全网最全seaborn的介绍
可视化统计关系
relplot
seaborn.relplot(x=None, y=None, hue=None, size=None, style=None,
data=None, row=None, col=None, col_wrap=None, row_order=None,
col_order=None, palette=None, hue_order=None, hue_norm=None,
sizes=None, size_order=None, size_norm=None, markers=None, dashes=None,
style_order=None, legend='brief', kind='scatter', height=5, aspect=1,
facet_kws=None, **kwargs)
relplot(关系图)可以看做是lineplot和scatterplot的归约,可以通过kind参数来指定画什么图形,重要参数解释如下:
kind:默认scatter(散点图),也可以选择kind=‘line’(线图);
sizes:List、dict或tuple,可选,简单点就是图片大小,注意和size区分;
col、row:将决定网格的面数的分类变量,具体看实例
散点图
绘制散点图,只需要将kind设置“scatter"
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style="darkgrid")
tips = sns.load_dataset("tips")
sns.relplot(x="total_bill", y="tip",kind="scatter", data=tips)
效果图如下

虽然这些点是以二维绘制的,但可以通过根据第三个变量对点进行着色来将另一个维度添加到绘图中。在 seaborn 中,这被称为使用“色调语义”,因为该点的颜色获得了意义
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style="darkgrid")
tips = sns.load_dataset("tips")
sns.relplot(x="total_bill", y="tip", hue="smoker",kind="scatter", data=tips)
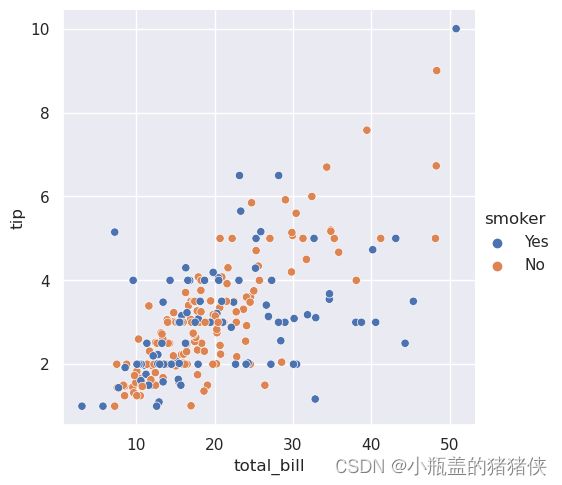
为了强调类别之间的差异并提高可访问性,可以为每个类别使用不同的标记样式
sns.relplot(x="total_bill", y="tip", hue="smoker", style="smoker",
data=tips)

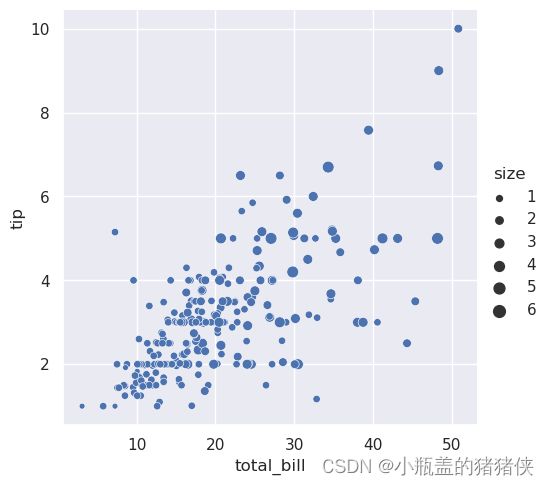
第三个语义变量改变每个点的大小
sns.relplot(x="total_bill", y="tip", size="size", data=tips)
线型图
散点图是非常有效的,但是没有通用的最优可视化类型。相反,可视表示应该适应数据集的细节以及您试图用图表回答的问题。
对于某些数据集,您可能希望了解一个变量中的变化关于时间的函数,或者类似的连续变量。在这种情况下,一个很好的选择是绘制线图。在 seaborn 中,这可以通过lineplot()函数直接实现,也可以通过设置relplot()的参数kind="line"来实现:
df = pd.DataFrame(dict(time=np.arange(500),
value=np.random.randn(500).cumsum()))
g = sns.relplot(x="time", y="value", kind="line", data=df)

更复杂的数据集将对x变量的相同值有多个观测值。seaborn 的默认行为是通过绘制平均值及 95%的置信区间,在每个x周围聚合多个测量值
fmri = sns.load_dataset("fmri")
sns.relplot(x="timepoint", y="signal", kind="line", data=fmri)

可视化分类数据
在绘制关系图的教程中,我们学习了如何使用不同的可视化方法来展示数据集中多个变量之间的关系。在示例中,我们专注于两个数值变量之间的主要关系。如果其中一个主要变量是“可分类的”(能被分为不同的组),那么我们可以使用更专业的可视化方法。
在 seaborn 中,有几种不同的方法可以对分类数据进行可视化。类似于relplot()与scatterplot()或者lineplot()之间的关系,有两种方法可以制作这些图。有许多 axes-level 函数可以用不同的方式绘制分类数据,还有一个 figure-level 接口catplot(),可以对它们进行统一的高级访问
分类散点图
在catplot()中,数据默认使用散点图表示。在 seaborn 中有两种不同的分类散点图,它们采用不同的方法来表示分类数据。 其中一种是属于一个类别的所有点,将沿着与分类变量对应的轴落在相同位置。stripplot()方法是catplot()中 kind 的默认参数,它是用少量随机“抖动”调整分类轴上的点的位置
tips = sns.load_dataset("tips")
sns.catplot(x="day", y="total_bill", data=tips)

类别内观察点的分布
随着数据集的大小增加,分类散点图中每个类别可以提供的值分布信息受到限制。当发生这种情况时,有几种方法可以总结分布信息,以便于我们可以跨分类级别进行简单比较
箱线图
第一个是熟悉的boxplot()。它可以显示分布的三个四分位数值以及极值。“胡须”延伸到位于下四分位数和上四分位数的 1.5 IQR 内的点,超出此范围的观察值会独立显示。这意味着箱线图中的每个值对应于数据中的实际观察值
sns.catplot(x="day", y="total_bill", kind="box", data=tips)

添加hue语义, 语义变量的每个级别的框沿着分类轴移动,因此它们将不会重叠
sns.catplot(x="day", y="total_bill", hue="smoker", kind="box", data=tips)

小提琴图
另一种方法是violinplot(),它将箱线图与分布教程中描述的核密度估算程序结合起来:
sns.catplot(x="day", y="total_bill", kind="violin", data=tips)

当 hue 参数只有两个级别时,也可以“拆分”violins,这样可以更有效地利用空间
sns.catplot(x="day", y="total_bill", hue="sex",
kind="violin", split=True, data=tips);

sns.catplot(x="day", y="total_bill", hue="sex",
kind="violin", data=tips);

我们也可以将swarmplot()或striplot()与箱形图或 violin plot 结合起来,展示每次观察以及分布摘要
可视化数据集的分布
绘制单变量分布
在 seaborn 中想要快速查看单变量分布的最方便的方法是使用distplot()函数。默认情况下,该方法将会绘制直方图histogram并拟合[内核密度估计] kernel density estimate (KDE).
x = np.random.normal(size=100)
sns.distplot(x)

直方图
对于直方图我们可能很熟悉,而且 matplotlib 中已经存在hist函数。 直方图首先确定数据区间,然后观察数据落入这些区间中的数量来绘制柱形图以此来表征数据的分布情况。
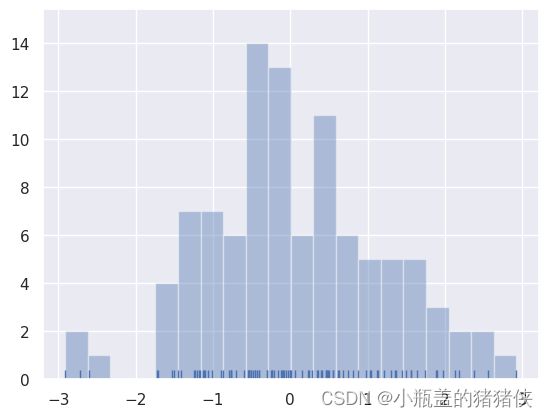
为了说明这一点,让我们删除密度曲线并添加一个 rug plot,它在每个观察值上画一个小的垂直刻度。您可以使用rugplot() 函数来创建 rugplot 本身,但是也可以在 distplot()中使用
sns.distplot(x, kde=False, rug=True)

在绘制柱状图时,您的主要选择是要使用的“桶”的数量和放置它们的位置。 distplot() 使用一个简单的规则来很好地猜测默认情况下正确的数字是多少,但是尝试更多或更少的“桶”可能会揭示数据中的其他特性
sns.distplot(x, bins=20, kde=False, rug=True)
核密度估计
可能你对核密度估计不太熟悉,但它可以是绘制分布形状的有力工具。和直方图一样,KDE 图沿另一个轴的高度,编码一个轴上的观测密度:
sns.distplot(x, hist=False, rug=True)

果在 seaborn 中使用kdeplot() 函数, 我们可以得到相同的曲线。这个函数也被distplot()所使用, 但是当您只想要密度估计时,它提供了一个更直接的接口,可以更容易地访问其他选项:
sns.kdeplot(x, fill=True)

绘制二元分布
它对于可视化两个变量的二元分布也很有用。在 seaborn 中,最简单的方法就是使用jointplot()函数,它创建了一个多面板图形,显示了两个变量之间的二元(或联合)关系,以及每个变量在单独轴上的一元(或边际)分布
散点图
可视化二元分布最常见的方法是散点图,其中每个观察点都以 x 和 y 值表示。 这类似于二维 rug plot。 您可以使用 matplotlib 的plt.scatter 函数绘制散点图, 它也是 jointplot()函数显示的默认类型的
mean, cov = [0, 1], [(1, .5), (.5, 1)]
data = np.random.multivariate_normal(mean, cov, 200)
df = pd.DataFrame(data, columns=["x", "y"])
sns.jointplot(x="x", y="y", data=df);

可视化数据集中的成对关系
要在数据集中绘制多个成对的双变量分布,您可以使用pairplot()函数。 这将创建一个轴矩阵并显示 DataFrame 中每对列的关系,默认情况下,它还绘制对角轴上每个变量的单变量分布
iris = sns.load_dataset("iris")
sns.pairplot(iris);
