mlr3系列机器学习教程1–mlr3介绍.
mlr3包是既往mlr包的升级,mlr3包为大量的机器学习技术提供了一个通用的技术接口。mlr3不单单是一个包,而是一个生态系列,包括一系列机器学习的R包。

我们下导入mlr3包,使用R自带的汽车数据来做个简单的演示
library(mlr3)
library(mlr3verse)
data("mtcars", package = "datasets")
head(mtcars,6)
## mpg cyl disp hp drat wt qsec vs am gear carb
## Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
## Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
## Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
## Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
## Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
## Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1
这是R语言自带的一个汽车数据,有许多品牌的汽车型号,马力,油耗等相关数据。我们先对变量缩减一下,变量太多增大运算量
mtcars_subset = subset(mtcars, select = c("mpg", "cyl", "disp"))
str(mtcars_subset)
## 'data.frame': 32 obs. of 3 variables:
## $ mpg : num 21 21 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 ...
## $ cyl : num 6 6 4 6 8 6 8 4 4 6 ...
## $ disp: num 160 160 108 258 360 ...
使用mlr3做机器学习的第一步就是建立任务, 使用task函数为数据建立任务,意思大概就是把数据打包在任务里面。我们要汽车重量mpg和其他两个参数”cyl”, “disp”的关系,需要建立一个回归模型,因此使用as_task_regr函数来建立,target填的是结局变量,该id参数是可选的,并指定用于绘图和摘要的任务的标识符;如果省略,数据的变量名将用作id.
task_mtcars = as_task_regr(mtcars_subset, target = "mpg", id = "cars")
task_mtcars
## (32 x 3)
## * Target: mpg
## * Properties: -
## * Features (2):
## - dbl (2): cyl, disp
我们可以使用mlr3viz包进行图形可视化,列出mpg和其他变量关系
library("mlr3viz")
library(GGally)
autoplot(task_mtcars, type = "pairs")
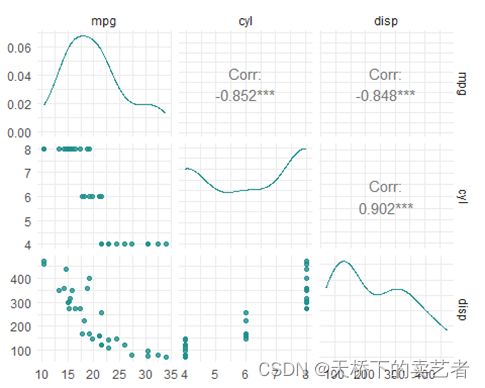
得出变量间的相关系数,下面我们把数据进行7:3划分
splits = partition(task_mtcars, ratio = 0.7)
splits
## $train
## [1] 1 4 5 9 10 25 27 30 32 6 7 12 13 14 15 16 22 23 29 18 19 20 28
##
## $test
## [1] 2 3 8 21 11 17 24 31 26
这样就得出了验证集和预测集。 建立任务后第二部就是定义一个学习器(Learner),其实就等于选哪个R包来分析,学习器将数据传给模型进行训练并返回结果,就等于把数据传给R包,R包得出结果在返回来,回归模型使用的是 regr.rpart等于使用rpart包来分析。

learner_rpart = lrn("regr.rpart")
把数据放入学习器,列出一个模型的数据,这里使用的是rpart包进行预测的
learner_rpart$train(task_mtcars, row_ids = splits$train)
learner_rpart
## : Regression Tree
## * Model: rpart
## * Parameters: xval=0
## * Packages: mlr3, rpart
## * Predict Types: [response]
## * Feature Types: logical, integer, numeric, factor, ordered
## * Properties: importance, missings, selected_features, weights
第三部就可以进行预测了,row_ids这里控制着我们取哪部分数据进行预测,splits$test取的是验证集,等于学习器中放入建模集数据,然后使用验证集来预测
predictions = learner_rpart$predict(task_mtcars, row_ids = splits$test)
predictions
## for 9 observations:
## row_ids truth response
## 2 21.0 16.73750
## 3 22.8 28.18571
## 8 24.4 28.18571
## ---
## 24 13.3 16.73750
## 31 15.0 16.73750
## 26 27.3 28.18571
生成9个预测值对应验证集9个数据,如果需要建模集的数据来预测
predictions = learner_rpart$predict(task_mtcars, row_ids = splits$train)
predictions
## for 23 observations:
## row_ids truth response
## 1 21.0 16.73750
## 4 21.4 16.73750
## 5 18.7 16.73750
## ---
## 19 30.4 28.18571
## 20 33.9 28.18571
## 28 30.4 28.18571
这里对应着建模集的数据数。如果你不喜欢这种row_ids来取数据,也可以使用传统的方法预测,我们先生成一个新数据
mtcars_new<-mtcars[c(1,3,4,8,10,21,27,30),]
生成预测值,truth就是我们数据中的Y值,也就是mpg的值,response是预测值,row_ids任务自己生成的ID
predictions = learner_rpart$predict_newdata(mtcars_new)
predictions
## for 8 observations:
## row_ids truth response
## 1 21.0 16.73750
## 2 22.8 28.18571
## 3 21.4 16.73750
## ---
## 6 21.5 28.18571
## 7 26.0 28.18571
## 8 19.7 16.73750
我们可以对预测值进一步可视化
predictions = learner_rpart$predict(task_mtcars, splits$test)
autoplot(predictions)

上面学习器rpart不能求出标准误,如果我们想进一步求出标准误就得换个学习器(任务不用换),其实就是换个R包来分析
library(mlr3learners)
learner_lm = lrn("regr.lm", predict_type = "se")
learner_lm
## 从上可知,这个学习器只要用3个R包, mlr3, mlr3learners, stats,其实就是主要用mlr3learners包,把数据放入学习器,就是把数据放入R包,并分析,就是重复刚才上面的过程
learner_lm$train(task_mtcars, splits$train)
learner_lm$predict(task_mtcars, splits$test)
## for 9 observations:
## row_ids truth response se
## 2 21.0 22.68033 0.9822678
## 3 22.8 27.26798 1.1418700
## 8 24.4 26.35702 1.3155846
## ---
## 24 13.3 14.84427 0.9238524
## 31 15.0 15.99769 1.0635741
## 26 27.3 27.95062 1.1319728
predictions=learner_lm$predict(task_mtcars, splits$test)
解读和刚才差不多,就是多了标准误se.也可以把数据提取出来绘图
bc<-predictions$data
bc1<-data.frame(row_ids=bc[["row_ids"]],truth=bc[["truth"]],response=bc[["response"]],se=bc[["se"]])
head(bc1,6)
## row_ids truth response se
## 1 2 21.0 22.68033 0.9822678
## 2 3 22.8 27.26798 1.1418700
## 3 8 24.4 26.35702 1.3155846
## 4 21 21.5 26.98316 1.1783833
## 5 11 17.8 22.50143 0.9170841
## 6 17 14.7 12.72575 1.4961354
进行转换后得到转换好的数据我们也可以使用ggplot绘图。本节就先介绍到这里啦。