本文期望通过本地化部署一个基于LLM模型的应用,能让大家对构建一个完整的应用有一个基本认知。包括基本的软硬环境依赖、底层的LLM模型、中间的基础框架及最上层的展示组件,最终能达到在本地零编码体验的目的。
一、ChatGLM-6B模型介绍
https://github.com/THUDM/ChatGLM-6B [Star 27.6k]
一个清华开源的、支持中英双语的对话语言模型,基于GLM架构,62亿参数。可以本地安装部署运行在消费级的显卡上做模型的推理和训练。
- 开源10天10000stars
- 当天在GitHub的趋势排行第一
- Huggingface下载超过100万
- 开源的训练数据量达到1万亿字符的模型
1、能力
- 自我认知
- 文案写作
- 提纲写作
- 信息抽取
2、缺点
- 模型容量小导致回答存在偏见内容,推理能力较弱
3、场景
- 垂直领域知识
- 基于私有数据的问答
二、部署体验
1、环境依赖:
硬件:
- 基于GPU,建议16GB起步,建议24GB+体验,否则多轮容易爆显存;
- 无GPU可以仅用CPU,大约需要25GB内存,CPU会慢一点,本次不使用。
软件:
- CUDA 11.7+
- Python3.10.8+
- pip3
- git
2、钞能力-算力市场:
强烈不建议本地部署,一整套硬件价值不菲,费时耗力,按需购买算力对于体验来说最划算,建议使用京东Ku+平台即可,目前都有配额,可直接申请使用,本次演示流程基于autodl算力平台搭建:
▪http://kuplus.jd.com [Ku+]
▪https://www.autodl.com [AutoDL]
3、下载demo:
# 下载项目源代码
git clone https://github.com/THUDM/ChatGLM-6B
# 切换到项目根目录
cd ChatGLM-6B
# 安装依赖
pip install -r requirements.txt
# 安装回老版本gradio,解决输出内容未渲染html标签问题
pip install gradio==3.28.3
# 如果pip下载有问题,修改其他源,比例douban或aliyun,没有pip.conf需新建
mkdir ~/.pip && touch ~/.pip/pip.conf && vim ~/.pip/pip.conf
[global]
index-url=http://pypi.douban.com/simple/
[install]
trusted-host=pypi.douban.com4、下载模型:
# 直接git下载模型,大约需要13G空间
git clone https://huggingface.co/THUDM/chatglm-6b
# 或者部分地区可能无法下载,可以使用镜像单独下载,新建url.txt, 拷贝以下镜像地址保存
https://cloud.tsinghua.edu.cn/seafhttp/files/08ff8050-912c-47b8-ad5c-56bcd231df71/ice_text.model
https://cloud.tsinghua.edu.cn/seafhttp/files/88a7978c-8eda-498d-85e8-0671294a4c47/pytorch_model-00001-of-00008.bin
https://cloud.tsinghua.edu.cn/seafhttp/files/de998e41-7093-41b3-84f1-59e32361e703/pytorch_model-00002-of-00008.bin
https://cloud.tsinghua.edu.cn/seafhttp/files/077b5058-5ebd-4930-9470-8e873c01f47c/pytorch_model-00003-of-00008.bin
https://cloud.tsinghua.edu.cn/seafhttp/files/728f7324-ce96-44bc-a08f-5c7222727ca5/pytorch_model-00004-of-00008.bin
https://cloud.tsinghua.edu.cn/seafhttp/files/932b40ac-d195-4ba4-8d06-7946b8e6d0d8/pytorch_model-00005-of-00008.bin
https://cloud.tsinghua.edu.cn/seafhttp/files/d763678e-c438-416b-a4b9-5594c52cb3f6/pytorch_model-00006-of-00008.bin
https://cloud.tsinghua.edu.cn/seafhttp/files/59da96fd-8eb9-42d4-992e-03e1d0637a01/pytorch_model-00007-of-00008.bin
https://cloud.tsinghua.edu.cn/seafhttp/files/849d7de4-9253-487a-bc37-9a43418e3c0c/pytorch_model-00008-of-00008.bin
# 此处文件夹名称使用THUDM/chatglm-6b
mkdir -p THUDM/chatglm-6b && cd THUDM/chatglm-6b && touch url.txt
# 保存批量下载地址
vim url.txt
# 执行wget批量下载到当前文件夹
wget -i url.txt5、安装运行:
打开 web_demo.py
# 一、如果模型位置不是默认path,修改如下位置:
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
# 二、找到最后一行或者类似 queue().launch 位置,指定ip、端口方便外网映射用,一般算力市场会默认提供一个映射端口,指定即可:
demo.queue().launch(share=False, inbrowser=True, server_name='0.0.0.0', server_port=6006)
# 启动
python web_demo.py
root@autodl-container-9494499a62-3e5ab6d1:~/ChatGLM-6B# python web_demo.py
Explicitly passing a `revision` is encouraged when loading a model with custom code to ensure no malicious code has been contributed in a newer revision.
Explicitly passing a `revision` is encouraged when loading a configuration with custom code to ensure no malicious code has been contributed in a newer revision.
Explicitly passing a `revision` is encouraged when loading a model with custom code to ensure no malicious code has been contributed in a newer revision.
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████| 8/8 [00:10<00:00, 1.36s/it]
Running on local URL: http://0.0.0.0:6006
To create a public link, set `share=True` in `launch()`.6、实际效果、资源占用:
| 主机配置 | 演示效果 |  |
|---|---|---|
 |
 |
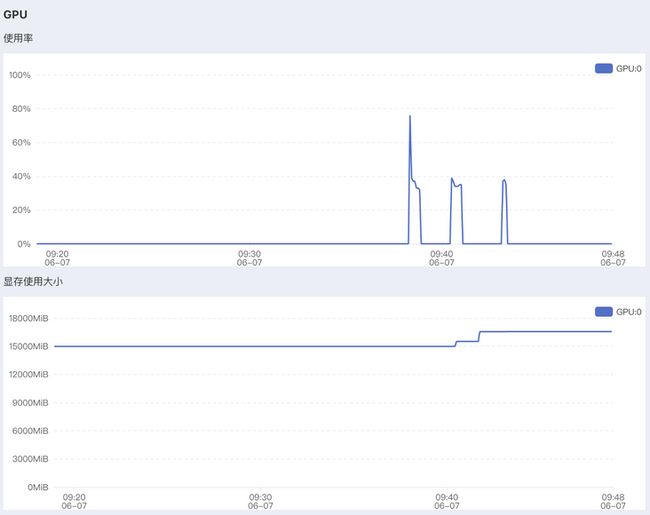 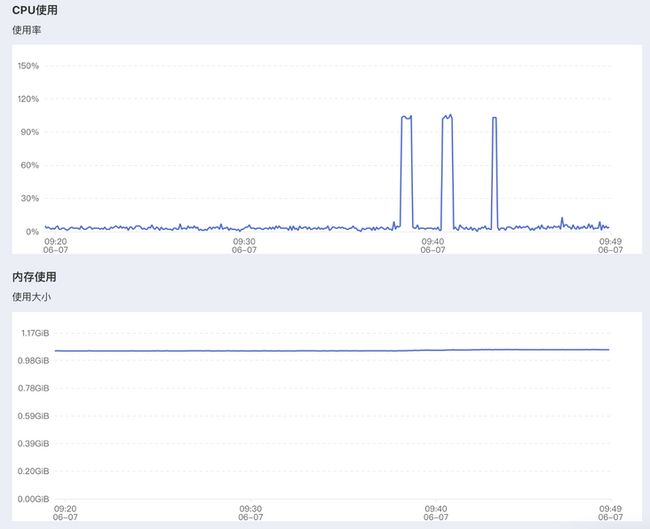 |
7、推理参数含义:
· Maximum length
通常用于限制输入序列的最大长度,因为ChatGLM-6B是2048长度推理的,一般这个保持默认就行, 太大可能会导致性能下降
· Top P
Top P 参数是指在生成文本等任务中,选择可能性最高的前P个词的概率累加和。这个参数被称为Top P,也称为Nucleus Sampling。
例如,如果将Top P参数设置为0.7,那么模型会选择可能性排名超过70%的词进行采样。这样可以保证生成的文本准确性较高,但可能会缺乏多样性。相反,如果将Top P参数设置为0.3,则会选择可能性超过30%的词进行采样,这可能会导致生成文本的准确性下降,但能够更好地增加多样性。
· Temperature
Temperature参数通常用于调整softmax函数的输出,用于增加或减少模型对不同类别的置信度。
具体来说,softmax函数将模型对每个类别的预测转换为概率分布。Temperature参数可以看作是一个缩放因子,它可以增加或减少softmax函数输出中每个类别的置信度。
例如,将Temperature设置为0.05和0.95的主要区别在于,T=0.05会使得模型更加自信,更加倾向于选择概率最大的类别作为输出,而T=0.95会使得模型更加不确定,更加倾向于输出多个类别的概率值较大。
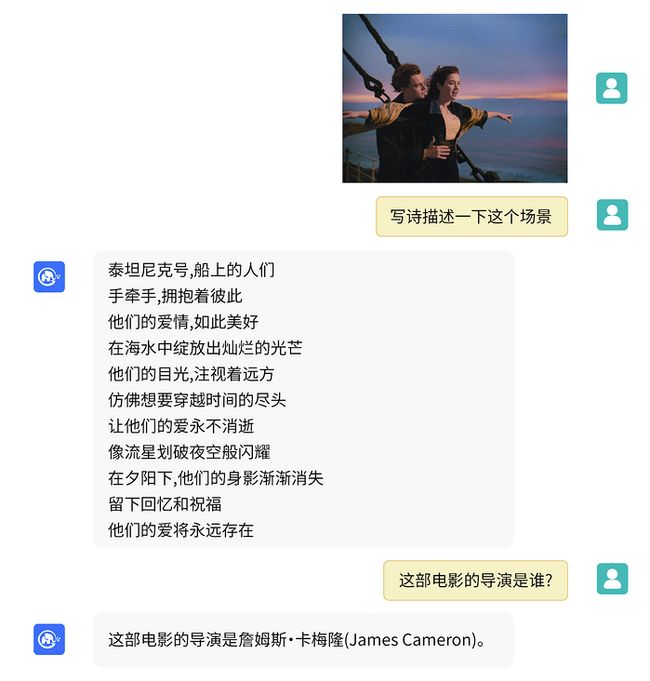
8、其他好玩的:
看图说话,VisualGLM-6B,一个支持图像理解的多模态对话语言模型,语言模型基于ChatGLM-6B。
 |
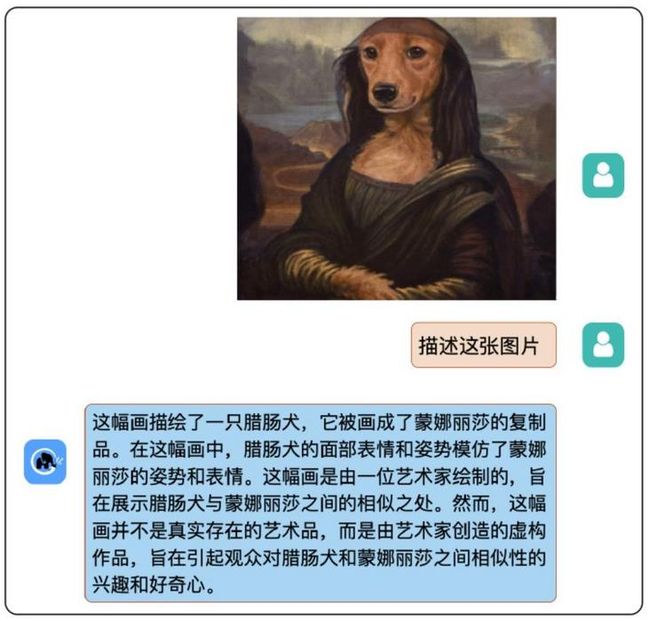 |
 |
|---|
三、结合LangChain实现本地知识库
1、LangChain:
https://github.com/hwchase17/langchain [Star 45k]
⽤于开发由语⾔模型驱动的应⽤程序的基础框架,是一个链接面向用户程序和LLM之间的中间层,可以理解成是一个lib。
· 简介原理
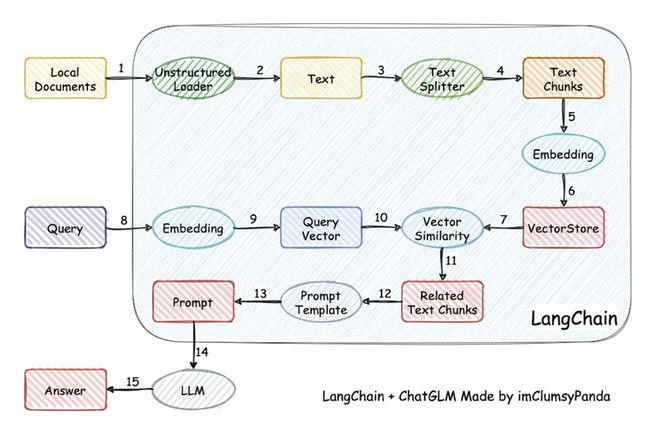
· 主要功能
1.调⽤语⾔模型;
2.将不同数据源接⼊到语⾔模型的交互中;
3.允许语⾔模型与运⾏环境交互。
· 模块介绍
1.Modules:⽀持的模型类型和集成;
2.Prompt:提示词管理、优化和序列化;
3.Memory:内存是指在链/代理调⽤之间持续存在的状态;
4.Indexes:当语⾔模型与特定于应⽤程序的数据相结合时,会变得更加强⼤-此模块包含⽤于加载、查询和更新外部数据的接⼝和集成;
5.Chain:链是结构化的调⽤序列(对LLM或其他实⽤程序);
6.Agents:代理是⼀个链,其中LLM在给定⾼级指令和⼀组⼯具的情况下,反复决定操作,执⾏操作并观察结果,直到⾼级指令执行完成;
7.Callbacks:回调允许您记录和流式传输任何链的中间步骤,从⽽轻松观察、调试和评估应⽤程序的内部。
2、LangChain-ChatGLM
https://github.com/imClumsyPanda/langchain-ChatGLM [Star 8k]
一种利用langchain实现的基于本地知识库的问答应用,目标期望建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案。
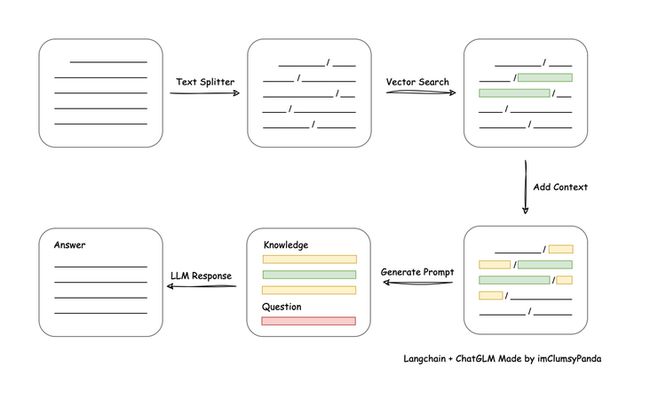
实现过程:包括加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的top k个 -> 匹配出的文本作为上下文和问题一起添加到prompt中 -> 提交给LLM生成回答。
· 项⽬特点
1.依托ChatGLM等开源模型实现,可离线部署;
2.基于langchain实现,可快速实现接⼊多种数据源;
3.在分句、⽂档读取等⽅⾯,针对中⽂使⽤场景优化;
4.⽀持pdf、txt、md、docx等⽂件类型接⼊,具备命令⾏demo、webui和vue前端。
· 项⽬结构
1.models:llm的接⼝类与实现类,针对开源模型提供流式输出⽀持;
2.loader:⽂档加载器的实现类;
3.textsplitter:⽂本切分的实现类;
4.chains:⼯作链路实现,如chains/local_doc_qa实现了基于本地⽂档的问答实现;
5.content:⽤于存储上传的原始⽂件;
6.vector_store:⽤于存储向量库⽂件,即本地知识库本体;
7.configs:配置⽂件存储。
· 安装部署
与ChatGLM安装基本类似,git clone之后修改模型地址到本地chartglm-6b的path启动即可,如果使用AutoDL平台,可用镜像一键拉起,镜像保持最新master版本,可体验最新功能。
最新镜像地址,已包含离线llm model: chatglm-6b 和 embedding: text2vec-large-chinese: https://www.codewithgpu.com/i/Liudapeng/langchain-ChatGLM/lan...
# 新增一步,下载离线 embedding model
sudo apt-get install git-lfs
git lfs install
git clone https://huggingface.co/GanymedeNil/text2vec-large-chinese
# 启用本地离线模型
vim ~/langchain-ChatGLM/configs/model_config.py
# 1、修改 embedding path
embedding_model_dict = {
"text2vec": "/root/GanymedeNil/text2vec-large-chinese",
}
# 2、修改 llm path, 直接指向为第一章节的 chatglm-6b path即可
"chatglm-6b": {
"name": "chatglm-6b",
"pretrained_model_name": "THUDM/chatglm-6b",
"local_model_path": "/root/ChatGLM-6B/THUDM/chatglm-6b",
"provides": "ChatGLM"
}
# 3、启用本地模型
NO_REMOTE_MODEL = True
# 运行Gradio web demo
cd ~/langchain-ChatGLM/
root@autodl-container-95b111aeb0-c6fdac9f:~/langchain-ChatGLM# python webui.py
INFO 2023-06-08 14:10:58,531-1d:
loading model config
llm device: cuda
embedding device: cuda
dir: /root/langchain-ChatGLM
flagging username: dc706ff885da43a8b0e8181bcc72ad1e
WARNING: OMP_NUM_THREADS set to 14, not 1. The computation speed will not be optimized if you use data parallel. It will fail if this PaddlePaddle binary is
compiled with OpenBlas since OpenBlas does not support multi-threads.
PLEASE USE OMP_NUM_THREADS WISELY.
Loading chatglm-6b...
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████| 8/8 [00:13<00:00, 1.66s/it]
Loaded the model in 23.48 seconds.
INFO 2023-06-08 14:11:26,780-1d: Load pretrained SentenceTransformer: /root/GanymedeNil/text2vec-large-chinese
{'answer': '你好!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。'}
INFO 2023-06-08 14:11:33,694-1d: 模型已成功加载,可以开始对话,或从右侧选择模式后开始对话
Running on local URL: http://0.0.0.0:6006
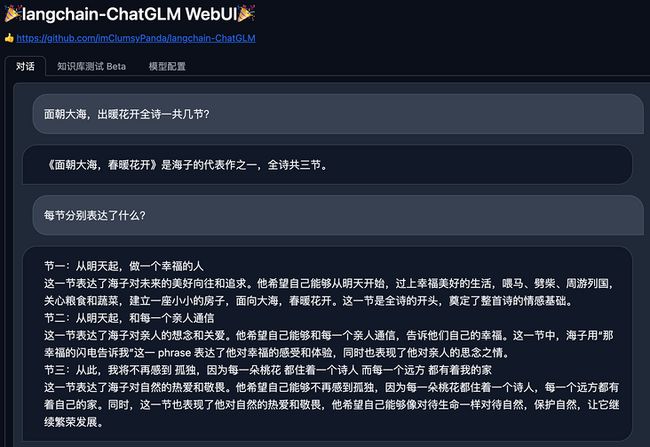
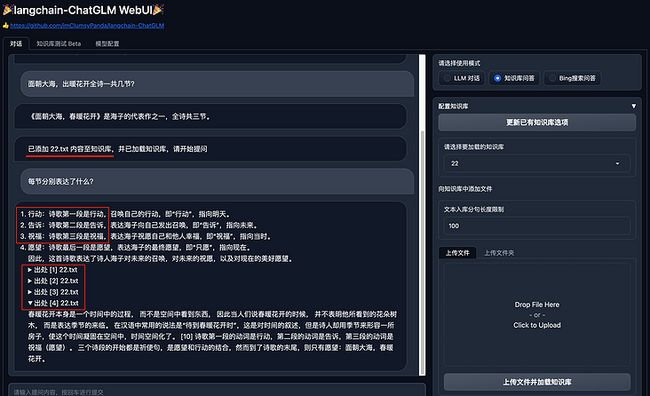
To create a public link, set `share=True` in `launch()`.· 效果对比
| LLM回答 | LLM+知识库 | 知识库来源 |
|---|---|---|
 |
 |
 |
四、视图框架
快速构建针对人工智能的python的webApp库,封装前端页面+后端接口+AI算法模型推理,方便AI算法工程师快速展示成果,常用的两个展示层框架:
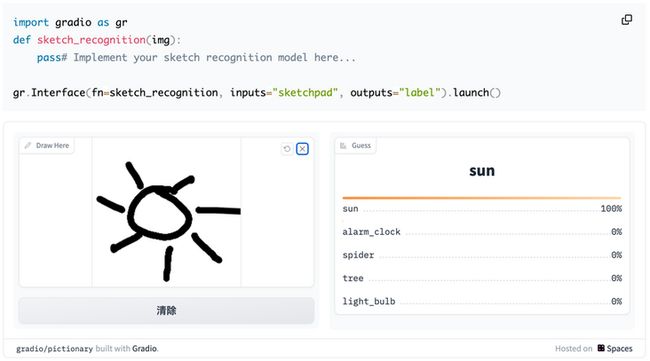
1、Gradio:
优势在于易用性,代码结构相比Streamlit简单,只需简单定义输入和输出接口即可快速构建简单的交互页面,更轻松部署模型。适合场景相对简单,想要快速部署应用的开发者;
2、Streamlit:
优势在于可扩展性,相比Gradio复杂。适合场景相对复杂,想要构建丰富多样交互页面的开发者。
作者:京东科技 刘大朋
来源:京东云开发者社区