哈希函数、哈希表及其应用
哈希函数
哈希函数又名散列函数,对于经典哈希函数来说,它具有以下5点性质:
(1)输入域无穷大
(2)输出域有穷尽
(3)输入一样输出肯定一样
(4)当输入不一样输出也可能一样(哈希碰撞)
(5)不同输入会均匀分布在输出域上(哈希函数的散列性):例如输入域是0-99这一百个数字,而我们使用的哈希函数的输出域为0,1,2,当我们将0-99这一百个数字通过该哈希函数,得到的返回值,0,1,2数量都会接近33个,不会出现某个返回值数量特别多,而某个返回值特别少。
哈希表
哈希表中存入的数据是key,value类型的,哈希表能够put(key,value),同样也能get(key,value)或者remove(key,value)。当我们需要向哈希表中put(插入记录)时,我们将key拿出,通过哈希函数计算hashcode。假设我们预先留下的空间大小为16,我们就需要将通过key计算出的hashcode模以16,得到0-15之间的任意整数,然后我们将记录挂在相应位置的下面(包括key,value)。
哈希函数在大数据中的应用
例如,有一个10TB的大文件存在分布式文件系统上,存的是100亿行字符串,并且字符串无序排列,现在我们要统计该文件中重复的字符串。
假设,我们可以调用100台机器来计算该文件。
那么,现在我们需要怎样通过哈希函数来统计重复字符串呢。
首先,我们需要将这一百台机器分别从0-99标好号,然后我们在分布式文件系统中一行行读取文件(多台机器并行读取),通过哈希函数计算hashcode,将计算出的hashcode模以100,根据模出来的值,将该行存入对应的机器中。
根据哈希函数的性质,我们很容易看出,相同的字符串会存入相同的机器中。
然后我们就能并行100台机器,各自分别计算相应的数据,大大加加快统计的速度。
例 1 设计RandomPool结构
【题目】 设计一种结构,在该结构中有如下三个功能:
insert(key):将某个key加入到该结构,做到不重复加入。
delete(key):将原本在结构中的某个key移除。
getRandom(): 等概率随机返回结构中的任何一个key。
【要求】 Insert、delete和getRandom方法的时间复杂度都是 O(1)
import java.util.HashMap;
public class hello {
public static class Pool {
//定义两个hashmap
private HashMap keyIndexMap;//下标,值
private HashMap indexKeyMap;//值,下标
private int size;//个数
//初始化池结构
public Pool() {
this.keyIndexMap = new HashMap();
this.indexKeyMap = new HashMap();
this.size = 0;
}
//插入
public void insert(K key) {
if (!this.keyIndexMap.containsKey(key)) {
this.keyIndexMap.put(key, this.size);
this.indexKeyMap.put(this.size++, key);
}
}
//删除
public void delete(K key) {
if (this.keyIndexMap.containsKey(key)) {
//获得删除下标
int deleteIndex = this.keyIndexMap.get(key);
//获得最后一个值的下标
int lastIndex = --this.size;
//获得最后一个值
K lastKey = this.indexKeyMap.get(lastIndex);
this.keyIndexMap.put(lastKey, deleteIndex);
this.indexKeyMap.put(deleteIndex, lastKey);
this.keyIndexMap.remove(key);
this.indexKeyMap.remove(lastIndex);
}
}
//获取随机值
public K getRandom() {
if (this.size == 0) {
return null;
}
int randomIndex = (int) (Math.random() * this.size); // 0 ~ size -1
return this.indexKeyMap.get(randomIndex);
}
}
public static void main(String[] args) {
Pool pool = new Pool();
pool.insert("cao");
pool.insert("y");
pool.insert("q");
System.out.println(pool.getRandom());
System.out.println(pool.getRandom());
}
}
布隆过滤器
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
(布隆过滤器常用于搜索)
一致性哈希
一致性Hash算法将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0-2^ 32-1(即哈希值是一个32位无符号整形),从 0 ~ 2^32-1 代表的分别是一个个的节点,这个环也叫哈希环.
然后我们将我们的节点进行一次哈希,按照一定的规则,比如按照 ip 地址的哈希值,让节点落在哈希环上。
最后就是需要通过数据 key 找到对应的服务器然后存储了,我们约定,通过数据 key 的哈希值落在哈希环上的节点,如果命中了机器节点就落在这个机器上,否则落在顺时针直到碰到第一个机器。
1.新增节点
我们假设我们需要增加一台机器,也就是增加一个节点D4,如下图所示,这个节点落在 D2-D1 之间,按照上述的哈希环上的哈希值落在节点的规则,那么此时之前落在 D2 到 D4 之间的数据都需要重新定位到新的节点上面了,而其它位置的数据是不需要有改变的。

2. 一致性哈希的数据倾斜问题
一致性Hash算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜(被缓存的对象大部分集中缓存在某一台服务器上)问题。比如只有 2 台机器,这 2 台机器离的很近,那么顺时针第一个机器节点上将存在大量的数据,第二个机器节点上数据会很少。如下图所示,D0 机器承载了绝大多数的数据

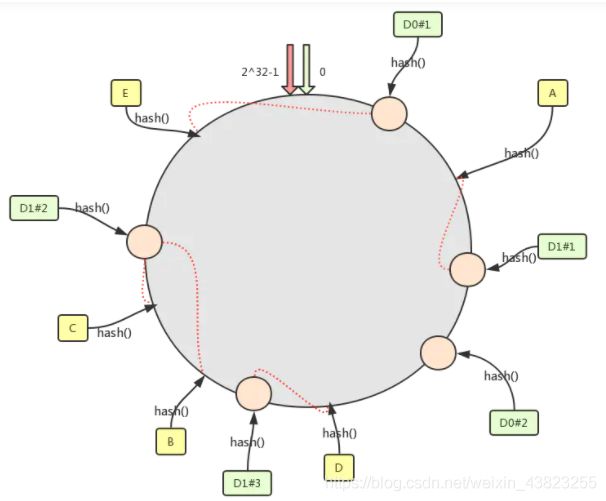
3. 虚拟节点解决数据倾斜问题
为了避免出现数据倾斜问题,一致性 Hash 算法引入了虚拟节点的机制,也就是每个机器节点会进行多次哈希,最终每个机器节点在哈希环上会有多个虚拟节点存在,使用这种方式来大大削弱甚至避免数据倾斜问题。同时数据定位算法不变,只是多了一步虚拟节点到实际节点的映射,例如定位到“D1#1”、“D1#2”、“D1#3”三个虚拟节点的数据均定位到 D1 上。这样就解决了服务节点少时数据倾斜的问题。在实际应用中,通常将虚拟节点数设置为32甚至更大,因此即使很少的服务节点也能做到相对均匀的数据分布。这也是 Dubbo 负载均衡中有一种一致性哈希负载均衡的实现思想。
并查集结构
并查集的结构实现,对外提供两个方法:
1.检查两个元素是否属于一个集合
2.将两个元素所在的集合合并在一起
import java.util.HashMap;
import java.util.List;
public class hello {
public static class Node {
// whatever you like(String,int,Char,Float)
//不定义指针
}
public static class UnionFindSet {
public HashMap fatherMap;//存放父节点
public HashMap sizeMap;//存放该节点所在集合包含的节点数量
//初始化map
public UnionFindSet() {
fatherMap = new HashMap();
sizeMap = new HashMap();
}
//建立集合,初始时每个节点各自建立一个集合
public void makeSets(List nodes) {
fatherMap.clear();
sizeMap.clear();
for (Node node : nodes) {
fatherMap.put(node, node);
sizeMap.put(node, 1);
}
}
//寻找头节点
private Node findHead(Node node) {
Node father = fatherMap.get(node);
if (father != node) {
father = findHead(father);
}
fatherMap.put(node, father);
return father;
}
//判断是否属于同一个集合
public boolean isSameSet(Node a, Node b) {
return findHead(a) == findHead(b);
}
//合并两个元素的集合
public void union(Node a, Node b) {
if (a == null || b == null) {
return;
}
Node aHead = findHead(a);
Node bHead = findHead(b);
if (aHead != bHead) {
int aSetSize= sizeMap.get(aHead);
int bSetSize = sizeMap.get(bHead);
//个数少的放在个数大的上面
if (aSetSize <= bSetSize) {
fatherMap.put(aHead, bHead);
sizeMap.put(bHead, aSetSize + bSetSize);
} else {
fatherMap.put(bHead, aHead);
sizeMap.put(aHead, aSetSize + bSetSize);
}
}
}
}
public static void main(String[] args) {
}
}
例:岛问题
一个矩阵中只有0和1两种值,每个位置都可以和自己的上、下、左、右 四个位置相连,如果有一片1连在一起,这个部分叫做一个岛,求一个 矩阵中有多少个岛?
举例:
0 0 1 0 1 0
1 1 1 0 1 0
1 0 0 1 0 0
0 0 0 0 0 0
这个矩阵中有三个岛。
public class hello {
//计算岛的个数
public static int countIslands(int[][] m) {
if (m == null || m[0] == null) {
return 0;
}
int N = m.length;
int M = m[0].length;
//计数器
int res = 0;
for (int i = 0; i < N; i++) {
for (int j = 0; j < M; j++) {
//找到岛并感染相连的数字,使得不重复计数
if (m[i][j] == 1) {
res++;
infect(m, i, j, N, M);
}
}
}
return res;
}
public static void infect(int[][] m, int i, int j, int N, int M) {
//数组越界或数值不为1,不被感染
if (i < 0 || i >= N || j < 0 || j >= M || m[i][j] != 1) {
return;
}
//感染的方式是数值从1变为2
m[i][j] = 2;
//查找上下左右
infect(m, i + 1, j, N, M);
infect(m, i - 1, j, N, M);
infect(m, i, j + 1, N, M);
infect(m, i, j - 1, N, M);
}
public static void main(String[] args) {
int[][] m1 = { { 0, 0, 0, 0, 0, 0, 0, 0, 0 },
{ 0, 1, 1, 1, 0, 1, 1, 1, 0 },
{ 0, 1, 1, 1, 0, 0, 0, 1, 0 },
{ 0, 1, 1, 0, 0, 0, 0, 0, 0 },
{ 0, 0, 0, 0, 0, 1, 1, 0, 0 },
{ 0, 0, 0, 0, 1, 1, 1, 0, 0 },
{ 0, 0, 0, 0, 0, 0, 0, 0, 0 }, };
System.out.println(countIslands(m1));
}
}
结果:3
如果并行计算,把矩阵拆分开分开计算,之后进行合并,可以加快速度,主要由以下几步构成
1、并行计算两部分岛的数量以及收集边界信息
2、利用并查集实现减少岛的过程