论文笔记:A multi-source dataset of urban life in the city of Milan and the Province of Trentino
- Scientific data 2015
0 摘要
- 描述了两个地理区域上发布的丰富的多源数据集。
- 该数据集由米兰市和特伦蒂诺省的电信、天气、新闻、社交网络和电力数据组成。
1 背景
- 通话详单记录 Call Detail Record CDR
- 提取移动模式
- 提取社交互动
- 估算人口密度
- 建模城市结构
- 预测社会经济指标
- 模拟疾病的传播
- 。。。
- 新兴的地理定位信息和通信技术(ICT)服务(如Twitter和Foursquare)的出现为研究人员提供了进一步的机会,以定量地检查人类行为的不同方面
- 不幸的是,通信和社交媒体数据的可用性通常仅限于少数与电信和其他私营公司签署保密协议(NDA)和研究合同的研究团队。
- 缺乏开源数据集限制了潜在的研究数量,并在科学界所需的验证和可重复性过程中引发问题。
- ——>意大利电信公司在2014年的“电信意大利大数据挑战”中提供了米兰市和特伦蒂诺省的数据
- 来自米兰市和特伦托省的电信、天气、新闻、社交网络和电力数据的丰富的开放式多源聚合
- ——>能够对给定地理区域的多个维度进行建模,并解决各种问题和科学问题
- 来自米兰市和特伦托省的电信、天气、新闻、社交网络和电力数据的丰富的开放式多源聚合
论文详细描述了数据记录的结构,并介绍了数据收集/聚合过程中使用的方法

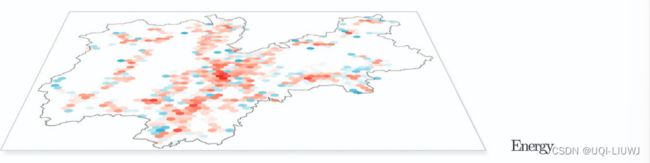
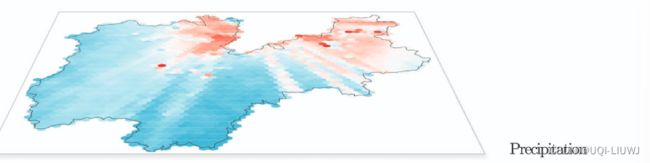
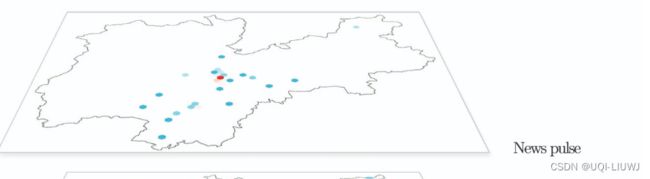
- 特伦蒂诺省的六边形网格地图,使用对数颜色比例尺。每个图层代表特定的数据集。
- 在能源图层中,红色表示消耗的电力总和
- 在降水图层中,颜色从蓝色(最小的平均降水强度)到红色(最大的降水强度)变化
- 在其他图层中,蓝色表示最小事件数量(例如连接、推文、新闻),红色表示最大事件数量。

- 新闻脉动地图是根据新闻数据集生成的,该数据集仅适用于特伦托地区
- 社交脉动地图显示了特伦蒂诺最大城市中推文的高浓度。

2 城市网格化
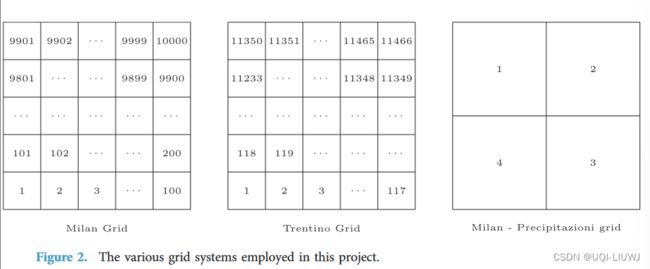
- 由于数据集来自采用不同标准的各个公司,它们的空间分布不规则性被聚集在一个具有方形单元格的网格中。
- 这样可以比较不同区域的数据,并便于地理数据管理。
- ——>米兰地区由1,000个大小约为235×235米的方形单元格的网格覆盖组成,特伦蒂诺地区由6,575个方形单元格的网格覆盖组成。
- 这个网格是使用WGS84(EPSG:4326)标准投影的。
3 CDR数据
3.1 数据介绍
- 每当用户进行电信互动时,运营商会分配一个无线基站(RBS radio base station)并通过网络进行通信。
- 然后,会创建一个新的CDR记录该交互的时间和处理该交互的RBS。
- 通过RBS,可以获取用户的地理位置指示,这得益于覆盖地图Cmap,它将每个RBS与其所服务的领土部分(也称为覆盖区域)相关联(下图)
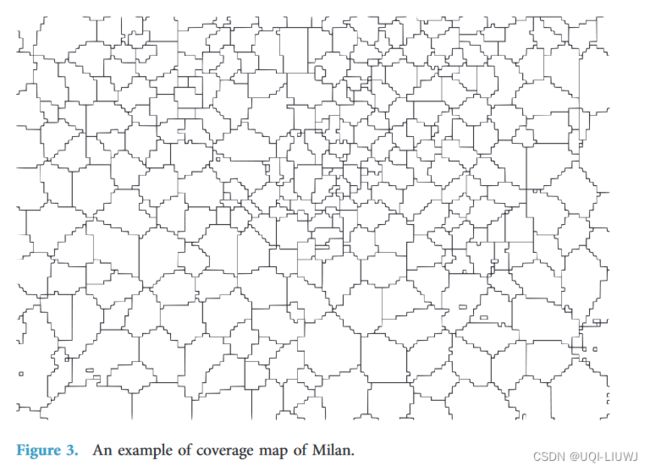
3.2 RBS覆盖区域和网格的映射
- 为了在网格内进行空间聚合,将每个交互与处理它的RBS的覆盖区域v相关联。
- 因此,在时间t时,网格方格i中的记录数量si(t)计算如下:
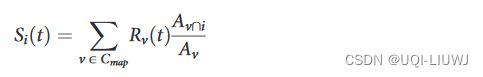
-
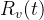 ——t时刻在区域v内的记录数量
——t时刻在区域v内的记录数量 - Av——区域v的面积
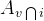 ——区域v和网格i重叠的面积
——区域v和网格i重叠的面积
-
- 【换句话说就是一个RBS服务范围内的record数量认为是均匀分布的】
3.3 许多类型的CDR数据
- 有许多类型的CDR数据,而Telecom Italia记录了以下活动:
- 收到短信:每当用户收到一条短信时生成一条CDR记录。
- 发送短信:每当用户发送一条短信时生成一条CDR记录。
- 呼入电话:每当用户接听电话时生成一条CDR记录。
- 呼出电话:每当用户发起一通电话时生成一条CDR记录。
- 上网:每当用户开始或结束一次上网连接时生成一条CDR记录。在同一连接中,如果连接持续时间超过15分钟或用户传输超过5MB的数据量,将生成一条CDR记录。
- 这些共享的数据集是通过将所有这些匿名信息进行组合创建的,并且时间上按照10分钟的时间段进行了聚合。数据集中的记录数量
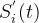 遵循以下规则:
遵循以下规则:
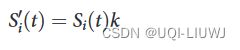
- 其中,k是Telecom Italia定义的常数,用于隐藏真实的呼叫、短信和连接数量。
4 数据集中的不同数据
4.1 电信活动数据集
- 第一类数据集代表了特伦蒂诺和米兰地区的活动,显示了这些地区发生的所有前述电信事件。
- 数据提供了Telecom Italia客户与网络进行交互的信息,以及在漫游时使用网络的其他人的信息。
4.2 电信互动
- 另外两种类型的CDR数据集,以衡量不同地点之间的互动强度:
- 一种是从特定地区(特伦蒂诺/米兰)到意大利各省的互动数据集
- 另一种是衡量城市/省内的互动数据(例如,米兰到米兰)。由于Telecom Italia只拥有其自己客户的数据,计算得出的互动仅发生在他们之间。这意味着(最多)只收集了人口数据的34%,这是由于Telecom Italia的市场份额。此外,关于未接来电的信息也没有提供。
4.3 社交脉搏数据集
- 2013年11月1日至2013年12月31日来自特伦蒂诺和米兰的用户发布的地理位置标记的推文组成
- 该数据集是通过Twitter Streaming API收集的,存了作者的用户名、推文内容和推文编写的时间戳
4.4 天气站数据
- 描述了米兰和特伦蒂诺的气象现象类型和强度。
- 米兰:
- 不同位置的传感器不断测量气象现象的类型和强度。
- 每个传感器都有唯一的ID、类型和位置。不同的传感器可以共享相同的位置。
- 数据分为两个数据集,分别称为Legend数据集和Weather Phenomena数据集。
- 前者提供了传感器的位置和测量单位
- 后者包含了每个传感器的测量文件
- 传感器可以测量不同的气象现象:风向、风速、温度、相对湿度、降水、全球辐射、大气压力和净辐射。
- 数据没有进行空间聚合,以60分钟的时间段进行聚合。
- 特伦蒂诺:
- 包含了36个天气站在特伦蒂诺省周围采集的温度、降水和风速/风向的测量数据。
- 数据没有进行空间聚合,以15分钟的时间段进行聚合。
- 米兰:
4.5 降水数据
- 降水数据集提供了有关地理区域降水强度和类型的信息。
- 米兰:
- 该数据集每10分钟进行时间聚合,并在四个相等大小的象限(11.75×11.75公里)内进行空间聚合,对应于用于聚合的网格的50个方格。象限用ID 1、2、3和4进行标识,相应的网格方格ID由公式y × 100 + x计算,其中x和y遵循以下规则:
- 象限1:x:[1,50],y:[50,99];
- 象限2:x:[51,100],y:[50,99];
- 象限3:x:[51,100],y:[0,49];
- 象限4:x:[1,50],y:[0,49]。

- 降水类型描述如下:
- 不存在:降水量等于0 mm/h,类型为0
- 轻微:降水量在[0,2] mm/h之间,类型为1
- 中等:降水量在[2,10] mm/h之间,类型为2
- 强降:降水量在[10,100] mm/h之间,类型为3。
- 而降水强度被分为不存在(类型:0)、雨(类型:1)和雪(类型:2)。
- 该数据集每10分钟进行时间聚合,并在四个相等大小的象限(11.75×11.75公里)内进行空间聚合,对应于用于聚合的网格的50个方格。象限用ID 1、2、3和4进行标识,相应的网格方格ID由公式y × 100 + x计算,其中x和y遵循以下规则:
- 特伦蒂诺:
- 特伦蒂诺的降水强度值在特伦蒂诺网格上进行空间聚合,并在每10分钟进行时间聚合
- 其标准描述如下
- 非常微弱:降水强度定义为[1,3],意味着[0.20,2.0] mm/hr的降水量;
- 微弱:降水强度定义为[4,6],意味着[2.0,7.0] mm/hr的降水量;
- 中等:降水强度定义为[7,9],意味着[7.0,16.0] mm/hr的降水量;
- 强降:降水强度定义为[10,12],意味着[16.0,30.0] mm/hr的降水量;
- 非常强降:降水强度定义为[13,15],意味着[30.0,70.0] mm/hr的降水量;
- 极端:降水强度定义为[16,18],意味着超过70 mm/hr的降水量;
4.6 用电数据
- SET电力公司几乎控制了特伦蒂诺领土上的整个电力网络。它使用大约180条主要配电线路(中压线路)将能源从国家电网输送到特伦蒂诺的用户。
- 为了确保SET客户的隐私,他们的位置和180条主要配电线路的几何形状没有明确公开。
- 因此,客户站点数据集显示了每个网格方格中每条电力线路的客户站点数量,而线路测量数据集则指示了时间t内通过线路流动的能量量。
- 客户站点为不同类型的客户(例如住宅、公寓楼、商业活动、工业等)提供能源,这些客户需要不同数量的电力。
- 出于隐私原因,这些信息被隐藏,意味着在数据集中流动的能量在各种类型的客户之间均匀分布。
- 客户站点为不同类型的客户(例如住宅、公寓楼、商业活动、工业等)提供能源,这些客户需要不同数量的电力。
- 图4显示了论文将原始数据集转换为共享数据集的过程。
- 在第一层中,我们拥有每个客户站点的精确位置(例如,其中一些是工业用途,其他是小房屋)和每条电力线路的精确几何形状。
- 在第二层中,我们失去了客户站点和电力线路的精确几何形状。然而,这些信息在客户站点数据集中得到总结,其中记录了每个网格方格中客户站点的数量以及它们连接的电力线路的信息。
- 在第三层中,我们知道一个电力线路的客户站点是如何分布在网格上的,并知道通过每条电力线路流动的能量(来自线路测量数据集)。然后,可以将通过电力线路p流动的能量在网格上分布,以便构建每个网格方格中的能量消耗分级地图(图4中的最后一层)。
- 线路测量数据集在10分钟的时间间隔中进行时间聚合。

4.7 新闻数据集
- 包含在http://www.milanotoday.it和http://www.trentotoday.it网站上发布的所有文章。
- 每篇新闻都与事件发生的地理位置相关联。
- 所有与整个米兰市或整个特伦蒂诺省相关的新闻都被地理标记为其行政中心。
5 数据集位置
- 数据集在哈佛Dataverse上公开提供。
- 在数据集生成过程中使用了不同类型的软件和工具,如果分享和解释使用的所有源代码将会过于复杂。因此,我们分享了代码的简化版本,以更好地理解方法部分中解释的一部分过程。该软件是用Python 2.7编写的,可以在https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/UTLAHU处找到。
- converter.py将原始CDR转换为先前解释的网格叠加。输出写入与脚本所在目录相同的位置。
6 数据具体介绍
6.1 网格
- 一些数据集使用在领土上叠加的规则网格进行空间聚合。
- Grid数据集提供了构成网格的每个方格的地理参考,参考系统为:WGS 84—EPSG:4326。
| 米兰网格 | https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/QJWLFU |
| 特伦蒂诺 | https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/FZRVSX |
| square id | 米兰或特伦蒂诺GRID中给定方格的标识字符串 |
| Time Interval | 以geoJSON表示的单元格几何形状,并投影到WGS84(EPSG:4326) |
6.2 通信
发布了三个不同的数据集,一个用于电信活动,两个用于电信互动。
6.2.1 电信活动
| 米兰 | https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/EGZHFV |
| 特伦蒂诺 | https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/QLCABU |
| Square id | 表示米兰/特伦蒂诺GRID的特定方格的识别字符串 |
| Time Interval | 以毫秒表示的起始间隔时间 |
| SMS in activity | 在给定的方格ID和时间间隔内接收到的短信活动的比例 |
| SMS out activity | 在给定的方格ID和时间间隔内发送的短信活动的比例 |
| Call-in activity | 在给定的方格ID和时间间隔内接收到的电话活动的比例 |
| Call-out activity | 在给定的方格ID和时间间隔内发出的电话活动的比例 |
| Internet traffic activity | 在给定的方格ID和时间间隔内生成的CDR数 |
| Country code | 电话国家代码 |
6.2.2 特伦蒂诺/米兰发出
| 米兰发出 | https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/F3RBMF |
| 特伦蒂诺发出 | https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/MAW5AR |
- 包含了米兰/特伦蒂诺网格和其他意大利省份之间的互动数据。每对小数表示互动的程度。
- 后面的数字与从米兰/特伦蒂诺方格到该省份生成的呼叫数量成比例,而前面的数字与从该省份到米兰/特伦蒂诺方格生成的呼叫数量成比例。
| Square id | 表示米兰/特伦蒂诺GRID的特定方格的识别字符串 |
| Time Interval | 以毫秒表示的起始间隔时间 |
| Square to Province Inter | 方格ID和该省份之间的互动程度的值 位于方格ID中的主叫方和位于该省份中的接收方之间的呼叫数量成比例 |
| Province to Square Inter | 表示方格ID和该省份之间的互动程度的值。 它与位于该省份中的主叫方和位于方格ID中的接收方之间的呼叫数量成比例 |
| Province | 意大利省份的名称 |
6.2.3 特伦蒂诺/米兰到特伦蒂诺/米兰
| 米兰到米兰 | https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/JZMTBJ |
| 特伦蒂诺到特伦蒂诺 | https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/KCRS61 |
这个数据集提供了米兰和特伦蒂诺省不同区域之间的方向互动强度。具体字段如下:
| Square id1 | 表示互动起始点的米兰/特伦蒂诺GRID方格的识别字符串 |
| Square id2 | 表示互动目的地的米兰或特伦蒂诺GRID方格的识别字符串 |
| Time Interval | 以毫秒表示的起始间隔时间 |
| Directional Inter. Strength | 表示Square id1和Square id2之间的方向互动强度的值。它与位于Square id1中的主叫方和位于Square id2中的接收方之间的呼叫数量成比例 |
6.3 社会脉搏数据集
| 米兰 | https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/9IZALB |
| 特伦蒂诺 | https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/5H0NUI |
包含了2013年11月1日至2014年1月1日间来自米兰和特伦蒂诺的地理定位推文。
| user | 匿名化的Twitter用户名 |
| entities | 使用dataTXT从推文文本中提取的DBPedia实体 |
| language | 推文的语言,其中und表示未定义 |
| municipality | 推文创建所在的市镇。该近似值与geometry字段相同 municipality字段由市镇名称和Dandelion acheneID组成,该ID在Administrative Regions数据集中指定。用户可以使用acheneID作为主键在Administrative Regions中获取有关市镇的更多数据(例如边界、人口) |
| created | 推文时间,使用ISO格式YYYY-MM-DDTHH: mm: SS,欧洲/罗马时区 |
| timestamp | 推文的时间戳 |
| geometry | 推文的大致位置,以geoJSON格式表示。误差范围为±600米 |
6.4 气象站数据集
| 米兰 | https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/9Z6CKW |
| 特伦蒂诺 | https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/UPODNL |
- 米兰的数据分为两个数据集,分别称为图例数据集和天气现象数据集
- 图例数据集
-
Sensor ID 传感器的标识字符串 Sensor street name: 传感器ID标识的传感器所在的街道名称 Sensor lat: 传感器ID标识的传感器的地理纬度 Sensor long 传感器ID标识的传感器的地理经度 Sensor type 传感器ID标识的传感器的类型 UOM 由传感器ID标识的传感器记录的值的测量单位
-
-
天气现象数据集
-
Sensor ID 传感器的标识字符串 Time instant 以YYYY/MM/DD HH24 : MI格式表示的测量时间点 Measurement 传感器ID在时间点上测量的气象现象强度值。
给定传感器记录的值的测量单位在图例数据集中指定
-
- 图例数据集
- 特伦蒂诺
-
station 气象站的ID geometry 以WGS84(EPSG:4326)投影的气象站的几何图形(GeoJSON格式) elevation 气象站的海拔高度(以米为单位) date 日期,格式为YYYY-MM-dd timestamp Unix时间戳格式的日期 minTemperature 一天的最低温度(摄氏度) maxTemperature 一天的最高温度(摄氏度) temperatures 稳度测量的映射,其中键表示以HHmm表示的时间点,值表示该时间点的温度(摄氏度) precipitation 如果任何降水测量值大于0,则为true precipitations 降水测量的映射,其中键表示以HHmm表示的时间点,值表示该时间间隔内的降水量(毫米) minWind 一天的最小风速(米/秒) maxWind 一天的最大风速(米/秒) winds 风速测量的映射,其中键表示以HHmm表示的时间点,值表示速度@方向的字符串。速度以米/秒为单位
-
6.5 降水数据集
| 特伦蒂诺 | https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/0RZVTA |
| 米兰 | https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/S2UGMD |
| Timestamp | 时间戳值,格式为YYYYMMDDHHmm |
| Square id | 米兰/特伦蒂诺GRID中给定方格的ID |
| Intensity | 降水强度值。它是0到3之间的值 |
| Coverage | 降水覆盖的象限百分比值 |
| Type: | 降水类型。它是0到2之间的值 |
6.6 SET 电力数据集
| 特伦蒂诺 | https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/AMKZXM |
- SET电力数据集仅适用于特伦蒂诺省,包含有关能源消耗和电力在该地区供应方式的信息。它由两个数据子集组成。
- 客户站点数据集。该数据集提供特伦蒂诺省主要配电线路的描述。
-
Square id 特伦蒂诺GRID中给定方格的标识字符串 Line id 分配给特伦蒂诺GRID方格的配电线路的标识字符串 Number of customer sites 连接到网格配电线路(Line id)的特伦蒂诺GRID方格中的客户站点数
-
- 线路测量数据集。该数据集提供特定实例下通过线路的总电流。
-
Line id 配电线路的标识字符串 Timestamp 与测量通过配电线路的电流的时刻相关的时间戳。日期格式为YYYY-MM-DD HH24 : MI Value 给定时间戳下通过特定电力线路(Line id)的安培值。如果电流的方向是从国家电网流向本地线路,则该值为正;否则为负
-
6.7 新闻数据集

| 特伦蒂诺 | https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/NYQ23N |
| 米兰 | https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/QWOE1R |
新闻数据集中包含了《米兰今日报》(Milano Today)和《特伦托今日报》(Trento Today)在2013年11月1日至2013年12月31日期间发布的所有文章 。
| title | 文章的标题 |
| link | 指向原始文章的链接 |
| model | 原始文章的模型 |
| topic | 文章的主题 |
| date | 发布日期,按照ISO 8601格式进行格式化 |
| timestamp | 根据发布日期生成的Unix时间戳 |
| municipality.acheneID | 用于查询行政区域数据集的Dandelion acheneID |
| municipality.name | 市政单位的名称 |
| address | 文章描述的事件的街道地址 |
| location | 文章描述的事件的位置 |
| geometry | 事件的坐标。并非始终可用。以geojson点表示,并在WGS84(EPSG:4326)投影下 |
6.8 行政区划数据
https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/KNMIVZ
- 提供了有关米兰和特伦托省当前行政区域的信息
- 该数据集帮助用户提供有关前述数据集涉及的区域的一些信息。
| acheneID | Dandelion的唯一标识字符串 |
| level | 该行政区域的级别,可以是- 50: 省 - 60: 市镇 - 70: 地点 |
| name | 行政区域的名称 |
| parentAchenes | 一个复合对象,存储当前实体所属的所有行政区域的achene ID |
| euroCode | 官方的Eurostat代码 |
| localCode | 基于行政区域所属国家的官方政府代码(意大利为ISTAT) |
| cadastralCode | 官方的地籍代码(如有) |
| postCodes | 该地区的邮政编码列表 |
| elevation | 海拔平均值(以米为单位) |
| population | 行政区域的人口数据 |
| isProvinceCheflieu | (仅适用于level = 50)该省是否是省会城市 |
| isMountainMunicipality | (仅适用于level = 60)该行政区域是否为山区。NM表示非山区,P表示部分山区,M表示山区 |
| website | (仅适用于level = 60)行政区域的网站 |
| wikipedia | 一个数据结构,包含该行政区域的维基百科页面链接 |
| alternateNames | 一个替代名称列表,有时在提及该行政区域时使用 |
| geometry | 行政区域的几何图形,以与geoJSON兼容的格式表示,并在WGS84(EPSG:4326)投影下 |
| geomComplex | 复合对象,存储关于几何图形的一些元数据 |
| geomComplex.provenance | 指示几何图形是从地理编码还是直接来自可信源的。可能的值为 0: 几何图形直接来自原始源,未经SpazioDati或任何人编辑 1: 几何图形是由SpazioDati从其他字段(如地点/市镇)推断得出的 2: 几何图形是从地址进行了地理编码得出的 |
| provenance | 字符串列表,表示信息的原始来源 |
| geomComplex.accuracy | 几何图形的质量。可能的值为 - 80: 街道(例如Via del Brennero) - 90: 地址(例如Via del Brennero, 52) - 100: 点(例如11.124032,46.076791 |
7 技术验证
7.1 时间因素


- 通常,人们在一天中会进行不同的活动。其中许多活动每天都会重复进行(例如,中午吃饭、晚上慢跑等),而其他活动则是每周一次(例如,在体育场观看喜爱的足球队比赛)。
- 从图5和图6可以观察到强烈的每日季节性,周内季节性也是可观察到的,尤其是周日和周一之间的比较。
7.2 空间因素
- 比较了一些预计具有明显不同行为特征的位置。
- 选择了以下区域:
- ● 博科尼(Bocconi),米兰最著名的大学之一(方格ID:4259);
- ● Navigli区,米兰最著名的夜生活场所之一(方格ID:4456);
- ● 杜奥莫(Duomo),米兰市中心(方格ID:5060);
- ● 杜奥莫(Duomo),特伦托市中心(方格ID:5200);
- ● Mesiano,特伦托大学工程学院(方格ID:5085);
- ● Bosco della città,特伦托附近的森林(方格ID:4703)

如手机使用情况图表所示(参见图7),所选区域显示出非常不同的行为模式。如预期,Navigli区在晚上的互联网连接增加,而Bocconi区在周末的连接减少。此外,相比于米兰市中心和最重要的旅游景点杜奥莫,Bocconi区的手机活动较少。
8 使用注意事项
- 为了对grid的地理位置有初步了解,建议将其导入到免费软件QGIS中,并添加OpenStreetMap图层。
- 鼓励使用免费的Python环境,并配备Pandas和scikit-learn包,与数据集进行交互和分析。对于可视化数据和地理区域内事件的分布也很有用。
- 因此,论文在http://dx.doi.org/10.7910/DVN/UTLAHU中提供了一些有用的示例来显示这些信息。
- plot.py显示了米兰的短信、通话、推文和互联网CDR的时间序列(参见图5)以及图6中显示的箱线图。
- plot_maps.py显示了图4中SET图层的专题地图。
- 因此,论文在http://dx.doi.org/10.7910/DVN/UTLAHU中提供了一些有用的示例来显示这些信息。