学习weka(3):idea中集成weka
一、前期准备
1、加入依赖
百度搜索 maven,找到 maven 的 repository 仓库,寻找 weka 的依赖包:
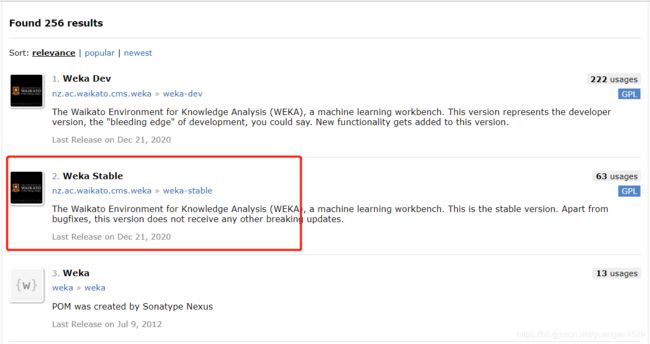
找到稳定版本(我下载 weka 软件的时候就是这个版本,没有犹豫,就是它了),点击进去选择对应版本,依然是和自己软件版本一致:
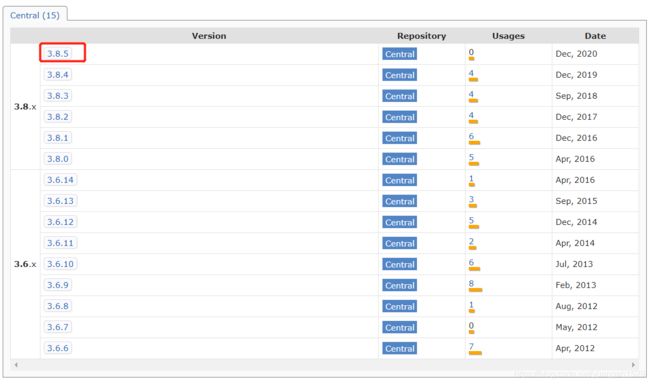
点击进去可以看到对应的依赖语句代码了,当然也可以下载 jar 包,不过能偷懒就偷懒一下吧:

<dependency>
<groupId>nz.ac.waikato.cms.weka</groupId>
<artifactId>weka-stable</artifactId>
<version>3.8.5</version>
</dependency>
2、新建 spring 项目,加入 weka 依赖
这里我创建的是 SpringBoot 项目,具体过程就不说了,超级简单。
创建一个 test 包,在建一个相关类就可以开始搞起了。
3、初步尝试
在网上找了半天,发现 weka 的实例代码比较少,搜关键词一大半网页都是软件 weka 的介绍,不得不说 java 搞 weka 实在是太过于小众了。
最终,皇天不负有心人,还是找到了一个代码实例:
public class test {
public static void main(String[] args) {
Instances ins = null;
Classifier cfs = null;
try {
// read the training set
File file = new File("D:\\weka\\Weka-3-8-5\\data\\weather.numeric.arff");
ArffLoader loader = new ArffLoader(); //ArffLoader类是weka.core.converters下的
loader.setFile(file);
ins = loader.getDataSet();
System.out.println(ins.numAttributes());
ins.setClassIndex(ins.numAttributes() - 1);
// 初始化分类器
cfs = (Classifier) Class.forName("weka.classifiers.bayes.NaiveBayes").newInstance();
// 使用训练集对数据集训练
cfs.buildClassifier(ins);
// 使用测试数据集测试分类器的性能
Instance testInst;
Evaluation testingEvaluation = new Evaluation(ins);
int length = ins.numInstances(); //得到数据集样本个数
for (int i = 0; i < length; i++) {
testInst = ins.instance(i);
testingEvaluation.evaluateModelOnceAndRecordPrediction(cfs, testInst);
}
// print the classifying results
System.out.println("分类正确率:" + (1 - testingEvaluation.errorRate()));
} catch (Exception e) {
e.printStackTrace();
}
}
}
有了代码实例,接下来就相对容易一些,至少有一个大体框架的实例可供参考。
二、逐步提升
1、任务:加载 arff 文件、csv 与 arff 文件之间转换
加载 arff 的两种方法:
//方法一:使用DataSource类的read方法来加载arff文件
Instances data1=DataSource.read("data/weather.nominal.arff");
//方法二:使用直接制定加载器的方法来加载Arff文件
ArffLoader arffLoader=new ArffLoader();//创建ArffLoader实例
arffLoader.setSource(new File("data/weather.nominal.arff"));
Instances data2=arffLoader.getDataSet();
将 arff 保存为 csv 文件:
//方法一
Instances data=new Instances(DataSource.read("data/weather.nominal.arff"));
DataSink.write("data/weather.csv", data);
//方法二:明确指定转换器,保存为csv文件
CSVSaver saver=new CSVSaver();
saver.setInstances(data);
saver.setFile(new File("data/weather2.csv"));
saver.writeBatch();
将 csv 文件保存为 arff 文件:
Instances allData = DataSource.read("E:\\dataset\\clusterData\\wine.csv");
ArffSaver saver = new ArffSaver();
saver.setInstances(allData);
saver.setFile(new File("E:\\dataset\\clusterData\\wine.arff"));
saver.writeBatch();
System.out.println("已经转化为arrf文件");
2、任务:切分数据集
代码例子中训练集和测试集用的都是同一个数据,这个就有点搞笑了,第一步认为暂定为学习切分数据集,至少也要有合适的训练集和测试集。
切分代码如下:
//读取
Instances trainingSet = DataSource.read(path);
//打乱顺序,因为后面要进行截取
trainingSet.randomize(new Random(0));
//训练集:测试集=4:1
int trainSize = (int) Math.round(trainingSet.numInstances() * 0.80);
int testSize = trainingSet.numInstances() - trainSize;
//从数据集中进行截取
Instances train = new Instances(trainingSet, 0, trainSize);
Instances test = new Instances(trainingSet, trainSize, testSize);
3、任务:修改测试数据一条一条进行测试
划分好了训练数据和测试数据,本打算将这个测试数据一起进行评估,结果报错如下:

查看源代码,找到原因在于 evaluateModelOnceAndRecordPrediction 函数本身只接受一条记录:
public double evaluateModelOnceAndRecordPrediction(double[] dist, Instance instance) throws Exception {
return this.m_delegate.evaluateModelOnceAndRecordPrediction(dist, instance);
}
通过查看源代码,找到了一个可以一次性评估整个数据集的:
public double[] evaluateModel(Classifier classifier, Instances data, Object... forPredictionsPrinting) throws Exception {
return this.m_delegate.evaluateModel(classifier, data, forPredictionsPrinting);
}
除了查看源代码,也可以通过输入 Evaluation 加点的方式查看评估器对象有哪些函数,主要看函数参数里面有 classifier 同时还有 Instances 的,如果有,再看看函数名,基本上就可以确定。
最终原代码中的 for 循环测试,修改如下:
testingEvaluation.evaluateModel(cfs,test);
测试了一下,准确率和一条条测试一模一样。
4、任务:测试模型几种模式
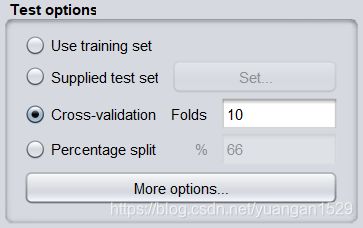
如上图所示,在 weka 软件上,测试模型分为四种方法,那么对应的使用 java 代码也可以还原上面四种方法。
(1)Use traning set
第一种方法就是从网上搬运过来的原版代码——使用训练数据测试模型:
for (int i = 0; i < length; i++) {
testInst = ins.instance(i); //ins是数据集,既是训练数据也是测试数据
testingEvaluation.evaluateModelOnceAndRecordPrediction(cfs, testInst);
}
(2)Supplied test set
也就是重新加载一个新的数据集作为测试集,这个比较简单,仿照着数据集加载模式再来一次即可:
File file = new File("你的测试数据集所在目录");
ArffLoader loader = new ArffLoader(); //ArffLoader类是weka.core.converters下的
loader.setFile(file);
Instances test = loader.getDataSet();
(3)Cross-validation
也就是交叉验证,这个原理大概说一下:
将整个数据集分为 k 份(也叫 k 折),做 k 次试验,每次取其中 k-1 份作为训练数据,另外一份作为测试数据,最后综合 k 次试验的结果来验证模型。
要进行交叉验证,要使用 Evaluation 类,该类就是用来评估测试机器学习模型的。
Evaluation 评估器有两种评估方法:
- 如果测试集和训练集没有分开,可以使用 crossValidateModel 方法,Evaluation 中crossValidateModel方法的四个参数分别为:
- 第一个是分类器
- 第二个是整个数据集(前面提到了测试集和训练集没有分开才使用这个)
- 第三个参数是交叉检验的次数(10 是比较常见的)
- 第四个是一个随机数对象。
- 如果有训练集和测试集,可以使用 Evaluation 类中的 evaluateModel 方法,方法中的参数为:第一个为一个训练过的分类器,第二个参数是测试数据集。
我们所说的交叉验证就是指第一种方法,也就是采用 crossValidateModel 方法进行测试,先看一下源代码:
//创建分类器
J48 classifier = new J48();
Evaluation eval = new Evaluation( m_instances );
eval.crossValidateModel( classifier, m_instances, 10, new Random(1));
System.out.println(eval.toClassDetailsString());
System.out.println(eval.toSummaryString());
System.out.println(eval.toMatrixString());
问题一
这里有一个疑问的地方,就是评估器在构建对象的时候,需要一个数据集,那么这个数据集有什么用?必须是训练数据,还说什么数据集都可以?
我查看了一下源代码(在安装目录 Weka-3-8-5/doc/index.html):

大家可以看到,data 参数的目的是为了获取信息的头部(估计是第一行信息,也就是特征名称)还有先验标签分布信息。
所有说,只要有这两个特征数据集即可,不过最好还是训练集为佳,毕竟这个先验标签分布信息不好说。
问题二
在网上查找代码的时候,发现一部分人在使用交叉验证的时候,用了 for 循环,而有的则没有使用,我上面的代码实例是后者,使用 for 循环的代码如下:
//直接调用Evaluation即可完成
Evaluation eval = null;
for (int i = 0; i < 10; i++) {
eval = new Evaluation(Train);
eval.crossValidateModel(m_classifier, Train, 10, new Random(i),
args);// 实现交叉验证模型
}
System.out.println(eval.toSummaryString());// 输出总结信息
System.out.println(eval.toClassDetailsString());// 输出分类详细信息
System.out.println(eval.toMatrixString());// 输出分类的混淆矩阵
到底用不用 for 循环,我特意查看了一下 crossValidateModel 函数的源代码(按住 Ctrl+点击鼠标),有这么一段代码:
for(int i = 0; i < numFolds; ++i) {
Instances train = data.trainCV(numFolds, i, random);
this.setPriors(train);
Classifier copiedClassifier = AbstractClassifier.makeCopy(classifier);
copiedClassifier.buildClassifier(train);
if (classificationOutput == null && forPrinting.length > 0) {
((StringBuffer)forPrinting[0]).append("\n=== Classifier model (training fold " + (i + 1) + ") ===\n\n" + copiedClassifier);
}
Instances test = data.testCV(numFolds, i);
if (classificationOutput != null) {
this.evaluateModel(copiedClassifier, test, forPrinting);
} else {
this.evaluateModel(copiedClassifier, test);
}
}
可以看到,crossValidateModel 方法中本身进行了一个 for 循环,每次循环生成一次训练集和测试集(基于第二个参数),还有分类器,在评估分类器时,本质还是调用的 evaluateModel 方法。
问题三
交叉验证的目的是什么?很多帖子都说是用来测试模型的,但是交叉验证中本身是有训练过程的,你测试模型过程中,又训练了模型(会使模型参数发生变化),那么交叉验证完后的模型还是原来的模型吗?或者说你测试的模型还是原来的模型吗?
这个问题,在一个帖子上找到了答案:
交叉验证本身不是用来选择模型的,或者说它不单单是用来选择模型的,它集成了训练、测试和选择模型三个过程。
(4)percentage split
这个就是按照比例切分了,代码如下:
//打乱顺序,保证切分样本的随机性
dataSet.randomize(new Random(0));
//训练集:测试集=4:1
int trainSize = (int) Math.round(dataSet.numInstances() * 0.80);
int testSize = dataSet.numInstances() - trainSize;
//从数据集中进行截取
Instances train = new Instances(dataSet, 0, trainSize);
Instances test = new Instances(dataSet, trainSize, testSize);
5、任务:初始化分类器与配置参数
初始化分类器:
// 初始化分类器,以下三种方法都可以
cfs = (Classifier) Class.forName("weka.classifiers.bayes.NaiveBayes").newInstance();
J48 cfs = new J48(); //推荐使用该种方法,因为简单,而且配置参数也容易
cfs = new weka.classifiers.trees.J48();
分类器说好了,再来说一下配置参数问题,这个折腾了半天,主要是网上的资料太少了,找到一个源代码,还是错误的:
String[] options ={"-B true"};
J48 classifier = new J48();
classifier.setOptions(options);
运行上述代码会报错如下:

根据错误提示,显然是配置参数格式有问题,于是开始查看 setOptions 方法源代码:
public void setOptions(java.lang.String[] options)
throws java.lang.Exception
Parses a given list of options. Valid options are:
-U:Use unpruned tree.
-O:Do not collapse tree.
-C <pruning confidence>
Set confidence threshold for pruning.
(default 0.25)
-M <minimum number of instances>
Set minimum number of instances per leaf.
(default 2)
-R:Use reduced error pruning.
-N <number of folds>
Set number of folds for reduced error
pruning. One fold is used as pruning set.
(default 3)
-B:Use binary splits only.
-S:Don't perform subtree raising.
-L:Do not clean up after the tree has been built.
-A:Laplace smoothing for predicted probabilities.
-J:Do not use MDL correction for info gain on numeric attributes.
-Q <seed>
Seed for random data shuffling (default 1).
-doNotMakeSplitPointActualValue
Do not make split point actual value.
Specified by:
setOptions in interface OptionHandler
Overrides:
setOptions in class AbstractClassifier
Parameters:
options - the list of options as an array of strings
Throws:
java.lang.Exception - if an option is not supported
可以看到,只有参数含义,并没有我们想要的实例,后来,看到分类器还有一个 getOptions 方法,眼睛一亮,想到可以查看一下默认参数的格式是怎么样的,源代码如下:
String[] options=cfs.getOptions();
for(int i=0;i<options.length;i++){
System.out.println(options[i]);
}
输出打印如下:
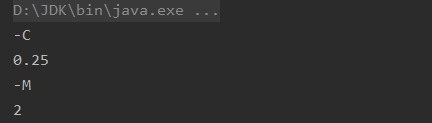
看到打印结果,果断知道了网上的实例为什么错误了,人家一个设置要分两个字符串来写,于是修改如下:
String[] options ={"-B","true"};
J48 classifier = new J48();
classifier.setOptions(options);
结果还是报错,也是佛了,最后的最后,想到了 weka 软件的参数设置:

看到上面 J48 后面出现的字符和通过 getOptions 打印出来的一样,点击进去,修改二分叉的属性(将 binarySplits 的 False 修改为 True),再看看果然发生了变化:

看到这里我才明白,根部不需要什么 true,对于这种非数值型参数设置只要一个字符串就可以,于是再次修改参数设置:
String[] options ={"-B"};
J48 classifier = new J48();
classifier.setOptions(options);
再次运行,没有报错,完美运行。
建议:先使用weka软件设置完参数,然后将参数复制粘贴过来就行了。问题一
有一问题是,除了 J48 classifier = new J48();创建的对象能够使用 setOptions 方法,其他两种创建对象方式都不能使用该方法,不知道哪里有问题,查看源代码,三种方式指向的类都是同一个类,这个后续有时间再解决一下。
6、任务:从数据库读取数据生成 Instances
从 oracle 数据库读取:
public static Instances oracleInput() throws Exception{
InstanceQuery query = new InstanceQuery();
String sql = "SELECT to_char(z.cydate,'yyyy/mm') AS d,sum(z.bcmoney) as c FROM zybc z"
+ " WHERE to_char(z.cydate,'yyyy/mm') IS NOT NULL"
+ " GROUP BY to_char(z.cydate,'yyyy/mm') ORDER BY to_date(to_char(z.cydate,'yyyy/mm'),'yyyy/mm') ASC";
//System.out.println(sql);
query.setCustomPropsFile(new File("weka/weka_oracle.props"));
query.setDatabaseURL("jdbc:oracle:thin:@192.168.2.133:1521/XE");
query.setUsername("***");
query.setPassword("***");
query.setQuery(sql);
Instances data = query.retrieveInstances();
return data;
}
从 mysql 数据库读取:
public static Instances mysqlInput() throws Exception{
InstanceQuery query = new InstanceQuery();
String sql = "SELECT * FROM iris";
//System.out.println(sql);
query.setCustomPropsFile(new File("weka/weka_mysql.props"));
query.setDatabaseURL("jdbc:mysql://localhost:3306/test");
query.setUsername("***");
query.setPassword("***");
query.setQuery(sql);
Instances data = query.retrieveInstances();
return data;
}
6、任务:保存模型与加载模型
这个相对简单一下:
//保存模型,参数一为模型保存文件,cfs为要保存的模型
SerializationHelper.write("J48.model", cfs);
//加载模型
Classifier cfs = (Classifier) weka.core.SerializationHelper.read("J48.model");
说实话,这一顿搞后,还是觉得通过 java 使用 weka 远没有软件方便,建议可以使用 weka 软件生成模型,再通过 java 直接调用模型即可,感觉会方便很多。
OK,今天就到这里,更多精彩内容关注我的个人网站:蓝亚之舟博客。