CS224n自然语言处理(四)——单词表示及预训练,transformer和BERT
文章目录
- 一、ELMO
-
- 1.TagLM – “Pre-ELMo”
- 2.ELMo: Embeddings from Language Models
- 二、ULMfit
- 三、Transformer
-
- 1.编码器
-
- (1)词向量+位置编码
- (2)多头注意力层
- (3)前馈神经网络层
- 2.解码器
- 四、BERT
-
- 1.BERT的输入
- 2.预训练任务1:Masked LM
- 3.预训练任务2:Next Sentence Prediction
之前介绍的Word Vector方法如Word2Vec, GloVe, fastText等存在两个大问题
- 对于一个 word type 总是是用相同的表示,不考虑这个 word token 出现的上下文,比如 star 这个单词,有天文学上的含义以及娱乐圈中的含义不同,我们可以进行非常细粒度的词义消歧
- 我们对一个词只有一种表示,但是单词有不同的方面,包括语义,句法行为,以及表达 / 含义
一、ELMO
1.TagLM – “Pre-ELMo”
TagLM的思想是想要获得单词在上下文的意思,但标准的 RNN 学习任务只在 task-labeled 的小数据上(如 NER ),可以通过半监督学习的方式在大型无标签数据集上训练 NLM,而不只是词向量。TagLM使用与上文无关的单词嵌入 + RNN model 得到的 hidden states 作为特征输入,如下图所示,

左侧Char CNN / RNN + Token Embedding 作为第一层 bi-LSTM 的输入得到的 hidden states 与右侧 预训练的 bi-LM(冻结的) 的 hidden states 连接起来输入到第二层的 bi-LSTM 中

2.ELMo: Embeddings from Language Models
ELMO的基本思想是使用长上下文而不是上下文窗口学习 word token 向量
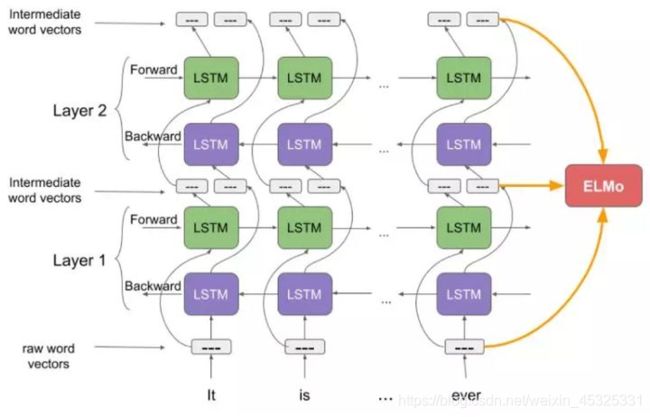
ELMO利用双向的LSTM结构,对于某个语言模型的目标,在大量文本上进行预训练,从LSTM layer中得到contextual embedding,其中较低层的LSTM代表了比较简单的语法信息,而上层的LSTM捕捉的是依赖于上下文的语义信息。对于下游的任务,再将这些不同层的向量线性组合,再做监督学习。
ELMo目标是 performant 但语言模型不要太大
- 使用2个biLSTM层
- (仅)使用字符CNN构建初始单词表示
- 2048 个 char n-gram filters 和 2 个 highway layers,512 维的 projection
- 4096 dim hidden/cell LSTM状态,使用 512 dim的对下一个输入的投影
- 使用残差连接
- 绑定 token 的输入和输出的参数(softmax),并将这些参数绑定到正向和反向LMs之间
- TagLM 中仅仅使用堆叠LSTM的顶层,ELMo 认为BiLSTM所有层都是有用的
对于k位置的标记,ELMO模型用2L+1个向量 R 来表示,其中1个是不依赖于上下文的表示,通常是用之前提及的word embedding或者是基于字符的CNN来得到 x 。L层前向 LSTM和 反向 LSTM每层会分别产生一个依赖于上文/下文的表示 h ,我们可以将他们一起简计。
得到每层的embedding后,对于每个下游的任务,我们可以计算其加权的表示即下图中的 ELMo
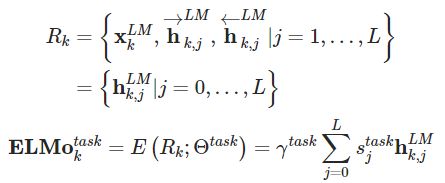
- γ衡量ELMo对任务的总体有用性,是为特定任务学习的全局比例因子
- s是 softmax 归一化的混合模型权重,是 BiLSTM 的加权平均值的权重,对不同的任务是不同的
采用了ELMO预训练产生的contextual embedding之后,在各项下游的NLP任务中,准确率都有显著提高。
二、ULMfit
ULMfit的基本思想:
- 在大型通用领域的无监督语料库上使用 biLM 训练
- 在目标任务数据上调整 LM
- 对特定任务将分类器进行微调
使用大型的预训练语言模型是一种提高性能的非常有效的方法。随着计算的扩大,得到了诸如GPT、BERT等Transformer模型

三、Transformer
参考文章:3W字长文带你轻松入门视觉transformer
Google所提基于transformer的seq2seq整体结构如下所示:
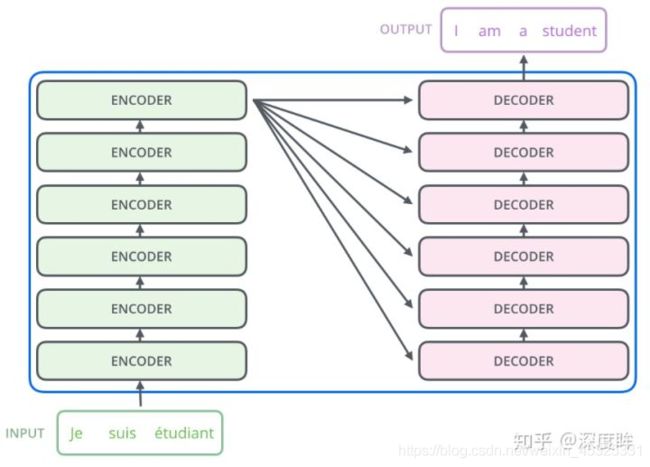
其包括6个结构完全相同的编码器,和6个结构完全相同的解码器,其中每个编码器和解码器设计思想完全相同,只不过由于任务不同而有些许区别,整体详细结构如下所示:

由于基于transformer的翻译任务已经转化为分类任务(目标翻译句子有多长,那么就有多少个分类样本),故在解码器最后会引入fc+softmax层进行概率输出,训练也比较简单,直接采用ce loss即可,对于采用大量数据训练好的预训练模型,下游任务仅仅需要训练fc层即可。下面结合代码和原理进行深入分析。
1.编码器
(1)词向量+位置编码
首先将单词使用词嵌入例如word2vec方法转化成n维向量,之后进行位置编码。
位置编码的意义在于因为transformer内部没有类似RNN的循环结构,没有捕捉顺序序列的能力。为了解决这个问题,在编码词向量时会额外引入了位置编码position encoding向量表示两个单词i和j之间的距离,简单来说就是在词向量中加入了单词的位置信息。
在论文中采用的是sin-cos规则来进行位置编码,具体做法是:

将向量的维度切分为奇数行和偶数行,偶数行采用sin函数编码,奇数行采用cos函数编码,然后按照原始行号拼接
def get_position_angle_vec(position):
# hid_j是0-511,d_hid是512,position表示单词位置0~N-1
return [position / np.power(10000, 2 * (hid_j // 2) / d_hid) for hid_j in range(d_hid)]
# 每个单词位置0~N-1都可以编码得到512长度的向量
sinusoid_table = np.array([get_position_angle_vec(pos_i) for pos_i in range(n_position)])
# 偶数列进行sin
sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2i
# 奇数列进行cos
sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2i+1
在最后将词向量编码和位置编码向量相加,得到多头注意力层输入
(2)多头注意力层
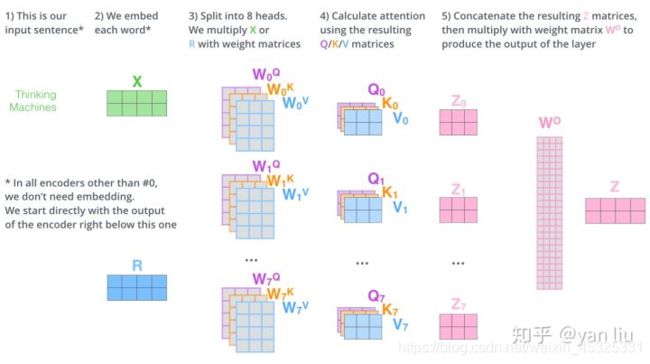
在介绍多头注意力之前首先介绍一下自注意力。首先定义三个可学习矩阵 W (相当于线性层,维度一般为 词向量维度 * 词向量维度),将 X 和三个矩阵相乘得到 Q、K、V三个输出。然后将Q和K进行点乘计算向量相似性并进行归一化;采用softmax转换为概率分布;将概率分布和V进行加权求和即可。可由下图表示:

多头注意力相当于多个自注意力的集成,并在两方面提高了注意力层的性能:
- 它扩展了模型专注于不同位置的能力
- 它给出了注意力层的多个表示子空间
简单来说多头注意力就是类似于分组操作,将输入X分别输入到8个self-attention层中,得到8个Z矩阵输出,之后对结果按列拼成一个大的特征矩阵,特征矩阵经过一层全连接后得到输出。另外,多头注意力加入了残差设计和层归一化操作,目的是为了防止梯度消失,加快收敛。
单头注意力代码:
class ScaledDotProductAttention(nn.Module):
''' Scaled Dot-Product Attention '''
def __init__(self, temperature, attn_dropout=0.1):
super().__init__()
self.temperature = temperature
self.dropout = nn.Dropout(attn_dropout)
def forward(self, q, k, v, mask=None):
# self.temperature是论文中的d_k ** 0.5,防止梯度过大
# QxK/sqrt(dk)
attn = torch.matmul(q / self.temperature, k.transpose(2, 3))
if mask is not None:
# 屏蔽不想要的输出
attn = attn.masked_fill(mask == 0, -1e9)
# softmax+dropout
attn = self.dropout(F.softmax(attn, dim=-1))
# 概率分布xV
output = torch.matmul(attn, v)
return output, attn
多头注意力代码:
class MultiHeadAttention(nn.Module):
''' Multi-Head Attention module '''
# n_head头的个数,默认是8
# d_model编码向量长度,例如本文说的512
# d_k, d_v的值一般会设置为 n_head * d_k=d_model,
# 此时concat后正好和原始输入一样,当然不相同也可以,因为后面有fc层
# 相当于将可学习矩阵分成独立的n_head份
def __init__(self, n_head, d_model, d_k, d_v, dropout=0.1):
super().__init__()
# 假设n_head=8,d_k=64
self.n_head = n_head
self.d_k = d_k
self.d_v = d_v
# d_model输入向量,n_head * d_k输出向量
# 可学习W^Q,W^K,W^V矩阵参数初始化
self.w_qs = nn.Linear(d_model, n_head * d_k, bias=False)
self.w_ks = nn.Linear(d_model, n_head * d_k, bias=False)
self.w_vs = nn.Linear(d_model, n_head * d_v, bias=False)
# 最后的输出维度变换操作
self.fc = nn.Linear(n_head * d_v, d_model, bias=False)
# 单头自注意力
self.attention = ScaledDotProductAttention(temperature=d_k ** 0.5)
self.dropout = nn.Dropout(dropout)
# 层归一化
self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
def forward(self, q, k, v, mask=None):
# 假设qkv输入是(b,100,512),100是训练每个样本最大单词个数
# 一般qkv相等,即自注意力
residual = q
# 将输入x和可学习矩阵相乘,得到(b,100,512)输出
# 其中512的含义其实是8x64,8个head,每个head的可学习矩阵为64维度
# q的输出是(b,100,8,64),kv也是一样
q = self.w_qs(q).view(sz_b, len_q, n_head, d_k)
k = self.w_ks(k).view(sz_b, len_k, n_head, d_k)
v = self.w_vs(v).view(sz_b, len_v, n_head, d_v)
# 变成(b,8,100,64),方便后面计算,也就是8个头单独计算
q, k, v = q.transpose(1, 2), k.transpose(1, 2), v.transpose(1, 2)
if mask is not None:
mask = mask.unsqueeze(1) # For head axis broadcasting.
# 输出q是(b,8,100,64),维持不变,内部计算流程是:
# q*k转置,除以d_k ** 0.5,输出维度是b,8,100,100即单词和单词直接的相似性
# 对最后一个维度进行softmax操作得到b,8,100,100
# 最后乘上V,得到b,8,100,64输出
q, attn = self.attention(q, k, v, mask=mask)
# b,100,8,64-->b,100,512
q = q.transpose(1, 2).contiguous().view(sz_b, len_q, -1)
q = self.dropout(self.fc(q))
# 残差计算
q += residual
# 层归一化,在512维度计算均值和方差,进行层归一化
q = self.layer_norm(q)
return q, attn
(3)前馈神经网络层
class PositionwiseFeedForward(nn.Module):
''' A two-feed-forward-layer module '''
def __init__(self, d_in, d_hid, dropout=0.1):
super().__init__()
# 两个fc层,对最后的512维度进行变换
self.w_1 = nn.Linear(d_in, d_hid) # position-wise
self.w_2 = nn.Linear(d_hid, d_in) # position-wise
self.layer_norm = nn.LayerNorm(d_in, eps=1e-6)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
residual = x
x = self.w_2(F.relu(self.w_1(x)))
x = self.dropout(x)
x += residual
x = self.layer_norm(x)
return x
将多头注意力层和前馈层连起来构建了一个encoder层
class EncoderLayer(nn.Module):
def __init__(self, d_model, d_inner, n_head, d_k, d_v, dropout=0.1):
super(EncoderLayer, self).__init__()
self.slf_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout)
self.pos_ffn = PositionwiseFeedForward(d_model, d_inner, dropout=dropout)
def forward(self, enc_input, slf_attn_mask=None):
# Q K V是同一个,自注意力
# enc_input来自源单词嵌入向量或者前一个编码器输出
enc_output, enc_slf_attn = self.slf_attn(
enc_input, enc_input, enc_input, mask=slf_attn_mask)
enc_output = self.pos_ffn(enc_output)
return enc_output, enc_slf_attn
将多个encoder层堆叠在一起得到了transformer的 encoder
class Encoder(nn.Module):
def __init__(
self, n_src_vocab, d_word_vec, n_layers, n_head, d_k, d_v,
d_model, d_inner, pad_idx, dropout=0.1, n_position=200):
# nlp领域的词嵌入向量生成过程(单词在词表里面的索引idx-->d_word_vec长度的向量)
self.src_word_emb = nn.Embedding(n_src_vocab, d_word_vec, padding_idx=pad_idx)
# 位置编码
self.position_enc = PositionalEncoding(d_word_vec, n_position=n_position)
self.dropout = nn.Dropout(p=dropout)
# n个编码器层
self.layer_stack = nn.ModuleList([
EncoderLayer(d_model, d_inner, n_head, d_k, d_v, dropout=dropout)
for _ in range(n_layers)])
# 层归一化
self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
def forward(self, src_seq, src_mask, return_attns=False):
# 对输入序列进行词嵌入,加上位置编码
enc_output = self.dropout(self.position_enc(self.src_word_emb(src_seq)))
enc_output = self.layer_norm(enc_output)
# 作为编码器层输入
for enc_layer in self.layer_stack:
enc_output, _ = enc_layer(enc_output, slf_attn_mask=src_mask)
return enc_output
2.解码器
解码器和编码器类似,区别在于以下几个地方:
- 解码开始标志位BOS_WORD,解码结束标志位EOS_WORD
- 使用了带有mask的MultiHeadAttention。使用mask的意义是我们不希望在训练解码器时一个单词一个单词按照顺序训练出来,我们希望能够像编码器一样并行的将所有目标单词预测出来,而且我们不能利用到后面单词的嵌入向量信息,所以我们用一个mask构成下三角矩阵,右上角全部设置为负无穷(相当于忽略),从而实现当解码第一个字的时候,第一个字只能与第一个字计算相关性,当解出第二个字的时候,只能计算出第二个字与第一个字和第二个字的相关性。
- 解码器内部的带有mask的MultiHeadAttention的qkv向量输入来自目标单词嵌入或者前一个解码器输出,三者是相同的,但是后面的MultiHeadAttention的qkv向量中的kv来自最后一层编码器的输入,而q来自带有mask的MultiHeadAttention模块的输出。

单个解码块
class DecoderLayer(nn.Module):
''' Compose with three layers '''
def __init__(self, d_model, d_inner, n_head, d_k, d_v, dropout=0.1):
super(DecoderLayer, self).__init__()
self.slf_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout)
self.enc_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout)
self.pos_ffn = PositionwiseFeedForward(d_model, d_inner, dropout=dropout)
def forward(
self, dec_input, enc_output,
slf_attn_mask=None, dec_enc_attn_mask=None):
# 标准的自注意力,QKV=dec_input来自目标单词嵌入或者前一个解码器输出
dec_output, dec_slf_attn = self.slf_attn(
dec_input, dec_input, dec_input, mask=slf_attn_mask)
# KV来自最后一个编码层输出enc_output,Q来自带有mask的self.slf_attn输出
dec_output, dec_enc_attn = self.enc_attn(
dec_output, enc_output, enc_output, mask=dec_enc_attn_mask)
dec_output = self.pos_ffn(dec_output)
return dec_output, dec_slf_attn, dec_enc_attn
多个解码块堆叠
class Decoder(nn.Module):
def __init__(
self, n_trg_vocab, d_word_vec, n_layers, n_head, d_k, d_v,
d_model, d_inner, pad_idx, n_position=200, dropout=0.1):
# 目标单词嵌入
self.trg_word_emb = nn.Embedding(n_trg_vocab, d_word_vec, padding_idx=pad_idx)
# 位置嵌入向量
self.position_enc = PositionalEncoding(d_word_vec, n_position=n_position)
self.dropout = nn.Dropout(p=dropout)
# n个解码器
self.layer_stack = nn.ModuleList([
DecoderLayer(d_model, d_inner, n_head, d_k, d_v, dropout=dropout)
for _ in range(n_layers)])
# 层归一化
self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
def forward(self, trg_seq, trg_mask, enc_output, src_mask, return_attns=False):
# 目标单词嵌入+位置编码
dec_output = self.dropout(self.position_enc(self.trg_word_emb(trg_seq)))
dec_output = self.layer_norm(dec_output)
# 遍历每个解码器
for dec_layer in self.layer_stack:
# 需要输入3个信息:目标单词嵌入+位置编码、最后一个编码器输出enc_output
# 和dec_enc_attn_mask,解码时候不能看到未来单词信息
dec_output, dec_slf_attn, dec_enc_attn = dec_layer(
dec_output, enc_output, slf_attn_mask=trg_mask, dec_enc_attn_mask=src_mask)
return dec_output
四、BERT
BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder。模型的主要创新点都在pre-train方法上,即用了Masked LM和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。

BERT其和GPT一样均是采用的transformer的结构,相对于GPT来说,其是双向结构的,而GPT是单向的
对比ELMo,虽然都是“双向”,但ELMO将上下文当作特征,无监督的语料和我们真实的语料还是有区别的,不一定的符合我们特定的任务,是一种双向的特征提取。
1.BERT的输入
BERT的输入可以是单一的一个句子或者是句子对,实际输入的Embedding由三种Embedding求和而成:

- Token Embeddings是词向量,第一个单词是CLS标志,可以用于之后的分类任务
- Segment Embeddings用来区别两种句子,因为预训练不光做LM还要做以两个句子为输入的分类任务
- Position Embeddings和之前文章中的Transformer不一样,不是三角函数而是学习出来的
- 每个句子开头为 CLS 符号,结尾 SEP 符号,两个句子的情况用 SEP 做分隔
2.预训练任务1:Masked LM
第一步预训练的目标就是做语言模型,如果使用预训练模型处理其他任务,那人们想要的肯定不止某个词左边的信息,而是左右两边的信息。而考虑到这点的模型ELMo只是将left-to-right和right-to-left分别训练拼接起来。因此BERT采用了深度双向模型
为了训练一个深度双向表示(deep bidirectional representation),研究团队采用了一种简单的方法,即随机屏蔽(masking)部分输入token,然后只预测那些被屏蔽的token。最终的损失函数只计算被mask掉那个token。
训练数据生成器随机选择15%的token,然后执行以下过程:
- 80%的时间:用[MASK]标记替换单词,例如,my dog is hairy → my dog is [MASK]
- 10%的时间:用一个随机的单词替换该单词,例如,my dog is hairy → my dog is apple
- 10%的时间:保持单词不变,例如,my dog is hairy → my dog is hairy.
因为序列长度太大(512)会影响训练速度,所以90%的steps都用seq_len=128训练,余下的10%步数训练512长度的输入。
3.预训练任务2:Next Sentence Prediction
因为涉及到QA和NLI之类的任务,增加了第二个预训练任务,目的是让模型理解两个句子之间的联系。选择一些句子对A与B,其中50%的数据B是A的下一条句子,剩余50%的数据B是语料库中随机选择的,输入这两个句子,模型预测B是不是A的下一句。预训练的时候可以达到97-98%的准确度。