python爬虫,智能爬取网站弹幕和评论,生成词云图,两种方法。
智能爬取网站弹幕和评论,生成词云图,两种方法,超简单,可打包,生成exe使用,可供教学使用。
- 目录
-
前言:两种一键爬取方法
一、传统正则匹配算法:使用步骤
1.引入库
2.源码
二、完美方法:利用API
三、总结
第一种方法bug:
打包问题:
-
声明:本人是山东某校大一学生,非计算机专业,文学专业出身。
由于系里老师需要,故,写好脚本,并用pyinstaller打好包,提供系里做研究用。本文不讨论pyinstaller打包问题,太麻烦了,尤其是引用第三方库的时候,打包一直报错,所幸现在已经解决。
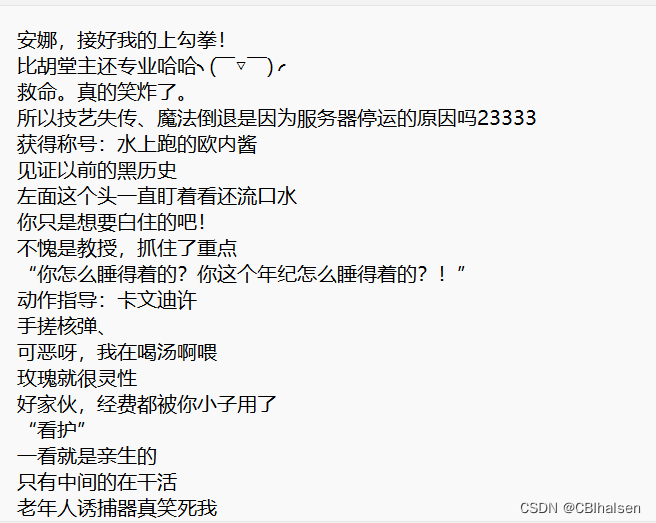
效果如图:

前言:两种一键爬取方法
本文共两种方法,由于全是自动化傻瓜式操作,所以代码量较多还请谅解。
大致思路:
小破站把弹幕都存放到了xml文件里。
如果读者急需源码直看第二种方法,若碰见pyinstaller打包问题,可私信我。
例如: comment.某站.com/cid.xml
XXXXXX为小破站视频的cid,即每个视频独属的id,那么获取弹幕就简单了,我们只要Fn+F12打开开发者工具,找Network ,Document,XHR,hearbeat,里面可能会有cid,那么如果你能幸运找到cid爬取弹幕就轻而易举了。当然这是一种麻烦的方法,每个视频链接对应的页面源码都存有这部作品每个视频的cid,注意我说的是每个。当然直接爬取页面源码正则匹配现在看来是种简单的办法,而实现这种方法的代码就是我所说的第一种方法,但是有个问题显而易见,一个html文件里包含多个视频的cid,如1,2,3....N集,那么匹配算法我们需要怎么设计?“第input()集”看起来是可行的,但是别忘了预告片,预告片cid同样存在,这样去查找第三集,会得到两个cid。我们目前只需要正片,嗯这不是什么大问题,那么大问题来了:如下图,视频命名规范,以及会员问题,如果我们继续采取正则匹配查找cid,那么遇见命名规范问题,我们需要重新修改我们的匹配算法,这对于程序猿来说不值一提,但是对小白可是个头疼问题。目前已知在html里,有些许会员视频不显示cid,这可是大麻烦,那么匹配算法直接pass掉。
如图:视频集数命名问题。

一、传统正则匹配算法:使用步骤
1.引入库
代码如下(示例):
import re
import requests
from bs4 import BeautifulSoup
import pandas as pd
import time
import json
from stylecloud import gen_stylecloud
import jieba
import re
import matplotlib.pyplot as plt
import os
2.示例和源码
输入url,爬取整个HTML文件,小破站把所有视频的bvid,cid和aid都存放在了html文件里。
爬下来后用匹配算法,查找哪一集的cid,后用cid爬取小破站弹幕。查找aid,用于爬评论。
以最近的番剧《恋爱世界对路人角色很不友好》为例。
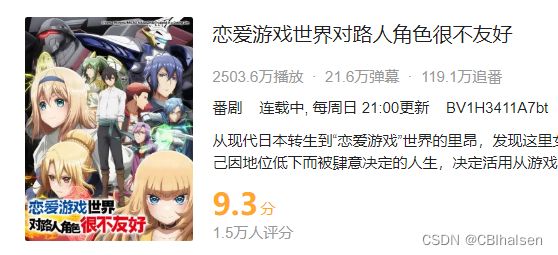
本人使用的为edge浏览器,Ctrl+U查看页面源码。Ctrl+F查找。

Product为控制台文件:
代码如下:
# Product.py
import time
import sec_bar as ec
import third_gwcloud as gw
import first_extract as ex
import request_comments as rc
print("请输入视频url")
a = input(":")
print("请输入保存视频html的文件名")
b = input(":")
url = a
path = b
headers={
"User-Agent":"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 2.0.50727; SLCC2; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0"
}
ex.use_requests(url,headers,path)
print("请输入要爬取的视频集数")
c = input(":")
number = c
print("请在此输入文件名,以保存该视频cid,aid和弹幕。")
d = input(":")
file_name = ''+d+'_demo'
file_path = d
ex.request_number(number,ex.use_requests(url,headers,path),file_name)
print("爬取弹幕输入1,爬取评论输入2")
n = int(input(":"))
if n == 1:
cid = ex.request_cid(file_name, file_name)
print(cid)
ec.request_barrage(file_path, cid)
print("您是否要生成弹幕词云图,1生成,2不生成。")
f = input(":")
g = int(f)
if g == 1:
gw.generate_wordlcloud(file_path, d)
elif g == 2:
print("好的")
elif n == 2:
aid = ex.request_aid(file_name, file_name)
print(aid)
e = 0
page = 1
while e == 0:
url = "https://api.bilibili.com/x/v2/reply?pn=" + str(page) + '&type=1&oid=' + aid + '&sort=2'
try:
print()
# print(url)
content = rc.get_content(url)
print("page:", page)
rc.Out2File(content,file_path)
page = page + 1
# 为了降低被封ip的风险,每爬20页便歇5秒。
if page % 10 == 0:
time.sleep(5)
except:
e = 1
else:
print("输入错误")
# first_extract.py
import re
import requests
from bs4 import BeautifulSoup
import pandas as pd
import os
#使用requests方法
def use_requests(url,headers,path):
response = requests.get(url,headers=headers)
data = response.text
file_path='./'+path+'.txt'
print(file_path)
#将爬到的内容保存到本地
with open(file_path,"w",encoding="utf-8") as f:
f.write(data)#"bvid"
with open('./' +path+ '.txt', 'r+', encoding='utf-8') as f:
data = f.read().replace('\n', '')
with open('./' + path + '.txt', 'r+', encoding='utf-8') as f:
data = f.read().replace('\n', '')
print(data)
return data
def request_number(number,data,file_name):
k = number
l = int(k)
m = l + 1
num1 = str(m)
pattern=re.compile('第'+k+'.*?第'+num1+'',)
result0 = pattern.findall(data)
print(data)
o = file_name
file = open('./' + o + '.txt', 'w', encoding='utf-8') # 外切
for i in set(result0):
file.write(i + '\n')
print(result0)
def request_cid(path,inner_path):
with open('./'+path+'.txt', 'r', encoding='utf-8') as f:
data = f.read()
pattern = re.compile('"cid":(.+),"cover"') # 匹配cid与cover之间的内容,即cid一串数值。
result = pattern.findall(data)
file = open('./'+inner_path+'.txt', 'w+', encoding='utf-8')
for i in set(result):
file.write(i + '\n')
print(result)
k = i
print(k)
return(k)
def request_aid(path,inner_path):
with open('./'+path+'.txt', 'r', encoding='utf-8') as f:
data = f.read()
pattern = re.compile('"aid":(.+),"badge"') # 匹配ab与ef之间的内容
result = pattern.findall(data)
file = open('./'+inner_path+'.txt', 'w+', encoding='utf-8')
for i in set(result):
file.write(i + '\n')
print(result)
k = i
print(k)
return(k)
def request_barrage(file_path,file_cid):
# 弹幕保存文件
file_name = file_path
j = file_cid
# 获取页面
cid = j
url = "https://comment.bilibili.com/" + str(cid) + ".xml"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'
}
request = requests.get(url=url, headers=headers)
request.encoding = 'utf-8'
# 提取弹幕
soup = BeautifulSoup(request.text, 'lxml')
results = soup.find_all('d')
# 数据处理
data = [data.text for data in results]
# 正则去掉多余的空格和换行
for i in data:
i = re.sub('\s+', '', i)
# 查看数量
print("弹幕数量为:{}".format(len(data)))
# 输出到文件
df = pd.DataFrame(data)
df.to_csv(file_name, index=False, header=None,encoding="utf_8_sig")
print("写入文件成功")
srcFile = './' +file_path+ ''
dstFile = './' +file_path+ '.txt'
try:
os.rename(srcFile, dstFile)
except Exception as e:
print(e)
print('rename file fail\r\n')
else:
print('rename file success\r\n')
# sec_bar.py
import re
import requests
from bs4 import BeautifulSoup
import pandas as pd
import os
def request_barrage(file_path,file_cid):
# 弹幕保存文件
file_name = file_path
j = file_cid
# 获取页面
cid = j
url = "https://comment.bilibili.com/" + str(cid) + ".xml"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'
}
request = requests.get(url=url, headers=headers)
request.encoding = 'utf-8'
# 提取弹幕
soup = BeautifulSoup(request.text, 'lxml')
results = soup.find_all('d')
# 数据处理
data = [data.text for data in results]
# 正则去掉多余的空格和换行
for i in data:
i = re.sub('\s+', '', i)
# 查看数量
print("弹幕数量为:{}".format(len(data)))
# 输出到文件
df = pd.DataFrame(data)
df.to_csv(file_name, index=False, header=None,encoding="utf_8_sig")
print("写入文件成功")
srcFile = './' +file_path+ ''
dstFile = './' +file_path+ '.txt'
try:
os.rename(srcFile, dstFile)
except Exception as e:
print(e)
print('rename file fail\r\n')
else:
print('rename file success\r\n')# third_gwcloud.py
from stylecloud import gen_stylecloud
import jieba
import re
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
def generate_wordlcloud(file_name,png_name):
with open('./'+file_name+'.txt', 'r', encoding='utf-8') as f:
data = f.read()
# 文本预处理 去除一些无用的字符 只提取出中文出来
new_data = re.findall('[\u4e00-\u9fa5]+', data, re.S)
new_data = " ".join(new_data)
# 文本分词
seg_list_exact = jieba.cut(new_data, cut_all=False)
result_list = []
with open('./unknow.txt', 'w+', encoding='utf-8') as f:
con = f.readlines()
stop_words = set()
for i in con:
i = i.replace("\n", "") # 去掉读取每一行数据的\n
stop_words.add(i)
for word in seg_list_exact:
# 设置停用词并去除单个词
if word not in stop_words and len(word) > 1:
result_list.append(word)
print(result_list)
# stylecloud绘制词云
gen_stylecloud(
text=' '.join(result_list), # 输入文本
size=600, # 词云图大小
collocations=False, # 词语搭配
font_path='msyh.ttc', # 字体
output_name=''+png_name+'.png', # stylecloud 的输出文本名
icon_name='fas fa-apple-alt', # 蒙版图片
palette='cartocolors.qualitative.Bold_5' # palettable调色方案
)
I = mpimg.imread('./'+png_name+'.png')
plt.axis('off')
plt.imshow(I)
plt.show()
# request_comments.py
import requests
import time
import json
def get_html(url):
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
} # 爬虫模拟访问信息
r = requests.get(url, timeout=30, headers=headers)
r.raise_for_status()
r.endcodding = 'utf-8'
# print(r.text)
return r.text
def get_content(url):
#分析网页,整理信息,保存在列表中。
comments = []
# 首先,我们把需要爬取信息的网页下载到本地
html = get_html(url)
try:
s = json.loads(html)
except:
print("jsonload error")
num = len(s['data']['replies']) # 获取每页评论栏的数量
# print(num)
i = 0
while i < num:
comment = s['data']['replies'][i] # 获取每栏评论
InfoDict = {} # 存储每组信息字典
InfoDict['Uname'] = comment['member']['uname'] # 用户名
InfoDict['Like'] = comment['like'] # 点赞数
InfoDict['Content'] = comment['content']['message'] # 评论内容
InfoDict['Time'] = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(comment['ctime'])) # ctime格式的特殊处理?不太清楚具体原理
comments.append(InfoDict)
i = i + 1
return comments
def Out2File(dict,path):
#保存到相对路径下,文件名"path"。
with open(''+path+'.txt', 'a+', encoding='utf-8') as f:
i = 0
for comment in dict:
i = i + 1
try:
f.write('姓名:{}\t 点赞数:{}\t \n 评论内容:{}\t 评论时间:{}\t \n '.format(
comment['Uname'], comment['Like'], comment['Content'], comment['Time']))
f.write("-----------------\n")
except:
print("out2File error")
print('当前页面保存完成')
以上是一种全自动爬取方法,但很鸡肋因为小破站有的视频命名方式是:"number"+上 or 下;"number" + "A" or "B",所以特定的集数需要重新设置正则表达式,太过麻烦。
二、完美方法:利用API
经考虑后决定直接用bvid,利用小破站API获取aid和cid。首先利用API传入bvid获取cid,后再利用API传入cid和bvid获取aid。
如图小破站提供了每一集的bvid(以bv开头的一串字符串。),所以bvid直接复制粘贴就好了,无需爬取整个html文件再做匹配,筛选条件。
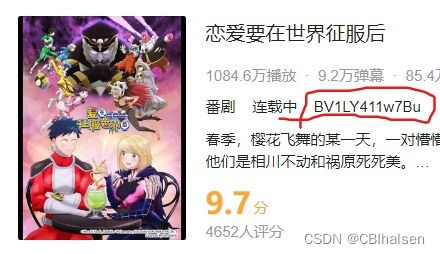
小破站提供的两个接口如下:
cid:
'https://api.bilibili.com/x/player/pagelist?bvid=(填入bvid,并删除())&jsonp=jsonp'
aid:
'https://api.bilibili.com/x/web-interface/view?cid=(填入cid,并删除())&bvid=(填入bvid,并删除())'
注意:Product.py为控制台文件。
新的方法如下:
# Product.py
import time
import request_barrage as ec
import generate_gwcloud as gw
import request_comments as rc
import requests
import json
import easygui as g
headers={
"User-Agent":"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 2.0.50727; SLCC2; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0"
}
bvNum = g.enterbox(msg='请输入视频的BV号,b站页面以BV开头的字符串', title='B站爬取弹幕和评论。 Author@halsen')
BUrl = 'https://api.bilibili.com/x/player/pagelist?bvid=' + bvNum + '&jsonp=jsonp'
response = requests.get(url = BUrl, headers = headers)
d = json.loads(response.text)
print(d)
cid = d['data'][0]['cid'] #0 数组元素的位置
print(cid)
cd = str(cid)
AidUrl = 'https://api.bilibili.com/x/web-interface/view?cid='+cd+'&bvid='+bvNum+''
response = requests.get(url = AidUrl, headers = headers)
e = json.loads(response.text)
print(e)
aid = e['data']['aid'] #e json数据 data的value值类型是集合
print(aid)
ad = str(aid)
d = g.enterbox(msg='请在此输入文件名,以保存该视频cid,aid和弹幕。')
# file_name = ''+d+'_demo'
file_path = d
h = g.enterbox(msg='爬取弹幕输入1,爬取评论输入2.')
n = int(h)
if n == 1:
ec.request_barrage(file_path, cid)
f = g.enterbox(msg='您是否要生成弹幕词云图,1生成,2不生成。')
g = int(f)
if g == 1:
gw.generate_wordlcloud(file_path, d)
elif g == 2:
print("好的")
elif n == 2:
e = 0
page = 1
while e == 0:
url = "https://api.bilibili.com/x/v2/reply?pn=" + str(page) + '&type=1&oid=' + ad + '&sort=2'
try:
print()
# print(url)
content = rc.get_content(url)
print("page:", page)
rc.Out2File(content,file_path)
page = page + 1
# 为了降低被封ip的风险,每爬20页便歇5秒。
if page % 10 == 0:
time.sleep(5)
except:
e = 1
else:
print("输入错误")
# request_barrage.py
import re
import requests
from bs4 import BeautifulSoup
import pandas as pd
import os
def request_barrage(file_path,file_cid):
# 弹幕保存文件
file_name = file_path
j = file_cid
# 获取页面
cid = j
url = "https://comment.bilibili.com/" + str(cid) + ".xml"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'
}
request = requests.get(url=url, headers=headers)
request.encoding = 'utf-8'
# 提取弹幕
soup = BeautifulSoup(request.text, 'lxml')
results = soup.find_all('d')
# 数据处理
data = [data.text for data in results]
# 正则去掉多余的空格和换行
for i in data:
i = re.sub('\s+', '', i)
# 查看数量
print("弹幕数量为:{}".format(len(data)))
# 输出到文件
df = pd.DataFrame(data)
df.to_csv(file_name, index=False, header=None,encoding="utf_8_sig")
print("写入文件成功")
srcFile = './' +file_path+ ''
dstFile = './' +file_path+ '.txt'
try:
os.rename(srcFile, dstFile)
except Exception as e:
print(e)
print('rename file fail\r\n')
else:
print('rename file success\r\n')# request_comments.py
import requests
import time
import json
def get_html(url):
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
} # 爬虫模拟访问信息
r = requests.get(url, timeout=30, headers=headers)
r.raise_for_status()
r.endcodding = 'utf-8'
# print(r.text)
return r.text
def get_content(url):
#整理信息,保存到列表变量中。
comments = []
# 把需要爬取信息的网页下载到本地
html = get_html(url)
try:
s = json.loads(html)
except:
print("jsonload error")
num = len(s['data']['replies']) # 获取每页评论栏的数量
# print(num)
i = 0
while i < num:
comment = s['data']['replies'][i] # 获取每栏评论
InfoDict = {} # 存储每组信息字典
InfoDict['Uname'] = comment['member']['uname'] # 用户名
InfoDict['Like'] = comment['like'] # 点赞数
InfoDict['Content'] = comment['content']['message'] # 评论内容
InfoDict['Time'] = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(comment['ctime'])) # ctime格式的特殊处理?不太清楚具体原理
comments.append(InfoDict)
i = i + 1
return comments
def Out2File(dict,path):
# 爬取文件写到本地,文件名path,相对路径。
with open(''+path+'.txt', 'a+', encoding='utf-8') as f:
i = 0
for comment in dict:
i = i + 1
try:
f.write('姓名:{}\t 点赞数:{}\t \n 评论内容:{}\t 评论时间:{}\t \n '.format(
comment['Uname'], comment['Like'], comment['Content'], comment['Time']))
f.write("-----------------\n")
except:
print("out2File error")
print('当前页面保存完成')
# generate_gwcloud.py
from stylecloud import gen_stylecloud
import jieba
import re
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
def generate_wordlcloud(file_name,png_name):
with open('./'+file_name+'.txt', 'r', encoding='utf-8') as f:
data = f.read()
# 文本预处理 去除一些无用的字符 只提取出中文出来
new_data = re.findall('[\u4e00-\u9fa5]+', data, re.S)
new_data = " ".join(new_data)
# 文本分词
seg_list_exact = jieba.cut(new_data, cut_all=False)
result_list = []
with open('./unknow.txt', 'w+', encoding='utf-8') as f:
con = f.readlines()
stop_words = set()
for i in con:
i = i.replace("\n", "") # 去掉读取每一行数据的\n
stop_words.add(i)
for word in seg_list_exact:
# 设置停用词并去除单个词
if word not in stop_words and len(word) > 1:
result_list.append(word)
print(result_list)
# stylecloud绘制词图
gen_stylecloud(
text=' '.join(result_list), # 输入文本
size=600, # 词图大小
collocations=False, # 词语搭配
font_path='C:/Windows/Fonts/msyh.ttc', #C:\Windows\Fonts目录下有诸多字体可选择,可自行替换。
output_name=''+png_name+'.png', #输出文本名
icon_name='fas fa-apple-alt', # 蒙版图片,暂不清楚能否替换
palette='cartocolors.qualitative.Bold_5' # palettable调色
)
I = mpimg.imread('./'+png_name+'.png')
plt.axis('off')
plt.imshow(I)
plt.show()
总结
第一种方法bug:
未能避免集数视频重命名问题,不能有效查找cid,同文件I/O流第三次写入,未能正常写入数据,导致未能正常匹配出cid,
打包问题:
我用的pyinstaller打包,打包前:建议将所需要的库拷贝到,Product.py相对路径下:site-packages里,若碰见打包问题可私聊我。