kotlin学习(二)泛型、函数、lambda、扩展、运算符重载
文章目录
- 泛型:in、out、where
-
- 型变(variance)
- 不变(Invariant)
- 协变(Covariant)
-
- Java上界通配符
- Kotlin的关键词 out
- @UnsafeVariance
- 逆变(Contravariant)
-
- Java 下界通配符
- kotlin的关键字 in
- 协变与逆变对比
-
- 与 对比
- PECS原则
- in与out
- 类型投影与星投影
-
- 类型投影
- 星投影
- 泛型擦除
- 下划线 _ 参数类型
-
- 可类型推导的参数略写
- 作为lambda函数是参数名称
- 作为解构声明的参数
- 函数
-
- 参数
-
- 可变数量的参数 varargs
- lambda作为参数
- 中缀函数
-
- 中缀函数的优先级
- 局部函数
- 泛型函数
- 尾递归函数tailrec
- 内联函数
-
- inline
- noinline
- crossinline
- 静态方法
-
- 伴生类
- 真正的静态方法:@JvmStatic注释
- 顶层方法
- 标准函数的使用
-
- let
- with
- run
- apply
- lambda表达式
-
- lambda表达式语法
- 简化lambda
- 从lambda中返回
- lambda表达式的类型
- 扩展
-
- 扩展函数
- 扩展属性 get()
- 运算符重载 operator
泛型:in、out、where
Kotlin 中的类可以有类型参数,与 Java 类似:
class Box<T>(t: T) {
var value = t
}
创建这样类的实例只需要提供类型参数即可:
val box: Box<Int> = Box<Int>(1)
如果类型参数可以推断出来,例如从构造函数的参数或者从其他途径,就可以省略类型参数:
val box = Box(1);
型变(variance)
Object a = new String("字符串")
String作为Object的子类,就可以直接将子类对象赋值给父类,这个操作即达到了型变。
但是Java中在使用泛型时,是无法型变的,这意味着 List并不是 List的子类型。
List<String> strs = new ArrayList<String>();
List<Object> objs = strs;// !!!此处的编译器错误让我们避免了之后的运行时异常
//假设我们忽略这个错误继续操作,假设objs = strs 也支持型变
objs.add(1);// 这里我们把一个整数放入一个字符串列表
String s = objs.get(0);// !!! ClassCastException:无法将整数转换为字符串
实际应用中,开发者需要语言对泛型类型的型变支持,所以引出了协变、逆变、不可变的实现思想(以此支持泛型的型变)
不变(Invariant)
默认情况下,Kotlin中的泛型类型是不变的。这意味着无法将一个类型的泛型实例赋值给另一个类型的泛型实例,即使它们之间有继承关系。
协变(Covariant)
Java上界通配符
Java的协变是通过上界通配符实现的,? extends 表示泛型参数必须是T类型或它的子类(继承自T,extends T)
如果Dog是Animal的子类,但 List< Dog> 并不是 List< Animal> 的子类。
下面的代码会在编译时报错:
List<Animal> animals = new ArrayList<>();
List<Dog> dogs = new ArrayList<>();
animals = dogs; // incompatible types
而使用上界通配符之后,List< Dog> 变成了 List 的子类型。即 animals 变成了可以放入任何 Animal 及其子类的 List。
List<? extends Animal> animals = new ArrayList<>();
List<Dog> dogs = new ArrayList<>();
animals = dogs;
Kotlin的关键词 out
把上述代码改成 Kotlin 的代码:
fun main() {
var animals: List<Animal> = ArrayList()
val dogs = ArrayList<Dog>()
animals = dogs
}
居然没有编译报错?其实,Kotlin 的 List 跟 Java 的 List 并不一样。
Kotlin 的 List 源码中使用了out,out相当于 Java 上界通配符。
public interface List<out E> : Collection<E> {
override val size: Int
override fun isEmpty(): Boolean
override fun contains(element: @UnsafeVariance E): Boolean
override fun iterator(): Iterator<E>
override fun containsAll(elements: Collection<@UnsafeVariance E>): Boolean
public operator fun get(index: Int): E
public fun indexOf(element: @UnsafeVariance E): Int
public fun lastIndexOf(element: @UnsafeVariance E): Int
public fun listIterator(): ListIterator<E>
public fun listIterator(index: Int): ListIterator<E>
public fun subList(fromIndex: Int, toIndex: Int): List<E>
}
@UnsafeVariance
Kotlin 中 List 的 contains、containsAll、indexOf 和 lastIndexOf 方法中,入参均出现了范型 E。并且使用 @UnsafeVariance 修饰。
由于类型安全性的考虑,泛型类型参数默认是不可协变或逆变的。但是,在某些情况下,你可能希望强制允许协变或逆变,这就是 @UnsafeVariance 注解的作用。
正是由于 @UnsafeVariance 的修饰,打破了刚才的限制,否则会编译报错。
@UnsafeVariance 注解应该谨慎使用,因为它会绕过编译器的类型检查,可能引入类型错误。只有在你确定代码是类型安全的情况下,才应该使用 @UnsafeVariance 注解。
逆变(Contravariant)
如果 A 是 B 的子类型,并且 Generic< B> 是 Generic< A> 的子类型,那么 Generic< T> 可以称之为一个逆变类。
Java 下界通配符
Java 的逆变通过下界通配符实现。? super表示泛型表示泛型参数必须是T类型或它的父类(T的超类,super T)
通过 ? super T告诉我们泛型参数是T类型或者T类型的父类,因此我们可以向该List中添加T类型或者T类型的子类元素。
List<? super Animal> animals = new ArrayList<>();
animals.add(new Dog());
kotlin的关键字 in
in相当于Java的下界通配符
类的参数类型使用了in之后,该参数只能出现在方法的入参。
abstract class Printer<in E> {
abstract fun print(value: E): Unit
}
class AnimalPrinter: Printer<Animal>() {
override fun print(animal: Animal) {
println("this is animal")
}
}
class DogPrinter : Printer<Dog>() {
override fun print(dog: Dog) {
println("this is dog")
}
}
fun main() {
val animalPrinter = AnimalPrinter()
animalPrinter.print(Animal())
val dogPrinter = DogPrinter()
dogPrinter.print(Dog())
}
协变与逆变对比
与 对比
-
对于 List l1:
- 正确的理解: ? super Integer 限定的是泛型参数. 令 l1 的泛型参数是 T, 则 T 是 Integer 或 Integer 的父类, 因此 Integer 或 Integer 的子类的对象就可以添加到 l1 中.
错误的理解: ? super Integer限定的是插入的元素的类型, 因此只要是 Integer 或 Integer 的父类的对象都可以插入 l1 中
-
对于 List l2:
- 正确的理解: ? extends Integer 限定的是泛型参数. 令 l2 的泛型参数是 T, 则 T 是 Integer 或 Integer 的子类, 进而我们就不能找到一个类 X, 使得 X 是泛型参数 T 的子类, 因此我们就不可以向 l2 中添加元素. 不过由于我们知道了泛型参数 T 是 Integer 或 Integer 的子类这一点, 因此我们就可以从 l2 中读取到元素(取到的元素类型是 Integer 或 Integer 的子类), 并可以存放到 Integer 中.
错误的理解: ? extends Integer 限定的是插入元素的类型, 因此只要是 Integer 或 Integer 的子类的对象都可以插入 l2 中
PECS原则
PECE原则:product extend,consumer super。
- Producer extends: 如果我们需要一个 List 提供类型为 T 的数据(即希望从 List 中读取 T 类型的数据), 那么我们需要使用 ? extends T, 例如 List. 但是我们不能向这个 List 添加数据。
- Consumer Super: 如果我们需要一个 List 来消费 T 类型的数据(即希望将 T 类型的数据写入 List 中), 那么我们需要使用 ? super T, 例如 List. 但是这个 List 不能保证从它读取的数据的类型。
- 如果我们既希望读取, 也希望写入, 那么我们就必须明确地声明泛型参数的类型, 例如 List< Integer>.
in与out
按照上边提到的PECS原则,生产T类型的元素(从list取出),使用 ? extends 取出,对应 out
消费T类型的元素,(把元素放入到list中),使用? super,装入,对应in
PECS:Producer Extend Consumer Super
消费者 in, 生产者 out
类型投影与星投影
在 Kotlin 中,类型投影和星投影都是用于处理泛型类型中的通配符或未知类型参数的概念。
类型投影
上边介绍的使用关键字out 和in限制泛型类型参数,就属于类型投影
- out 投影:使用 out 关键字可以使泛型类型参数在所在类型中变为协变。这意味着可以安全地将泛型类型参数的子类型赋值给泛型类型的父类型。使用 out 关键字的泛型类型参数只能用于输出位置(即,作为返回类型),不能用于输入位置(即,作为函数参数)。
- in 投影:使用 in 关键字可以使泛型类型参数在所在类型中变为逆变。这意味着可以安全地将泛型类型参数的父类型赋值给泛型类型的子类型。使用 in 关键字的泛型类型参数只能用于输入位置(即,作为函数参数),不能用于输出位置(即,作为返回类型)。
星投影
星投影是一种特殊的类型投影,用于在使用泛型类型时,不关心具体的类型参数。星投影使用星号 (*) 来表示未知类型参数。
星投影有三种形式:
*:表示一个未知类型参数,可以被任意类型替代。out *:表示一个未知类型参数,可以被任意类型替代,并且可以在输出位置(作为返回类型)使用。in *:表示一个未知类型参数,可以被任意类型替代,并且可以在输入位置(作为函数参数)使用。
星投影通常在以下情况下使用:
当你对泛型类型中的具体类型参数不感兴趣时。
当你需要将泛型类型作为函数参数,但不需要对类型参数进行操作时。
class Processor<T> {
fun process(value: T) {
// 处理 value
}
}
fun processAny(processor: Processor<*>){
val value: Any = getValue()
processor.process(value) // 可以传
泛型擦除
与Java一样,Kotlin 为泛型声明用法执行的类型安全检测在编译期进行。 运行时泛型类型的实例不保留关于其类型实参的任何信息。 其类型信息称为被擦除。例如,Foo 与 Foo
下划线 _ 参数类型
下划线运算符 _ 可以用于类型参数。
可类型推导的参数略写
当显式指定其他类型时,使用它可以自动推断参数的类型。
abstract class SomeClass<T> {
abstract fun execute() : T
}
class SomeImplementation : SomeClass<String>() {
override fun execute(): String = "Test"
}
class OtherImplementation : SomeClass<Int>() {
override fun execute(): Int = 42
}
object Runner {
inline fun <reified S: SomeClass<T>, T> run() : T {
return S::class.java.getDeclaredConstructor().newInstance().execute()
}
}
fun main() {
// T被推断为字符串,因为SomeImplementation派生自SomeClass<String>
val s = Runner.run<SomeImplementation, _>()
assert(s == "Test")
// T被推断为Int,因为SomeImplementation派生自SomeClass<Int>
val n = Runner.run<OtherImplementation, _>()
assert(n == 42)
}
作为lambda函数是参数名称
fun main(args: Array<String>) {
val aa = mapOf(1 to "a",2 to "B")
aa.forEach { key, value -> println("value:$value")
}
在上述示例中,只是用到了value值,key并没有用到。这样,我们就想不在声明key,那么就需要使用下划线字符(_)作为key替代,即:
fun main(args: Array<String>) {
val aa = mapOf(1 to "a",2 to "B")
aa.forEach { _, value -> println("value:$value")
}
作为解构声明的参数
解构声明就是将一个对象解构(destructure)为多个变量,也就是意味着一个解构声明会一次性创建多个变量.简单的来说,一个解构声明有两个动作:
- 声明多个变量
- 将对象的属性赋值给相应的变量
例如,有个数据类Person,其有name和age两个属性
data class Person(var name: String, var age: Int) {
}
当我们对Person的实例使用解构声明时,可以这样做:
var person: Person = Person("Jone", 20)
var (name, age) = person
println("name: $name, age: $age")// 打印:name: Jone, age: 20
其中,var (name, age) = person就是解构声明,其实际意义是创建了两个变量name和age,然后将person的属性值”Jone”和20分别赋值给name和age。
通过解构声明创建多个变量时,我们这么做:
fun main() {
val book = Book(1, "英语")
val (id, name) = book
}
data class Book(var id: Int, var name: String)
上面的示例中,解构book声明了 id,name两个变量。如果只需要id这一个变量时,可以这么做:
val book = Book(1, "英语")
val (id, _) = book
函数
Kotlin 函数使用 fun 关键字声明:
fun double(x: Int): Int {
return 2 * x
}
参数
函数参数使用 Pascal 表示法定义——name: type。参数用逗号隔开, 每个参数必须有显式类型:
fun powerOf(number: Int, exponent: Int): Int { /*……*/ }
声明函数参数时可以使用尾随逗号:
fun powerOf(
number: Int,
exponent: Int, // 尾随逗号
) {
}
可变数量的参数 varargs
函数的参数(通常是最后一个),可以用vararg修饰符标记:
fun <T> asList(var)
lambda作为参数
如果在默认参数之后的最后一个参数是 lambda 表达式,那么它既可以作为具名参数在括号内传入,也可以在括号外传入:
fun foo(
bar: Int = 0,
baz: Int = 1,
qux: () -> Unit,
) { /*……*/ }
foo(1) { println("hello") } // 使用默认值 baz = 1
foo(qux = { println("hello") }) // 使用两个默认值 bar = 0 与 baz = 1
foo { println("hello") } // 使用两个默认值 bar = 0 与 baz = 1
中缀函数
标有infix关键字的函数可以使用中缀表示法(忽略该调用的点和圆括号)调用。中缀函数必须满足以下要求:
- 它们必须是成员函数或拓展函数
- 它们必须只有一个参数
- 参数不得接受可变数量的参数且不能有默认值
infix fun Int.shl(x : Int) : Int {}
// 用中缀表示法调用该函数
1 shl 2
// 等同于这样
1.shl(2)
中缀函数的优先级
中缀表示法的函数调用类似于算术运算符,但是中缀函数的调用的优先级低于算术操作符、类型转换以及rangeTo操作符,以下表达式是等价的:
- 1 shl 2 + 3 等价于 1 shl (2 + 3)
- xs union ys as Set < * > 等价于 xs union (ys as Set< * >)
- 0 until n * 2 等价于 0 until (n × 2)
另一方面,中缀函数调用的优点级高于布尔操作符&&与||、is与in检测以及其他一些操作符。
- a && b xor c 等价于 a && (b xor c)
- a xor b in c 等价于(a xor b)in c
请注意,中缀函数总是要求指定接收者与参数。当使用中缀表示法在当前接收者上调用方法时,需要显式使用this,这是确保非模糊解析所必需的。
class MyStringCollection {
infix fun add(s : String) { }
fun build() {
this add "abc"
add("abc")
// add "abc" 错误,必须指定接收者
}
}
局部函数
kotlin支持局部函数,即一个函数在另一个函数内部:
fun dfs(graph: Graph) {
fun dfs(current: Vertex, visited: MutableSet<Vertex>) {
if (!visited.add(current)) return
for (v in current.neighbors)
dfs(v, visited)
}
dfs(graph.vertices[0], HashSet())
}
局部函数可以访问外部函数(闭包)的局部变量。在上例中,visited 可以是局部变量:
fun dfs(graph: Graph) {
val visited = HashSet<Vertex>()
fun dfs(current: Vertex) {
if (!visited.add(current)) return
for (v in current.neighbors)
dfs(v)
}
dfs(graph.vertices[0])
}
泛型函数
函数可以有泛型参数,通过在函数名前使用尖括号指定:
fun <T> singletonList(item: T): List<T> {}
尾递归函数tailrec
Kotlin 支持一种称为尾递归的函数式编程风格:
val eps = 1E-10 // "good enough", could be 10^-15
tailrec fun findFixPoint(x: Double = 1.0): Double =
if (Math.abs(x - Math.cos(x)) < eps) x else findFixPoint(Math.cos(x))
上面这个函数的特点是,函数将其自身调用作为它执行的最后的一个操作。代码计算余弦的不动点(fixpoint of cosine),这是一个数学常数。 它只是重复地从 1.0 开始调用 Math.cos, 直到结果不再改变,对于这里指定的 eps 精度会产生 0.7390851332151611 的结果。最终代码相当于这种更传统风格的代码:
val eps = 1E-10 // "good enough", could be 10^-15
private fun findFixPoint(): Double {
var x = 1.0
while (true) {
val y = Math.cos(x)
if (Math.abs(x - y) < eps) return x
x = Math.cos(x)
}
}
内联函数
inline
内联函数起初是在 C++ 里面的。
简单来讲,当一个函数被inline标注后,在调用它的地方,会把这个函数方法体中的所有代码移动到调用的地方,而不是通过方法间压栈进栈的方式。
inline在一般的方法是标注是不会起到很大作用的,inline能带来性能提升,往往是在lambda函数上。这是因为在kotlin中,出现了大量的高级函数(高阶函数是将函数作为参数或者返回值的函数),使得越来越多的地方出现函数参数不断传递的现象,每一个函数参数都会被编译为一个对象,使得调用时会增加运行时间开销。
noinline
假设一个函数有多个函数型参数,若加上inline会使全部的参数参与内联,若某些不想参与内联,则需要在参数前加上noinline关键字。
使用如下:
inline fun test(lambda1:() -> Unit, noinline lambda2: () -> Unit) {
lambda1()
lambda2()
}
内联的函数将被代码替换,并没有真正的参数含义,只能传递给另一个内联函数,而非内联的函数是一个真正的参数,使用noline关掉局部优化,可以摆脱不能把函数类型的参数当做对象使用的限制。
crossinline
内联函数可以使用return,内联时的return会跑到调用者的函数中,return结束的是调用者的函数,非内联的return结束的是内部类的方法。即使用inline优化会影响调用方的return流程控制。
考虑一种情况,我们即想lambda被inline优化,但是又不想让lambda对调用者的控制流程产生影响,可以使用crossinline关键字,保留了inline的特性,但是如果想在传入的lambda里边return,就会报错。
crossinline就像一个契约,保证传入的lambda一定不使用return
静态方法
静态方法在Java中使用static关键字声明,在调用时无需创建实例,通过类名.方法名的方式调用。
在kotlin中定义Object类,其内部的方法调用类似static方法的调用:
object Utils {
fun test() {
}
}
调用如下:
Utils.test()
但其实这并非是真正的静态方法,而是单例对象的方法调用。
其对象的java文件如下:
public final class Utils {
@NotNull
public static final Utils INSTANCE;
public final void test() {
}
private Utils() {
}
static {
Utils var0 = new Utils();
INSTANCE = var0;
}
}
伴生类
如果我们想使一个普通类中的某些方法通过类名.方法名的方式调用,而别的方法还是正常的调用方式,可以借助伴生类,即关键字companion object
class Util2{
fun function1(){
println("这是一个普通的方法")
}
companion object{
fun function2(){
println("这是伴生类中的方法")
}
}
}
这里的function1必须通过对象名.方法名的方式调用,而function2被定义在companion object中,可以通过类名.方法名的方式调用,它的本质是在类中创建了一个Compain的静态内部类(伴生类),调用function2(),就是调用此对象的test2()。
上述方法只是实现了类似于静态方法的特性,而非真正的静态方法,因为在java文件中以静态方法的形式调用时,发现这些方法都是不存在的。
真正的静态方法:@JvmStatic注释
如果给单例类(object)和伴生类中(companion object)的方法加上@JvmStatic注解,就会成为真正的静态方法,在kotlin和java文件中都可以调用。
注意:@JvmStatic只能加在单例类和伴生类中的对象上。如果加在一个普通方法上,就会报错。
class Util3 {
companion object{
@JvmStatic
fun function(){
println("这是一个真正的静态方法")
}
}
}
顶层方法
顶层方法是指不在类中定义的方法,编译器会自动把所有的顶层方法全部编译为静态方法,如果在kotlin中调用顶层方法,直接使用函数名即可。
标准函数的使用
let
let函数所作的事情就是把一个调用它的对象变成lambda表达式的参数,结合安全调用语法,能有效地把调用let函数的可空对象转变为非空类型,换言之,仅在对象非空时,执行lambda。
s?.let {
print(s.length)
}
with
with接收两个参数,一个任意类型的对象,一个Lambda表达式,第一个参数会传给Lambda使用,其Lambda内部执行的方法都是传入的对象所执行的,Lambda的最后一行代码会当成返回值返回,调用with则Lambda会立即执行。
val result = with(obj) {
//this则代表obj
//test() 等价于 this.test() 等价于 obj.test()
//返回值,result最终为value
"value"
}
比如存在一个水果列表,现在想吃完所有水果,并打印结果,不借助with如下:
val list = listOf("apple, banana, orange")
val builder = StringBuffer()
builder.append("Start eating fruits.\n")
for (fruit in list) {
builder.append(fruit).append("\n")
}
builder.append("Ate all fruits")
val result = builder.toString()
println(result)
with实现如下:
val list = listOf("apple, banana, orange")
val result = with(StringBuilder()) {
append("Start eating fruits.\n")
for (fruit in list) {
append(fruit).append("\n")
}
append("Ate all fruits")
toString()
}
println(result)
可以看出我们可以省略对象去调用方法,使得代码更加简洁。
run
run与with的使用场景类似,不同的是run在对象上调用,且只需要一个lambda参数,其他地方一样,
上述吃水果用run实现如下:
val list = listOf("apple, banana, orange")
val result = StringBuilder().run {
append("Start eating fruits.\n")
for (fruit in list) {
append(fruit).append("\n")
}
append("Ate all fruits")
toString()
}
println(result)
apply
apply与run相似,也需要在对象上调用,不同的是他的返回值是调用对象本身。
上述吃水果用apply实现如下:
val list = listOf("apple, banana, orange")
val result = StringBuilder().apply {
append("Start eating fruits.\n")
for (fruit in list) {
append(fruit).append("\n")
}
append("Ate all fruits")
}
println(result.toString())
lambda表达式
lambda表达式语法
lambda表达式的完整语法形式如下:
val sum : (Int, Int) -> Int = {x: Int, y: Int -> x + y}
- lambda表达式总在花括号中
- 完整语法形式的参数声明放在花括号内,并有
可选的类型标注。 - 如果推断出lambda的返回类型不是Unit,那么该lambda主体中的最后一个表达式会视为返回值。
简化lambda
下面这个示例就是简化lambda的写法:
fun main(args: Array<String>) {
args.forEach {
if (it == "q") return
println(it)
}
println("The End")
}
首先forEash本质上是一个内联函数:
public inline fun<T> forEach(action: (T) -> Unit): Unit {
for (element in this) action(elment)
}
inline的作用是代码替换,因此上边的代码相当于:
args.forEach({element -> println(element)})
1、kotlin 允许我们把函数的最后一个lambda表达式参数,移动到小括号外:
args.forEach(){
element -> println(element)
}
2、如果函数只有一个lambda,小括号可以省略掉:
args.forEach{
element -> println(element)
}
3、只有一个参数可以默认为it:
args.forEach{
println(it)
}
4、入参,返回值与形参一致的函数可以用函数的引用作为实参传入:
args.forEach(::println)
总结:
- 最后一个lambda可以移出去
- 只有一个lambda,小括号可以省略
- lambda只有一个参数可以默认为it
- 入参,返回值与形参一致的函数可以用函数的引用作为实参传入
这下再回头看这种写法就明白了:
fun main(args: Array<String>) {
args.forEach {
if (it == "q") return
println(it)
}
println("The End")
}
从lambda中返回
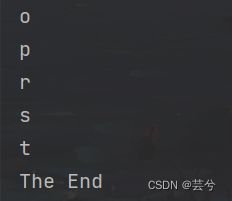
下面的代码,我们预期的效果是打印非q元素的字符,最后输出“The End”。
fun main() {
var args: String = "opqrst"
args.forEach {
if (it == 'q') return
println(it)
}
println("The End")
}
然而实际上,由于forEach本质是inline,lambda中的return实际的调用者在main函数中,因此输出为:
o
p
解决方式是定义一个标签@forEachBlock
fun main() {
var args: String = "opqrst"
args.forEach forEachBlock@{
if (it == 'q') return@forEachBlock
println(it)
}
println("The End")
}
lambda表达式的类型
public inline fun <T> Array<out T>.forEach(action: (T) -> Unit): Unit {
for (element in this) action(element)
}
注意到,action 这个形参的类型是 (T) -> Unit,这个是 Lambda 表达式的类型,或者说函数的类型,它
表示这个函数接受一个 T 类型的参数,返回一个 Unit 类型的结果。
() -> Int //无参,返回 Int
(Int, Int) -> String //两个整型参数,返回字符串类型
(()->Unit, Int) -> Unit //传入了一个 Lambda 表达式和一个整型,返回 Unit
扩展
扩展函数
扩展函数:对类的方法进行补充,动态给类添加方法。
Java没法对系统类进行拓展,而kotlin可以对其进行拓展,比如实现一个统计string中的字母个数的函数:
若不借助扩展函数,定义StringUtil并实现lettersCount:
object StringUtil {
fun lettersCount(string: String): Int {
var count = 0;
for (char in string) {
if (char.isLetter()) count++
}
return count
}
}
调用如下:
StringUtil.lettersCount("ab2")
若借助扩展函数,可直接将lettersCount()方法添加到String类中,不必再创建StringUtil:
创建String.kt,其职责就是对String进行拓展,创建新的文件可以使得拓展函数拥有全局访问域,不定义新文件也是可以的,郭霖大佬的建议是定义新文件。
fun String.lettersCount(): Int {
var count = 0
for (char in this) {
if (char.isLetter()) count++
}
return count
}
Kotlin访问可以直接使用:
var count = "111asd".lettersCount()
Java中调用需要如下方式:
StringKt.lettersCount("aaa");
扩展属性 get()
kotlin还可以扩展属性,在String.kt加入以下代码,相当于给String添加了一个值为10的int,get()是固定语法
val String.value : Int get() = 10
Kotlin中访问如下:
var value = "".value
Java中访问如下:
int value = StringKt.getValue("aaa");
运算符重载 operator
Kotlin的每个运算符都有其对应的方法:
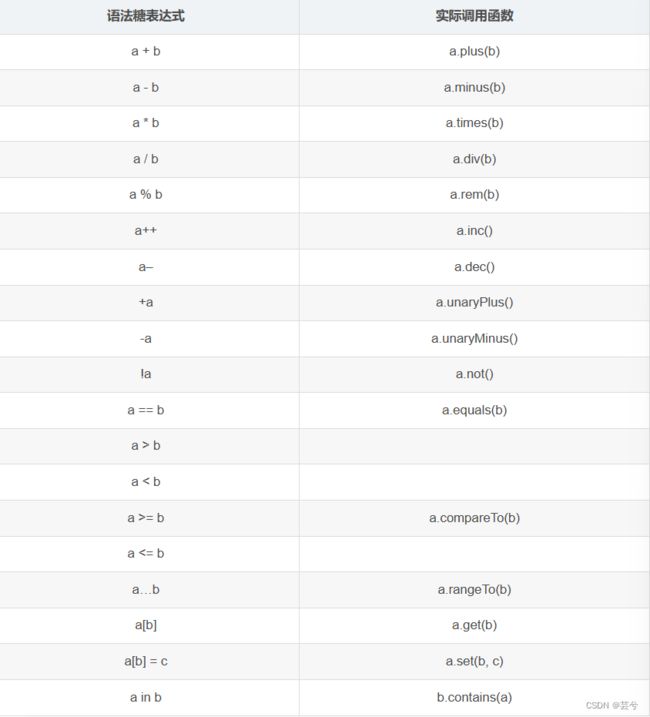
Kotlin的编译器可以把+转换成相对应的plus方法调用。
构建一个Money类:
class Money(val value: Int) {
operator fun plus(money: Money): Money {
val sum = value + money.value
return Money(sum)
}
}
上边的Money类,在构造时声明了Int类型的value属性,使用operator重载了plus方法.
fun main() {
val money = Money(10) + Money(30)
println(money.value)
//输出 40
}