【论文解读】MMNet: Memory Matching Networks for One-Shot Image Recognition(记忆匹配网络,小样本)
1. 介绍
论文地址:Memory Matching Networks for One-Shot Image Recognition, CVPR 2018.
或者 Matching networks for one shot learning.NIPS2016.
参考代码:https://github.com/gitabcworld/MatchingNetworks
针对问题:小样本学习、对未标记图像进行one-shot学习
形式化来说,few-shot 的训练集中包含了很多的类别,每个类别中有多个样本。在训练阶段,会在训练集中随机抽取 N 个类别,每个类别 K 个样本(总共 N * K个数据,作为模型的支撑集support set)输入;再从这N个类中剩余的数据中抽取一批(batch)样本作为模型的预测对象(batch set 或 query set)。即要求模型从 N*K 个数据中学会如何区分这 N个类别,这样的任务被称为 N-way K-shot 问题。其中K值一般较小,当K=1时,即变成了One-shot。
少样本学习的主要方向:数据扩充、迁移学习、深度嵌入学习和元学习。数据增强方法是通过数据制造扩大训练数据的最自然的少样本学习解决方案。迁移学习方法旨在将从以前的任务中学到的知识循环用于few-shot学习。利用了从小样本模型到底层大样本模型的泛型类别不可知变换进行一次性学习。深度嵌入学习试图创建一个低维的嵌入空间,在这个空间中,变换后的表示更具辨别力,利用暹罗网络学习图像的深度嵌入空间,并采用最近邻规则对图像进行分类。这篇文章开发了匹配网络,通过匹配机制将支持集和测试样本转换为一个共享的嵌入空间。元学习模型主要从两个层次来描述学习问题:快速学习以获取每个任务中的知识,逐步学习以提取所有任务中所学的知识。
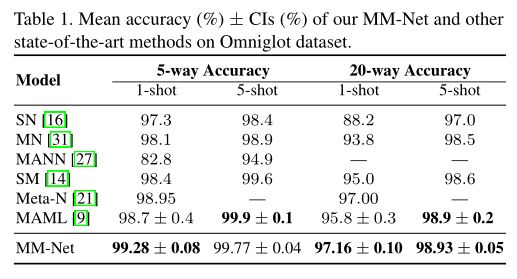
文章引入记忆学习增强卷积神经网络(CNNs)的新思想,对未标记图像进行one-shot学习。具体来说,提出了记忆匹配网络(MM-Net)-一种新的深层架构,探索了训练过程,遵循训练和测试条件必须匹配的理念。从技术上讲,MM-Net将一组标记图像(支持集)的特征写入内存,并在执行推理时从内存中读取,以全面利用集合中的知识。同时,上下文学习以顺序的方式使用记忆槽来预测未标记图像的CNNs参数。整个体系结构通过一次只显示每个类的几个示例,并将学习从minibatch切换到另一个minibatch来进行训练,当在测试时显示几个新类别的示例时,这是为one-shot学习而定制的。与传统的one-shot学习方法不同,我们的MM网络可以输出一个统一的模型,而不考虑shot的数量和类别。在两个公共数据集,即Omniglot和minimagenet上进行了大量的实验,与最先进的方法相比,得到了了更好的结果。在Omniglot上提高了one-shot的准确率,从98.95%提高到99.28%,在minimagenet上从49.21%提高到53.37%。
文章贡献:
-
提出一种新小样本学习算法框架:记忆匹配网络(MM-Net);
-
将一组标记图像(支持集)的特征写入内存,并在执行推理时从内存中读取,以全面利用集合中的知识;
-
上下文学习以顺序的方式使用记忆槽来预测未标记图像的CNNs参数;
-
与传统的one-shot学习方法不同,我们的MM网络可以输出一个统一的模型,而不考虑shot的数量和类别;
-
还提出了如何修正one-shot 学习中训练和推理之间的差异,训练过程中,每次训练(episode)都会采样得到不同 Support和Batch,所以总体来看,训练时的训练集包含了不同的类别组合,通过这种机制学习,使得模型学会了从不同类别样本中的提取共性部分,所以在面对新类别样本时,该模型也能较好地进行分类。
2. 方法
2.1 记忆匹配网络
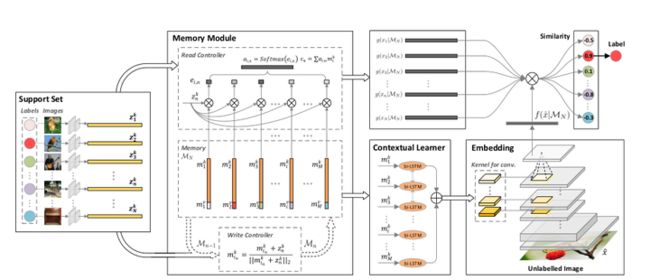
记忆匹配网络(MMNet)的基本思想是构造一个嵌入空间,在这个嵌入空间中,可以从几个标记的图像(支持集)中快速识别出不可见的物体。MM-Net首先利用内存模块对整个支持集进行编码和泛化,并将支持集泛化到内存槽中,内存槽被赋予在类别上指定的上下文信息。然后,通过读取控制器将整个支持集与所有类别的内存进行上下文嵌入,实现MM-Net的训练。同时,根据类别间的上下文关系,设计了一个上下文学习者来预测CNNs的参数以嵌入未标记图像。通过嵌入空间中的匹配机制,进一步利用支持集和未标记图像的嵌入来检索未标记图像的标签。我们的MM-Netis是以一种从学习到学习的方式进行训练的,并且可以灵活地适应于识别任何新的对象,只需前馈支持集。MM -Net的概述如上图所示。
给定一个支持集,每个类别由一个或几个标记的例子组成,利用深层CNNs学习丰富的图像表示,然后由一个内存模块通过写控制器将输入支持集压缩和概括到内存中的插槽中。存储器模块中的读取控制器通过在所有类别中整体地利用存储器来进一步增强图像在支持集中的表示(嵌入)学习。同时,采用上下文学习者bilstm,通过对记忆槽进行顺序编码,探索类别间的上下文关系,预测CNNs的参数,其输出被视为未标记图像的嵌入。将给定的未标记图像嵌入到支持集中的每幅图像之间的点积计算为相似度,并将最近的一幅图像的标签赋给该未标记图像。我们的MM网的训练与推理完全吻合。此外,内存是一种统一的介质,它可以将不同大小的支持集转换为公共内存槽,从而可以灵活地训练一个统一的模型,并采用混合策略对任何一次性学习场景进行推理。
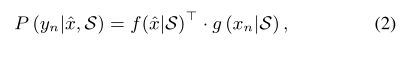
其中f(·)和g(·)分别是未标记图像ˆx和支持图像xn在整个支持集S上的两个深度嵌入函数。请注意,从记忆网络的思想出发,我们利用一个内存模块将整个支持集显式地概括到内存槽中,这些内存槽被赋予支持集之间的上下文信息,并且可以进一步集成到f(·)和g(·)的学习中。
2.2 带内存模块的编码支持集
内存:由key和value组成,key是嵌入上下文向量,value是标签;
![]()
写控制器:
在给定支持集S的情况下,利用内存模块将N个支持图像序列通过写控制器编码到M个内存插槽中,提取类的内在特征。因此,我们将写控制器中的内存更新策略设计为一个动态特征聚合问题,以利用每个类在单个样本之外固有的通用特性和每个类内部显著的多样性。 这种设计的核心问题是写控制器是否应该通过顺序地更新相应的存储器键来联合地将视觉上相似的支持样本聚合到一个存储器插槽中,或者单独地寻找一个新的存储器插槽来存储不同的样本。当输入支持样本与视觉上相似的内存键共享相同的类标签/内存值时触发前一个类标签/内存值,否则采用后一个类标签/内存值。
下面给出了写控制器内存更新策略的向量公式。 在第n个时间步,通过写控制器将当前输入支持集向量xn及其类标签yn写入内存插槽以更新先前的内存Mn−1,产生存储器Mn。T是一个映射矩阵。
![]()
接下来,对于输入支持图像,我们从先前的内存Mn-1中挖掘其最近的邻居(即视觉上最相似的内存键)关于其在存储密钥空间zn中的表示与每个存储key之间的点积相似性。 然后根据xn的最近邻居mn的内存值是否与xn的类标签yn完全匹配,以不同的方式进行内存更新:如果相等,只更新对应的mk,并将其规格化:

不等的话,直接存到一个新的内存槽中。如果没有新的插槽,则按上式更新。
2.3 对支持集背景嵌入
将图像从支持集转换到嵌入空间的最典型方法是在区分学习中通过共享的深度嵌入结构g(xn)独立地嵌入每个样本,而支持集中的整体上下文信息没有得到充分利用。本文提出了一个支持集g(xn | MN)的上下文嵌入函数,通过内存模块的读控制器将xn条件嵌入到内存MN上,直觉地认为,内存中所有类别的完整上下文信息都能引导g产生更具区别性的xn表示。
读控制器:
首先计算输入支持向量与存储Mk之间的点乘相似度,然后聚合关于Mk的上下文信息:
![]()
因此,输入的支持集向量最终表示为:

2.4 对查询集的背景嵌入
标准深嵌入函数f(ˆx;W) 在判别学习中,通常由矩阵W参数化的卷积层堆栈组成。参数W的优化往往需要大量的训练数据和漫长的迭代过程才能很好地推广到未知样本上。然而,在每个类只有一个标记实例的极端情况下,对深度嵌入体系结构的训练是不够的,直接微调这种体系结构往往会导致对新类别的识别性能较差。
为了解决上述one-shot学习的挑战,文章设计了一种新的上下文嵌入架构f(ˆx;W | MN)算法将从记忆MN中挖掘出的类别间的上下文关系融入到深度嵌入函数中,实现了对未标记图像的深度嵌入。特别地,该上下文嵌入体系结构的参数W是以前馈方式学习的,其条件是基于存储器mn而不是反向传播,从而避免了为了适应新类别而进行微调的需要。
上下文学习器:
![]()
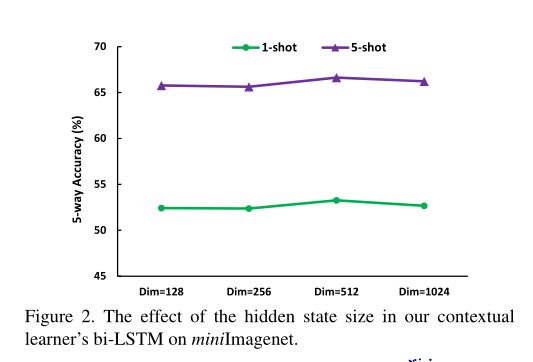
其中w是一个双向LSTM组成的上下文学习器,其编码表示为双向LSTM的最后 hidden states的求和表示。其最后的输出W表示为:
![]()
通过与我们的上下文学习器合成上下文嵌入的参数,类别之间的上下文关系被优雅地整合到这个深度嵌入结构f(ˆx;W | MN),这鼓励了变换后的表示在图像识别中更具鉴别能力。
分解架构:
设计未标记图像上下文嵌入的具体结构时,采用因式分解设计对传统卷积层进行了改进,显著减少了卷积滤波器中的参数数目,使上下文学习器的参数预测更加可行。
2.5 训练过程
在获得未标记图像和整个支持集的嵌入表示之后,我们按照先前的工作来训练我们的模型,用于广泛采用的单镜头学习任务:C-way k-shot图像识别任务,即,将一组不相交的未标记图像分类为一组C个不可见类,每个类只有k个标记图像。具体地说,对于训练阶段的每一批,我们首先从所有训练类别中均匀抽取C个类别,每个类别抽取k个样本,形成标记支持集S。从训练集中属于C类的剩余数据中随机抽取对应的未标记图像集B。因此,给定支持集S和输入未标记图像集B,然后将softmax损失公式化为:
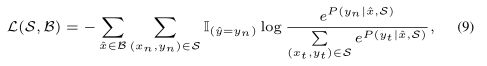
通过最小化训练批上的softmax损失,我们的MM网被训练成在支持集S的条件下识别B中所有图像的正确类标签。因此,在测试阶段,假设支持集包含训练过程中从未见过的C类,我们的模型可以通过匹配机制快速预测未标记图像的类标签,由于其非参数特性,不需要对新类别进行任何微调。
混合训练策略:
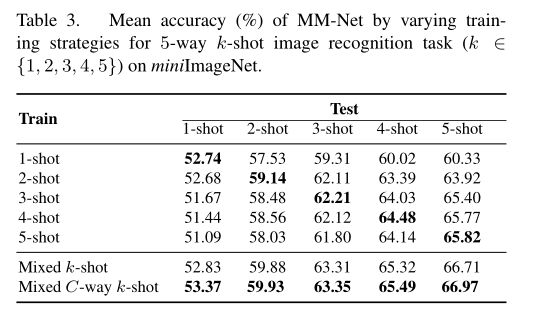
在上述训练过程中,每个训练批都采用与测试设置完全匹配的统一设置(c-way k-shot)构造,目标是模仿测试场景进行单次学习。然而,这种匹配机制表明所学习的模型只适用于前缀为C路k-shot的测试场景,很难推广到其他C0路k0-shot任务。因此,为了提高one-shot学习模型的泛化能力,我们设计了一种混合训练策略,通过构造不同镜头数和类别的训练批来学习一个统一的体系结构,以便对任何one-shot学习场景进行推理。请注意,内存可以被视为一个统一的介质,将不同大小的支持集转换为公共内存插槽。因此,混合训练策略可以应用于学习一个统一的模型,而不受镜头数和类别的影响。
3. 实验