深度学习笔记之循环神经网络(六)长短期记忆神经网络(LSTM)
深度学习笔记之循环神经网络——长短期记忆神经网络[LSTM]
- 引言
-
- 回顾: RNN \text{RNN} RNN的反向传播过程
-
- RNN \text{RNN} RNN反向传播的梯度消失问题
- 长短期记忆神经网络
-
- 遗忘门结构
- 输入门结构
- 遗忘门与输入门的特征融合操作
- 输出门结构
- 个人感悟
引言
上一节介绍了循环神经网络 ( Recurrent Neural Network,RNN ) (\text{Recurrent Neural Network,RNN}) (Recurrent Neural Network,RNN)的反向传播过程,本节将针对 RNN \text{RNN} RNN存在的梯度消失问题,介绍一种新的网络——长短期记忆神经网络 ( Long-Short Term Memory,LSTM ) (\text{Long-Short Term Memory,LSTM}) (Long-Short Term Memory,LSTM)。
回顾: RNN \text{RNN} RNN的反向传播过程
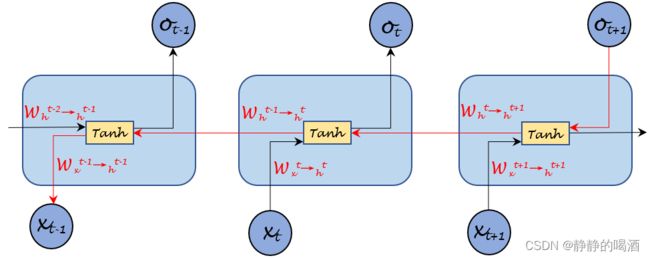
关于 RNN \text{RNN} RNN的网络结构图(展开)表示如下:

仅以上图部分为例,它的前馈计算过程表示如下:
对应的 t , t + 1 t,t+1 t,t+1时刻同理。
{ Z 1 ( t − 1 ) = W h ( t − 2 ) ⇒ h ( t − 1 ) ⋅ h ( t − 2 ) + W x ( t − 1 ) ⇒ h ( t − 1 ) ⋅ x ( t − 1 ) + b ( t − 1 ) h ( t − 1 ) = Tanh [ Z 1 ( t − 1 ) ] Z 2 ( t − 1 ) = W h ( t − 1 ) ⇒ O ( t − 1 ) ⋅ h ( t − 1 ) + b O O ( t − 1 ) = Softmax ( Z 2 ( t − 1 ) ) \begin{aligned} \begin{cases} \mathcal Z_1^{(t-1)} & = \mathcal W_{h^{(t-2)}\Rightarrow h^{(t-1)}}\cdot h^{(t-2)} + \mathcal W_{x^{(t-1)} \Rightarrow h^{(t-1)}} \cdot x^{(t-1)} + b^{(t-1)}\\ h^{(t-1)} & = \text{Tanh}\left[\mathcal Z_1^{(t-1)}\right] \\ \mathcal Z_2^{(t-1)} & = \mathcal W_{h^{(t-1)} \Rightarrow \mathcal O^{(t-1)}} \cdot h^{(t-1)} + b_{\mathcal O} \\ \mathcal O^{(t-1)} & = \text{Softmax}(\mathcal Z_2^{(t-1)}) \end{cases} \end{aligned} ⎩ ⎨ ⎧Z1(t−1)h(t−1)Z2(t−1)O(t−1)=Wh(t−2)⇒h(t−1)⋅h(t−2)+Wx(t−1)⇒h(t−1)⋅x(t−1)+b(t−1)=Tanh[Z1(t−1)]=Wh(t−1)⇒O(t−1)⋅h(t−1)+bO=Softmax(Z2(t−1))
假设针对分类任务使用交叉熵作为损失函数,从 t + 1 t+1 t+1时刻的损失函数信息 L ( t + 1 ) \mathcal L^{(t+1)} L(t+1)开始,对 t − 1 t-1 t−1时刻的权重 W x ( t − 1 ) ⇒ h ( t − 1 ) \mathcal W_{x^{(t-1)} \Rightarrow h^{(t-1)}} Wx(t−1)⇒h(t−1)求解梯度。那么它的梯度传播方向表示如下(红色箭头方向):
这里仅描述 L ( t + 1 ) \mathcal L^{(t+1)} L(t+1)对 W x ( t − 1 ) ⇒ h ( t − 1 ) \mathcal W_{x^{(t-1)} \Rightarrow h^{(t-1)}} Wx(t−1)⇒h(t−1)的梯度,其他时刻输出对应的梯度不包含在内。
对应梯度公式表示如下:
关于∂ L ( t + 1 ) ∂ O ( t + 1 ) ⋅ ∂ O ( t + 1 ) ∂ Z 2 ( t + 1 ) \begin{aligned}\frac{\partial \mathcal L^{(t+1)}}{\partial \mathcal O^{(t+1)}} \cdot \frac{\partial \mathcal O^{(t+1)}}{\partial \mathcal Z_2^{(t+1)}}\end{aligned} ∂O(t+1)∂L(t+1)⋅∂Z2(t+1)∂O(t+1)结果见上一节。其中y ( t + 1 ) y^{(t+1)} y(t+1)表示t + 1 t+1 t+1时刻样本的真实分布。
∂ L ( t + 1 ) ∂ W x ( t − 1 ) ⇒ h ( t − 1 ) = ∂ L ( t + 1 ) ∂ O ( t + 1 ) ⋅ ∂ O ( t + 1 ) ∂ Z 2 ( t + 1 ) ⋅ ∂ Z 2 ( t + 1 ) ∂ h ( t + 1 ) ⏟ O ( t + 1 ) 梯度结果 ⋅ [ ∏ k = t t + 1 ∂ h ( k ) ∂ Z 1 ( k ) ⋅ ∂ Z 1 ( k ) ∂ h ( k − 1 ) ] ⋅ ∂ h ( t − 1 ) ∂ Z 1 ( t − 1 ) ⋅ ∂ Z 1 ( t − 1 ) ∂ W x ( t − 1 ) ⇒ h ( t − 1 ) = ( O ( t + 1 ) − y ( t + 1 ) ) ⋅ W h ( t + 1 ) ⇒ O ( t + 1 ) ⋅ { ∏ k = t t + 1 Diag [ 1 − Tanh 2 ( Z 1 ( k ) ) ] ⋅ W h ( k − 1 ) ⇒ h ( k ) } ⋅ Diag [ 1 − Tanh 2 ( Z 1 ( t − 1 ) ) ] ⋅ x ( t − 1 ) = ( O ( t + 1 ) − y ( t + 1 ) ) ⋅ W h ( t + 1 ) ⇒ O ( t + 1 ) ⋅ { ∏ k = t − 1 t + 1 Diag [ 1 − Tanh 2 ( Z 1 ( k ) ) ] } ⋅ { ∏ k = t t + 1 W h ( k − 1 ) ⇒ h ( k ) } ⋅ x ( t − 1 ) \begin{aligned} \frac{\partial \mathcal L^{(t+1)}}{\partial \mathcal W_{x^{(t-1)} \Rightarrow h^{(t-1)}}} & = \underbrace{\frac{\partial \mathcal L^{(t+1)}}{\partial \mathcal O^{(t+1)}} \cdot \frac{\partial \mathcal O^{(t+1)}}{\partial \mathcal Z_2^{(t+1)}} \cdot \frac{\partial \mathcal Z_2^{(t+1)}}{\partial h^{(t+1)}}}_{\mathcal O^{(t+1)}梯度结果} \cdot \left[\prod_{k=t}^{t+1} \frac{\partial h^{(k)}}{\partial \mathcal Z_1^{(k)}} \cdot \frac{\partial \mathcal Z_1^{(k)}}{\partial h^{(k-1)}}\right] \cdot \frac{\partial h^{(t-1)}}{\partial \mathcal Z_1^{(t-1)}} \cdot \frac{\partial \mathcal Z_1^{(t-1)}}{\partial \mathcal W_{x^{(t-1)} \Rightarrow h^{(t-1)}}} \\ & = (\mathcal O^{(t+1)} - y^{(t+1)}) \cdot \mathcal W_{h^{(t+1)} \Rightarrow \mathcal O^{(t+1)}} \cdot \left\{\prod_{k=t}^{t+1} \text{Diag} \left[1 - \text{Tanh}^2(\mathcal Z_1^{(k)})\right] \cdot \mathcal W_{h^{(k-1)} \Rightarrow h^{(k)}}\right\} \cdot \text{Diag}\left[1 - \text{Tanh}^2(\mathcal Z_1^{(t-1)})\right] \cdot x^{(t-1)} \\ & = (\mathcal O^{(t+1)} - y^{(t+1)}) \cdot \mathcal W_{h^{(t+1)} \Rightarrow \mathcal O^{(t+1)}} \cdot \left\{\prod_{k=t-1}^{t+1} \text{Diag} \left[1 - \text{Tanh}^2(\mathcal Z_1^{(k)})\right]\right\}\cdot \left\{\prod_{k=t}^{t+1}\mathcal W_{h^{(k-1)} \Rightarrow h^{(k)}}\right\} \cdot x^{(t-1)} \end{aligned} ∂Wx(t−1)⇒h(t−1)∂L(t+1)=O(t+1)梯度结果 ∂O(t+1)∂L(t+1)⋅∂Z2(t+1)∂O(t+1)⋅∂h(t+1)∂Z2(t+1)⋅[k=t∏t+1∂Z1(k)∂h(k)⋅∂h(k−1)∂Z1(k)]⋅∂Z1(t−1)∂h(t−1)⋅∂Wx(t−1)⇒h(t−1)∂Z1(t−1)=(O(t+1)−y(t+1))⋅Wh(t+1)⇒O(t+1)⋅{k=t∏t+1Diag[1−Tanh2(Z1(k))]⋅Wh(k−1)⇒h(k)}⋅Diag[1−Tanh2(Z1(t−1))]⋅x(t−1)=(O(t+1)−y(t+1))⋅Wh(t+1)⇒O(t+1)⋅{k=t−1∏t+1Diag[1−Tanh2(Z1(k))]}⋅{k=t∏t+1Wh(k−1)⇒h(k)}⋅x(t−1)
这仅仅是两个时刻长度的梯度描述。更泛化的情况呢 ? ? ?例如想要将 T \mathcal T T时刻的损失信息 L ( T ) \mathcal L^{(\mathcal T)} L(T)通过梯度传递给 W x ( 1 ) ⇒ h ( 1 ) \mathcal W_{x^{(1)}\Rightarrow h^{(1)}} Wx(1)⇒h(1),关于梯度 ∂ L ( T ) ∂ W x ( 1 ) ⇒ h ( 1 ) \begin{aligned}\frac{\partial \mathcal L^{(\mathcal T)}}{\partial \mathcal W_{x^{(1)} \Rightarrow h^{(1)}}} \end{aligned} ∂Wx(1)⇒h(1)∂L(T)可表示为:
∂ L ( T ) ∂ W x ( 1 ) ⇒ h ( 1 ) = ( O ( T ) − y ( T ) ) ⋅ W h ( T ) ⇒ O ( T ) ⋅ { ∏ k = 1 T Diag [ 1 − Tanh 2 ( Z 1 ( k ) ) ] } ⋅ { ∏ k = 2 T W h ( k − 1 ) ⇒ h ( k ) } ⋅ x ( 1 ) \begin{aligned}\frac{\partial \mathcal L^{(\mathcal T)}}{\partial \mathcal W_{x^{(1)} \Rightarrow h^{(1)}}} & = (\mathcal O^{(\mathcal T)} - y^{(\mathcal T)}) \cdot \mathcal W_{h^{(\mathcal T)} \Rightarrow \mathcal O^{(\mathcal T)}} \cdot \left\{\prod_{k=1}^{\mathcal T} \text{Diag}\left[1 - \text{Tanh}^2(\mathcal Z_1^{(k)})\right]\right\} \cdot \left\{\prod_{k=2}^{\mathcal T} \mathcal W_{h^{(k-1)} \Rightarrow h^{(k)}}\right\} \cdot x^{(1)} \end{aligned} ∂Wx(1)⇒h(1)∂L(T)=(O(T)−y(T))⋅Wh(T)⇒O(T)⋅{k=1∏TDiag[1−Tanh2(Z1(k))]}⋅{k=2∏TWh(k−1)⇒h(k)}⋅x(1)
RNN \text{RNN} RNN反向传播的梯度消失问题
上述梯度仅仅描述了 L ( T ) \mathcal L^{(\mathcal T)} L(T)对 W x ( 1 ) ⇒ h ( 1 ) \mathcal W_{x^{(1)} \Rightarrow h^{(1)}} Wx(1)⇒h(1)的梯度信息,实际上,除去初始时刻,其他时刻的输出都会向 W x ( 1 ) ⇒ h ( 1 ) \mathcal W_{x^{(1)} \Rightarrow h^{(1)}} Wx(1)⇒h(1)传递梯度信息。
观察上式,其中 ∏ k = 2 T W h ( k − 1 ) ⇒ h ( k ) \begin{aligned}\prod_{k=2}^{\mathcal T} \mathcal W_{h^{(k-1)} \Rightarrow h^{(k)}}\end{aligned} k=2∏TWh(k−1)⇒h(k)就是各时刻隐变量权重的累积结果。
由于损失函数使用的交叉熵,因此使用梯度下降法对各权重进行更新,这导致 W h ( k − 1 ) ⇒ h ( k ) ( k = 2 , ⋯ , T ) \mathcal W_{h^{(k-1)}\Rightarrow h^{(k)}}(k=2,\cdots,\mathcal T) Wh(k−1)⇒h(k)(k=2,⋯,T)结果逐渐趋近于零。最终导致梯度结果 ∂ L ( T ) ∂ W x ( 1 ) ⇒ h ( 1 ) \begin{aligned}\frac{\partial \mathcal L^{(\mathcal T)}}{\partial \mathcal W_{x^{(1)} \Rightarrow h^{(1)}}} \end{aligned} ∂Wx(1)⇒h(1)∂L(T)随着各时刻权重更新几乎不发生变化,即梯度消失现象。
从物理意义的角度观察,随着序列长度的增加,对序列初始位置的信息出现忘却的现象。因为参数更新过程中梯度仅能有效传递到之前若干个时刻。这导致无法捕捉长期关联或者依赖关系。
这个问题也被称作‘长期依赖问题’。
长短期记忆神经网络
针对循环神经网络的长期依赖问题, LSTM \text{LSTM} LSTM给出了解决方式。从思想的角度观察,它与循环神经网络没有本质区别,依然是对各时刻隐变量 h t ( t = 1 , 2 , ⋯ , T ) h_t(t=1,2,\cdots,\mathcal T) ht(t=1,2,⋯,T)的后验分布以及对应下一时刻输入的后验分布进行交替求解:
{ P ( h t ∣ h t − 1 , x t − 1 ) = P [ h t ∣ f ( h t − 1 , x t − 1 ; λ ) ] P ( x t ∣ h t , x t − 1 ) = P [ x t ∣ f ( h t , x t − 1 ; η ) ] \begin{cases} \mathcal P(h_t \mid h_{t-1},x_{t-1}) = \mathcal P [h_t \mid f(h_{t-1},x_{t-1};\lambda)] \\ \mathcal P(x_t \mid h_{t},x_{t-1}) = \mathcal P [x_t \mid f(h_t,x_{t-1};\eta)] \end{cases} {P(ht∣ht−1,xt−1)=P[ht∣f(ht−1,xt−1;λ)]P(xt∣ht,xt−1)=P[xt∣f(ht,xt−1;η)]
不同于 RNN \text{RNN} RNN的神经网络构建, LSTM \text{LSTM} LSTM对各单元的输出进行了限制,从而避免出现梯度消失现象。 LSTM \text{LSTM} LSTM的结构展开图表示如下:
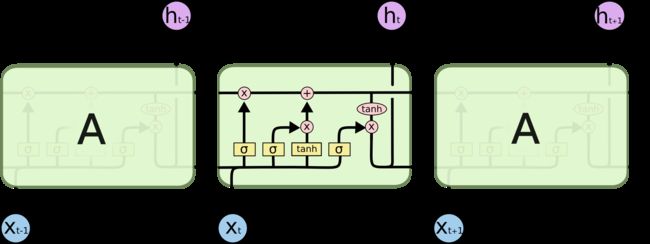
可以看出, LSTM \text{LSTM} LSTM单元结构与循环神经网络是相似的。每个单元均包含 x ( t ) , h ( t ) x^{(t)},h^{(t)} x(t),h(t);不同点在于, LSTM \text{LSTM} LSTM内增加了一个新的变量——细胞状态 ( Cell State ) C ( t ) (\text{Cell State})\mathcal C^{(t)} (Cell State)C(t)。
从图中可以看出,在每一个 LSTM \text{LSTM} LSTM单元中, C ( t ) \mathcal C^{(t)} C(t)不仅全程陪跑,并且还对当前时刻隐变量输出 h ( t ) h^{(t)} h(t)存在紧密关联。下面从 LSTM \text{LSTM} LSTM单元中的各结构进行介绍。
遗忘门结构
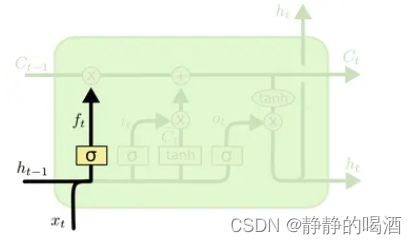
被称作遗忘门 ( Forget Gate ) (\text{Forget Gate}) (Forget Gate)的神经元结构,其输入包含两个部分:当前时刻 t t t的输入信息 x ( t ) x^{(t)} x(t),以及 t t t时刻之前的序列信息 h ( t − 1 ) h^{(t-1)} h(t−1);由于 σ = Sigmoid \sigma = \text{Sigmoid} σ=Sigmoid激活函数的原因,其输出 f ( t ) f^{(t)} f(t)是一个各元素值均 ∈ ( 0 , 1 ) \in (0,1) ∈(0,1)的向量结果。对应公式表示如下:
正常写法是 f t = σ ( W f ⋅ [ h ( t − 1 ) , x ( t ) ] + b f ) f_t = \sigma(\mathcal W_f \cdot [h^{(t-1)},x^{(t)}] + b_f) ft=σ(Wf⋅[h(t−1),x(t)]+bf),其将 h ( t − 1 ) , x ( t ) h^{(t-1)},x^{(t)} h(t−1),x(t)进行拼接,使用一个权重矩阵 W f \mathcal W_f Wf进行表示。这里仅是为了与上面格式相同,下同。
f ( t ) = σ [ W h ( t − 1 ) ⇒ f ( t ) ⋅ h ( t − 1 ) + W x ( t ) ⇒ f ( t ) ⋅ x ( t ) + b f ] f^{(t)} = \sigma \left[\mathcal W_{h^{(t-1)} \Rightarrow f^{(t)}} \cdot h^{(t-1)} + \mathcal W_{x^{(t)} \Rightarrow f^{(t)} }\cdot x^{(t)} + b_f\right] f(t)=σ[Wh(t−1)⇒f(t)⋅h(t−1)+Wx(t)⇒f(t)⋅x(t)+bf]
我们可以将 f ( t ) f^{(t)} f(t)理解成比率,即各分量保留下来(不被遗忘)的比率。
输入门结构
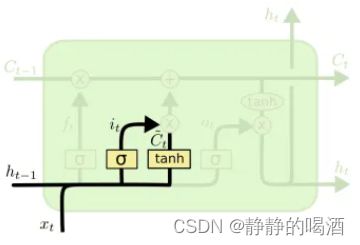
被称作输入门 ( Input Gate ) (\text{Input Gate}) (Input Gate)的结构,包含了两个神经元,并且这两个神经元的输入是相同的: x ( t ) , h ( t − 1 ) x^{(t)},h^{(t-1)} x(t),h(t−1)
- 第一个神经元的激活函数是 Tanh \text{Tanh} Tanh,该格式与循环神经网络中的 h ( t ) h^{(t)} h(t)的描述相同,即当前 t t t时刻,单元内的序列信息。记作候选信息 C ~ ( t ) \widetilde{\mathcal C}^{(t)} C (t):
C ~ ( t ) = Tanh [ W h ( t − 1 ) ⇒ C ~ ( t ) ⋅ h ( t − 1 ) + W x ( t ) ⇒ C ~ ( t ) ⋅ x ( t ) + b C ~ ] \widetilde{\mathcal C}^{(t)} = \text{Tanh} \left[\mathcal W_{h^{(t-1)} \Rightarrow \widetilde{\mathcal C}^{(t)}} \cdot h^{(t-1)} + \mathcal W_{x^{(t)} \Rightarrow \widetilde{\mathcal C}^{(t)}} \cdot x^{(t)} + b_{\widetilde{\mathcal C}}\right] C (t)=Tanh[Wh(t−1)⇒C (t)⋅h(t−1)+Wx(t)⇒C (t)⋅x(t)+bC ] - 另一个神经元的激活函数是 Sigmoid \text{Sigmoid} Sigmoid,它与遗忘门结构的思想完全相同。只不过该神经元针对的对象是候选信息 C ~ ( t ) \widetilde{\mathcal C}^{(t)} C (t),而遗忘门针对的对象是过去时刻累积的状态信息 C ( t − 1 ) \mathcal C^{(t-1)} C(t−1):
i ( t ) = σ [ W h ( t − 1 ) ⇒ i ( t ) ⋅ h ( t − 1 ) + W x ( t ) ⇒ i ( t ) ⋅ x ( t ) + b i ] i^{(t)} = \sigma \left[\mathcal W_{h^{(t-1)} \Rightarrow i^{(t)}} \cdot h^{(t-1)} + \mathcal W_{x^{(t)} \Rightarrow i^{(t)}} \cdot x^{(t)} + b_i\right] i(t)=σ[Wh(t−1)⇒i(t)⋅h(t−1)+Wx(t)⇒i(t)⋅x(t)+bi]
遗忘门与输入门的特征融合操作
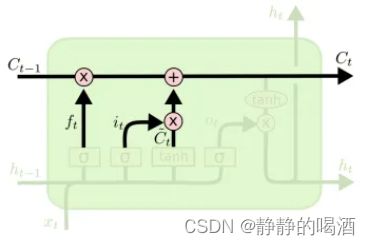
将 t t t时刻输入门结构中的更新比率 i ( t ) i^{(t)} i(t)与对应的候选信息 C ~ ( t ) \widetilde{\mathcal C}^{(t)} C (t)做点乘 i ( t ) ∗ C ~ ( t ) i^{(t)} * \widetilde{\mathcal C}^{(t)} i(t)∗C (t),表示:当前 t t t时刻能够被保留下来的候选信息;同理,遗忘门结构的遗忘比率 f ( t ) f^{(t)} f(t)与 C ( t − 1 ) \mathcal C^{(t-1)} C(t−1)做点乘 f ( t ) ∗ C ( t − 1 ) f^{(t)} * \mathcal C^{(t-1)} f(t)∗C(t−1),表示能够保留下来的过去 t − 1 t-1 t−1时刻的累积信息。
将两种信息融合,得到:从初始时刻到 t t t时刻保留下来的累积信息 C ( t ) \mathcal C^{(t)} C(t):
C ( t ) = f ( t ) ∗ C ( t − 1 ) + i ( t ) ∗ C ~ ( t ) \mathcal C^{(t)} = f^{(t)} * \mathcal C^{(t-1)} + i^{(t)} * \widetilde{\mathcal C}^{(t)} C(t)=f(t)∗C(t−1)+i(t)∗C (t)
输出门结构
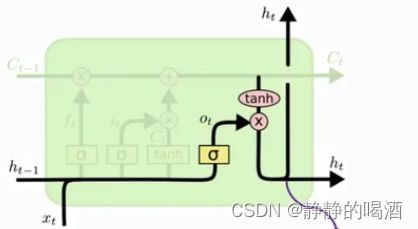
被称作输出门 ( Output Gate ) (\text{Output Gate}) (Output Gate)的结构,包含一个神经元和一个 Tanh \text{Tanh} Tanh激活函数:
- 对于激活函数 Tanh \text{Tanh} Tanh,它的输入部分是融合特征 C ( t ) \mathcal C^{(t)} C(t)。 Tanh \text{Tanh} Tanh函数的一个主要作用是: C ( t ) \mathcal C^{(t)} C(t)种贸然将两类特征融合,势必会使特征分布发生变化。而 Tanh \text{Tanh} Tanh激活函数在不破坏恒等映射分布的情况下,最大程度的将偏离的分布拉回来。
Tanh \text{Tanh} Tanh激活函数不仅映射值域较广( − 1 , 1 ) (-1,1) (−1,1),并且该函数在0 0 0附近的结果趋近于y = x y=x y=x,这是一个优秀的性质。
关于恒等映射分布与激活函数的底层逻辑,详见数值稳定性、模型初始化与激活函数
Tanh ( C ( t ) ) \text{Tanh}(\mathcal C^{(t)}) Tanh(C(t)) - 另一个神经元的激活函数是 Sigmoid \text{Sigmoid} Sigmoid,它与遗忘门、输入门结构的思想完全相同。也就是说:即便是融合后,并将分布还原后的特征信息,同样需要挑选出需要保留的信息,并作为下一时刻的隐状态输出 h ( t ) h^{(t)} h(t),而未经过 Tanh \text{Tanh} Tanh映射的融合特征 C ( t ) \mathcal C^{(t)} C(t),继续陪跑,作为下一时刻的过去时刻累积状态:
{ o ( t ) = σ ( W h ( t − 1 ) ⇒ o ( t ) ⋅ h ( t − 1 ) + W x ( t ) ⇒ o ( t ) ⋅ x ( t ) + b o ) h ( t ) = o ( t ) ∗ Tanh ( C ( t ) ) \begin{cases} o^{(t)} = \sigma(\mathcal W_{h^{(t-1)} \Rightarrow o^{(t)}} \cdot h^{(t-1)} + \mathcal W_{x^{(t)} \Rightarrow o^{(t)}} \cdot x^{(t)} + b_o) \\ h^{(t)} = o^{(t)} * \text{Tanh}(\mathcal C^{(t)}) \end{cases} {o(t)=σ(Wh(t−1)⇒o(t)⋅h(t−1)+Wx(t)⇒o(t)⋅x(t)+bo)h(t)=o(t)∗Tanh(C(t))
个人感悟
之前在其他的模型中,我们更多的是对随机变量的后验进行推断(观测变量、隐变量)。而这里的 f ( t ) , i ( t ) , o ( t ) f^{(t)},i^{(t)},o^{(t)} f(t),i(t),o(t),我们人为给他们赋予的物理意义是一个比率,更泛化地说,它们都是约束序列信息的一种权重。而这种权重还被其他权重约束着。例如:
o ( t ) ⏟ 一种权重 = σ ( W h ( t − 1 ) ⇒ o ( t ) ⏟ 约束权重 o ( t ) 的权重 ⋅ h ( t − 1 ) + W x ( t ) ⇒ o ( t ) ⏟ 约束权重 o ( t ) 的权重 ⋅ x ( t ) + b o ) \underbrace{o^{(t)}}_{一种权重} = \sigma \left(\underbrace{\mathcal W_{h^{(t-1)} \Rightarrow o^{(t)}}}_{约束权重o^{(t)}的权重} \cdot h^{(t-1)} + \underbrace{\mathcal W_{x^{(t)} \Rightarrow o^{(t)}}}_{约束权重o^{(t)}的权重} \cdot x^{(t)} + b_o \right) 一种权重 o(t)=σ 约束权重o(t)的权重 Wh(t−1)⇒o(t)⋅h(t−1)+约束权重o(t)的权重 Wx(t)⇒o(t)⋅x(t)+bo
并能够执行用其执行运算。这种嵌套是个很奇特的感受。
它们的本质也是隐变量,但它们能够与其他隐变量执行运算。
下一节将从反向传播的角度观察为什么 LSTM \text{LSTM} LSTM能够抑制梯度消失。
相关参考:
RNN梯度消失回顾(公式推导)
大名鼎鼎的LSTM详解