(金融)银行贷款的用户增长项目——数据分析
银行贷款项目的用户特征数据分析
1、案例背景
Thera Bank是一家拥有不断增长客户群的银行。这银行中大多数客户的存款规模都是不一样的。由于贷款业务的客户数量很少,所以银行希望有效地将存款用户转化为贷款用户以此扩大贷款业务量的基础,以带来更多的贷款业务,并在此过程中,通过贷款利息赚取更多。
因此,该银行去年为存款用户但未办理个人贷款业务的客户开展了一项推广活动来促使其办理个人贷款业务,有部分客户通过此活动已经办理了相关服务。这时的零售营销部门希望制定更好的策略去定位营销,以最小的预算提高成功率。该部门希望识别出更有可能购买贷款的潜在客户,提高转化的成功率,降低营销的费用。
#导入相关模块
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
#连接mysql
import pymysql
pymysql.install_as_MySQLdb()
from sqlalchemy import create_engine
engine=create_engine('mysql://ID:password@localhost:3306/database?charset=gbk')
#读取数据
Bank_Personal_Loan=pd.read_sql_query('select * from Personal_Loan',con=engine)
2、理解数据
数据集共包含5000条记录,14个字段,对应字段含义如下:
- ID - 客户
- Age - 客户年龄
- Experience - 客户工作经验
- Income - 客户年收入(单位:千美元)
- ZIPCode - 家庭地址邮政编码
- Family - 客户的家庭规模
- CCAvg - 每月信用卡消费额(单位:千美元)
- Education - 教育水平 (1: 本科; 2: 研究生; 3: 高级)
- Mortgage - 房屋抵押价值(如有)(单位:千美元)
- Personal Loan - 此客户是否接受上一次活动中提供的个人贷款?(1:是 0:否)
- Securities Account - 是否有证券账户?(1:是 0:否)
- CD Account - 是否有存款证明(CD)帐户吗(1:是 0:否)
- Online - 是否开通网上银行?(1:是 0:否)
- CreditCard - 是否有信用卡?(1:是 0:否)
Bank_Personal_Loan.head()
| ID | Age | Experience | Income | ZIP Code | Family | CCAvg | Education | Mortgage | Personal Loan | Securities Account | CD Account | Online | CreditCard | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 25 | 1 | 49 | 91107 | 4 | 1.6 | 1 | 0 | 0 | 1 | 0 | 0 | 0 |
| 1 | 2 | 45 | 19 | 34 | 90089 | 3 | 1.5 | 1 | 0 | 0 | 1 | 0 | 0 | 0 |
| 2 | 3 | 39 | 15 | 11 | 94720 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 4 | 35 | 9 | 100 | 94112 | 1 | 2.7 | 2 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 5 | 35 | 8 | 45 | 91330 | 4 | 1 | 2 | 0 | 0 | 0 | 0 | 0 | 1 |
#观察数据整体情况
Bank_Personal_Loan.info()
RangeIndex: 5000 entries, 0 to 4999
Data columns (total 14 columns):
ID 5000 non-null object
Age 5000 non-null object
Experience 5000 non-null object
Income 5000 non-null object
ZIP Code 5000 non-null object
Family 5000 non-null object
CCAvg 5000 non-null object
Education 5000 non-null object
Mortgage 5000 non-null object
Personal Loan 5000 non-null object
Securities Account 5000 non-null object
CD Account 5000 non-null object
Online 5000 non-null object
CreditCard 5000 non-null object
dtypes: object(14)
memory usage: 547.0+ KB
观察各字段基础信息,数据并无重复,缺失情况;对于一些数值型的字段则需要做一些数据类型的转化
#更改变量类型,方便后续做统计分析
Bank_Personal_Loan['Age']=Bank_Personal_Loan['Age'].astype('int')
Bank_Personal_Loan['Experience']=Bank_Personal_Loan['Experience'].astype('int')
Bank_Personal_Loan['Family']=Bank_Personal_Loan['Family'].astype('int')
Bank_Personal_Loan['Education']=Bank_Personal_Loan['Education'].astype('int')
Bank_Personal_Loan['ZIP Code']=Bank_Personal_Loan['ZIP Code'].astype('int')
Bank_Personal_Loan['Personal Loan']=Bank_Personal_Loan['Personal Loan'].astype('int')
Bank_Personal_Loan['CD Account']=Bank_Personal_Loan['CD Account'].astype('int')
Bank_Personal_Loan['Securities Account']=Bank_Personal_Loan['Securities Account'].astype('int')
Bank_Personal_Loan['Online']=Bank_Personal_Loan['Online'].astype('int')
Bank_Personal_Loan['CreditCard']=Bank_Personal_Loan['CreditCard'].astype('int')
Bank_Personal_Loan['Income']=Bank_Personal_Loan['Income'].astype('float')
Bank_Personal_Loan['CCAvg']=Bank_Personal_Loan['CCAvg'].astype('float')
Bank_Personal_Loan['Mortgage']=Bank_Personal_Loan['Mortgage'].astype('float')
#观察数据的一个描述性信息
Bank_Personal_Loan.describe()
| Age | Experience | Income | ZIP Code | Family | CCAvg | Education | Mortgage | Personal Loan | Securities Account | CD Account | Online | CreditCard | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 5000.000000 | 5000.000000 | 5000.000000 | 5000.000000 | 5000.000000 | 5000.000000 | 5000.000000 | 5000.000000 | 5000.000000 | 5000.000000 | 5000.00000 | 5000.000000 | 5000.000000 |
| mean | 45.338400 | 20.104600 | 73.774200 | 93152.503000 | 2.396400 | 1.937913 | 1.881000 | 56.498800 | 0.096000 | 0.104400 | 0.06040 | 0.596800 | 0.294000 |
| std | 11.463166 | 11.467954 | 46.033729 | 2121.852197 | 1.147663 | 1.747666 | 0.839869 | 101.713802 | 0.294621 | 0.305809 | 0.23825 | 0.490589 | 0.455637 |
| min | 23.000000 | -3.000000 | 8.000000 | 9307.000000 | 1.000000 | 0.000000 | 1.000000 | 0.000000 | 0.000000 | 0.000000 | 0.00000 | 0.000000 | 0.000000 |
| 25% | 35.000000 | 10.000000 | 39.000000 | 91911.000000 | 1.000000 | 0.700000 | 1.000000 | 0.000000 | 0.000000 | 0.000000 | 0.00000 | 0.000000 | 0.000000 |
| 50% | 45.000000 | 20.000000 | 64.000000 | 93437.000000 | 2.000000 | 1.500000 | 2.000000 | 0.000000 | 0.000000 | 0.000000 | 0.00000 | 1.000000 | 0.000000 |
| 75% | 55.000000 | 30.000000 | 98.000000 | 94608.000000 | 3.000000 | 2.500000 | 3.000000 | 101.000000 | 0.000000 | 0.000000 | 0.00000 | 1.000000 | 1.000000 |
| max | 67.000000 | 43.000000 | 224.000000 | 96651.000000 | 4.000000 | 10.000000 | 3.000000 | 635.000000 | 1.000000 | 1.000000 | 1.00000 | 1.000000 | 1.000000 |
发现Experience出现负值,有异常数据
#考虑将Experience的负值改为0
Bank_Personal_Loan.loc[Bank_Personal_Loan['Experience']<0,'Experience']=0
Bank_Personal_Loan.Experience.describe()
count 5000.000000
mean 20.119600
std 11.440484
min 0.000000
25% 10.000000
50% 20.000000
75% 30.000000
max 43.000000
Name: Experience, dtype: float64
3、数据分析
整体思路:
1.去年银行举办的推广活动的效果如何?
2什么类型的存款用户成为银行贷款业务的潜在客户可能性更大?
2.1随着客户年收入的增长,贷款情况是如何变化?
2.2随着客户年龄的增长,贷款情况如何变化?
#活动推广结果分析
Bank_Personal_Loan.groupby('Personal Loan').size()
Personal Loan
0 4520
1 480
dtype: int64
通过这次推广活动以后,5000名客户中,有480个客户开通了个人贷款业务。由于该活动是针对未办理个人贷款业务的客户开展的,对比从以往数据来看,个人贷款业务增长了近10%,说明此次推广活动的效果还是不错的
?sns.heatmap
#探索其他变量与Personal Loan变量的关系
print(Bank_Personal_Loan.corr()['Personal Loan'])
#fig代表绘图窗口(Figure);axis代表这个绘图窗口上的坐标系(axis)
fig,axis=plt.subplots(figsize=(12,12))
#绘制热力图,颜色越深,相关性越强
ax=sns.heatmap(Bank_Personal_Loan.corr(),annot=True,cmap='YlGnBu')
#bottom代表y轴下限,top表示y轴上限(有些matplotlib版本画热力图上下边框只显示一半)
bottom,top=ax.get_ylim()
ax.set_ylim(bottom+0.5,top-0.5)
Age -0.007726
Experience -0.007858
Income 0.502462
ZIP Code 0.000107
Family 0.061367
CCAvg 0.366891
Education 0.136722
Mortgage 0.142095
Personal Loan 1.000000
Securities Account 0.021954
CD Account 0.316355
Online 0.006278
CreditCard 0.002802
Name: Personal Loan, dtype: float64
(13.0, 0.0)
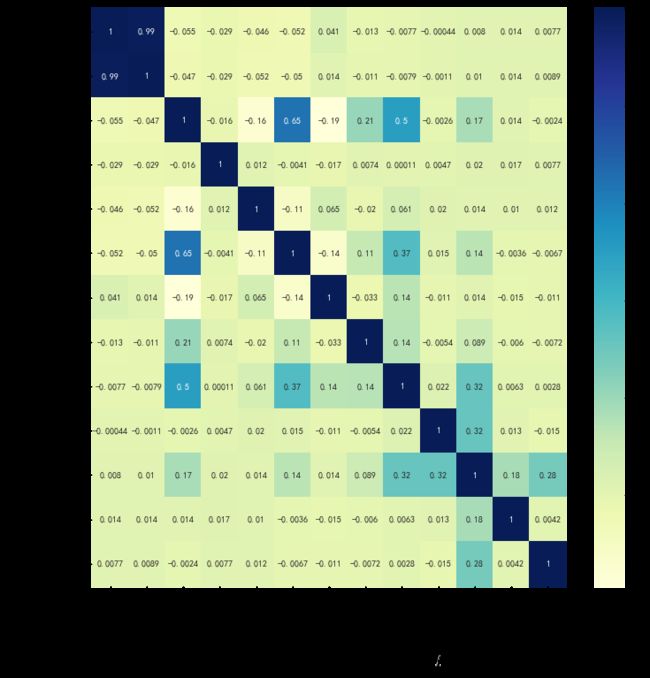
从图中可以看出:
1、和开通信贷强相关的变量有:收入(0.5),信用卡消费额(0.37)及是否有该银行存款账户(0.32);
2、和开通信贷弱相关的变量有:受教育程度(0.14),房屋抵押贷款数(0.14);
3、邮编(0.00011)、是否是证券账户(0.022),是否开通网上银行(0.0063)及是否有信用卡(0.0028),关系都不大;
4、年龄(-0.0077)、工作经验(-0.0011)虽然关系也不大,但它们属于连续的数值变量,所以需要分箱后再做观察,看看是否有某一段存在特殊值。
#先剔除无关的变量,对其余相关变量进行分析
#1 定性变量与开通贷款的关系(对定性变量中是否有该银行存单账户、受教育程度、家庭人数与是否开通贷款的关系进行探究)
#1.1 是否有该银行存单账户
print(Bank_Personal_Loan.groupby('CD Account')['Personal Loan'].agg(np.mean))
sns.countplot(x='CD Account',data=Bank_Personal_Loan,hue='Personal Loan')
CD Account
0 0.072371
1 0.463576
Name: Personal Loan, dtype: float64

开通了银行存单账户的客户,其申请贷款的可能性是没有开通的6倍多,说明开通了银行账户的客户是一个主要的目标客户;找到方法让客户开通该银行存款账单也是一个提高申请贷款率的可能选项。
#1.2 教育水平
print(Bank_Personal_Loan.groupby('Personal Loan')['Education'].agg(np.mean))
sns.catplot(x='Education',data=Bank_Personal_Loan,hue='Personal Loan',kind='count')
Personal Loan
0 1.843584
1 2.233333
Name: Education, dtype: float64

学历越高,贷款意愿的比率越多,说明教育水平越高,越能接受超前消费观念,其贷款意愿越高。学历层次越高的用户的存款用户成为银行贷款业务的潜在客户可能性会更大
#1.3 家庭人数
print(Bank_Personal_Loan.groupby('Family')['Personal Loan'].agg(np.mean))
sns.catplot(x='Family',data=Bank_Personal_Loan,hue='Personal Loan',kind='count')
Family
1 0.072690
2 0.081790
3 0.131683
4 0.109656
Name: Personal Loan, dtype: float64
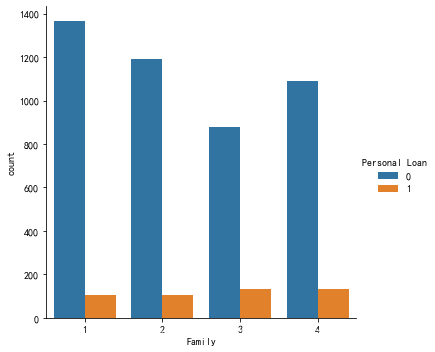
单身人士与没有孩子的家庭的贷款率都比较低,有孩子的家庭用户相对而言更有意愿转化为贷款用户,特别是独生子女家庭
#2、定量变量与开通贷款的关系(对定量变量中的年领、收入、信用卡还款额和房屋抵押贷款与是否开通贷款的关系进行探究)
#2.1.1年龄
Bank_Personal_Loan.groupby('Age')['Personal Loan'].agg(np.mean)
sns.boxenplot(x='Personal Loan',y='Age',data=Bank_Personal_Loan)
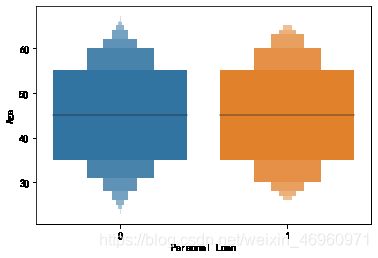
#2.1.2 对年龄分层
Bank_Personal_Loan['Income Bins']=pd.cut(Bank_Personal_Loan.Age,6)
print(Bank_Personal_Loan.groupby('Income Bins')['Personal Loan'].agg([np.mean,'count']))
Bank_Personal_Loan.groupby('Income Bins')['Personal Loan'].agg({'Loan Rate':np.mean}).plot()
mean count
Income Bins
(22.956, 30.333] 0.105769 624
(30.333, 37.667] 0.106605 863
(37.667, 45.0] 0.087209 1032
(45.0, 52.333] 0.093785 885
(52.333, 59.667] 0.086768 922
(59.667, 67.0] 0.102374 674
/home/anaconda3/lib/python3.7/site-packages/ipykernel_launcher.py:4: FutureWarning: using a dict on a Series for aggregation
is deprecated and will be removed in a future version. Use named aggregation instead.
>>> grouper.agg(name_1=func_1, name_2=func_2)
after removing the cwd from sys.path.
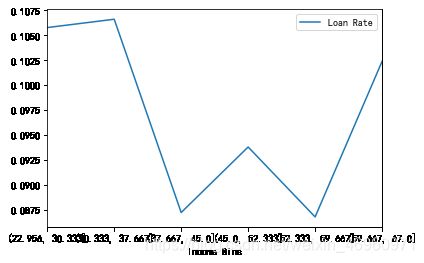
综合来看,各阶段的年龄的贷款意愿都相差不大,相对来说38岁以下和60岁以上的客户意愿较强
取平均来看,高收入的人群会比低收入的人群更愿意申请贷款
#2.2.1 收入分层
Bank_Personal_Loan['Income_bins']=pd.qcut(Bank_Personal_Loan.Income,20)
print(Bank_Personal_Loan.groupby('Income_bins')['Personal Loan'].agg([np.mean,'count']))
Bank_Personal_Loan.groupby('Income_bins')['Personal Loan'].agg({'Loan Rate':np.mean}).plot()
mean count
Income_bins
(7.999, 18.0] 0.000000 278
(18.0, 22.0] 0.000000 229
(22.0, 29.0] 0.000000 295
(29.0, 33.0] 0.000000 227
(33.0, 39.0] 0.000000 283
(39.0, 42.0] 0.000000 237
(42.0, 45.0] 0.000000 224
(45.0, 52.0] 0.000000 229
(52.0, 59.0] 0.000000 278
(59.0, 64.0] 0.007407 270
(64.0, 71.0] 0.012987 231
(71.0, 78.0] 0.008403 238
(78.0, 82.0] 0.007905 253
(82.0, 88.3] 0.043860 228
(88.3, 98.0] 0.066929 254
(98.0, 113.0] 0.179775 267
(113.0, 128.0] 0.275862 232
(128.0, 145.0] 0.395437 263
(145.0, 170.0] 0.412766 235
(170.0, 224.0] 0.526104 249
/home/anaconda3/lib/python3.7/site-packages/ipykernel_launcher.py:4: FutureWarning: using a dict on a Series for aggregation
is deprecated and will be removed in a future version. Use named aggregation instead.
>>> grouper.agg(name_1=func_1, name_2=func_2)
after removing the cwd from sys.path.
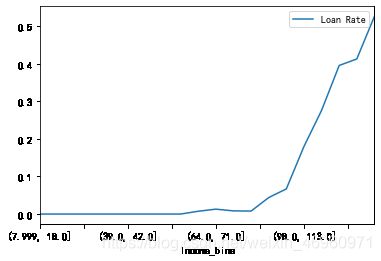
# pd.cut()根据值本身来选择箱子均匀间隔,即每个箱子的间距都是相同的
#pd.qcut()根据这些值的频率来选择箱子的均匀间隔,即每个箱子中含有的数的数量是相同的
当年收入超过82时,贷款意愿会有5倍以上的上升,超过98时,贷款意愿达到17%以上,超过170时,贷款意愿达到一半,相对收入越高,贷款的意愿越强烈
#2.3.1 房屋抵押值
print(Bank_Personal_Loan.groupby('Mortgage')['Personal Loan'].agg([np.mean,'count']))
sns.catplot('Personal Loan','Mortgage',data=Bank_Personal_Loan,kind='boxen')
mean count
Mortgage
0.0 0.090121 3462
75.0 0.125000 8
76.0 0.083333 12
77.0 0.000000 4
78.0 0.000000 15
... ... ...
590.0 1.000000 1
601.0 0.000000 1
612.0 1.000000 1
617.0 1.000000 1
635.0 0.000000 1
[347 rows x 2 columns]
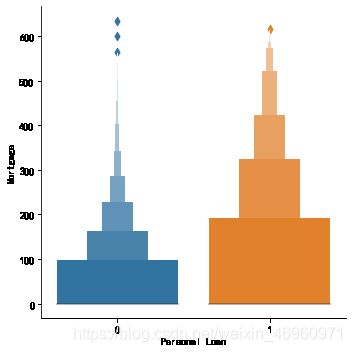
#2.3.2 对房屋抵押值分层
Bank_Personal_Loan['Mortgage Bins']=pd.cut(Bank_Personal_Loan.Mortgage,10)
print(Bank_Personal_Loan.groupby('Mortgage Bins')['Personal Loan'].agg([np.mean,'count']))
Bank_Personal_Loan.groupby('Mortgage Bins')['Personal Loan'].agg({'Loan Rate':np.mean}).plot(rot=-45)
mean count
Mortgage Bins
(-0.635, 63.5] 0.090121 3462
(63.5, 127.0] 0.043630 573
(127.0, 190.5] 0.052257 421
(190.5, 254.0] 0.114173 254
(254.0, 317.5] 0.228346 127
(317.5, 381.0] 0.324324 74
(381.0, 444.5] 0.355556 45
(444.5, 508.0] 0.333333 21
(508.0, 571.5] 0.615385 13
(571.5, 635.0] 0.800000 10
/home/anaconda3/lib/python3.7/site-packages/ipykernel_launcher.py:4: FutureWarning: using a dict on a Series for aggregation
is deprecated and will be removed in a future version. Use named aggregation instead.
>>> grouper.agg(name_1=func_1, name_2=func_2)
after removing the cwd from sys.path.

当房屋抵押值大于190.5千美元时,贷款申请的意愿有明显的提升,总体来看,抵押值越高,贷款意愿越强烈
#2.4.1 每月信用卡消费额
print(Bank_Personal_Loan.groupby('CCAvg')['Personal Loan'].agg([np.mean,'count']))
sns.catplot('Personal Loan','CCAvg',data=Bank_Personal_Loan,kind='boxen')
mean count
CCAvg
0.0 0.009434 106
0.1 0.010929 183
0.2 0.039216 204
0.3 0.024896 241
0.4 0.022346 179
... ... ...
8.8 0.111111 9
8.9 1.000000 1
9.0 1.000000 2
9.3 1.000000 1
10.0 1.000000 3
[108 rows x 2 columns]
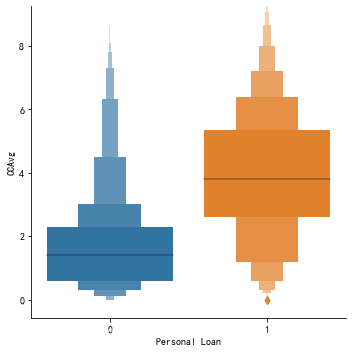
大部分没有申请贷款的,信用卡消费额的均值在1.7K美元左右,而申请贷款的客户信用款消费额均值达到3.9K美元,是其2倍有多。
#2.4.2 对每月消费额进行分层
Bank_Personal_Loan['CCAvg Bins']=pd.cut(Bank_Personal_Loan.CCAvg,20)
Bank_Personal_Loan.groupby('CCAvg Bins')['Personal Loan'].agg([np.mean,'count'])
Bank_Personal_Loan.groupby('CCAvg Bins')['Personal Loan'].agg({'Loan Rate':np.mean}).plot()
/home/anaconda3/lib/python3.7/site-packages/ipykernel_launcher.py:4: FutureWarning: using a dict on a Series for aggregation
is deprecated and will be removed in a future version. Use named aggregation instead.
>>> grouper.agg(name_1=func_1, name_2=func_2)
after removing the cwd from sys.path.
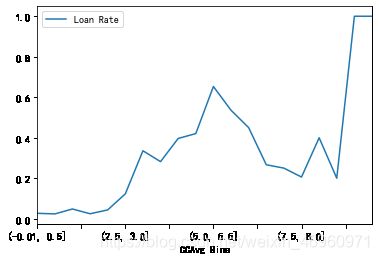
大概在每月消费额为2.8千美元时,申请贷款率会增大将近4倍,超过6千美元时,申请申请贷款率会有所回落到31%左右,但这个贷款意愿相对还是很强烈的,可对每月消费额在2.8千美元以上的客户加大力度去营销
4、结论
-
通过这次活动,个人贷款业务增长了近10%,说明此次推广活动的效果还是不错的
-
对于开通了银行账户的用户需要加强营销力度,他们的贷款意愿相对于没有开通银行账户更强
-
教育水平越高的客户越容易接受贷款
-
家庭人口较多的家庭贷款意愿较强,尤其是独生子女的家庭
-
年龄区间在30-40岁的客户相对贷款意愿更强
-
相对收入越高,贷款的意愿越强烈, 当年收入超过82k时,贷款意愿会有5倍以上的上升,超过98k时,贷款意愿达到17%以上,超过170k时,贷款意愿达到一半
-
当房屋抵押值大于190.5k美元时,贷款申请的意愿有明显的提升
-
每月消费额在2.8k美元以上的客户,贷款申请的意愿有明显的提升