Python:爬虫乱码
文章目录
- 一、预备知识
-
- 进制
- 位(bit)与字节(Byte)
- 编码/解码
- 二、编解码方式(以文本/字符串编解码为例)
-
- 规则
- 1. ASCII字符集——ASCII编/解码
- 2. GBK字符集——GBK编/解码
- 3. Unicode字符集——UTF-8编/解码(最通用)
- 4. 总结
- 三、Python操作编解码
-
- Python中的bytes与str
- Python演示
- 四、爬虫、保存数据过程
-
- 1.Response --> str
-
- (1)HTTP Response对象
- (2)代码
- (3)乱码案例
- 2. str --> 本地
- 3. 本地 --> str
一、预备知识
进制
- 十进制(0-9):
0, 1, 2, 3, 3, 4, 5, 6, 7, 8, 9,
10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
… - 四进制(0-3):
0, 1, 2, 3,
10, 11, 12, 13,
… - 二进制(0-1):
0, 1,
10, 11,
… - …
n进制就是每一个位置只能表示0~n-1,到了n之后向前进位,通过一系列连续的位置来表示一个数字
e.g. 十进制的4 – 四进制的10 – 二进制的100
我们在使用计算机时,看到和输入的是十进制,但计算机底层(存储、网络传输)是采用二进制来存储数据的
位(bit)与字节(Byte)
- bit:一个0或1
- 上面说的一个位置,就是1bit;
- 计算机中最小的数据单位,1bit代表1个二进制位,0101大小就是4bit。
- Byte:8个连续的0或1
- 计算机中存储、处理数据的基本单位;
- 1bit有1个位置,能表示0或1
2bit有2个位置,能表示2^2即4种状态
…
8bit有8个位置,能表示2^8即128种状态 - 1Byte由8bit组成。各种数据在计算机中存储、处理的单位都是字节,一个数字/符号/文字/图片/视频等,其大小一定是整数倍的Byte
编码/解码
计算机底层只认识0和1,所以计算机存储、网络传输的并不是我们看到的数据的样子,而是一系列的0和1,这一系列的0和1,一般称之为字节流。
1、编码:将数据转化为字节流,进行存储和网络传输;
2、解码:将字节流转化为数据本身,以供阅读/使用/观看。
- 数字:数字的编码是十进制转化为二进制、解码是二进制转化为十进制,也就是进制的转化;
- 字符(汉字、标点、符号、…)/图片/视频:相对复杂,有不同的解码规则与方法
二、编解码方式(以文本/字符串编解码为例)
规则
要求:将某个字符编码为二进制,之后可以将该二进制在转化为该字符
-
字符与二进制要有固定、唯一的对应关系
- 特定的字符只能编码为唯一、确认的二进制字节流
- 这个二进制字节流只能解码为特定的字符
-
需要一个大家认可的字典/规范,规定这种对应关系
-
字符集(记录全部的字符)+ 该字符集对应的编解码方式(字符与二进制的对应关系)
- 一种字符集可能有多种编解码的方式;
或者说,不同的编解码方式,可能采用同一种字符集。
- 一种字符集可能有多种编解码的方式;
1. ASCII字符集——ASCII编/解码
- ASCII字符集:共定义了128个字符。
大写字母26个,小写字母26个,0-9阿拉伯数字(字符),所有的英文标点符号,数学运算符号,其他特殊符号以及控制码 - ASCII编/解码:ASCII字符集中的每个字符与二进制字节流的对应关系。
全部都是用1个字节(Byte)/8bit 标识一个字符,如 'A’被编码为0100 0001
2. GBK字符集——GBK编/解码
-
GBK字符集:在ASCII字符集的基础上,增加了简体汉字、繁体汉字、数学符号、罗马字母、希腊字母等。
-
GBK编/解码:GBK字符集中每个字符与二进制字节流的对应关系。
- ASCII字符集中的字符用1个字节(Byte)/8bit 标识,并且对其ASCII编码,如 0100 0001还是表示’A’;
- 不在ASCII字符集中的字符,都用2个字节(Byte)/16bit来标识,如1101 0000 1110 1100表示’徐’。
3. Unicode字符集——UTF-8编/解码(最通用)
-
Unicode字符集:为了解决传统的字符编码方案的局限性而产生。包含了每种语言的每个字符,以满足跨语言、跨平台进行文版转换、处理的需求,适应全球化的发展。
-
UTF-8编/解码:Unicode字符集中每个字符与二进制字节流的对应关系。(还有很多其他的编码方式也采用了Unicode字符集,如 UTF-32、UTF-16等)。
- ASCII字符集中的字符用1个字节(Byte)/8bit 标识,并且对其ASCII编码,如 0100 0001还是表示’A’;
- 部分字符用2个字节(Byte)/16bit来标识,如1100 1111 1000 1111表示ⱪ;
- 中文字符一般用3个字节(Byte)/24bit来标识,如1110 0101 1011 1110 1001 0000表示’徐’。
4. 总结
- 在所有的编解码方式中,ASCII码字符对应的二进制表示都是一样的。
- 编、解码要相对应,才能不损失数据原本的意义,我们才不会误解数据;
数据以编码方式1进行编码的到字节流,那么这段字节流必须以对应的解码方式1进行解码,才可以得到原始的数据;
否则这段字节流可能会:1、解码成别的数据(按照解码方式2,这一段二进制位对应了别的字符);2、解码失败(按照解码方式2,这一段二进制位可能不对应任何字符)。
三、Python操作编解码
Python中的bytes与str
一个str一定能编码成二进制,因为组成str的字符一定在Unicode字符集中。
-
bytes:字节流/比特流
bytes就是一系列二进制位,也就是说,bytes是0101 0001,但Python中通过十六进制的形式来表示- Python的IDE中展示bytes类型的方式是b’\x~';
- 在此基础上,由于在所有的编解码方式中,ASCII码字符对应的二进制表示都是一样的,所以如果一段字节流中有ASCII字符,则直接将该ASCII字符展示出来;否则还是展示十六进制数字。
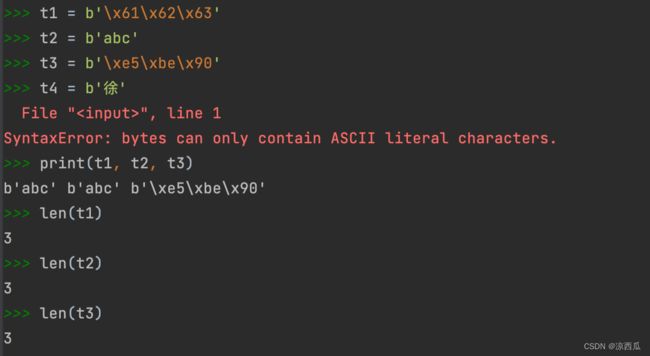
- Python中看到的bytes对象有两个样子:b’ascii字符’;b’\x十六进制数字’。
一段二进制不一定能解码成str。
如果想在Python中直接声明一个bytes对象:
- b’\x十六进制’:b’\x61’
- b’ascii字符’:b’\a’
print一个bytes对象:
-
b’\x十六进制’形式:print(b’\x61’)
- 如果对应ascii字符:则直接转换成b’ascii字符’的形式
- 否则:原样输出
-
b’ascii字符’形式:print(b’\a’)
- 原样输出

Python演示
-
方法
-
编码:
- bytes(str, ‘编码方式’)
- str.encode(‘编码方式’)
-
解码:
- 字节流.decode(‘解码方式’)
-
-
编码
- ASCII编码
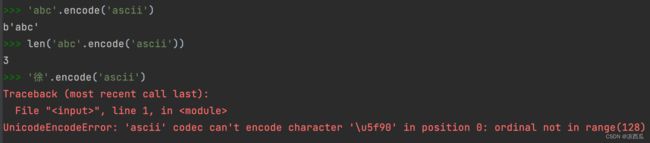
- GBK编码

- UTF-8编码

- ASCII编码
-
编解码练习

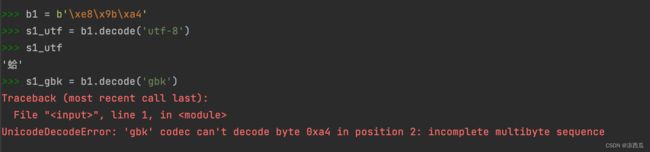
b1三个字节,gbk解码时一个中文占2个字节,这时会认为少了一个字节所以报错。s2六个字节则不会报错。
四、爬虫、保存数据过程
请求网络,拿到Response,Response中包含了二进制字节流/bytes
- 字节流 —> 变成字符串(解码):需要知道相应的编码方式,按照给定的编码方式,解码出字符串
- 字符串 —> 本地txt文档(编码):按照UTF-8编码,保存到本地txt文档
- 本地txt文档 —> 字符串(解码):按照UTF-8解码,读取本地txt文档
用软件打开本地的txt文档,也是以某种编解码方式进行的,一般和系统默认的编解码方式有关:可以抛弃原生txt文本编辑器,选用VSCode或nodepad++
1.Response --> str
(1)HTTP Response对象
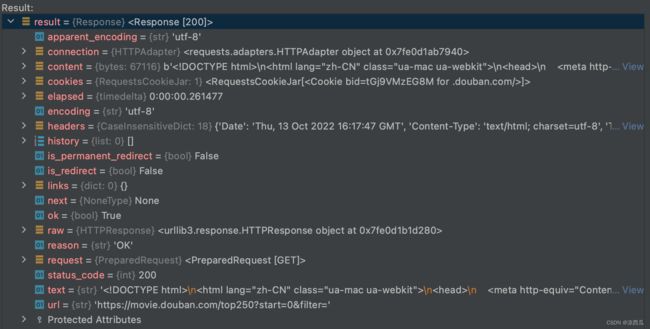
- headers: 响应头
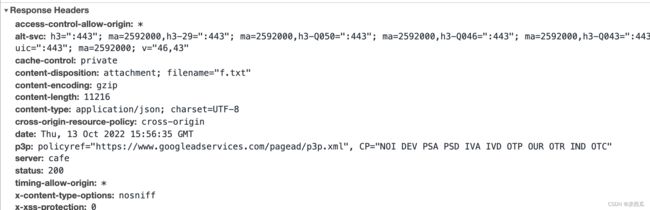
{
‘Date’: ‘Thu, 13 Oct 2022 16:17:47 GMT’,
‘Content-Type’: ‘text/html; charset=utf-8’,
‘Transfer-Encoding’: ‘chunked’,
‘Connection’: ‘keep-alive’,
‘Keep-Alive’: ‘timeout=30’,
‘X-Xss-Protection’: ‘1; mode=block’,
‘X-Douban-Mobileapp’: ‘0’,
‘Expires’: ‘Sun, 1 Jan 2006 01:00:00 GMT’,
‘Pragma’: ‘no-cache’,
‘Cache-Control’: ‘must-revalidate, no-cache, private’,
‘X-DAE-App’: ‘movie’,
‘X-DAE-Instance’: ‘default’,
‘Set-Cookie’: ‘bid=tGj9VMzEG8M; Expires=Fri, 13-Oct-23 16:17:47 GMT; Domain=.douban.com; Path=/’,
‘X-DOUBAN-NEWBID’: ‘tGj9VMzEG8M’,
‘Server’: ‘dae’,
‘Strict-Transport-Security’: ‘max-age=15552000’,
‘X-Content-Type-Options’: ‘nosniff’,
‘Content-Encoding’: ‘gzip’
}
i) ‘Content-Type’: ‘text/html; charset=utf-8’
响应体的媒体类型(类型和编码),确定了接收方以什么类型、什么编码读取响应体。
application/x-www-form-urlencoded
multipart/form-data
application/json
text/xml
ii) ‘Content-Encoding’: ‘gzip’
响应体的压缩方式(不同压缩算法),确定了接收方以什么样的方式解压响应体。
gizp
compress
deflate
identity
- content:响应体
响应主体的二进制内容,即bytes类型。
- encoding: ‘utf-8’
返回用于解码 response.content 的编码方式
response.encoding 是response headers响应头 Content-Type字段 charset 的值。
response.encoding 是从http协议中的response headers响应头中的charset字段中提取的编码方式;若response headers响应头中没有charset字段,则服务器响应的内容默认为ISO-8859-1 编码模式【使用此编码方式无法解析中文内容,会造成响应体乱码(解析为乱码数据)】 - apparent_encoding: ‘utf-8’
自动的从服务器接口响应的内容中(响应体)分析内容编码的方式,所以apparent_encoding 比encoding更加准确。当网页或者接口响应内容出现乱码时可以把 apparent_encoding 的编码格式赋值给encoding。 - text
将response.content进行解码的字符串,解码需要制定一个编码方式,requests会根据自己的猜测来判断编码的方式,所以有时候可能会猜测错误,就会导致解码产生乱码。
(2)代码
-
text = response.text:
将response.content进行解码,requests会根据自己的猜测来判断编码的方式,所以有时候可能会猜测错误,就会导致解码产生乱码。 -
==> text = response.content.decode(response.encoding):
是response headers响应头 Content-Type 字段 charset 的值;
若response header响应头中没有charset字段,则服务器响应的内容默认为 ISO-8859-1 编码模式,使用此编码方式无法解析中文内容,会造成响应体乱码(解析为乱码数据) -
==> text = response.content.decode(apparent_encoding):
自动的从服务器接口响应的内容中(响应体)分析内容编码的方式,所以比 encoding 更加准确
(3)乱码案例
r = requests.get('https://www.baidu.com/')
print(r.text) # 乱码
print(r.content.decode(response.encoding)) # 乱码
print(r.encoding) # ISO-8859-1
print(r.headers('Content-Type')) # 'text/html'
print(r.content.decode(response.apparent_encoding)) # 中文
print(r.apparent_encoding) # utf-8
2. str --> 本地
with open(sourcePath, 'w', encoding='utf-8') as f:
f.write(text)
f.close()
3. 本地 --> str
f = open(sourcePath, encoding='utf-8')
content = f.read()
print(content)
f.close()