SpringCloudAlibaba中篇(Sentinel,Seata)(超级无敌认真好用,万字收藏篇!!!!)
文章目录
- SpringCloudAlibaba中篇(Sentinel,Seata)
-
- 1 Sentinel(流量处理)
-
- 1.1 分布式系统遇到的问题
- 1.2 服务雪崩
- 1.3 容错机制
- 1.4 什么是Sentinel
- 1.5 初步使用Sentinel-流控规则
- 1.6 Sentinel- @SentinelResource
- 1.7 初步使用Sentinel-降级规则
- 1.8 控制台部署
- 1.9 Sentinel整合SpringCloud-alibaba
- 1.10 sentinel-流控规则
-
- 1.10.1 sentinel-QPS-流控规则
- 1.10.2 sentinel-并发线程数-流控规则
- 1.10.3 BlockException统一异常处理
- 1.10.4 sentinel-关联流控模式
- 1.10.5 sentinel-链路流控模式
- 1.10.6 sentinel-流控效果介绍
- 1.10.7 sentinel-预热流控效果
- 1.10.8 sentinel-排队等待
- 1.11 sentinel-熔断降级规则
-
- 1.11.1 慢调用策略
- 1.11.2 异常比例
- 1.11.3 异常数
- 1.11.4 整合openfegin
- 1.11.5 热点参数限流
- 1.12sentinel—系统保护规则
- 1.13 sentinel—规则持久化
- 2 Seata(分布式事务)
-
- 2.1 什么是Seata?
- 2.2 分布式事务基础
-
- 2.2.1 2PC两阶段提交协议
- 2.2.2 2PC问题
- 2.2.3 分布式解决方案
- 2.2.4 Seata的AT模式
- 2.3 Seata简单使用
-
- 2.3.1 Seata-db服务搭建-数据源
- 2.3.2 Seata服务搭建-Nacos
- 2.3.3 Seata-Client搭建
-
- 2.3.3.1 如果是本地事务方式
- 2.3.3.1 采用seata进行分布式事务搭建
- 2.4 Seata运行原理
SpringCloudAlibaba中篇(Sentinel,Seata)
1 Sentinel(流量处理)
森特奈尔
1.1 分布式系统遇到的问题

1.2 服务雪崩
服务雪崩效应:因为服务生产者的不可用导致服务消费者的不可用,并将服务不可用放大化,就叫服务雪崩效应
导致服务不可用的原因:
-
流量激增
① 激增流量导致系统CPU/load彪高,无法正常处理请求
② 激增流量打垮冷系统(数据库连接未创建,缓存未预热)
③ 消息投递速度过快,导致消息挤压
-
不稳定服务依赖
① 慢SQL查询,卡爆连接池
② 第三方服务不响应,卡满线程池
③ 业务调用持续出现异常,产生大量副作用
1.3 容错机制
-
超时机制
当服务生产者不可用时,服务生产者会在设置的时间内继续请求,当超过设置的超时时间会自动断开该对该服务的请求,释放申请服务耗费的资源,一定程度可以解决不断申请挂掉服务导致资源耗尽的问题。
-
服务限流
假设某一个服务临界QPS(每秒访问量)为500,当QPS为800访问该服务时,该服务会分出300进行限流,对这300进行降级处理
-
隔离
原理与限流相似,只不过根据线程和信号来进行处理
- 信号隔离也可以用于限剩并发划问,防止B塞扩散。与线隔岛鼠大不同在于执行依絷代码的线程依然是请求线程(战线5需要通过信号申请,如果客户递是可信的且可以决速返回,可以使用信号隔高替换线程隔离降低开销。信号量的大小可以动态调整,线程池大小不可以。
-
服务熔断
远程服务不稳定或网络抖动时暂时关闭,就叫服务熔断
软件世界的断路器可以这样理解:
-
实时监测应用,如果发现在一定时间内失败次数/快败率达到一定阈值,就跳闸,断路器打开——此时,请求直按返回,而不去调用原本调用的逻辑。跳闸一段时间后(例如10秒),断路器会进入半开状态,这是一个瞬间态,此时允许一次请求调用该调用的逻辑,如果成功,则断路器关闭,应用正常调用;如果调用依然不成功,断路器继续回到打开状态,过段时间再进入半开状态尝试——通过"跳闸",应用可以保护自己,而且避免浪费资源;而通过半开的设计,可实现应用的"自我修复"。
- 所以,同样的道理,当依赖的服务有大量超时时,在让新的请求去访问根本没有意义,只会无畏的消耗现有资源。比如我们设置了超时时间为1s,如果短时间内有大量请求在1s内都得不到响应,就意味着这个服务出现了异常,此时就没有必要再让其他的请求去访问这个依赖了,这个时候就应该使用断路器避免资源浪费。
-
-
服务降级
有服务熔断,必然有降级
当服务熔断,服务将不再被调用,此时服务端不能向客户端发送异常,就会有服务降级(就是A计划行不通,执行B计划)
弱依赖:某些服务挂掉不影响系统直接使用,就会使用弱依赖,将系统本来要调用该服务发送的值,转成一个日志,便于后续恢复
强依赖:某些服务挂掉直接影响系统使用
降级通常在弱依赖中实现
上述容错机制我们自己实现起来非常困难,Sentinel就提供了帮我们实现上述容错机制的方法
1.4 什么是Sentinel
分布式系统流量防卫兵-帮我们挡住客户端来势汹汹的流量
随着微服务的流行,服务和服务之间的稳定性变得越来越重要。 Sentinel 以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。
Sentinel官网:https://sentinelguard.io/zh-cn/docs/introduction.html
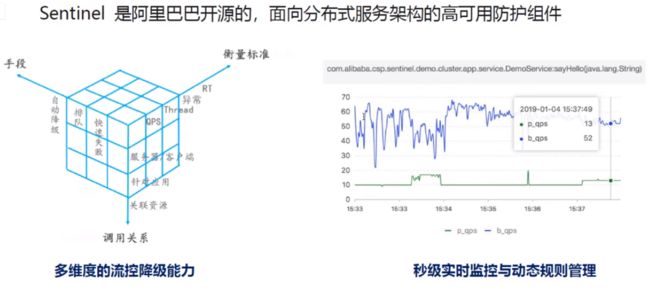
Sentinel 具有以下特征:
- 丰富的应用场景: Sentinel 承接了阿里巴巴近 10 年的双十一大促流量的核心场景,例如秒杀(即突发流量控制在系统容量可以承受的范围)、消息削峰填谷、实时熔断下游不可用应用等。
- 完备的实时监控: Sentinel 同时提供实时的监控功能。您可以在控制台中看到接入应用的单台机器秒级数据,甚至 500 台以下规模的集群的汇总运行情况。
- 广泛的开源生态: Sentinel 提供开箱即用的与其它开源框架/库的整合模块,例如与 Spring Cloud、Dubbo、gRPC 的整合。您只需要引入相应的依赖并进行简单的配置即可快速地接入 Sentinel。
- 完善的 SPI 扩展点: Sentinel 提供简单易用、完善的 SPI 扩展点。您可以通过实现扩展点,快速的定制逻辑。例如定制规则管理、适配数据源等。
阿里云提供了企业级的Sentinel服务,应用高可用服务AHAS
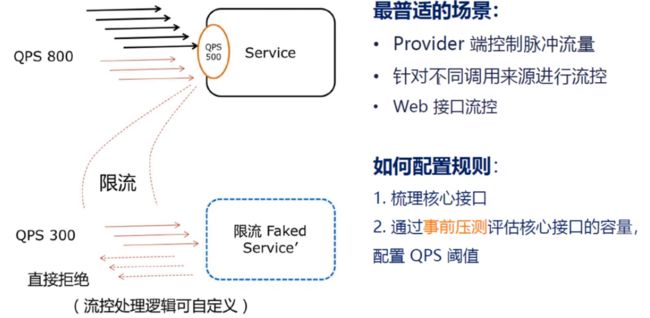
流量控制在网络传输中是一个常用的概念,它用于调整网络包的发送数据。然而,从系统稳定性角度考虑,在处理请求的速度上,也有非常多的讲究。任意时间到来的请求往往是随机不可控的,而系统的处理能力是有限的。我们需要根据系统的处理能力对流量进行控制。Sentinel 作为一个调配器,可以根据需要把随机的请求调整成合适的形状,如下图所示: [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dFz6w4p2-1685193213097)(img/流量控制.png)]
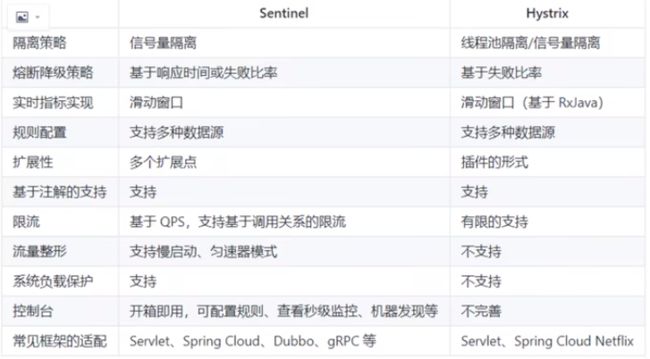
Sentinel和Hystrix对比
1.5 初步使用Sentinel-流控规则
Sentinel 的使用可以分为两个部分:
- 核心库(Java 客户端):不依赖任何框架/库,能够运行于 Java 8 及以上的版本的运行时环境,同时对 Dubbo / Spring Cloud 等框架也有较好的支持(见 主流框架适配)。
- 控制台(Dashboard):Dashboard 主要负责管理推送规则、监控、管理机器信息等。
流控规则
| Field | 说明 | 默认值 |
|---|---|---|
| resource | 资源名,资源名是限流规则的作用对象 | |
| count | 限流阈值 | |
| grade | 限流阈值类型,QPS 或线程数模式 | QPS 模式 |
| limitApp | 流控针对的调用来源 | default,代表不区分调用来源 |
| strategy | 调用关系限流策略:直接、链路、关联 | 根据资源本身(直接) |
| controlBehavior | 流控效果(直接拒绝 / 排队等待 / 慢启动模式),不支持按调用关系限流 | 直接拒绝 |
① 引入 Sentinel等 依赖
<dependency>
<groupId>com.alibaba.cspgroupId>
<artifactId>sentinel-coreartifactId>
<version>1.8.6version>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<version>1.18.26version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
②controller层进行流控
@RestController
@Slf4j
public class HelloController {
private static final String RESOURCE_NAME = "hello";
private static final String USER_RESOURCE_NAME = "user";
private static final String DEGRADE_RESOURCE_NAME = "degrade";
//进行Sentinel流控
@RequestMapping("/hello")
public String hello() {
Entry entry = null;
try {
//把资源交给sentinel进行监控
entry = SphU.entry(RESOURCE_NAME);
//被保护业务逻辑
String str = "hello word";
log.info("---------" + str + "---------");
return str;
} catch (BlockException e) {
log.info("block");
return "被流控了!";
} catch (Exception e) {
//若需要配置降级规则,需要通过这种方式记录业务异常
Tracer.traceEntry(e, entry);
} finally {
if (entry != null) {
entry.exit();
}
}
return null;
}
/**
* 定义流控规则
*/
@PostConstruct //被该注解修饰后,该类创建后,会自动调用被改注解修饰的方法
private static void initFlowRules() {
//流控规则集合
List<FlowRule> rules = new ArrayList<>();
//流控
FlowRule rule = new FlowRule();
//设置被保护的资源
rule.setResource(RESOURCE_NAME);
//设置流控规则:QPS
rule.setGrade(RuleConstant.FLOW_GRADE_QPS);
// 设置受保护阈值为1
rule.setCount(1);//
//添加规则
rules.add(rule);
//加载配置的规则
FlowRuleManager.loadRules(rules);
}
}
③配置类配置端口为7050,启动类启动,浏览器输入http://localhost:7050/访问
每秒访问次数小于1控制台输出:
---------hello word---------每秒访问次数大于1,受到保护规则保护,控制台输出:
block
1.6 Sentinel- @SentinelResource
上述代码被流控资源耦合度过高,
@SentinelResource:可以改善我们上述接口中资源定义,和被流控降级后的处理方法
@SentinelResource 注解包含以下属性:
-
value:资源名称,必需项(不能为空) -
blockHandler:设置被流控后,执行的方法该方法默认在同一个类,若需要放在其他类,需要通过
blockHandlerClass属性来指定 -
fallback:当接口出现了异常,交给fallback指定的方法处理该方法默认在同一个类,若需要放在其他类,需要通过
fallbackHandlerClass属性来指定 -
exceptionsToIgnore:排除哪些异常不会被处理,也不会进入 fallback 逻辑中,而是会原样抛出。 -
entryType:entry 类型,可选项(默认为EntryType.OUT)
①添加依赖
<dependency>
<groupId>com.alibaba.cspgroupId>
<artifactId>sentinel-annotation-aspectjartifactId>
<version>1.8.6version>
dependency>
②配置bean:SentinelResourceAspect
若您的应用使用了 Spring AOP(无论是 Spring Boot 还是传统 Spring 应用),您需要通过配置的方式将
SentinelResourceAspect注册为一个 Spring Bean:
@SpringBootApplication
public class SentinelDemo_7050 {
public static void main(String[] args) {
SpringApplication.run(SentinelDemo_7050.class);
}
@Bean
public SentinelResourceAspect sentinelResourceAspect() {
return new SentinelResourceAspect();
}
}
③使用SentinelResource
//同时使用fallback和blockHandler,优先被blockHandler处理
@RequestMapping("/user")
@SentinelResource(value = USER_RESOURCE_NAME,fallback = "fallbackHandlerForGetUser",blockHandler = "blockHandlerForGetUser")
public User getUser(String id) {
throw new RuntimeException("抛出异常");
//return new User("huozhexiao");
}
/**
* 注意:
* 1. 一定要是public
* 2. 返回值要与资源方法保持一致,包含源方法的参数
* 3. 可以在参数后添加BlockException,可以区分是什么方法的处理方法
* @param id
* @param e
* @return
*/
public User blockHandlerForGetUser(String id,BlockException e){
e.printStackTrace();
return new User("被流控了!!");
}
public User fallbackHandlerForGetUser(String id,Throwable e){
e.printStackTrace();
return new User("异常处理");
}
//------流控规则------
1.7 初步使用Sentinel-降级规则
降级规则
| Field | 说明 | 默认值 |
|---|---|---|
| resource | 资源名,即规则的作用对象 | |
| grade | 熔断策略,支持慢调用比例/异常比例/异常数策略 | 慢调用比例 |
| count | 慢调用比例模式下为慢调用临界 RT(超出该值计为慢调用);异常比例/异常数模式下为对应的阈值 | |
| timeWindow | 熔断时长,单位为 s | |
| minRequestAmount | 熔断触发的最小请求数,请求数小于该值时即使异常比率超出阈值也不会熔断(1.7.0 引入) | 5 |
| statIntervalMs | 统计时长(单位为 ms),如 60*1000 代表分钟级(1.8.0 引入) | 1000 ms |
| slowRatioThreshold | 慢调用比例阈值,仅慢调用比例模式有效(1.8.0 引入) |
-
被监管的资源及降级处理
@RequestMapping("/degrade") @SentinelResource(value = DEGRADE_RESOURCE_NAME, entryType = EntryType.IN, blockHandler = "blockHandlerForFb") public User degrade(String id) { throw new RuntimeException("抛出异常"); // return new User("huozhexiao"); } public User blockHandlerForFb(String id, BlockException e) { e.printStackTrace(); return new User("降级处理!!!"); } -
定义降级规则
/**
* 定义降级规则
*/
@PostConstruct
public void initDegradeRule() {
//降级规则集合
List<DegradeRule> degradeRules = new ArrayList<>();
DegradeRule degradeRule = new DegradeRule();
degradeRule.setResource(DEGRADE_RESOURCE_NAME);
//设置规则侧率:异常数
degradeRule.setGrade(RuleConstant.DEGRADE_GRADE_EXCEPTION_COUNT);
//阈值
//异常数
degradeRule.setCount(2);
//最小请求数
degradeRule.setMinRequestAmount(2);
//统计时长:1min
degradeRule.setStatIntervalMs(60 * 1000);
/*熔断持续时长:出现熔断后,10s内调用我们的降级方法
10s后会进入半开状态:恢复接口请求,如果第一次请求就异常,再次熔断,不会根据设置条件进行判定
*/
degradeRule.setTimeWindow(10);
degradeRules.add(degradeRule);
DegradeRuleManager.loadRules(degradeRules);
}
1.8 控制台部署
① 下载Sentinel控制台jar包,根据本篇文章的springcloud-alibaba版本对应这里是 1.8.5
https://github.com/alibaba/Sentinel/releases
② 启动控制台命令
注意:启动 Sentinel 控制台需要 JDK 版本为 1.8 及以上版本。
java -jar sentinel-dashboard-1.8.5.jar
-
启动时可进行如下配置
-Dserver.port=8080:指定端口号;-Dcsp.sentinel.dashboard.server=localhost:8080:项目地址;-Dproject.name=sentinel-dashboard:项目名; -
用户可通过如下参数进行配置:
-Dsentinel.dashboard.auth.username=sentinel用于指定控制台的登录用户名为sentinel;-Dsentinel.dashboard.auth.password=123456用于指定控制台的登录密码为123456;如果省略这两个参数,默认用户和密码均为sentinel;-Dserver.servlet.session.timeout=7200用于指定 Spring Boot 服务端 session 的过期时间,如7200表示 7200 秒;60m表示 60 分钟,默认为 30 分钟;
③ 每次输入命令都会麻烦,我们可以创建批处理文件sentinel-dashboard.bat,内容如下
java -Dserver.port=1234 -Dsentinel.dashboard.auth.username=huozhexiao -Dsentinel.dashboard.auth.password=123456 -jar E:\IOT\LinuxSoft\sentinel-dashboard-1.8.5.jar
pause
④ 客户端整合控制台
- 引入依赖
<dependency>
<groupId>com.alibaba.cspgroupId>
<artifactId>sentinel-transport-simple-httpartifactId>
<version>1.8.6version>
dependency>
-
配置启动参数
在idea启动配置的VM参数加入 JVM 参数
-Dcsp.sentinel.dashboard.server=consoleIp:port指定控制台地址和端口。若启动多个应用,则需要通过-Dcsp.sentinel.api.port=xxxx指定客户端监控 API 的端口(默认是 8719)。
除了修改 JVM 参数,也可以通过配置文件取得同样的效果。
⑤ 触发客户端初始化
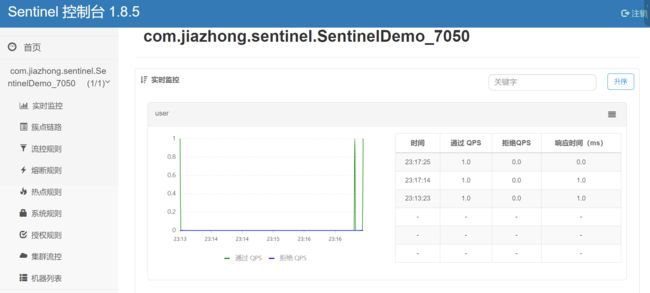
Sentinel 会在客户端首次调用的时候进行初始化,开始向控制台发送心跳包,所以要确保客户端有访问量;
访问:http://localhost:7050/user
查看控制台,服务被监控起来了
1.9 Sentinel整合SpringCloud-alibaba
- 引入依赖
<dependency>
<groupId>com.alibaba.cloudgroupId>
<artifactId>spring-cloud-starter-alibaba-sentinelartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-actuatorartifactId>
dependency>
- 配置文件
server:
port: 7006
#应用名称,(服务名称)
spring:
application:
name: order-sentinel-service
cloud:
sentinel:
transport:
dashboard: localhost:1234
- controller
@RestController
@RequestMapping("/order")
public class OrderController {
@RequestMapping("/add")
public String add(){
System.out.println("下单成功!!!");
return "下单成功!!!";
}
@RequestMapping("/flow")
public String flow(){
return "正常访问";
}
}
- 启动类
@SpringBootApplication
public class OrderSentinel_7006 {
public static void main(String[] args) {
SpringApplication.run(OrderSentinel_7006.class);
}
}
- 如下可进行一些流控,熔断,热点,授权等规则的设置
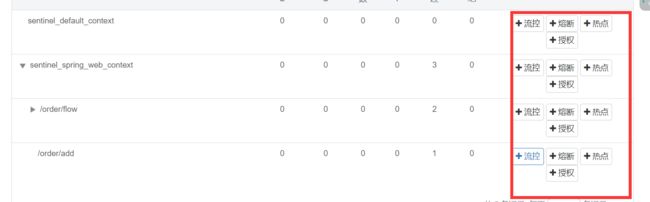
1.10 sentinel-流控规则
1.10.1 sentinel-QPS-流控规则
- 流量控制(flow control),其原理是监控应用流量的QPS或并发线程数等指标,当达到指定的阈值时对流量进行控制,以避免被瞬时的流量高峰冲垮,从而保障应用的高可用性, FlowRuleRT(响应时间)1/0.2s =5
- 应对洪峰流量∶秒杀,大促,下单,订单回流处理
- 消息型场景∶削峰填谷,冷热启动
- 付费系统∶根据使用流量付费
- API Gateway:精准控制API流量
- 任何应用∶探测应用中运行的慢程序块,进行限制
-
设置流控规则
资源名:被流控资源
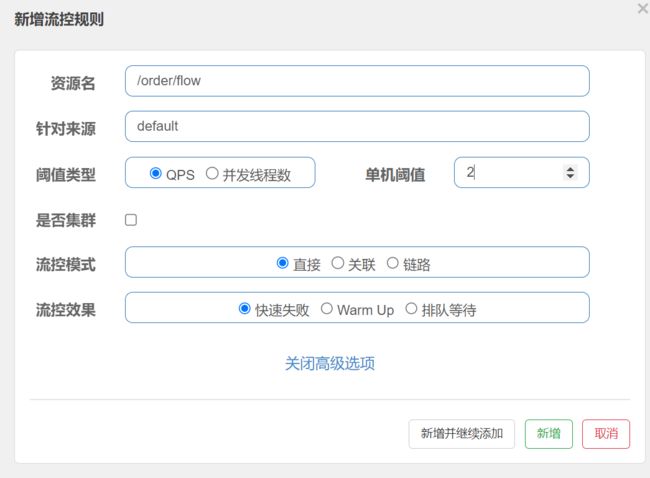
每秒访问三次时:Blocked by Sentinel (flow limiting)
-
用
@SentinelResource设置被流控后的方法@RequestMapping("/flow") @SentinelResource(value = "flow" , blockHandler = "flowBlockHandler") public String flow(){ return "正常访问"; } public String flowBlockHandler(BlockException e){ return "流控"; }
1.10.2 sentinel-并发线程数-流控规则
- 并发数控制用于保护业务线程池不被慢调用耗尽。例如,当应用所依赖的下游应用由于某种原因导致服务不稳定、响应延迟增加,对于调用者来说,意味着吞吐量下降和更多的线程数占用,极端情况下甚至导致线程池耗尽。为应对太多线程占用的情况,业内有使用隔离的方案,比如通过不同业务逻辑使用不同线程池来隔离业务自身之间的资源争抢(线程池隔离)。这种隔离方案虽然隔离性比较好,但是代价就是线程数目太多,线程上下文切换的overhead 比较大,特别是对低延时的调用有比较大的影响。Sentinel并发控制不负责创建和管理线程池而是简单统计当前请求上下文的线程数目(正在执行的调用数目),如果超出阈值,新的请求会被立即拒绝,效果类似于信号量隔离。并发数控制通常在调用端进行配置。
并发线程数,主要用于线程池被耗尽的情况
-
控制台进行设置
-
Controller层
@RequestMapping("/flowThread") @SentinelResource(value = "flowThread" , blockHandler = "flowBlockHandler") public String flowThread(){ try { TimeUnit.MILLISECONDS.sleep(10000); } catch (InterruptedException e) { e.printStackTrace(); } return "正常访问"; } public String flowBlockHandler(BlockException e){ return "流控"; }
1.10.3 BlockException统一异常处理
- 自定义BlockExceptionHandler 的实现类统—处理BlockException
没有统一异常处理结果不建议使用
@Component
public class MyBlockExceptionHandler implements BlockExceptionHandler {
Logger logger = LoggerFactory.getLogger(this.getClass());
@Override
public void handle(HttpServletRequest request, HttpServletResponse response, BlockException e) throws Exception {
//getRule()包含资源信息
logger.info("BlockExceptionHandler BlockException===========" + e.getRule());
//结果处理类
Result r = null;
if (e instanceof FlowException) {
r = Result.error(100, "接口限流了");
} else if (e instanceof DegradeException) {
r = Result.error(101, "服务降级了");
} else if (e instanceof ParamFlowException) {
r = Result.error(102, "热点参数限流了");
} else if (e instanceof SystemBlockException) {
r = Result.error(103, "触发系统保护规则了");
} else if (e instanceof AuthorityException) {
r = Result.error(104, "授权规则不通过");
}
//返回json数据
response.setStatus(500);
response.setCharacterEncoding("utf-8");
response.setContentType(MediaType.APPLICATION_JSON_VALUE);
new ObjectMapper().writeValue(response.getWriter(), r);
}
}
1.10.4 sentinel-关联流控模式
直接流控模式:收到的限制是其本身
- 基于调用关系的流量控制。调用关系包括调用方、被调用方;一个方法可能会调用其它方法,形成一个调用链路的层次关系。
关联
当两个资源之间具有资源争抢或者依赖关系的时候,这两个资源便具有了关联。比如加对数据库同一个字段的读操作和写操作存在争抢,读的速度过高会影响写得速度,写的速度过高会影响读的速度。如果放任读写操作争抢资源,则争抢本身带来的开销会降低整体的吞吐量。可使用关联限流来避免具有关联关系的资源之间过度的争抢,举例来说,read_db和write_db这两个资源分别代表数据库读写,我们可以给read_db设置限流规则来达到写优先的目的:设置stratey为BaleCcnsat. STkeECY_BLE 同时设置refResoure 为wite.db。这样当写库操作过于频繁时,读数担的请求会被限流。
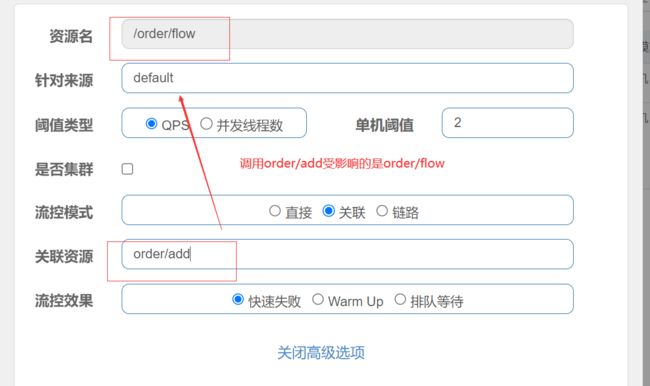
-
Controller
生成订单触发查询订单的限流
@RestController @RequestMapping("/order") public class OrderController { @RequestMapping("/add") public String add(){ System.out.println("下单成功!!!"); return "下单成功!!!"; } @RequestMapping("/get") public String get(){ System.out.println("查询订单!!!"); return "查询订单!!!"; } } -
使用Jmeter测试
1.10.5 sentinel-链路流控模式
-
主要针对调用链路数结构进行流控
getUserorder/test1order/test2上图中来自入口/ordertest1和/ordertest2的请求都调用到了资源getUser,Sentinel允许只根据某个入口的统计信息对资源限流。
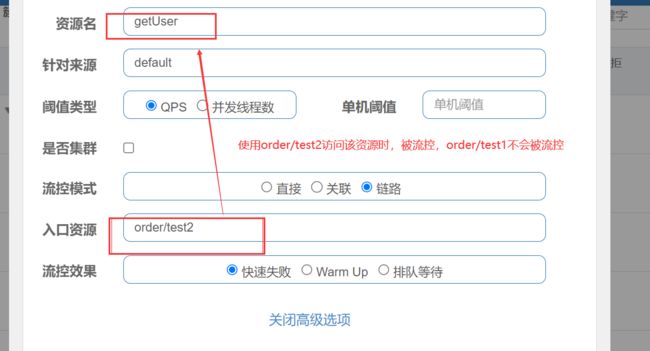
-
Service
@Service public class OrderServiceImpl implements OrderService { @Override @SentinelResource(value = "getUser",blockHandler = "getUserBlockHandler") public String getUser() { return "查询用户"; } public String getUserBlockHandler(BlockException e) { return "被限流"; } } -
Controller
@RestController @RequestMapping("/order") public class OrderController { @Resource private OrderService orderService; @RequestMapping("/test1") public String test1(){ return orderService.getUser()+"1"; } @RequestMapping("/test2") public String test2(){ return orderService.getUser()+"2"; } } -
测试会发现链路规则不生效
-
坑:
从1.6.3 版本开始,Sentinel Web filter默认收敛所有URL的入口context,因此链路限流不生效
默认使用链路时会有一个链路数,Sentinel默认情况不会维护有这个调用链路数,需要在yml中配置
spring.cloud.sentinel.web-context-unify: false
-
1.10.6 sentinel-流控效果介绍
- 快速失败:超过流控所设规则,多余流量直接被拒绝
- Warm UP:在预热时间长内慢慢接受流量
- 排队等待:设置一个阈值为10,一个超时时间5000ms,此时有20个流量请求该资源,前10个请求成功,后10个不会直接失败,会在超时时间内等待前10个流量的使用完毕
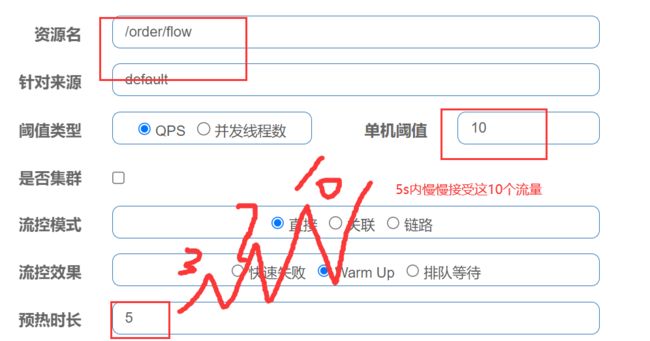
1.10.7 sentinel-预热流控效果
秒杀场景下,该方法可预防缓存击穿
激增流量:突然有大量流量请求一个不经常访问的流量
WamUp(RuleConstant.CONTROL_BEHAVIOR_WARM_UP)方式,即预热/冷启动方式。当系统长期处于低水位的情况下,当流量突然增加时,直接把系统拉升到高水位可能瞬间把系统压垮,通过"冷启动",让通过的流量缓慢增加,在一定时间内逐渐增加到阈值上限,给冷系统一个预热的时间,避免冷系统被压垮。
冷加载因子: codeFactor默认是3,即请求QPS 从 threshold / 3开始,经预热时长逐渐升至设定的QPS 阈值
1.10.8 sentinel-排队等待
脉冲流量:流量高一下,低一下,超时时间就是利用流量高和低之间的间隔时间
匀速排队(RuleConstant.CONTROL_BEHAVIOR_RATE_LMITER)方式会严格控制请求通过的间隔时间,也即是让请求以均匀的速度通过,对应的是漏桶算法。
- 如果是直接失败的话,间隔5s,每秒请求10次
5次成功5次失败,间隔的5s时间就会浪费
- 如果是排队等待的话,中间的间隔5s会被利用起来
仍然还有5次失败,但是不会立即失败,会在队列中等待成功的完成
1.11 sentinel-熔断降级规则
-
除了流量控制以外,对调用链路中不稳定的资源进行熔断降级也是保障高可用的重要措施之一。我们需要对不稳定的弱依赖服务调用进行熔断降级,暂时切断不稳定调用,避免局部不稳定因素导致整体的雪崩。熔断降级作为保护自身的手段,通常在客户端(调用端)进行配置。
弱依赖:某些服务挂掉不影响系统直接使用,就会使用弱依赖,将系统本来要调用该服务发送的值,转成一个日志,便于后续恢复
强依赖:某些服务挂掉直接影响系统使用
-
熔断降级与隔离
保护自身的手段
通常在consumer端配置
- 并发控制(信号量隔离)
- 基于慢调用比例熔断
- 基于异常比例熔断
触发熔断后处理逻辑示例
- 提供fallback实现(服务降级)
- 返回错误result
- 读缓存(DB访问降级)
1.11.1 慢调用策略
-
慢调用比例(
SLOW_REQUEST_RATIO):选择以慢调用比例作为阈值,需要设置允许的慢调用RT(即最大的响应时间),请求的响应时间大于该值则统计为慢调用。当单位统计时长(statIntervalMs)内请求数目大于设置的最小请求数目,并且慢调用的比例大于阈值,则接下来的熔断时长内请求会自动被熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN状态),若接下来的一个请求响应时间小于设置的慢调用RT则结束熔断,若大于设置的慢调用RT则会再次被熔断。
-
Controller
@RequestMapping("/flowThread") public String flowThread(){ try { TimeUnit.SECONDS.sleep(2); } catch (InterruptedException e) { e.printStackTrace(); } return "正常访问"; } -
慢调用策略
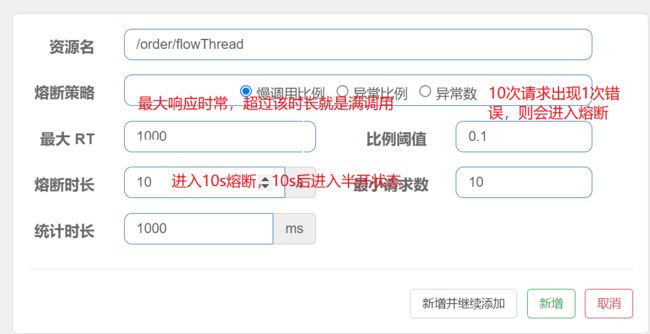
半开状态:第一次请求出现慢调用直接熔断
-
Jmeter测试
保证请求书大于最小请求数

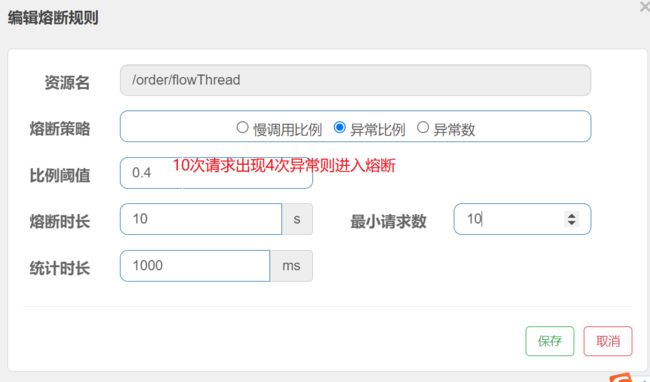
1.11.2 异常比例
-
Controller
@RequestMapping("/myError") public String myError(){ int a=1/0; return "error"; } -
异常比例
-
Jmeter测试
1.11.3 异常数
与异常比例不同的是,达到所设置异常数就会进入熔断…
1.11.4 整合openfegin
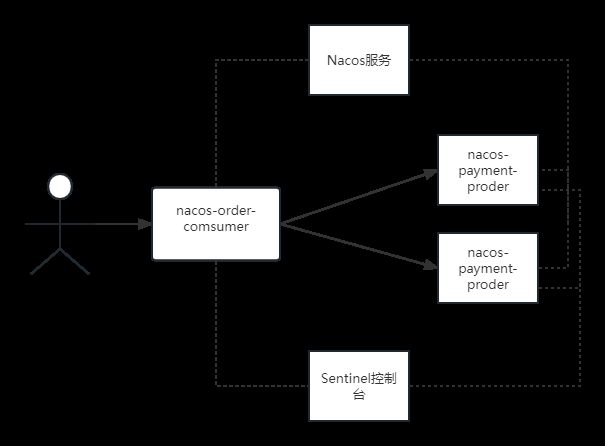
-
引入依赖
<dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-webartifactId> dependency> <dependency> <groupId>com.alibaba.cloudgroupId> <artifactId>spring-cloud-starter-alibaba-nacos-discoveryartifactId> dependency> <dependency> <groupId>org.springframework.cloudgroupId> <artifactId>spring-cloud-starter-openfeignartifactId> dependency> <dependency> <groupId>com.alibaba.cloudgroupId> <artifactId>spring-cloud-starter-alibaba-sentinelartifactId> dependency> -
application.yml配置
server: port: 7007 #应用名称,(服务名称) spring: application: name: order-openfegin-sentinel-service cloud: #配置nacos nacos: server-addr: 192.168.198.129:8849 discovery: #配置用户名和密码 username: nacos password: nacos namespace: public #开启对fegin的支持 feign: sentinel: enabled: true -
openfegin接口
@FeignClient(name = "stock-service", path = "/stock ",fallback = StockFeginServiceImpl.class) public interface StockFeginService { //声明需要调用的方法 @RequestMapping("/del2") public String del2(); } -
openfegin的fallback实现类
@Component public class StockFeginServiceImpl implements StockFeginService { @Override public String del2() { return "降级了"; } }
1.11.5 热点参数限流
- 何为热点?热点即经常访问的数据。很多时候我们希望统计某个热点数据中访问频次最高的数据,并对其访问进行限制。
常用场景
- 热点商品访问/操作控制
- 用户/IP防刷
实现原理
- 热点淘汰策略(LRU)+Token Bucket流控
热点参数限流会统计传入参数中的热点参数,并根据配置的限流阈值与模式,对包含热点参数的资源调用进行限流。热点参数限流可以看做是一种特殊的流量控制,仅对包含热点参数的资源调用生效。
实现demo
- Controller层
/**
* 热点规则:必须使用@SentinelResource
* @param id
* @return
*/
@RequestMapping("/get/{id}")
@SentinelResource(value = "getById",blockHandler = "HotBlockHandler")
public String getById(@PathVariable("id") Integer id){
System.out.println("查询商品"+id);
return "查询商品"+id;
}
public String HotBlockHandler(@PathVariable("id") Integer id,BlockException e){
return "热点异常处理";
}
-
热点规则
注意:资源名必须是@SentinelResource(value=“资源名”)中配置的资源名,热点规则依赖于注解
单机阈值:
1.假设参数大部分值都是热点参数;那单机阈值就主要针对热点参数进行流控,瞭后续额外针对普通的参数值进行流控
2.假设大部分值都是普通流量,反之;
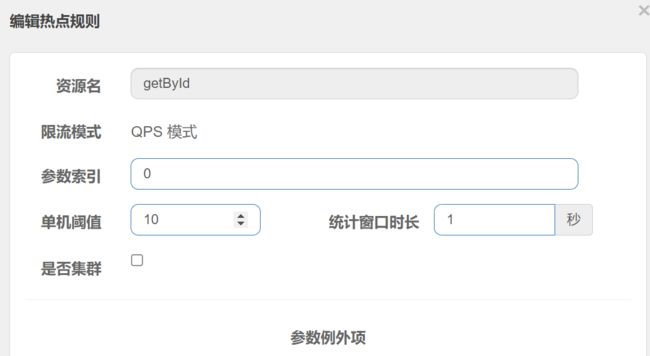
普通流量,阈值为10时,进行限流
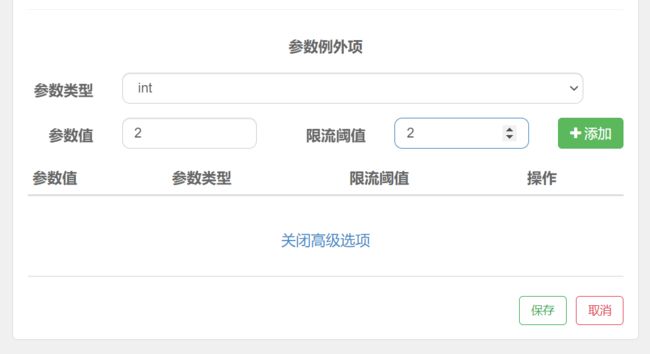
热点流量,阈值为2时,进行限流
1.12sentinel—系统保护规则
- 容量评估不到位,某个大流量接口限流配置不合理或没有配置,导致系统崩溃,来不及进行处理。
- 突然发现机器的Load和CPU usage等开始飚高,但却没有办法很快的确认到是什么原因造成的,也来不及处理。
- 当其中一台机器挂了之后,本该由这台机器处理的流量被负载均衡到另外的机器上,另外的机器也被打挂了,引起系统雪崩。
- 希望有个全局的兜底防护,即使缺乏容量评估也希望有一定的保护机制。
Serninel系统自适应限流从整体维度对应用入口流量进行控制,结合应用的Load,CPU使用率、总体平均RT、入口QPS和并发线程数等几个维度的监控指标,通过自适应的流控策略,让系统的入口流量和系统的负载达到一个平衡,让系统尽可能跑在最大吞吐量的同时保证系统整体的稳定性。
-
Load自适应(仅对Linux/Unix-like机器生效)∶系统的load1作为启发指标,进行自适应系统保护。当系统load1超过设定的启发值,且系统当前的并发线程数超过估算的系统容量时才会触发系统保护(BBR阶段)。系统容量由系统的
maxOps * minRt估算得出。设定参考值一般是CPU cores * 2.5。一核CPU对应我们一条公路,一个进程对应一辆汽车。
在一条公路上,只有一辆汽车行驶,load=1没有出现拥堵的情况
如果有两量汽车行驶在一条公路上行驶,会出现拥堵的情况,需要排队,这是load=2
cpu核数=12,当系统load=12时,系统cpu刚刚好在该机器cpu能处理的范围内
当load>12时,机器就超出负荷了,会有任务出现等待的情况。
-
CPU usage (1.5.0+版本)︰当系统CPU使用率超过阈值即触发系统保护(取值范围0.0-1.0),比较灵敏。
-
平均RT:当单台机器上所有入口流量的平均RT达到阈值即触发系统保护,单位是毫秒。
-
并发线程数:当单台机器上所有入口流量的并发线程数达到阈值即触发系统保护。
-
入口QPS:当单台机器上所有入口流量的QPS达到阈值即触发系统保护。
1.13 sentinel—规则持久化
- 一旦我们重启应用,Sentinel规则将消失,生产环境需要将配置规则进行持久化
Sentinel有三种持久化模式
| 推送模式 | 说明 | 优点 | 缺点 |
|---|---|---|---|
| 原始模式 | API将规则推送至客户端并直接更新到内存中,扩展写数据源(WritableDataSource) | 简单,无任何依赖 | 不保证一致性;规则保存在内存中,重启即消失。严重不建议用于生产环境 |
| Pull模式 | 扩展写数据源(WritableDataSource) ,客户端主动向某个规则管理中心定期轮询拉取规则,这个规则中心可以是 RDBMS、文件等 | 见简单,无任何依赖;规则持久化 | 不保证一致性;实时性不保证,拉取过于频繁也可能会有性能问题。 |
| Push模式 | 扩展读数据源(ReadableDataSource),规则中心统一推送,客户端通过注册监听器的方式时刻监听变化,比如使用Nacos.Zookeeper等配置中心。这种方式有更好的实时性和一致性保证。生产环境下一般采用push模式的数据源。 | 规则持久化;一致性;快速 | 引入第三方依赖 |
原始模式:如果不做任何修改,Dashboard 的推送规则方式是通过API将规则推送至客户端并直接更新到内存中
这种做法的好处是简单,无依赖;坏处是应用重启规则就会消失,仅用于简单测试,不能用于生产环境。
拉模式:pull模式的数据源(如本地文件、RDBMS等)一般是可写入的。使用时需要在客户端注册数据源:将对应的读数据源注册至对应的RuelManager,将写数据源注册至transpot的WritableDataSourceRegistry中。
推模式:生产环境下一般更常用的是 push模式的数据源。对于push模式的数据源如远程配置中心(Zokeeper Nacos,Apollo等等),推送的操作不应由Seninel客户端进行,而应该经控制台统一进行管理,直接进行推送,数据源仅负责获取配置中心推送的配置并更新到本地。因此推送规则正确做法应该是配置中心控制台/Sertinel控制台→配置中心→ Sentinel 数据源→ Sentinel,而不是经Sentinel数据源推送至配置中心。这样的流程就非常清晰了;
① 基于Nacos配置中心控制台实现推送
- 引入依赖
<dependency>
<groupId>com.alibaba.cspgroupId>
<artifactId>sentinel-datasource-nacosartifactId>
dependency>
- Nocas配置文件,配置
[
{
"resource":"/order/flow", //资源
"limitApp":"default", //来源应用
"grade":1, //阈值类型,0表示线程数,1表示QPS
"count":1, //单机阈值
"strategy":0, //流控模式,0表示直接,1表示关联,2表示链路;
"controlBehavior":0, //流控效果,0表示快速失败,1表示Warm Up,2表示排队等待;
"clusterMode":false //是否集群
}
]
- yml配置
server:
port: 7006
#应用名称,(服务名称)
spring:
application:
name: order-sentinel-service
cloud:
sentinel:
transport:
dashboard: localhost:1234
web-context-unify: false
datasource:
flow-rule: #自定义
nacos:
server-addr: 192.168.65.220:8847
username: nacos
password: nacos
data-id: order-sentinel-service-flow-rule
rule-type: flow
2 Seata(分布式事务)
sei他
2.1 什么是Seata?
Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案。
AT模式是阿里首推的模式,阿里云上有商用版本的GTS (Global Transaction Service 全局事务服务)
- 本地事务:Spring的
@Transactional:在单体应用中,多个业务操作一组数据,这些数据在同一个数据库,很容易实现事务,但是在分布式环境中该事务只能控制自己回滚,不能控制其他服务回滚;
2.2 分布式事务基础
- 常见分布式事务的解决方案
- seata 阿里分布式事务框架
- 消息队列
- saga
- XA
他们有一个共同点,都是"两阶段(2PC)"。"两阶段"是指完成整个分布式事务,划分成两个步骤完成。
这四种常见的分布式事努解决方案,分别对应着分布式事务的四种模式:AT、TCC、Saga、XA;
2.2.1 2PC两阶段提交协议
两阶段分为:Prepare和Commit
-
一阶段Prepare:预处理
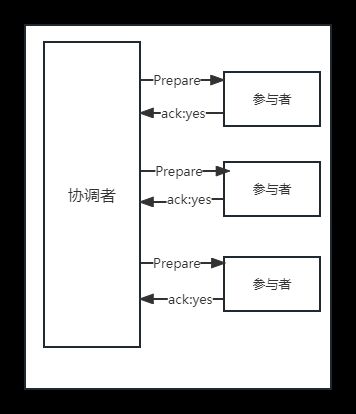
协调者:(中间件协调者/事务管理器)
参与者:(数据库,应用服务)
具体流程
① 询问 协调者向所有事务参与者发送事务请求,询问是否可执行事务操作,然后等待各个参与者响应
② 执行 各个参与者接受到协调者的事务请求后,执行事务操作,并将undo,redo信息记录事务日志
③ 响应 如果事务参与者成功执行了事务并写入undo和redo信息,向协调者返回yes响应,否则返回no响应,当然事务也能宕机,从而不会返回响应
-
二阶段Commit:提交
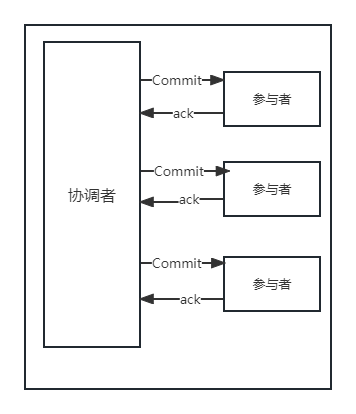
具体流程
① commit请求 协调者向参与者发送Commit请求
② 事务提交 参与者收到Commit请求后,执行事务提交,提交完成后释放事务执行期占用所用资源
③ 反馈结果 参与者执行事务提交后向协调者发生Ack请求
④ 完成事务 接受所有参与者Ack响应后,完成事务提交
2.2.2 2PC问题
-
同步阻塞:同步阻塞参与者在等待协调者的指令时,其实是在等待其他参与者的响应,在此过程中,参与者是无法进行其他操作的,也就是阻塞了其运行。倘若参与者与协调者之间网络异常导致参与者一直收不到协调者信息,那么会导致参与者一直阻塞下去。
-
单点在2PC中,一切请求都来自协调者,所以协调者的地位是至关重要的,如果协调者宕机,那么就会使参与者一直阻塞并一直占用事务资源。如果协调者也是分布式,使用选主方式提供服务,那么在一个协调者挂掉后,可以选取另一个协调者继续后续的服务,可以解决单点问题。但是,新协调者无法知道上一个事务的全部状态信息(例如已等待 Prepare 响应的时长等),所以也无法顺利处理上一个事务。
-
数据不一致 Commit事务过程中Commit请求/Rollback请求可能因为协调者宕机或协调者与参与者网络问题丢失,那么就导致了部分参与者没有收到Commit/Rollback请求,而其他参与者则正常收到执行了Commit/Rollback操作,没有收到请求的参与者则继续阻塞。这时,参与者之间的数据就不再一致了。当参与者执行Commit/Rollback后会向协调者发送Ack,然而协调者不论是否收到所有的参与者的Ack,该事务也不会再有其他补救措施了,协调者能做的也就是等待超时后像事务发起者返回一个“我不确定该事务是否成功”。
-
环境可靠性依赖协调者Prepare请求发出后,等待响应,然而如果有参与者宕机或与协调者之间的网络中断,都会导致协调者无法收到所有参与者的响应,那么在2PC中,协调者会等待一定时间,然后超时后,会触发事务中断,在这个过程中,协调者和所有其他参与者都是出于阻塞的。这种机制对网络问题常见的现实环境来说太苛刻了。
2.2.3 分布式解决方案
- AT模式
AT 模式是一种无侵入的分布式事务解决方案
阿里seata框架,实现了该模式。
在AT模式下,用户只需关注自己的“业务SQL”,用户的“业务SQL”作为一阶段,Seata框架会自动生成事务的二阶段提交和回滚操作。
-
一阶段
在一阶段,Seata 会拦截“业务SQL”,首先解析SQL语义,找到“业务SQL”要更新的业务数据,在业务数据被更新前,将其保存成“before image”,然后执行“业务SQL”更新业务数据,在业务数据更新之后,再将其保存成“after image”,最后生成行锁。以上操作全部在一个数据库事务内完成,这样保证了一阶段操作的原子性。
-
二阶段回滚
二阶段如果是回滚的话,Seata就需要回滚一阶段已经执行的“业务SQL”,还原业务数据。回滚方式便是用“before image”还原业务数据;但在还原前要首先要校验脏写,对比“数据库当前业务数据”和“after image”,如果两份数据完全一致就说明没有脏写,可以还原业务数据,如果不一致就说明有脏写,出现脏写就需要转人工处理。
-
TCC模式
① 侵入性强,自己实现相关事务逻辑
② 整个过程基本没有锁,性能更强
TCC模式需要用户根据自己的业务场景实现Try、Confirm和 Cancel三个操作;事务发起方在一阶段执行Try方式,在二阶段提交执行Confirm方法,二阶段回滚执行 Cancel 方法。
2.2.4 Seata的AT模式
- 三大角色
- TC(Transaction Coordinator)-事务协调者维护全局和分支事务的状态,驱动全局事务提交或回滚。
- TM(Transaction Manager)-事务管理器定义全局事务的范围开始全局事务、提交或回滚全局事务。
- RM(Resource Manager)-资源管理器分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
其中,TC为单独部署的Server 服务端,TM和RM为嵌入到应用中的Client客户端。
2.3 Seata简单使用
Server端存储模式(store.mode)现有file、db、redis三种(后续将引入raft,mongodb),file模式无需改动,直接启动即可,下面专门讲下db启动和redis启动。
- file模式为单机模式,全局事务会话信息内存中读写并持久化本地文件root.data,性能较高;
- db模式为高可用模式,全局事务会话信息通过db共享,相应性能差些;
- redis模式Seata-Server 1.3及以上版本支持,性能较高,存在事务信息丢失风险,请提前配置合适当前场景的redis持久化配置.
2.3.1 Seata-db服务搭建-数据源
-
资源目录介绍
- client
存放client端sql脚本 (包含 undo_log表) ,参数配置
- config-center
各个配置中心参数导入脚本,config.txt(包含server和client,原名nacos-config.txt)为通用参数文件
- server
server端数据库脚本 (包含 lock_table、branch_table 与 global_table) 及各个容器配置
① 官网下载启动包
https://github.com/seata/seata/releases
官网查询对应版本,我用的是
Seata 1.5.2
② 建表(仅db)
全局事务会话信息由3块内容构成,全局事务–>分支事务–>全局锁,对应表global_table、branch_table、lock_table
导入对应数据库
https://github.com/seata/seata/tree/master/script/server/db
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-w2IjB423-1685193213108)(img/seata-mysql.png)]
③ 修改store.mode
启动包: seata–>conf–>application.yml,修改store.mode=“db或者redis”
源码: 根目录–>seata-server–>resources–>application.yml,修改store.mode=“db或者redis”
1.5.0以下版本:
启动包: seata–>conf–>file.conf,修改store.mode=“db或者redis”
源码: 根目录–>seata-server–>resources–>file.conf,修改store.mode=“db或者redis”
④ 修改数据库连接
启动包: seata–>conf–>application.example.yml中附带额外配置,将其db|redis相关配置复制至application.yml,进行修改store.db或store.redis相关属性。
源码: 根目录–>seata-server–>resources–>application.example.yml中附带额外配置,将其db|redis相关配置复制至application.yml,进行修改store.db或store.redis相关属性。
1.5.0以下版本:
启动包: seata–>conf–>file.conf,修改store.db或store.redis相关属性。
源码: 根目录–>seata-server–>resources–>file.conf,修改store.db或store.redis相关属性。
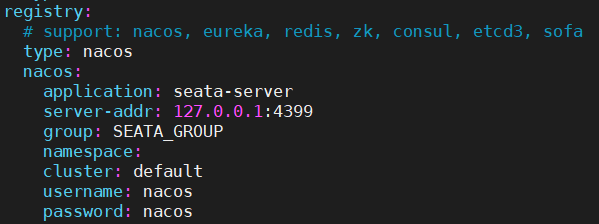
2.3.2 Seata服务搭建-Nacos
- 同样的修改注册中心为nacos
启动包: seata–>conf–>application.example.yml中附带额外配置,将其nacos相关配置复制至application.yml,进行修改registry相关属性。
源码: 根目录–>seata-server–>resources–>application.example.yml中附带额外配置,将nacos相关配置复制至application.yml,进行修改registry相关属性。
-
其余配置
集群模式可以配置负载均衡策略
loadBalance = “RandomLoadBalance”
loadBalanceVirtualNodes = 10
-
修改配置中心为Nacos
config: # support: nacos, consul, apollo, zk, etcd3 type: nacos nacos: server-addr: 127.0.0.1:4399 namespace: group: SEATA_GROUP username: nacos password: nacos ##if use MSE Nacos with auth, mutex with username/password attribute #access-key: "" #secret-key: "" data-id: seataServer.properties将/script/config-center/config.text里面的东西添加到配置中心
按照需求修改配置文件
事务容错
-
service.vgroupMapping.default_tx_group=default值对应的defalut要对应application.yml中的
cluster: defalut事务分组:解决机房异地停电容错
default_tx_group:自定义,例如(XiAn,BaoJi)配置完之后对应客户也要配置
seata.service.vgroup-mapping.projectA=default_tx_group
运行nacos中的
nacos-config.shconfig.txt会自动添加进配置中心端口不一致需要修改启动配置
sh ${SEATAPATH}/script/config-center/nacos/nacos-config.sh -h localhost -p 8848 -g SEATA_GROUP -t 5a3c7d6c-f497-4d68-a71a-2e5e3340b3ca -u username -w password -
2.3.3 Seata-Client搭建
声明式事务实现(
@GlobalTransactional)
2.3.3.1 如果是本地事务方式
Stock模块
bean
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Stock implements Serializable {
private Integer id;
private Integer product_id;
private Integer count;
}
mapper层
@Mapper
public interface StockMapper {
@Update("update seata_stock.stock_tbl set count=count-1 where product_id=#{productId}")
void reduct(Integer productId);
}
service层
@Service
public class StockServiceImpl implements StockService {
@Resource
private StockMapper stockMapper;
@Override
public void reduct(Integer productId) {
System.out.println("更新商品:"+ productId);
stockMapper.reduct(productId);
}
}
controller层
@RestController
@RequestMapping("/stock")
public class StockController {
@Resource
private StockService stockService;
@RequestMapping("/reduct")
public String reduct(Integer productId) {
stockService.reduct(productId);
return "库存扣减成功!!!";
}
}
Order模块
bean
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Order implements Serializable {
private Integer id;
private Integer product_id;
private Integer total_amount;
private Integer status;
}
mapper层
@Mapper
public interface OrderMapper {
@Insert("insert into seata_order.order_tbl values (default,#{product_id},#{total_amount},#{status})")
void add(Order order);
}
service层
@Service
public class OrderServiceImpl implements OrderService {
@Resource
private OrderMapper orderMapper;
@Resource
private RestTemplate restTemplate;
@Override
@Transactional
public Order create(Order order) {
orderMapper.add(order);
//扣减库存能否成功
MultiValueMap<String,Object> paramMap =new LinkedMultiValueMap<>();
paramMap.add("productId",order.getProduct_id());
String msg = restTemplate.postForObject("http://localhost:7101/stock/reduct",paramMap,String.class);
int a =1/0;
return order;
}
}
controller层
@RestController
@RequestMapping("/order")
public class OrderController {
@Resource
private OrderService orderService;
@RequestMapping("/add")
public String add(){
Order order =new Order();
order.setProduct_id(9);
order.setStatus(0);
order.setTotal_amount(100);
orderService.create(order);
return "下单成功";
}
}
- 如果是本地事务,当服务调用者在调用服务提供者后出现异常,调用者未执行成功,但是服务提供者已经执行…
2.3.3.1 采用seata进行分布式事务搭建
① 添加 seata依赖
<dependency>
<groupId>com.alibaba.cloudgroupId>
<artifactId>spring-cloud-starter-alibaba-seataartifactId>
<exclusions>
<exclusion>
<groupId>io.seatagroupId>
<artifactId>seata-spring-boot-starterartifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>io.seatagroupId>
<artifactId>seata-spring-boot-starterartifactId>
dependency>
② 在每个微服务对应数据库建表undo_log、配置参数
https://github.com/seata/seata/tree/1.5.2/script/client/at/db
-- for AT mode you must to init this sql for you business database. the seata server not need it.
CREATE TABLE IF NOT EXISTS `undo_log`
(
`branch_id` BIGINT NOT NULL COMMENT 'branch transaction id',
`xid` VARCHAR(128) NOT NULL COMMENT 'global transaction id',
`context` VARCHAR(128) NOT NULL COMMENT 'undo_log context,such as serialization',
`rollback_info` LONGBLOB NOT NULL COMMENT 'rollback info',
`log_status` INT(11) NOT NULL COMMENT '0:normal status,1:defense status',
`log_created` DATETIME(6) NOT NULL COMMENT 'create datetime',
`log_modified` DATETIME(6) NOT NULL COMMENT 'modify datetime',
UNIQUE KEY `ux_undo_log` (`xid`, `branch_id`)
) ENGINE = InnoDB
AUTO_INCREMENT = 1
DEFAULT CHARSET = utf8mb4 COMMENT ='AT transaction mode undo table';
③ 配置客户端
seata:
tx-service-group: default_tx_group #事务分组
config:
type: nacos
nacos:
server-addr: 192.168.198.129:4399
group: SEATA_GROUP
data-id: seataServer.properties
username: nacos
password: nacos
registry:
type: nacos
nacos:
server-addr: 192.168.198.129:4399
group: SEATA_GROUP
application: seata-server
username: nacos
password: nacos
④ 使用@GlobalTransactional注解
修改 业务事务注解为@GlobalTransactional
@Override
@GlobalTransactional
public Order create(Order order) {
orderMapper.add(order);
//扣减库存能否成功
stockFegin.reduct(order.getProduct_id());
int a = 1 / 0;
return order;
}
2.4 Seata运行原理
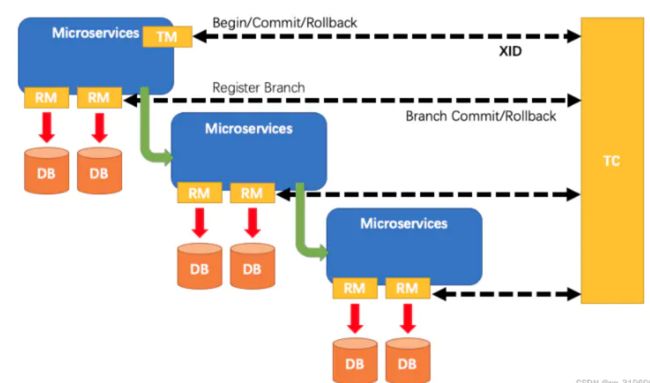
-
TM请求TC开启一个全局事务。TC会生成一个XID作为该全局事务的编号。XID,会在微服务的调用链路中传播,保证将多个微服务的子事务关联在一起.
-
RM请求TC将本地事务注册为全局事务的分支事务,通过全局事务的XID进行关联。
-
TM请求TC告诉XID对应的全局事务是进行提交还是回滚。
-
TC驱动RM们将XID对应的自己的本地事务进行提交还是回滚。
- 学习来自于b站图灵