Python使用requests库爬取中国新闻网新闻实例
Python引入requests库
这里以Pycharm为开发工具(用VSCode开发也没有什么区别,主要注意引入requests库和lxml解析库),点击左上角File,选择New Project新建项目
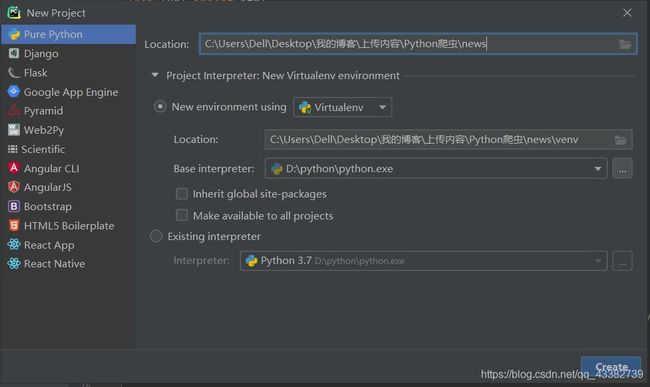
如上图选择项目路径和Python解释器,点击Create创建项目
引入requests库
在terminal终端输入:pip install requests,安装requests库,lxml库同理
pip install requests

分析网页代码
这里对首页右侧的所有实时新闻进行分析
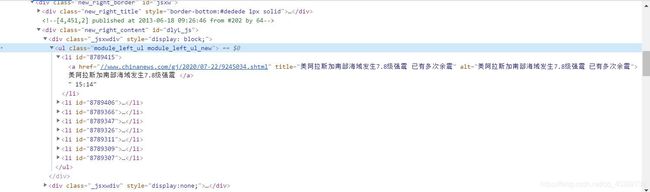
可以看出其中的每条新闻都在一个li标签里
使用xpath对html标签进行分析,语法如下:

实现代码
import requests
from lxml import html
def get_in_time_news():
# 采用get方法获取响应
resp = requests.get('http://www.chinanews.com/')
# 为防止获取的网页乱码,对响应内容进行重新编码,编码格式可能是utf-8或gbk
html_content = resp.content.decode('utf-8', 'replace')
# 用lxml模块中的html的etree将响应内容转换为可以分析的标签
news_html_time = html.etree.HTML(html_content)
# 用xpath获取所有的li标签
lis = news_html_time.xpath('//div[@class="new_right_border"]//div['
'@class="new_right_content"]//div//ul//li')
# 定义存储实时新闻的列表
time_news_list = []
# 遍历li获取新闻的标题内容、链接和时间
for li in lis:
time_news_list.append(
{'text': li.xpath('a/@title')[0], 'href': 'http:' + li.xpath('a/@href')[0],
'time': li.xpath('text()')[0]})
return time_news_list
代码分析如下:
- //div[@id=“guide-step”]会获取所有后代结点总id为guide-step的div标签,class类似,理解上述代码中获取lis的部分可以参照新闻网首页控制台中的html标签
- li.xpath(‘a/@title’)[0]会获取新闻标题,后面获取的为新闻链接,然后为新闻发布时间
实现结果

总结
主要工作内容还是需要学会用xpath对结点进行解析,后续会发布具体爬取某篇新闻的文章,可以持续关注哦–_--。