猿人学web端爬虫攻防大赛赛题解析_第八题:验证码 图文点选
验证码 图文点选
- 一、前言
- 二、解析过程
-
- 2.1、点选逻辑分析
- 2.2、验证码图像预处理
-
- 2.2.1、处理图像背景
- 2.2.2、移除干扰线条
- 2.2.3、增强字体显示效果
- 2.3、验证码中的文字识别
-
- 2.3.1、ocr识别
-
- 2.3.2、手动识别
- 三、完整代码实现
- 四、结语
- 五、参考文献
一、前言
第八题跟以往的几道混淆题有很大区别,不需要你去很费劲扣代码逻辑,找加密参数什么的,但是难就难在验证码图片太难识别了,花了一两个星期尝试看看有没比较好的解决方案,最终还是选择最稳妥的人工识别法,深度学习识别什么的以后再慢慢研究,不过解题过程中还是涨了不少姿势。
二、解析过程
2.1、点选逻辑分析
网站给出的目标是按顺序点击这四个字

通过点击观察请求后,发现其操作逻辑是先选择正确的文字坐标,点击完成后,携带正确的坐标信息请求数据页,最后得到正确的数值相应。
坐标信息附带在数据页api的请求参数上,就是这个answer,由四个数值构成的汉字对应坐标信息:
/api/match/8?page=1&answer=735%7C776%7C145%7C724%7C
在源代码里请求观察可以发现,四个坐标会通过“|”符号连接:

每次点击验证码中的一个位置,就会选中该汉字对应的div 索引:

整个验证码图片共计对应有900个div标签,对应九个字的话,就是每个字对应100个div,点击某个字体区域的任何一个div位置,都可以算成功选中这个字,经过测试,div是横向排列的。以下图为例,位置1234的位置索引分别是:“0|29|270|299|”。

所以实际上整个验证码实际上是一幅30*30像素的图片,最上面的三个字对应的所有div位置如下表所示,其余字的坐标也是按这个规则推算。
| 行数 | 左边的字 | 中间的字 | 右边的字 |
|---|---|---|---|
| 第一行 | 0-9 | 10-19 | 20-29 |
| 第二行 | 30-39 | 40-49 | 50-59 |
| 第三行 | 60-69 | 70-79 | 80-89 |
| 第四行 | 90-99 | 100-109 | 110-119 |
| 第五行 | 120-129 | 130-139 | 140-149 |
| 第六行 | 150-159 | 160-169 | 170-179 |
| 第七行 | 180-189 | 190-199 | 200-209 |
| 第八行 | 210-219 | 220-229 | 230-239 |
| 第九行 | 240-249 | 250-259 | 260-269 |
| 第十行 | 270-279 | 280-289 | 290-299 |
了解了验证码里的字对应的div坐标转换规则以后,剩下的问题就是怎么确定每个字在图上的哪个区域,这也是这道题最大的难点。按常规直觉,通过ocr识别是我首先想到的方式。
2.2、验证码图像预处理
由于验证码图片的干扰程度太强,一开始我尝试直接用一些ocr平台(还是太天真)试试能不能识别出里面的字体来,结果果然是失败了,直接用没处理的原图来识别是不可能正常识别出字体的,所以还是要做一些预处理,把图片里面的背景、字体表面的干扰线条去掉。
由于我以前没怎么做过图像处理,所以在网上搜了半天,找到一个大佬的处理方案,看这里,并且做了一点小改动,整体上分下面几步:
2.2.1、处理图像背景
以这个验证码为例,大片的背景颜色对识别这个这些字体造成了严重干扰,所以首先要想办法把背景颜色消除。
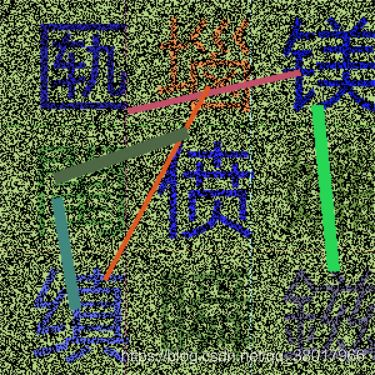
处理代码如下:
im=cv2.imread('验证码图片')
# 读取图片高,宽
h, w = im.shape[0:2]
# np.unique()该函数是去除数组中的重复数字,并进行排序之后输出,这里返回的是所有像素rgb值,以及对应的数量
colors, counts = np.unique(np.array(im).reshape(-1, 3), axis=0, return_counts=True)
#挑选图片中背景最多的两种颜色对应的像素个数
ct=np.sort(counts)
top2_counts=ct[-2:].tolist()
# 把频率最高的两种颜色筛掉
info_dict = {counts[i]: colors[i].tolist() for i, v in enumerate(counts) if not v in top2_counts}
colors_select=np.array([v for v in info_dict.values()])
# 移除了背景的图片,赋值为去了黑色背景的colors就不会出现少一个字的情况
remove_background_rgbs = colors_select
mask = np.zeros((h, w, 3), np.uint8) + 255 # 生成一个全是白色的图片
# 通过循环将不是噪点的像素,赋值给一个白色的图片,最后到达移除背景图片的效果
for rgb in remove_background_rgbs:
mask[np.all(im == rgb, axis=-1)] = im[np.all(im == rgb, axis=-1)]
cv2.imshow("Image with background removed", mask) # 移除了背景的图片
cv2.waitKey(0)
经过这一步处理后,图片的背景就被替换为白色了,只剩遮住字体的线条还存在一定干扰。

2.2.2、移除干扰线条
移除干扰线条的原理比较简单,由于验证码图片里,干扰线条的颜色跟待识别字体是不一样的,所以可以通过选择字体间隔间的像素颜色,将对应颜色的像素都替换为白色,这样就达到去除线条的目的。
# 去掉线条,全部像素黑白化
line_list = [] # 首先创建一个空列表,用来存放出现在间隔当中的像素点
# 两个for循环,遍历9000次
for y in range(h):
for x in range(w):
tmp = mask[x, y].tolist()
if tmp != [0, 0, 0]:
if 0 < y < 20 or 110 < y < 120 or 210 < y < 220:
line_list.append(tmp)
if 0 < x < 10 or 100 < x < 110 or 200 < x < 210:
line_list.append(tmp)
remove_line_rgbs = np.unique(np.array(line_list).reshape(-1, 3), axis=0)
for rgb in remove_line_rgbs:
mask[np.all(mask == rgb, axis=-1)] = [255, 255, 255]
# 把所有字体颜色统一替换为黑色
mask[np.any(mask != [255, 255, 255], axis=-1)] = [0, 0, 0]
cv2.imshow("Image with lines removed", mask) # 移除了线条的图片
cv2.waitKey(0)
移除线条后的图片是这样:

2.2.3、增强字体显示效果
经过上一步处理后的图片,基本上已经可以很好的辨识出字体原有的形状了,但是由于字形内还存在一些小空隙,整个字看起来会略微有些单薄,所以再做一个腐蚀处理,让字体显示更清晰。
# 生成一个2行三列数值全为1的二维数字,作为腐蚀操作中的卷积核
kernel = np.ones((2, 3), 'uint8')
# iterations 迭代的次数,也就是进行多少次腐蚀操作,卷积核越大,迭代次数越多字体会被处理的越粗
erode_img = cv2.erode(mask, kernel,iterations=2)
cv2.imshow('Eroded Image', erode_img)
cv2.waitKey(0)
cv2.imwrite(r"...\capchta_yuan_processed.jpg", erode_img)
经过处理后的图片,最终效果如下:

在完成以上几个步骤的处理后,我们可以看出图像相比没处理之前,辨识度已经提高很多了。但是这个代码也还是存在一些缺陷,比如有些线条不能完全消除,以及处理后由于线条被去除,连带字体一部分内容也被消除了,这就给后期的识别带来一定难度。
2.3、验证码中的文字识别
2.3.1、ocr识别
ocr识别是一种比较智能化,便捷的提取图片中文字的方法了,bat公司都有提供在线ocr调用接口,百度甚至也开源了paddle ocr 这个python库,实际上这些方式用于识别常规的图片文字是绰绰有余的,精度相当不错。但是第八题这个验证码里的字首先是生僻字,对识别库的汉字训练库要求比较高,其次即使是处理过后的图片,还是存在一些干扰,这就导致我们及时使用这些现有的ocr识别库,依然没法很高精度的识别出图片里的九个字。实际测试中对于验证码里稍微简单点的字,成功率会高一点,但生僻字比例较高的图片里几乎不可能把全部汉字都正确识别出来。所以可能比较合适的一个尝试是自己对这些图片做个深度学习模型训练,这需要对深度学习有一定了解,而且采样、预处理什么的有点耗时间,我这里就暂时放弃这种方法了,还是太菜了(〃 ̄︶ ̄)。
使用easyocr和paddleocr识别图片的代码如下,可以留作参考:
'''easyocr识别图片,设置识别中英文两种语言'''
reader = easyocr.Reader(['ch_sim'], gpu = False) # need to run only once to load model into memory
text = reader.readtext(img_path, detail = 0)
'''paddle ocr识别图片,设置识别中文'''
ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to download and load model into memory
pd_ocr_words = ocr.ocr(img_path, cls=True)
2.3.2、手动识别
手动识别就很简单了,虽然是笨办法,但是很有效,每次把处理好的图片弹出窗口,然后人眼判断对应汉字的位置,再手动输入坐标,就能实现百分百准确识别了…
一开始我是不想用这种方法的,本来就是搞自动化爬虫,结果最后还是手动处理,太没面子了!没办法,谁叫自己技术不到家,技术栈修炼不够啊。
代码的整体思路如下:先给每个字定义固定的索引位置,在人眼识别图片的时候,输入0-8这就个索引就行,最后自动拼接出answer字符串:
cv2.imshow("Image processed", processed_img) # 移除了背景的图片
cv2.waitKey(0)
#w为验证码中的每个字定义一个标准位置索引,从左往右,从上到下
std_index={0:'1',1:'11',2:'21',3:'301',4:'311',5:'321',6:'601',7:'611',8:'621'}
loc=input("手动输入坐标:")
answer_str=''
for l in loc:
answer_str += std_index[int(l)] + '|'
return answer_str
三、完整代码实现
整个代码写的有点长,中间夹杂了许多其他尝试,比如图片切割后ocr识别,或者用识别出的字体跟四个标准字做相似度比较,所以导入的库比较多
import os
import requests
import re
import base64
import io
import cv2
from PIL import Image,ImageFont,ImageDraw
import numpy as np
import pandas as pd
from fuzzychinese import FuzzyChineseMatch
import easyocr
from collections import Counter
# from paddleocr import PaddleOCR, draw_ocr
# import imagehash
HEADERS={
'Proxy-Connection': 'keep-alive',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'User-Agent': 'yuanrenxue.project',
'X-Requested-With': 'XMLHttpRequest',
'Referer': 'http://match.yuanrenxue.com/match/8',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
SESSION=requests.session()
SESSION.headers=HEADERS
# ocr识别图片,设置识别中英文两种语言
reader = easyocr.Reader(['ch_sim'], gpu=False) # need to run only once to load model into memory
#图像处理
def image_process(cv_img):
'''
处理验证码图片,并使用easyocr模块识别图中中文汉字
:param cv_img: cv格式图片内容
:return: 返回九个识别出来的汉字
'''
'''步骤一:处理图像背景'''
# cv2.imread读取图像
im = cv_img
cv2.imshow("原图", im) # 移除了背景的图片
cv2.waitKey(0)
# img.shape可以获得图像的形状,返回值是一个包含行数,列数,通道数的元组 (100, 100, 3)
h, w = im.shape[0:2]
# 去掉黑椒点的图像
# np.all()函数用于判断整个数组中的元素的值是否全部满足条件,如果满足条件返回True,否则返回False
# im[np.all(im == [0, 0, 0], axis=-1)] = (255, 255, 255) #将像素点为黑色的全部转换为白色的
# reshape:展平成n行3列的二维数组
# np.unique()该函数是去除数组中的重复数字,并进行排序之后输出
colors, counts = np.unique(np.array(im).reshape(-1, 3), axis=0, return_counts=True)
ct=np.sort(counts)
# print(ct[-2:])
top2_counts=ct[-2:].tolist()
# 筛选条件这里可以再完善一下,可以试试反向筛选,把频率最高的两种颜色筛掉试试
# 通过后面的操作就可以移除背景中的噪点
info_dict = {counts[i]: colors[i].tolist() for i, v in enumerate(counts) if not v in top2_counts}
# colors_select=info_dict.values()
colors_select=np.array([v for v in info_dict.values()])
# 移除了背景的图片,赋值为去了黑色背景的colors就不会出现少一个字的情况
remove_background_rgbs = colors_select
mask = np.zeros((h, w, 3), np.uint8) + 255 # 生成一个全是白色的图片
# 通过循环将不是噪点的像素,赋值给一个白色的图片,最后到达移除背景图片的效果
for rgb in remove_background_rgbs:
mask[np.all(im == rgb, axis=-1)] = im[np.all(im == rgb, axis=-1)]
cv2.imshow("Image with background removed", mask) # 移除了背景的图片
cv2.waitKey(0)
'''步骤二:移除干扰线条'''
# 去掉线条,全部像素黑白化
line_list = [] # 首先创建一个空列表,用来存放出现在间隔当中的像素点
# 两个for循环,遍历9000次
for y in range(h):
for x in range(w):
tmp = mask[x, y].tolist()
if tmp != [0, 0, 0]:
if 0 < y < 20 or 110 < y < 120 or 210 < y < 220:
line_list.append(tmp)
if 0 < x < 10 or 100 < x < 110 or 200 < x < 210:
line_list.append(tmp)
remove_line_rgbs = np.unique(np.array(line_list).reshape(-1, 3), axis=0)
for rgb in remove_line_rgbs:
mask[np.all(mask == rgb, axis=-1)] = [255, 255, 255]
# np.any()函数用于判断整个数组中的元素至少有一个满足条件就返回True,否则返回False。
mask[np.any(mask != [255, 255, 255], axis=-1)] = [0, 0, 0]
cv2.imshow("Image with lines removed", mask) # 移除了线条的图片
cv2.waitKey(0)
'''步骤三:图像膨胀腐蚀操作'''
# 腐蚀
# 卷积核涉及到python形态学处理的知识,感兴趣的可以自行百度
# 生成一个2行三列数值全为1的二维数字,作为腐蚀操作中的卷积核
kernel = np.ones((2, 3), 'uint8')
# kernel2 = np.ones((3, 3), 'uint8')
# iterations 迭代的次数,也就是进行多少次腐蚀操作
erode_img = cv2.erode(mask, kernel,iterations=2)
# erode_img2 = cv2.erode(mask, kernel2, iterations=1)
cv2.imshow('Eroded Image', erode_img)
# cv2.imshow('Eroded Image2', erode_img2)
# cv2.imwrite('deal.png',erode_img) 这行代码可以保存处理的图片
# cv2.waitKey()等待键盘输入,为毫秒级
# cv2.waitKey()防止图片一闪而过
cv2.waitKey(0)
# cv2.imwrite(r"...\capchta_yuan_processed.jpg", erode_img)
'''给图像最右侧加一列空白'''
# white = np.zeros((300, 300, 3), np.uint8) + 255 # 生成一个全是白色的图片,右侧加十个像素宽度的空白
# img = np.concatenate([erode_img, white], axis=1)
# cv2.imshow("Image add lines white", img) # 移除了线条的图片
# cv2.waitKey(0)
return erode_img
#ocr识别
def ocr_recognization(processed_img):
imglist=image_clip(processed_img)
ocr_words=[]
'''easyocr识别图片,设置识别中英文两种语言'''
# reader = easyocr.Reader(['ch_sim'], gpu = False) # need to run only once to load model into memory
for img in imglist:
text = reader.readtext(img, detail = 0)
ocr_words.append(text)
# ocr_words=sum([[t for t in te] for te in text],[])
print('easyocr结果:', sum(ocr_words,[]))
return sum(ocr_words,[])
'''paddle ocr识别图片,设置识别中文'''
# ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to download and load model into memory
# img_path = "d:/Desktop/capchta_yuan_processed.jpg"
# pd_ocr_words = ocr.ocr(img_path, cls=True)
# print('paddleocr结果:', pd_ocr_words)
#手动识别
def manual_recognization(processed_img):
cv2.imshow("Image processed", processed_img) # 移除了背景的图片
cv2.waitKey(0)
#w为验证码中的每个字定义一个标准位置索引,从左往右,从上到下
std_index={0:'1',1:'11',2:'21',3:'301',4:'311',5:'321',6:'601',7:'611',8:'621'}
loc=input("手动输入坐标:")
answer_str=''
for l in loc:
answer_str += std_index[int(l)] + '|'
return answer_str
#通过ocr方式获取返回坐标
def word_match(words,ocr_words):
'''
将ocr识别出来的九个字与正确的四个字进行相似度匹配,选择最相似的四个字,返回其点选位置构成的字符串
:param words: 四个带点选的字
:param ocr_words: 识别出来的九个字
:return: answer参数的字符串
'''
#w为验证码中的每个字定义一个标准位置索引,从左往右,从上到下
std_index={0:'1',1:'11',2:'21',3:'301',4:'311',5:'321',6:'601',7:'611',8:'621'}
answer_str=''
for ind,ocr in enumerate(ocr_words):
for word in words:
if ocr==word:
answer_str+=std_index[ind]+'|'
print(answer_str)
return answer_str
#请求获得验证码信息
def get_verifyInfo():
'''
解析待待点选的字符和验证码图片
:return:
'''
response = SESSION.get('http://match.yuanrenxue.com/api/match/8_verify').json()
content=response['html']
words=re.findall('(.*?)
',content,re.S)
base64_image=re.findall('base64,(.*?)" alt=',content,re.S)[0]
image=base64.b64decode(base64_image)
# with open(r"...\capchta_yuan_processed.jpg",'wb') as f:
# f.write(image)
# 读取二进制图片文件方法二
# image = Image.open(io.BytesIO(image))
# img = cv2.cvtColor(np.asarray(image), cv2.COLOR_RGB2BGR)
#读取二进制图片文件
img1 = np.frombuffer(image, np.uint8)
img = cv2.imdecode(img1, cv2.IMREAD_ANYCOLOR)
# cv2.imwrite("d:/Desktop/capchta_yuan.jpg", img)
# image=cv2.imread(img)
# cv2.imshow("Image", img)
# cv2.waitKey(0)
return words, img
#请求正确数据
def get_data():
url = 'http://match.yuanrenxue.com/api/match/8'
for i in range(1,6):
words, img = get_verifyInfo()
print('待识别字符:', words)
processed_img = image_process(img)
#ocr识别
# ocr_words=ocr_recognization(processed_img)
# answer = word_match(words, ocr_words)
#手动识别
answer=manual_recognization(processed_img)
params = (
('page', str(i)),
('answer',answer)
)
response = SESSION.get(url, params=params)
try:
data = response.json()
except:
print('识别失败')
continue
print(data)
#汉字转图片
def text_to_image(words):
'''汉字转图片'''
for word in words:
text = word
im = Image.new("RGB", (100, 100), (255, 255, 255))
dr = ImageDraw.Draw(im)
font = ImageFont.truetype('C:\Windows\Fonts\simhei.ttf', 100)
dr.text((0, 0), text=text, font=font, fill="#000000")
im.show()
im.save(r"d:/Desktop/{0}.jpg".format(text))
#图片切割
def image_clip(cv_img):
clip_imgs=[]
# num=0
for y in range(0,300,100):
for x in range(10,300,100):
cropped = cv_img[y:y+100, x:x+100] # 裁剪坐标为[y0:y1, x0:x1]
clip_imgs.append(cropped)
# cv2.imwrite(r"...\{0}.jpg".format(str(num)), cropped)
# num+=1
return clip_imgs
if __name__=="__main__":
get_data()
某一轮五页的验证码识别输出结果:
待识别字符: ['涧', '帄', '围', '止']
手动输入坐标:6243
{'status': '1', 'state': 'success', 'data': [{'value': 7453}, {'value': 1457}, {'value': 5053}, {'value': 2127}, {'value': 4455}, {'value': 4290}, {'value': 9875}, {'value': 7453}, {'value': 8778}, {'value': 2571}]}
待识别字符: ['娆', '嚎', '劳', '钥']
手动输入坐标:1872
{'status': '1', 'state': 'success', 'data': [{'value': 3932}, {'value': 5963}, {'value': 3372}, {'value': 9736}, {'value': 7831}, {'value': 1706}, {'value': 887}, {'value': 9955}, {'value': 4029}, {'value': 3034}]}
待识别字符: ['螅', '恽', '謟', '埚']
手动输入坐标:4315
{'status': '1', 'state': 'success', 'data': [{'value': 9606}, {'value': 3850}, {'value': 4106}, {'value': 2381}, {'value': 8545}, {'value': 2403}, {'value': 9984}, {'value': 7453}, {'value': 3585}, {'value': 7545}]}
待识别字符: ['牝', '衙', '铐', '山']
手动输入坐标:7106
{'status': '1', 'state': 'success', 'data': [{'value': 5231}, {'value': 7453}, {'value': 6090}, {'value': 6476}, {'value': 2965}, {'value': 5510}, {'value': 3879}, {'value': 7453}, {'value': 5821}, {'value': 1356}]}
待识别字符: ['绖', '璜', '餋', '鳅']
手动输入坐标:0863
{'status': '1', 'state': 'success', 'data': [{'value': 4798}, {'value': 8040}, {'value': 3086}, {'value': 7453}, {'value': 9874}, {'value': 4251}, {'value': 2862}, {'value': 677}, {'value': 9708}, {'value': 7902}]}
四、结语
爬虫案例尝试的越多,越发现搞爬虫是一项对技术栈要求很高的任务,js逆向、深度学习什么的任何一门领域内容都是非常庞杂的,掌握皮毛不难,想要学深的话就需要花很多功夫了,总之且学且珍惜,慢慢修炼吧。
五、参考文献
