python的os模块详解
本章介绍python自带模块os,os为操作系统 operating system 的简写,意为python与电脑的交互。主要学习的函数有 os.getcwd()、os.chdir()、os.path.basename()、os.path.join()、os.path.exists()、os.path.isdir()、os.path.isfile()、os.listdir()、os.walk()、os.scandir()、os.stat()、os.mkdir()、os.makedirs()、os.rename()、os.remove()以及获取桌面路径。目录链接有点不准,不够我调多次也调不好,无法手动生成 都是自动生成的,将就一下。话不多说,进入正题。
目录
1. 绝对路径、相对路径
2. 绝对路径的三种表达方式
3. os.getcwd()
4. os.chdir()
5. os.path.basename()
6. os.path.join()
7. os.path.exists()
8. os.path.isdir() 、 os.path.isfile()
9. os.listdir()
10. os.walk()
11. os.scandir()
12. os.stat()
13. os.mkdir()
14. os.makedirs()
15. os.rename()
(1)重命名
(2)移动
(3)重命名并移动
16. os.remove()
17. 获取桌面的路径
结尾
1. 绝对路径、相对路径
概念:绝对路径为一个完整的路径。相对路径为基于当前默认路径下的路径,省去了当前路径的部分。
例子:假如 当前默认路径为 D:\临时\python试验\pandas。pandas文件夹下里还有 /merge/first/test.txt 文件夹及文件。那么test.txt文件的路径:
| 绝对路径 | D:\临时\python试验\pandas\merge\first\test.txt |
| 相对路径 | \merge\first\test.txt |
传授两个快捷技巧获取文件的路径:①在文件夹上方路径处复制路径。②按住shift 右击文件,此时会出现 “复制文件地址” 的选项,点击即可。对于文件,无疑是方法②略胜一筹。
2. 绝对路径的三种表达方式
(1)用单斜杠 / 来分隔文件夹。这是路径是最好表达方式。
如:"D: / 临时 / python试验 / pandas"
(2)用双反斜杠 \\ 来分隔文件夹。按照上述的②方法获得的路径都是以单反斜杠 \ 来分隔的,如果手动把 \ 改为 / ,工作量有点大,此时可以选择再加一个反斜杠变为双反斜杠,反斜杠在python中表示的意义是转义符,把具有特殊含义的后者转为不含任何意义的字符(用replace是不行的,因为\在python里表现为转义符,会报错,不信可以试试哈)
如:"D: \\ 临时 \\ python试验 \\ pandas"
(3)在路径前加上字母 r ,意思为 raw原始的。字母 r 加在字符串前能确保该字符串全是字符串形式,如 \n也只是 \n,不再翻译为回车换行;\也只是\,不再翻译为转义符。把文件路径复制粘贴后直接在前面加个 r 就行,该方法是最方便的,大推。
如:r"D: \ 临时 \ python试验 \ pandas"
3. os.getcwd()
获取当前文件所在的路径。
import os
print(os.getcwd()) 图1 os.getcwd()
图1 os.getcwd()
默认状态下,os.getcwd()输出的是当前正在编辑的 ipynb或 py文件所在的路径。
4. os.chdir(path)
更改当前路径,更改后,默认路径为更改后的路径。
os.chdir(r'D:\临时\python试验\pandas')
print(os.getcwd()) 图2 更改默认路径 os.chdir
图2 更改默认路径 os.chdir
更改路径可不是仅仅输出为path那么简单,它对于文件的读取和写入非常方便。
5. os.path.basename(p)
获取路径中的最后一个文件夹名字。
print(os.path.basename(r'D:\临时\python试验\pandas')) 图3 os.path.basename
图3 os.path.basename
注意,若传入的路径为文件,如 r'D:\临时\python试验\pandas\test.txt',返回的结果是文件名 test.txt。
6. os.path.join(path, *paths)
拼接路径。
p1 = r'D:\临时\python试验\pandas'
p2 = r'merge\test.txt'
print(os.path.join(p1,p2)) 图4 os.path.join
图4 os.path.join
7. os.path.exists(path)
判断路径 path是否存在。
print(os.path.exists(r'D:\临时\python试验\pandas'))
print(os.path.exists(r'D:\临时\python试验\pandas\3D图.csv'))
8. os.path.isdir(path, /) 、 os.path.isfile(path)
前者判断path是否为文件夹,后者判断path是否为文件。
r1 = r'D:\临时\python试验\pandas'
r2 = r'D:\临时\python试验\pandas\merge\test.txt'
print(os.path.isdir(r1))
print(os.path.isfile(r2)) 图5 判断是否文件夹或文件
图5 判断是否文件夹或文件
9. os.listdir(path=None)
输出path路径下所有文件及文件夹,返回结果为一个列表。(不遍历下层)
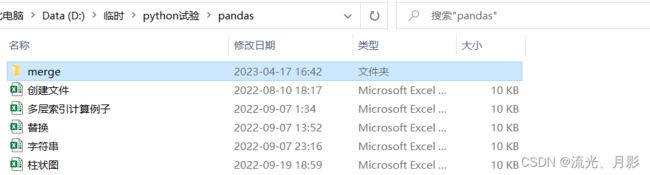 图6 我的指定路径下的文件
图6 我的指定路径下的文件
print(os.listdir(r'D:\临时\python试验\pandas')) 图7 os.listdir
图7 os.listdir
当传入指定 path时,输出该路径下的文件及文件夹,如图6,图中蓝色的为文件夹。
当不传入 path时,有两种情况:①若没有设置 os.chdir(path)去指定默认路径,则输出当前代码文件所在目录下的文件及文件夹。②若设置了 os.chdir(path1),则输出该path1路径下的文件及文件夹。
“ 不遍历嵌套文件夹 ” 意思是:即使merge文件夹下还有文件,那么这个文件也不会得到输出,即仅遍历当前层。(如果想要输出嵌套文件夹下的所有文件,可见下面第9点 os.walk(path) )
10. os.walk(top, topdown=True, οnerrοr=None, followlinks=False)
循环遍历top路径下的所有文件,该路径下层的文件及文件夹。
top:路径,顶层路径
topdown:可以理解为加快速度,不用管,默认为True
onerror:当有错误时,可以用定义的函数去输出错误
followlinks:默认为False,意义不大
该函数必须传入路径,返回3个变量值。第一个为文件夹绝对路径,第二个为子文件夹的列表,第三个为根目录下所有文件的列表。先看第一个 (i):
for (i,j,k) in os.walk(r'D:\临时\python试验\pandas'):
print(i) 图8 os.walk输出 i
图8 os.walk输出 i
i 得到的是该路径下所有文件夹的绝对路径(看图6,该路径下有个merge文件夹)。再看 j :
for (i,j,k) in os.walk(r'D:\临时\python试验\pandas'):
print(j)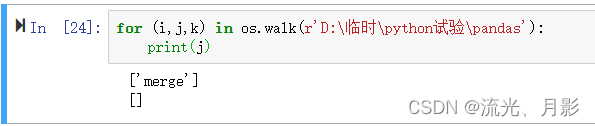 图9 os.walk输出 j
图9 os.walk输出 j
j 得到的是对应 i 路径下含有的文件夹,每个 i 的路径输出一个列表。['merge']的由来是因为 D:\临时\python试验\pandas下有个merge文件;[]的由来是因为 D:\临时\python试验\pandas\merge下没有文件夹了。再看 k:
for (i,j,k) in os.walk(r'D:\临时\python试验\pandas'):
print(k) 图9 os.walk输出 k
图9 os.walk输出 k
k 得到的是对应 i 路径下含有的文件,每个 i 的路径输出一个列表。这里输出的两个列表的由来,和 j 一样,就不一一解释了。
由此,通常循环遍历某路径下所有文件以及路径的方法是把 i 和 k 结合:
for (i,j,k) in os.walk(r'D:\临时\python试验\pandas'):
for l in k:
print(i+'/'+ l)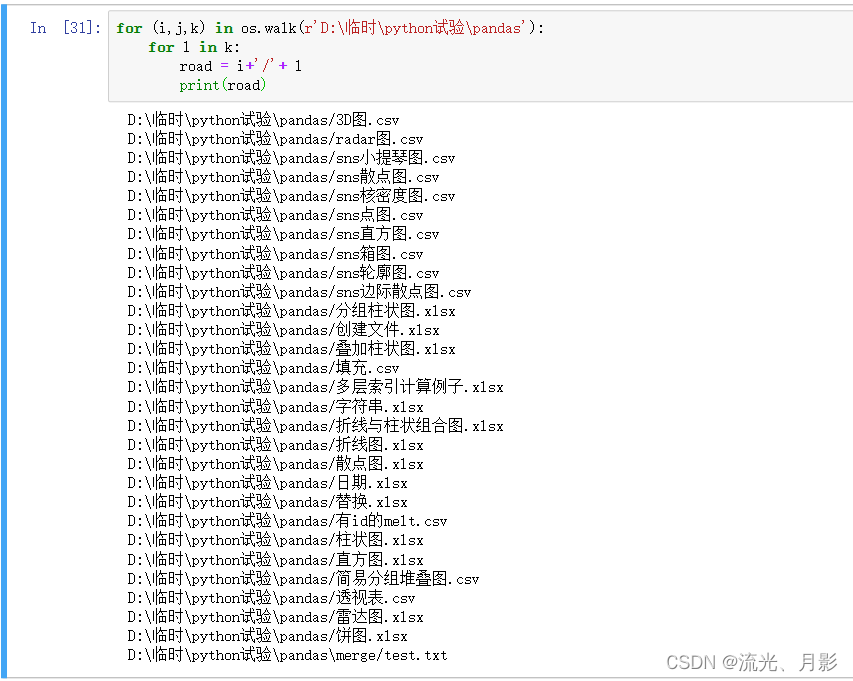 图10 循环遍历文件夹下的全部文件
图10 循环遍历文件夹下的全部文件
此时,位于下层merge文件下的 test.txt 也打印了出来,这是与 os.listdir()即图7的区别。
11. os.scandir(path=None)
加快迭代速度,把需要迭代的内容放在一个迭代对象里,而不是像os.listdir()一样把结果存在列表中(放在列表占用大量内存)
 图11 os.scandir
图11 os.scandir
可见返回的是一个可迭代对象,作用是减少内存占用,加快运行速度。除此之外,它还可以访问文件的各种属性。如获取文件/文件夹名,文件/文件夹绝对路径,是否为文件夹,是否为文件,以及属性。
for i in os.scandir(r'D:\临时\python试验\pandas'):
print(i)
print(i.name)
print(i.path)
print(i.is_dir())
print(i.is_file())
print('-'*70)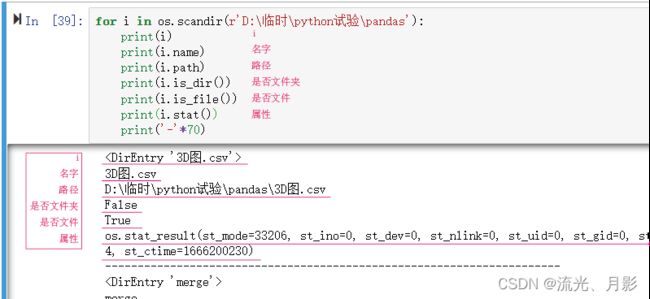 图12
图12
根据属性,还可以提取文件的大小(单位为kb,文件夹大小为0kb)、最近访问时间、最近修改时间、window系统下的创建时间、linux系统下的创建时间等。这里以文件大小 .st_size为例
| 文件大小 | .st_size |
| 最近访问时间 | .st_atime |
| 最近修改时间 | .st_mtime |
| window系统下的创建时间 | .st_ctime |
| linux系统下的创建时间 | .st_birthtime |
for i in os.scandir(r'D:\临时\python试验\pandas'):
print(i.name,i.stat().st_size,'kb') 图13 输出文件大小的属性
图13 输出文件大小的属性
12. os.stat(path, *, dir_fd=None, follow_symlinks=True)
获得文件的属性。能获得的属性与上面一样,不再重复。
a = os.stat(r'D:\临时\python试验\pandas\3D图.csv')
print(a)
print(a.st_size,'kb') 图14 os.stat
图14 os.stat
13. os.mkdir(path, mode=511, *, dir_fd=None)
创建路径(文件夹),若该路径已存在,则报错。(只能创建一层)
path:路径
mode:访问权限,默认为511,即所有人都可访问。在window系统下,mode参数会被忽略。
(1)当路径已存在:(目前已存在的路径:D:\临时\python试验\pandas\merge )
 图15 路径已存在 则报错
图15 路径已存在 则报错
(2)创建两层文件夹:
os.mkdir(r'D:\临时\python试验\pandas\merge\concat\join') 图16 创建两层文件夹 报错
图16 创建两层文件夹 报错
用os.mkdir()去创建两层文件夹(merge → concat)是不允许的,每次只能创建一层。
(3)创建一层文件夹:
 图17 创建一层 成功运行而没有报错
图17 创建一层 成功运行而没有报错
14. os.makedirs(name, mode=511, exist_ok=False)
创建路径(文件夹),能一次创建多层。
在运行该代码前,首先要删掉第13中创建的文件夹,回到最初的状态,方便观察效果(即 D:\临时\python试验\pandas\merge 目录下没有文件夹)
os.makedirs(r'D:\临时\python试验\pandas\merge\concat\join')
print('成功') 图18 os.makedirs
图18 os.makedirs
os.mkdir 一次只能创建一层,而 os.makedirs 一次能创建多层,则就是它们之间的区别。
15. os.rename(src, dst, *, src_dir_fd=None, dst_dir_fd=None)
重命名/移动文件或文件夹。
src:原文件路径
dst:重命名/移动后的文件路径
首先在 D:/临时/python试验/pandas 目录下手动创建3个word文件用于实验:重命名before.docx、移动before.docx、重命名并移动before.docx
(1)重命名
把文件 "重命名before.docx" 重命名为 "重命名after.docx"。
os.rename(r"D:/临时/python试验/pandas/重命名before.docx",r"D:\临时\python试验\pandas\重命名after.docx")![]()
(2)移动
把文件 "移动before.docx" 由 "D:/临时/python试验/pandas" 移动到 "D:\临时" ,不改变命名。
os.rename(r"D:\临时\python试验\pandas\移动before.docx",r"D:\临时\移动before.docx")![]()
(3)重命名并移动
把文件 "重命名并移动before.docx" 由 "D:/临时/python试验/pandas" 移动到 "D:\临时" ,同时命名改为 "重命名并移动after.docx " 。
os.rename(r"D:\临时\python试验\pandas\重命名并移动before.docx",r"D:\临时\变变变.docx")![]()
总的来说,重命名把名字改了就行;移动把路径改了就行;移动并重命名则同时改路径和名字。
如果后路径不存在,会报错 “找不到路径” 。
需要注意的是,改名字的时候小心不要把文件的后缀弄没了,如果真的不小心弄没了后缀,可以点击文件夹的左上角 “查看”,把 “文件拓展名” 勾上,然后手动加上后缀名。要小心避免此类问题。下图为不小心把 .docx后缀弄没了的文件,该文件由于没有后缀,系统不能识别该文件是什么类型。
 图19 没了后缀的文件
图19 没了后缀的文件
16. os.remove(path, *, dir_fd=None)
删除文件。小心该操作,不进回收站,删除后是很难找回来的,建议不要用重要的文件去实验。
17. 获取桌面的路径
给大家传授一个不常见但非常有用的东西:获取桌面的路径。
os.path.expanduser("~") 获取电脑用户名及路径
获取到用户名的路径后,用os.path.join()拼接即可获得桌面路径。
user = os.path.expanduser("~")
desktop = os.path.join(user,'Desktop')
print(user)
print(desktop)
有什么用途呢,幻想一下你写了一个程序把运行出来的结果保存在excel里,想要把这个excel文件保存在对方桌面(为什么保存到桌面,因为缩小化去运行程序,让没有学过编程的朋友看着桌面自动生成了一个excel文件,他们的兴趣马上就来了,那种仰望的眼神,谁懂!!)的时候,就需要获取电脑的桌面路径了,这种方法的缺点是在电脑更改了桌面路径后便不适用。当然,这只是一个小例子,其他用处还有很多,待各位小伙伴发掘,然后分享出来。
结尾
os 模块操作最多的是路径和文件夹,涉及到对文件的文件不多。
如果想要用python模块去批处理文件,对于重命名,移动等,os还是可以做到的。但是更高级的功能,比如文件的复制,剪切,以及使用通配符*去查找符合条件的文件就比较困难了,通常要使用到其他库,如shutil, glob,fnmatch 等库,如果小伙伴对这方面感兴趣,可以提前进行了解。
可能后续我也会更新shutil, glob,fnmatch 等库,但是一篇文章的输出、排版、思考如何才能讲得清楚明白都需要大量时间。把我学到的知识用自己的理解、自己的思维写出来,有输入有输出,同时能锻炼自己的写作、组织、通俗易懂化和其他能力,目前我可能讲的不够条理,但是我也在和大家一起进步,一起加油。