jsoup 框架的使用指南
概述
参考:
- 官方文档
- jsoup的使用
- JSoup教程
- jsoup 在 GitHub 的开源代码
概念简介
jsoup 是一款基于 Java 的 HTML 解析器,它提供了一套非常省力的 API,不但能直接解析某个 URL 地址、HTML 文本内容,而且还能通过类似于 DOM、CSS 或者 jQuery 的方法来操作数据,所以 jsoup 也可以被当做爬虫工具使用。
jsoup 实现 WHATWG HTML5 规范,并将 HTML 解析为与现代浏览器相同的 DOM。
-
从 URL,文件或字符串中提取并解析 HTML
查找和提取数据,使用 DOM 遍历或 CSS 选择器
-
操纵 HTML元素,属性和文本
-
根据安全的白名单清理用户提交的内容,以防止 XSS 攻击
-
输出整洁的 HTML
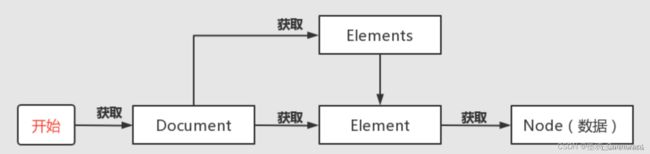
相关概念简介
-
Document :文档对象
每份 HTML 页面都是一个文档对象,Document 是 jsoup 体系中最顶层的结构。
-
Element:元素对象。
一个 Document 中可以着包含着多个 Element 对象,可以使用 Element 对象来遍历节点提取数据或者直接操作 HTML。
-
Elements:元素对象集合,类似于
List。 -
Node:节点对象。
标签名称、属性等都是节点对象,节点对象用来存储数据。
-
类继承关系:Document 继承自 Element ,Element 继承自 Node。
-
一般执行流程:先获取 Document 对象,然后获取 Element 对象,最后再通过 Node 对象获取数据。
依赖
<dependency>
<groupId>org.jsoupgroupId>
<artifactId>jsoupartifactId>
<version>1.15.4version>
dependency>
jsoup 的主要类
虽然完整的类库中有很多类,但大多数情况下,需要重点了解下面给出3 个类即可
-
org.jsoup.Jsoup 类
Jsoup 类是任何 Jsoup 程序的入口点,并将提供从各种来源加载和解析 HTML 文档的方法。
Jsoup 类的一些重要方法如下:
// 创建并返回URL的连接。 static Connection connect(String url) // 将指定的字符集文件解析成文档。 static Document parse(File in, String charsetName) // 将给定的html代码解析成文档。 static Document parse(String html) // 从本地文件中加载文档对象 static Document parse(File in, String charsetName) // 从输入 HTML 返回安全的 HTML,通过解析输入 HTML 并通过允许的标签和属性的白名单进行过滤。 static String clean(String bodyHtml, Whitelist whitelist) -
org.jsoup.nodes.Document 类
该类表示通过 Jsoup 库加载 HTML 文档。
可以使用此类执行适用于整个 HTML 文档的操作。
-
org.jsoup.nodes.Element 类
HTML 元素是由标签名称,属性和子节点组成。 使用 Element 类,可以提取数据,遍历节点和操作 HTML。
-
注:继承关系为 Document extends Element extends Node
API
Jsoup 类
Jsoup 类的一些重要方法如下:
// 创建并返回URL的连接。
static Connection connect(String url)
// 将指定的字符集文件解析成文档。
static Document parse(File in, String charsetName)
// 将给定的html代码解析成文档。
static Document parse(String html)
// 从本地文件中加载文档对象
static Document parse(File in, String charsetName)
// 从输入 HTML 返回安全的 HTML,通过解析输入 HTML 并通过允许的标签和属性的白名单进行过滤。
static String clean(String bodyHtml, Whitelist whitelist)
Connection 接口
// 将请求作为GET执行,并解析结果
Document get() throws IOException;
// 将请求作为POST执行,并解析结果。
Document post() throws IOException;
// 执行请求。获取内容包含响应码等
Connection.Response execute() throws IOException;
// 将请求方法设置为使用GET或POST。默认为GET
Connection method(Connection.Method method);
// 创建一个新请求,使用此Connection作为会话状态并初始化连接设置(然后可以独立于返回的Connection.request对象)
Connection newRequest();
// 设置要提取的请求URL。协议必须是HTTP或HTTPS
Connection url(URL url);
Connection url(String url);
// 设置头部信息
Connection header(String name, String value);
Connection headers(Map<String, String> headers);
// 发出请求的用户信息
Connection userAgent(String userAgent);
// 先前网页的地址,当前请求网页紧随其后,即来路
Connection referrer(String referrer);
// 设置用于此请求的HTTP代理。设置为null禁用以前设置的代理。
Connection proxy(Proxy proxy);
Connection proxy(String host, int port);
// 设置总请求超时时间。如果发生超时SocketTimeoutException将被抛出。默认超时为30秒(30000ms)。零超时被视为无限超时。
// 注意,此超时指定连接时间和读取完整响应时间的组合最长持续时间
Connection timeout(int millis);
// 在关闭连接和截断输入之前,设置从(未压缩)连接读取到正文的最大字节数(即正文内容将被修剪)。
// 默认最大值为2MB。最大大小为0被视为无限量(仅受机器上可用内存的限制)。
Connection maxBodySize(int bytes);
// 设置是否遵循服务器重定向的连接。默认为true
Connection followRedirects(boolean followRedirects);
// 将连接配置为在发生HTTP错误时不引发异常(4xx-5xx,例如404或500)。默认为false;,如果遇到错误,将引发IOException。
// 如果设置为true,响应将填充错误正文,状态消息将反映错误。
Connection ignoreHttpErrors(boolean ignoreHttpErrors);
// 分析响应时忽略文档的Content-Type。默认为false,未识别的内容类型将引发IOException。(例如,为了防止试图解析JPEG二进制图像而产生垃圾。)设置为true可强制解析尝试,而不管内容类型如何。
Connection ignoreContentType(boolean ignoreContentType);
// 设置自定义SSL套接字工厂
Connection sslSocketFactory(SSLSocketFactory var1);
// 添加请求数据参数。请求参数在GET的请求查询字符串中发送,在POST的请求正文中发送。一个请求可能有多个同名值。
Connection data(String key, String value);
// 添加输入流作为请求数据参数。
Connection data(String key, String filename, InputStream inputStream);
// 添加输入流作为请求数据参数。对于GET,没有影响,但对于POST,这将上载输入流。filename为文件名,不是路径
Connection data(String key, String filename, InputStream InputStream, String contentType);
Connection data(Collection<Connection.KeyVal> data);
Connection data(Map<String, String> data);
Connection data(String... keyvals);
// 获取此密钥的数据KeyVal(如果有)
Connection.KeyVal data(String var1);
// 设置要在请求中发送的cookie
Connection cookie(String name, String value);
Connection cookies(Map<String, String> cookies);
// 获取此连接使用的cookie存储
Connection cookieStore(CookieStore cookieStore);
// 提供自定义或预先填充的CookieStore,用于此连接发出的请求。
CookieStore cookieStore();
// 提供在分析文档响应时使用的备用解析器
Connection parser(Parser parser);
// 设置请求的数据字符集,默认x-www-form-urlencoded
Connection postDataCharset(String charset);
// 设置连接请求
Connection request(Connection.Request var1);
// 设置POST(或PUT)请求主体
Connection requestBody(String body);
// 获取与此连接关联的请求对象
Connection.Request request();
// 设置连接的响应
Connection response(Connection.Response response);
// 执行请求后,获取响应。
Connection.Response response();
Element(元素)类
org.jsoup.nodes.Element extends Node
Elements 对象提供了一系列类似于 DOM 的方法来查找元素,抽取并处理其中的数据。
查找元素
// 通过 id 来查找元素
public Element getElementById(String id)
// 通过标签来查找元素
public Elements getElementsByTag(String tag)
// 通过类选择器来查找元素
public Elements getElementsByClass(String className)
// 通过属性名称来查找元素,例如查找带有 href 元素的标签
public Elements getElementsByAttribute(String key)
// 获取兄弟元素。如果元素没有兄弟元素,则返回一个空列表
public Elements siblingElements()
// 获取第一个兄弟元素
public Element firstElementSibling()
// 获取最后一个兄弟元素
public Element lastElementSibling()
// 获取下一个兄弟元素
public Element nextElementSibling()
// 获取上一个兄弟元素
public Element previousElementSibling()
// 获取此节点的父节点
public Element parent()
// 获取此节点的所有子节点
public Elements children()
// 获取此节点的指定子节点
public Element child(int index)
// 使用 CSS 选择器查找元素
public Elements select(String cssQuery)
获取元素数据
在获得文档对象并且指定查找元素后,就可以获取元素中的数据。
注:这些访问器方法都有相应的 setter 方法来更改数据。
// 获取单个属性值
public String attr(String key)
// 获取所有属性值
public Attributes attributes()
// 设置属性值
public Element attr(String key, String value)
// 获取文本内容
public String text()
// 设置文本内容
public Element text(String value)
// 获取元素内的 HTML 内容
public String html()
// 设置元素内的 HTML 内容
public Element html(String value)
// 获取元素外 HTML 内容
public String outerHtml()
// 获取数据内容(例如:script 和 style 标签)
public String data()
// 获得 id 值(例如:衣服
)
public String id()
// 检查这个元素是否含有一个类选择器(不区分大小写)
public boolean hasClass(String className)
// 获得第一个类选择器值
public String className()
// 获得所有的类选择器值
public Set<String>classNames()
// 获取元素标签
public Tag tag()
// 获取元素标签名(例如:``、`
` 等)
public String tagName()
修改数据
在解析了一个 Document 对象之后,可能想修改其中的某些属性值,并把它输出到前台页面或保存到其他地方,jsoup 对此提供了一套非常简便的接口(支持链式写法)。
-
设置属性的值
以下方法当针对 Element 对象操作时,只有一个元素会受到影响。当针对 Elements 对象进行操作时,可能会影响到多个元素。
// 设置标签的属性值
public Element attr(String key, String value)
// 删除标签
public Element removeAttr(String key)
// 增加类选择器选项
public Element addClass(String className)
// 删除对应的类选择器
public Element removeClass(String className)
代码示例:
Document doc = Jsoup.connect("http://csdn.com").get();
// 复数,Elements
Elements elements = doc.getElementsByClass("text");
// 单数,Element
Element element = elements.first();
// 复数对象,所有 class="text" 的元素都将受到影响
elements.attr("name","goods");
// 单数对象,只有一个元素会受到影响(链式写法)
element.attr("name","shop").addClass("red");
-
修改元素的 HTML 内容
可以使用 Element 中的 HTML 设置方法,具体如下:
// 在末尾追加 HTML 内容
public Element append(String html)
// 在开头追加 HTML 内容
public Element prepend(String html)
// 在匹配元素内部添加 HTML 文本。这个方法将先清除元素中的 HTML 内容,然后用传入的 HTML 代替
public Element html(String value)
// 对元素包裹一个外部 HTML 内容,将元素置于新增的内容中间
public Element wrap(String value)
示例代码:
Document doc = Jsoup.connect("http://csdn.com").get();
Element div = doc.select("div").first();
div.html("csdn
");
div.prepend("a
");
div.append("good
");
// 输出: a
csdn
good
Element span = doc.select("span").first();
span.wrap(" csdn
修改元素的文本内容
对于传入的文本,如果含有像 <, > 等这样的字符,将以文本处理,而非 HTML。
// 清除元素内部的 HTML 内容,然后用提供的文本代替
public Element text(String text)
// 在元素后添加文本节点
public Element prepend(String first)
// 在元素前添加文本节点
public Element append(String last)
示例代码:
//
Element div = doc.select("div").first();
div.text(" one ");
div.prepend(" two ");
div.append(" three ");
// 输出: two one three
基本使用
获取文档(Document)
获得文档对象 Document 一共有 4 种方法,分别对应不同的获取方式。
-
从URL中加载文档对象(常用)
使用
Jsoup.connect(String url).get()方法获取(只支持 http 和 https 协议):Document doc = Jsoup.connect("http://csdn.com/").get(); String title = doc.title();connect(String url)方法创建一个新的 Connection 并通过.get()或者.post()方法获得数据。- 如果从该URL获取 HTML 时发生错误,便会抛出 IOException,应适当处理。
Connection接口还提供一个方法链来解决特殊请求,可以在发送请求时带上请求的头部参数。示例代码:Document doc = Jsoup.connect("http://csdn.com") .data("query", "Java") .userAgent("Mozilla") .cookie("auth", "token") .timeout(8000) .post();可以使用
execute()方法获得完整的响应对象和响应码:// 获得响应对象 Connection.Response response = Jsoup.connect("http://csdn.com").execute(); // 获取状态码 int code = response.statusCode(); -
从本地文件中加载文档对象
可以使用静态的
Jsoup.parse(File in, String charsetName)方法从文件中加载文档。其中in表示路径,charsetName表示编码方式。示例代码:File input = new File("/tmp/input.html"); Document doc = Jsoup.parse(input, "UTF-8"); -
从字符串文本中加载文档对象
使用静态的
Jsoup.parse(String html)方法可以从字符串文本中获得文档对象 Document 。示例代码:String html = "First parse " + "Parsed HTML into a doc.
"; Document doc = Jsoup.parse(html); -
从
片断中获取文档对象使用
Jsoup.parseBodyFragment(String html)方法,示例代码:String html = "Lorem ipsum.
"; Document doc = Jsoup.parseBodyFragment(html); // doc 此时为:Lorem ipsum.
Element body = doc.body();- parseBodyFragment 方法创建一个新的文档,并插入解析过的 HTML 到 body 元素中。
- 虽然使用正常的 Jsoup.parse(String html) 方法,通常也能得到相同的结果,但是明确将用户输入作为 body 片段处理是个更好的方式。
- Document.body() 方法能够取得文档 body 元素的所有子元素,与 doc.getElementsByTag(“body”) 相同。
选择元素(Element)
解析文档对象并获取数据一共有 2 种方式,分别为 DOM方式、CSS 选择器方式,可以选择一种自己喜欢的方式去获取数据,效果一样。
DOM 方式
将 HTML 解析成一个 Document 之后,就可以使用类似于 DOM 的方法进行操作。
常用方法详见 Element(元素)类 API
示例代码:
// 获取 csdn 首页所有的链接
Document doc = Jsoup.connect("http://csdn.com").get();
Elements elements = doc.getElementsByTag("body");
Elements contents = elements.first().getElementsByTag("a");
for (Element content : contents) {
String linkHref = content.attr("href");
String linkText = content.text();
}
CSS 选择器方式
可以使用类似于 CSS 选择器的语法来查找和操作元素,常用的方法为 select(String cssQuery)
示例代码:
Document doc = Jsoup.connect("http://csdn.com").get();
// 获取带有 href 属性的 a 元素
Elements elements = doc.select("a[href]");
for (Element content : elements) {
String linkHref = content.attr("href");
String linkText = content.text();
}
select()方法在Document、Element或Elements对象中都可以使用,而且是上下文相关的,因此可实现指定元素的过滤,或者采用链式访问。select()方法将返回一个Elements集合,并提供一组方法来抽取和处理结果。
select(String cssQuery) 方法参数简介
-
#id:通过 ID 查找元素,比如通过#logo查找 -
.class:通过 class 名称查找元素,比如通过.titile查找 -
ns|tag:通过标签在命名空间查找元素,比如使用fb|name来查找 -
[^attribute]:利用属性名前缀来查找元素,比如:可以用[^data-]来查找带有HTML5 dataset属性的元素 -
[attribute=value]:利用属性值来查找元素,比如:[width=500] -
[attribute^=value],[attribute$=value],[attribute*=value]:利用匹配属性值开头、结尾或包含属性值来查找元素,比如通过[href*=/path/]来查找 -
[attribute~=regex]:利用属性值匹配正则表达式来查找元素比如通过
img[src~=(?i)\.(png|jpe?g)]来匹配所有的png 或者 jpg、jpeg 格式的图片 -
*:通配符,匹配所有元素
参数属性组合使用
-
el#id:元素 + ID,比如:div#logo -
el.class:元素 + class,比如:div.masthead -
el[attr]:元素 + class,比如:a[href]匹配所有带有 href 属性的 a 元素 -
任意组合,比如:
a[href].highlight匹配所有带有 href 属性且 class=“highlight” 的 a 元素。 -
ancestor child:查找某个元素下子元素比如:可以用
.body p查找在 “body” 元素下的所有 p 元素 -
parent > child:查找某个父元素下的直接子元素比如:可以用
div.content > p查找p元素,也可以用body > *查找 body 标签下所有直接子元素 -
siblingA + siblingB:查找在 A 元素之前第一个同级元素 B,比如:div.head + div -
siblingA ~ siblingX:查找 A 元素之前的同级 X 元素,比如:h1 ~ p -
el, el, el:多个选择器组合,查找匹配任一选择器的唯一元素,例如:div.masthead, div.logo
特殊参数:伪选择器
-
:lt(n):查找哪些元素的同级索引值(它的位置在 DOM 树中是相对于它的父节点)小于 n比如:
td:lt(3)表示小于三列的元素 -
:gt(n):查找哪些元素的同级索引值大于n,比如:div p:gt(2)表示哪些 div 中有包含 2 个以上的 p 元素 -
:eq(n):查找哪些元素的同级索引值与n相等,比如:form input:eq(1)表示包含一个 input 标签的 Form元素 -
:has(seletor):查找匹配选择器包含元素的元素,比如:div:has(p)表示哪些 div 包含了 p 元素 -
:not(selector):查找与选择器不匹配的元素,比如:div:not(.logo)表示不包含 class=logo 元素的所有 div 列表 -
:contains(text):查找包含给定文本的元素,搜索不区分大不写,比如:p:contains(jsoup) -
:containsOwn(text):查找直接包含给定文本的元素(不包含任何它的后代) -
:matches(regex):查找哪些元素的文本匹配指定的正则表达式,比如:div:matches((?i)login) -
:matchesOwn(regex):查找直接包含文本匹配指定正则表达式的元素(不包含任何它的后代)
注意:上述伪选择器索引是从 0 开始的,即第一个元素索引值为 0,第二个元素 index 为 1 等
其他功能
一些常用数据的获取
-
从 HTML 获取标题
Document document = Jsoup.parse( new File("C:/Users/xyz/Desktop/yiibai-index.html"), "utf-8"); System.out.println(document.title()); -
获取 HTML 页面的 Fav 图标
假设
favicon图像将是 HTML 文档的部分中的第一个图像String favImage = "Not Found"; try { Document document = Jsoup.parse(new File("C:/Users/zkpkhua/Desktop/yiibai-index.html"), "utf-8"); Element element = document.head().select("link[href~=.*\\.(ico|png)]").first(); if (element == null) { element = document.head().select("meta[itemprop=image]").first(); if (element != null) { favImage = element.attr("content"); } } else { favImage = element.attr("href"); } } catch (IOException e) { e.printStackTrace(); } System.out.println(favImage); -
获取 HTML 页面中的所有链接
try { Document document = Jsoup.parse(new File("C:/Users/zkpkhua/Desktop/yiibai-index.html"), "utf-8"); Elements links = document.select("a[href]"); for (Element link : links) { System.out.println("link : " + link.attr("href")); System.out.println("text : " + link.text()); } } catch (IOException e) { e.printStackTrace(); } -
获取 HTML 页面中的所有图像
try { Document document = Jsoup.parse(new File("C:/Users/zkpkhua/Desktop/yiibai-index.html"), "utf-8"); Elements images = document.select("img[src~=(?i)\\.(png|jpe?g|gif)]"); for (Element image : images) { System.out.println("src : " + image.attr("src")); System.out.println("height : " + image.attr("height")); System.out.println("width : " + image.attr("width")); System.out.println("alt : " + image.attr("alt")); } } catch (IOException e) { e.printStackTrace(); } -
获取 URL 的元信息
元信息包括 Google 等搜索引擎用来确定网页内容的索引为目的。它们以 HTM L页面的
HEAD部分中的一些标签的形式存在。try { Document document = Jsoup.parse(new File("C:/Users/zkpkhua/Desktop/yiibai-index.html"), "utf-8"); String description = document.select("meta[name=description]").get(0).attr("content"); System.out.println("Meta description : " + description); String keywords = document.select("meta[name=keywords]").first().attr("content"); System.out.println("Meta keyword : " + keywords); } catch (IOException e) { e.printStackTrace(); } -
在 HTML 页面中获取表单属性
在网页中获取表单输入元素非常简单。 使用唯一 ID 查找 FORM 元素; 然后找到该表单中存在的所有 INPUT 元素。
Document doc = Jsoup.parse(new File("c:/temp/yiibai-index.html"),"utf-8"); Element formElement = doc.getElementById("loginForm"); Elements inputElements = formElement.getElementsByTag("input"); for (Element inputElement : inputElements) { String key = inputElement.attr("name"); String value = inputElement.attr("value"); System.out.println("Param name: " + key + " \nParam value: " + value); }
相对路径转绝对路径
-
在 HTML 元素中,URLs 经常写成相对于文档位置的相对路径,如:
...。当使用 .attr(String key) 方法来取得 a 元素的 href 属性时,它将直接返回在 HTML 源码中指定的值。
-
如果需要取得一个绝对路径,有两种方式:
- 方式1:在属性名前加
abs:前缀,就可以返回包含根路径的 URL 地址attr("abs:href") - 方式2:使用 absUrl(String key) 方法
- 方式1:在属性名前加
示例场景
-
问题描述:
有一个包含相对 URLs 路径的 HTML 文档,现在需要将这些相对路径转换成绝对路径的URLs
-
解决方式:
- 确保在解析文档时有指定
base URI路径。 - 然后使用
abs:属性前缀来取得包含base URI的绝对路径。
示例代码:
Document doc = Jsoup.connect("http://www.open-open.com").get(); Element link = doc.select("a").first(); String relHref = link.attr("href"); // 输出:/ String absHref = link.attr("abs:href"); // 输出:http://www.open-open.com/ - 确保在解析文档时有指定
消除不受信任的HTML (防止XSS攻击)
-
假设在应用程序中,想显示用户提交的 HTML 片段。
例如用户可以在评论框中放入 HTML 内容。 这可能会导致非常严重的问题,如果允许直接显示此 HTML。 用户可以在其中放入一些恶意脚本,并将用户重定向到另一个脏网站。
-
为了清理这个 HTML,Jsoup 提供
Jsoup.clean()方法。此方法期望 HTML 格式的字符串,并将返回清洁的 HTML。
要执行此任务,Jsoup 使用白名单过滤器。 jsoup 白名单过滤器通过解析输入 HTML(在安全的沙盒环境中)工作,然后遍历解析树,只允许将已知安全的标签和属性(和值)通过清理后输出。
它不使用正则表达式,这对于此任务是不合适的。
清洁器不仅用于避免 XSS,还限制了用户可以提供的元素的范围:可以使用文本,强元素,但不能构造
div或表元素。
示例场景
-
问题描述:
在某些网站中经常会提供用户评论的功能,但是有些不怀好意的用户,会搞一些脚本到评论内容中,而这些脚本可能会破坏整个页面的行为,更严重的是获取一些机要信息,此时需要清理该 HTML,以避免跨站脚本攻击(XSS)。
-
解决方式:
使用 clean() 方法清除恶意代码,但需要指定一个配置的 Safelist(旧版本中是 Whitelist),通常使用 Safelist.basic() 即可。
Safelist 的工作原理是将输入的 HTML 内容单独隔离解析,然后遍历解析树,只允许已知的安全标签和属性输出。
示例代码:
String unsafe = ""; String safe = Jsoup.clean(unsafe, Safelist.basic()); // 输出: -
注:
- jsoup 的
Safelist不仅能够在服务器端对用户输入的 HTML 进行过滤,只输出一些安全的标签和属性,还可以限制用户可以输入的标签范围。
- jsoup 的
jsoup 使用代理
-
示例代码:
Connection.Response execute = Jsoup.connect("http://csdn.net/") .proxy("12.12.12.12", 1080) // 使用代理 .execute();