【论文精读】InstructIE: A Chinese Instruction-based Information Extraction Dataset
InstructIE: A Chinese Instruction-based Information Extraction Dataset
- 前言
- Abstract
- 1. Introduction
- 2. Task Definition: Instruction-based IE
- 3. Dataset Construction for InstructIE
-
- 3.1 Data Source
- 3.2 Data Preparation
- 3.3 Dataset Construction
-
-
- Identifying all entity mentions
- Disambiguating
- Matching
- Schema-Constraint
- Crowdsourcing Annotation
-
- 3.4 Dataset Statistics
- 4. Experiments
-
- 4.1 Baselines
- 4.2 Evaluation Setting
- 4.3 Experiment Results
- 4.4 Experiment Analysis
- 5. Related Work
- 6. Conclusion and Future Work
- 阅读总结
前言
一篇关于信息抽取的中文数据集构建的文章,旨在构建指令微调数据集对大语言模型进行微调,以达到对输入文本更为准确抽取其中信息的目的,阅读总结部分有我对这篇工作更为细致的看法~
Abstract
本文引入了一个名为Instruction-based IE的信息抽取任务,旨在要求LLM遵循特定的说明或指南来提取信息。此外构建了名为InstructIE的数据集,该数据集由来自中文维基百科的270000个弱监督数据和1000个高质量的众包注释实例组成。实验部分,InstructIE和其他模型进行了对比,还有一定的提升空间。最后总结了基于指令的IE任务现有的挑战。
1. Introduction
信息抽取作为信息获取的关键技术,在知识图谱构建、问答系统等各个领域具有广泛的应用和前景。IE旨在从非结构化数据提取结构化信息,根据目标的不同可以将抽取任务分为命名实体识别、关系抽取、事件抽取。
之前对于不同的IE任务需要设计不同架构的模型,费时费力。Seq2Seq架构缓解了这些挑战,UIE提出了一个统一的文本到文本的架构,能够对不同的IE任务进行通用建模。

然而如上图(a)所示,这些架构只能够处理预定义模式中固定数量的类型,泛化能力很差。理想情况下,希望模型能够理解自然语言编写的指令生成预期的输出。最近LLM使用自然语言指令来指导LLM解决下游任务,极大提高了模型的泛化能力。
因此,本文提出了新的IE任务Instruction-based IE。它要求模型理解用户的指令,根据指令从输入文本中提取关系三元组,并以指定格式输出。为此本文首先构建一个基于指令的IE数据集InstructIE,它包含来自中文维基百科的270000个弱监督数据和1000个高质量的众包注释数据。作者将多个baseline模型在这1000个高质量数据上进行实验,结果表明模型还有进一步的提升空间。
本文的贡献如下:
- 提出一个更现实的IE任务,基于指令IE,改进了传统的IE设置。
- 构造指令IE任务的数据集InstructIE。
2. Task Definition: Instruction-based IE
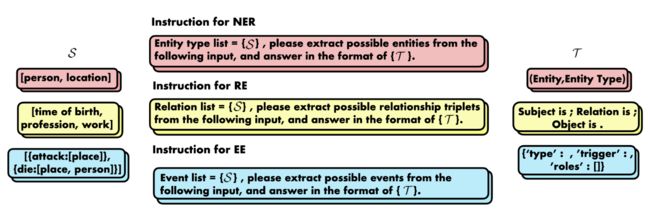
基于指令的信息抽取格式如上图所示。抽取指令表示为 I \mathcal{I} I,它嵌入了抽取要求 S \mathcal{S} S和指定的输出格式 T \mathcal{T} T。 T = f o r m a t ( h , r , t ) \mathcal{T}=format(h,r,t) T=format(h,r,t)可以指引模型的输出。
3. Dataset Construction for InstructIE
3.1 Data Source
数据主要来源维基数据和中国维基百科。
- 中国维基百科:最初从维基百科中爬取带有中文标题的文章。将文档分成段落,选择长度在50-300之间的段落,从而产生180万个段落。
- 维基数据:该工作中使用到的知识图谱是维基数据的子集,包含具有中文标签或者别名的所有实体,以及他们的关系。
3.2 Data Preparation
作者发现为每个段落分配一个特定的主题可以显著简化标注过程。为了提高效率,作者使用5000个标记数据训练主题分类器,便于为每个段落分配主题。作者定义了12个主题,并为每个主题设计了相应的模板。

上表是主题分类结果,旨在通过尽可能涵盖所有领域来最大限度覆盖实际抽取需求。
3.3 Dataset Construction
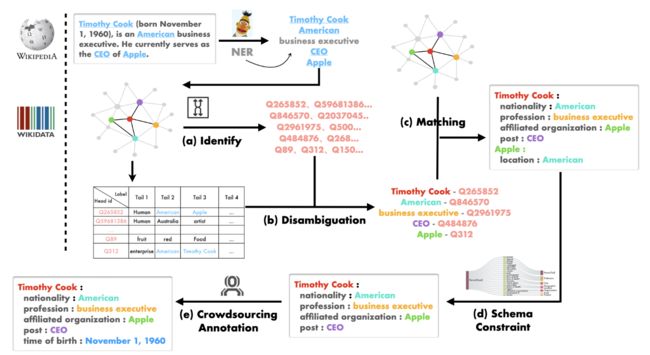
InstructIE中关系三元组的完整标注过程如上图所示,可以分为五步,下面对每步进行详细说明。
Identifying all entity mentions
利用维基百科文章中的链接构建实体集,但是很多链接只在第一次出现时标注,导致很多实体未被标注,为了解决这个问题,作者使用Chinese NER模型识别剩余的实体。
Disambiguating
接着根据中文标签获取实体mention的唯一ID。但是维基数据中相同的标签可能对应不同的实体,比如苹果可以指代水果或者苹果公司。因此设计了一个消歧算法如下所示,它根据实体集中相应尾部实体标签的出现频率计算每个ID的分数。选择得分最高的ID作为该实体mention的唯一维基数据ID。

此外,通过查询其“instance of”属性为每个实体分配实体类型,有助于后序的Schema-Constraint。通过统计分析,将所有实体抽象为18类,如下图所示:
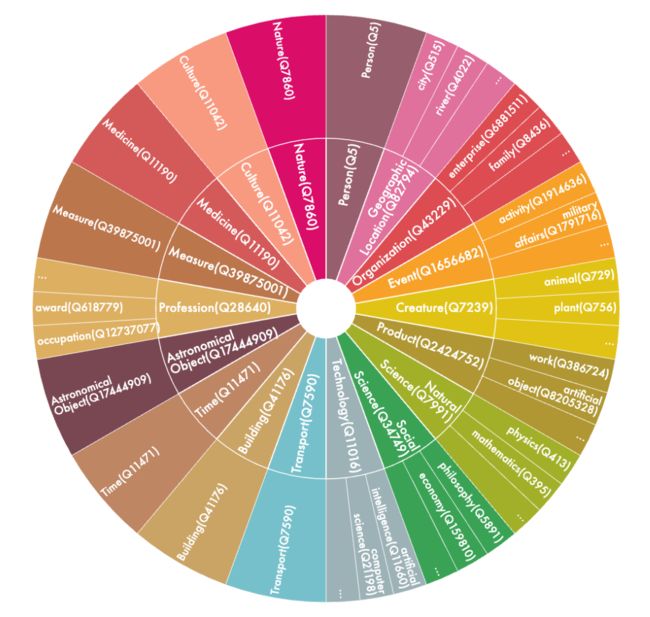
其中内圈表示粗粒度实体类型,外圈表示细粒度实体类型。
Matching
实体消歧后,将实体集中的每一对实体与它们在知识图谱中对应关系进行匹配,但是这会带来与任务不相关的匹配,因此提出Schema-Constraint来限制可以匹配的关系。
Schema-Constraint
作者为12个主题中的每一个定义了模式,模式中每个条目都限制了关系的头实体和尾实体类型。只有头实体和尾实体类型满足约束才会被添加。

上图显示“组织”主题的模式,此外,作者还通过关键字匹配过滤掉与政治、暴力、色情相关的实例。
Crowdsourcing Annotation
通过上述步骤,作者仔细选择了1000个实例,并通过两轮标注对其进行手动注释。标注过程也是基于模式的,出现在模式之外的任何关系都不被标注出来。
3.4 Dataset Statistics
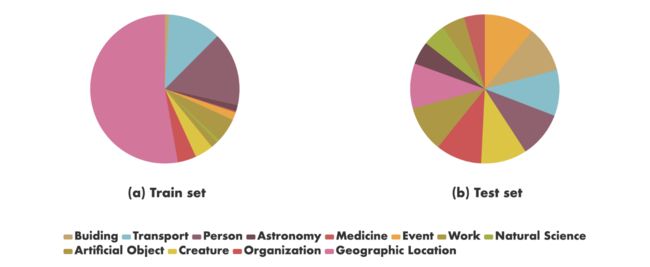
270000条弱监督数据用于微调,此外1000个标注实例作为基线测试集。上图展示了文本主题在数据集中的分布。可以看到测试集主题分布相对均衡,而训练集的分布则发生显著的变化,“地理位置”的实例的占比甚至超过了主题的一半,这种差异归因于中文维基百科主题分布的不均匀。
4. Experiments
为了评估InstructIE的挑战,作者使用上下文学习、LoRA和微调等技术对不同大小的语言模型进行了广泛的实验。
4.1 Baselines
作者将InstructIE与如下模型进行对比评估:
- MT5
- ChatGPT
- LLaMA
- AIpaca
- CaMA
4.2 Evaluation Setting
作者利用EasyInstruct在ChatGPT上执行上下文学习。由于token长度限制,demonstration的数量限定为5个。对于每个主题,作者提供500个示例。对于LoRA,作者使用来自AIpaca-LoRA的框架,所有参数为默认值。
对于基于span的Micro-F1评估指标,模型只有对头实体、尾实体和关系类型全部正确预测,得到的关系三元组才是正确的。但是细微的差异仍然可以认为正确的,因此作者结合了ROUGE-2得分,该得分是将输出拆为两部分进行评估匹配的。最终的加权得分计算如下,其中 λ \lambda λ设置为0.5。
Score = λ × F 1 + ( 1 − λ ) × ROUGE − 2 \text { Score }=\lambda \times \mathrm{F} 1+(1-\lambda) \times \text { ROUGE }-2 Score =λ×F1+(1−λ)× ROUGE −2
4.3 Experiment Results
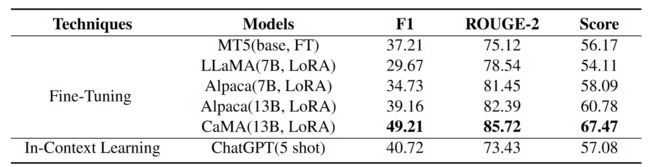
上表展示了实验结果,微调CaMA表现出做好的结果,这归因于CaMA在大规模中文语料库中训练。此外,同样是7B模型,AIpaca的表现要优于LLaMA,这是因为AIpaca在包含52K指令的数据集上微调,从而增强了理解遵守指令的能力。此外7B的AIpaca和13B的AIpaca对比说明增大模型规模可以进一步提升性能。
此外LoRA只是对小部分参数进行调整,和full fine-tuning相比显得不是那么有效。
4.4 Experiment Analysis
模型预测出错主要出现在如下类型中:
- Error Head:头实体不匹配;
- Error Relation:关系不匹配;
- Error Tail:尾实体不匹配;
- Redundancy:预测结果重复出现;
- Undefined Relation:预测的关系类型并不在候选集中;
- Other:多个部分不匹配。
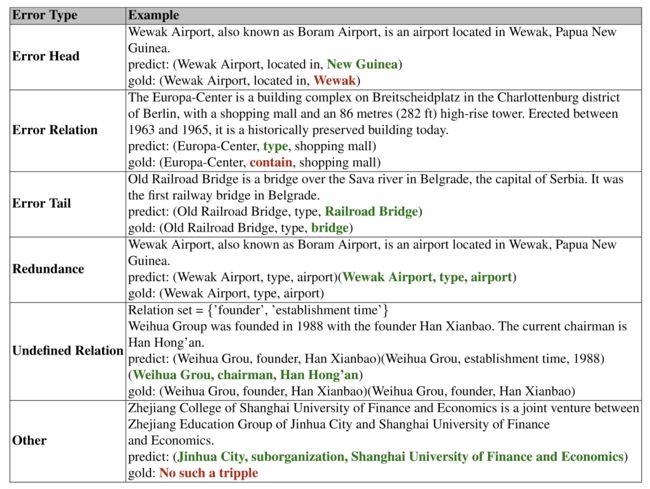

上面两张表分别是各个错误类型的示例,以及这些错误预测在不同模型中的预测结果占比。所有模型在错误关系和未定义关系上出错少,在实体识别上错误较多,这可能归因于模型在识别实体边界上有局限性。此外“Other”错误类型也有一定比例,说明模型倾向生成不相关信息。
这些模型中,CaMA表现最好,尤其在“Other”上,说明其对无关信息有一定有效的控制。
5. Related Work
LLM的进步极大推动了自然语言理解和生成领域的发展,此外,越来越多工作集中在指令微调范式上,利用LLM对指令的理解能力完成特定的任务。这样的方法消除了特定于任务的架构或训练范式的需求。
6. Conclusion and Future Work
本文介绍了IE,一个旨在要求大模型理解自然语言指令从输入文本中抽取关系三元组来增强传统IE的新任务。本文构建了InstructIE数据集,并在该数据集上评估各种基线的性能,展示了指令微调的潜力。未来改进的方向专注于构建更多高质量的测试数据,以及开发英文版本的InstructIE数据集。
阅读总结
虽然文章标题是中文信息抽取的数据集,但是本文主要介绍的还是一种信息抽取的指令微调范式,详细介绍了数据的构建过程,并且基于这个数据,测试了多个大模型的微调性能,可惜只和ChatGPT进行了对比,并且间接炫耀了一番了先前的指令微调的工作CaMA。数据集的构造过程还是有点启发意义的,等于是从零开始构建,对维基百科进行切割,然后调用模型进行实体识别,根据维基KG结构化信息来实现实体之间关系的匹配,之后还有进一步的消歧和约束。
但是这篇工作并不是完全的通用抽取任务,通篇看下来更像是只有关系抽取(本身关系抽取就带有命名实体识别),而使用大模型只处理关系抽取的任务,显然有些杀鸡用牛刀,或者说,大模型做通用抽取更能发挥其优势,此外相比于复旦的IE INSTRUCTIONS数据集,本文的数据集显然不够全面,虽然前者是英文数据集,并且是全网搜集后处理的数据集,而不是本文从头开始构建的数据集,但是它拥有32个三种抽取任务的数据,并且标注上显然比本文这种弱监督方式要更为准确。所以,如果想要做中文领域的通用抽取大模型,可以考虑利用已有的中文NER、EE、RE数据集,辅以重新构建的数据集,去微调一个中文微调的模型,比如CaMA,Belle等,相信会有不错的效果。