的股价,是一种典型的回归分析方法,如果预测股价的涨跌就是分类问题。在这里有很多坑,我帮小伙伴一一填平。
获取数据
这部分内容,在之前的章节有详细说明,现以sh.60000为例,从2019年1月1日 到至今天(2023-5-31)。
# 加载相应的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus']=False
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import make_scorer,mean_squared_error,mean_absolute_error
# 加载数据
df=pd.read_csv("data/sh.600000.csv",parse_dates=["date"],index_col=[0])
df.head()
| date | code | open | high | low | close | preclose | volume | amount | adjustflag | turn | tradestatus | pctChg | isST |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2019-01-02 | sh.600000 | 8.079311 | 8.120785 | 7.946591 | 8.046131 | 8.129080 | 23762822 | 229625669.0 | 2 | 0.084554 | 1 | -1.020412 | 0 |
| 2019-01-03 | sh.600000 | 8.046131 | 8.145670 | 8.012951 | 8.137375 | 8.046131 | 18654262 | 181975985.0 | 2 | 0.066376 | 1 | 1.134027 | 0 |
| 2019-01-04 | sh.600000 | 8.071016 | 8.294980 | 8.046131 | 8.261800 | 8.137375 | 27172844 | 268964563.0 | 2 | 0.096688 | 1 | 1.529048 | 0 |
| 2019-01-07 | sh.600000 | 8.369635 | 8.369635 | 8.228620 | 8.278390 | 8.261800 | 23597376 | 235440197.0 | 2 | 0.083965 | 1 | 0.200798 | 0 |
| 2019-01-08 | sh.600000 | 8.319865 | 8.319865 | 8.220325 | 8.261800 | 8.278390 | 15104933 | 150501650.0 | 2 | 0.053747 | 1 | -0.200396 | 0 |
分离数据
由于是时间序列,特征选 'open','high','low','close','volume','turn',我们目标值(标签)需要进行一处理,我们就选用30天后的收盘价。利用shitt函数,即data.close.shift(-30)。
cols=['open','high','low','close','volume','turn']
data=df[cols]
data['target']=data.close.shift(-30)
将数据集拆分为训练集、验证集和测试集。由于这个数据集是时间序列,决不能不能用train_test_split 进行分拆数据。
train=data[data.index<='2022-12-31']
vali=data[data.index>'2022-12-31'][:-30]
test=data[-30:]
建模
X_train,X_valid,y_train,y_valid=train.iloc[:,:-1],valid.iloc[:,:-1],train.target,valid.target
rfr=RandomForestRegressor()
rfr.fit(X_train,y_train)
y_pred = rfr.predict(X_train)
y_valpred=rfr.predict(X_valid)
评估
print('MSE:',mean_squared_error(y_train,y_pred),mean_squared_error(y_valid,y_valpred))
print('MAE:',mean_absolute_error(y_train,y_pred),mean_absolute_error(y_valid,y_valpred))
MSE: 0.024523304572707856 0.148004080839963
MAE: 0.11476424162232533 0.31643676975294
从MSE和 MAE来看,值并不大。但从最后一天的收盘价为7.39来看,0.316 这个偏差也算够大的了。
作图
plt.figure(figsize=(10, 8))
plt.title("股票收盘价格")
plt.xticks(y_valid.index)
plt.plot(y_valid.values, label="真实")
plt.plot(y_valpred, label="预测")
plt.legend()
plt.show()
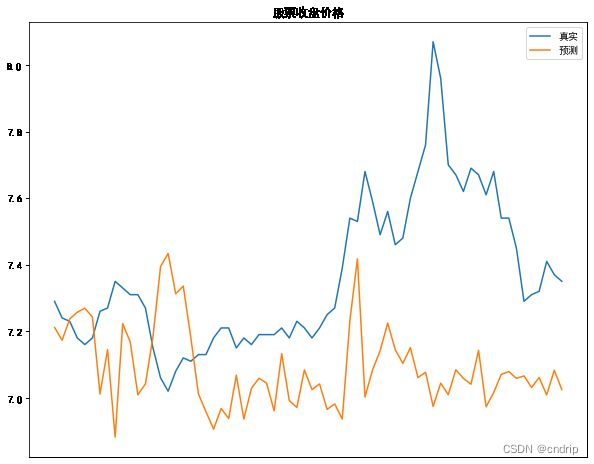
预测
y_pred=rfr.predict(test.iloc[:,:-1])
y_pred
array([7.25712055, 7.40309288, 7.40801386, 7.43678256, 7.48561795,
7.45129724, 7.35071418, 7.41735554, 7.40655025, 7.5429179 ,
7.44490355, 7.45728217, 7.74914538, 7.54671586, 7.50899764,
7.4850967 , 7.42395024, 7.55281253, 7.48490723, 7.46983359,
7.47770723, 7.52752326, 7.39138246, 7.39152939, 7.44892407,
6.8768 , 7.23216313, 7.45918674, 7.47948684, 7.21223155])
这里的数据即预测未来30天的值。

小结
以上是用随机森林作的一个预测方法,仅此而以。上面的数据是用当天的6个特征值预测未来30天的结果,可想而知。下面在此基础上我们做如下修改,采用前面30天的部分数据来预测第二天的收盘价。
数据处理
原始数据还是与上面一样,在数据分离做进一步处理。
为了方便说明问题,简化部分数据处理,如想更加详细的说明,后继将有 LSTM 预测股票的价格的文章。
原来的数据只有6列特征,在此基本上增加29列之前每天的收盘价数据一起作为特征。
cols=['open','high','low','close','volume','turn']
data=df[cols]
# 添加前29天的收盘价数据
for i in range(1,30):
data['R_%d'%i]=df.close.shift(i)
#第二收盘价作为目标
data['target']=data.close.shift(-1)
#删除空缺值
data=data.dropna()
数据分离
train=data[data.index<='2022-12-31']
valid=data[data.index>'2022-12-31'][:-30]
test=data[-30:]
X_train,X_valid,y_train,y_valid=train.iloc[:,:-1],valid.iloc[:,:-1],train.target,valid.target
建模和评估
rfr=RandomForestRegressor()
rfr.fit(X_train,y_train)
y_pred = rfr.predict(X_train)
y_valpred=rfr.predict(X_valid)
print('MSE:',mean_squared_error(y_train,y_pred),mean_squared_error(y_valid,y_valpred))
print('MAE:',mean_absolute_error(y_train,y_pred),mean_absolute_error(y_valid,y_valpred))
MSE: 0.0018605951383111714 0.0029620773221556763
MAE: 0.0297794545549311 0.04252798919403008
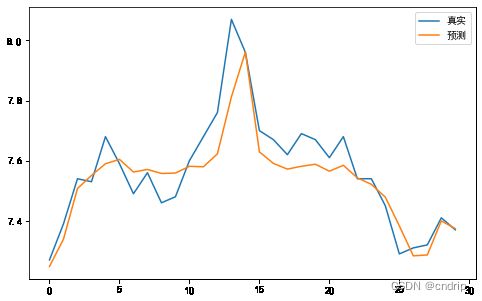
MSE和MAE 已经很小了,很接近真实值
plt.figure(figsize=(10, 8))
plt.title("股票收盘价格")
plt.plot(y_valid.values, label="真实")
plt.plot(y_valpred, label="预测")
plt.legend()
plt.show()

从上图来看,预测值与真实值很接近
预测
y_pred=rfr.predict(test.iloc[:,:-1])
y_pred
array([7.2483 , 7.33919421, 7.50750781, 7.55087572, 7.58982307,
7.6044283 , 7.56227032, 7.57089137, 7.55753348, 7.5588598 ,
7.58131242, 7.57973364, 7.62280714, 7.812186 , 7.96168067,
7.62943871, 7.59097557, 7.57193348, 7.58140716, 7.58822821,
7.56501769, 7.58472294, 7.54284928, 7.52143876, 7.47868092,
7.38327099, 7.28360451, 7.28648865, 7.3997869 , 7.37405036])
er)
如果不仔细看,小伙伴一定会有疑问,怎么会有真实值呢,其实,最先的数据是用当天的数据预测未来30天的值,而改进后的方案为前面30天的数据,预测第二天的值。
总结
这里只是预测的方法,想应用到真实的预测,以此来作股票买卖,我在这里说,别,千万别,…。
作为随机森林预测数据的一种方法,后继我将用 LSTM 和 CNN 以及 GAN 的深度学习方法来作进一步的使用说明。
在此警告:文章中的所有内容,不能给你构成投资的理由。