获取网站上的旅游攻略信息,并作数据可视化
1.爬取2023最新游记有什么好玩的地方-适合年轻人的旅游攻略-去哪儿攻略 (qunar.com)
1.导入相应的库
import requests
import parsel
import csv
import time
import random2.使用GET的方式请求网页信息
url = f'https://travel.qunar.com/travelbook/list.htm?page=1&order=hot_heat'
response = requests.get(url)3. 获取数据
html_data = reponse.text4.用了Python的Web爬虫库Parsel,从HTML数据中提取了所有类名为“b_strategy_list”的元素下的所有链接(即a标签的href属性),并将它们存储在一个列表中。其中,::attr(href)表示要提取的是a标签的href属性。
selector = parsel.Selector(html_data)
url_list = selector.css('.b_strategy_list li h2 a::attr(href)').getall()5.保存为csv文件
csv_qne = open('去哪儿.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.writer(csv_qne)
csv_writer.writerow(['地点', '短评', '出发时间', '天数', '人均消费', '人物', '玩法', '浏览量'])6.爬取旅游攻略详情页的信息。首先通过循环遍历一个包含多个旅游攻略页面链接的列表,然后将链接中的特定字符替换掉,得到旅游攻略的ID。接着构造旅游攻略详情页的URL,发送请求并获取响应。使用parsel模块解析响应,提取出标题、评论、日期、天数、花费、旅行人物、旅游玩法、浏览量等信息,并输出到控制台。
for detail_url in url_list:
# 字符串的 替换方法
detail_id = detail_url.replace('/youji/', '')
url_1 = 'https://travel.qunar.com/travelbook/note/' + detail_id
print(url_1)
response_1 = requests.get(url_1).text
selector_1 = parsel.Selector(response_1)
title = selector_1.css('.b_crumb_cont *:nth-child(3)::text').get().replace('旅游攻略', '')
comment = selector_1.css('.title.white::text').get()
date = selector_1.css('#js_mainleft > div.b_foreword > ul > li.f_item.when > p > span.data::text').get()
days = selector_1.css('#js_mainleft > div.b_foreword > ul > li.f_item.howlong > p > span.data::text').get()
money = selector_1.css('#js_mainleft > div.b_foreword > ul > li.f_item.howmuch > p > span.data::text').get()
character = selector_1.css('#js_mainleft > div.b_foreword > ul > li.f_item.who > p > span.data::text').get()
play_list = selector_1.css('#js_mainleft > div.b_foreword > ul > li.f_item.how > p > span.data span::text').getall()
play = ' '.join(play_list)
count = selector_1.css('.view_count::text').get()
print(title, comment, date, days, money, character, play, count)7.最后写入csv文件中
# 写入数据
csv_writer.writerow([title, comment, date, days, money, character, play, count])
time.sleep(random.randint(1, 3))
csv_qne.close()爬取的数据有些为空,是因为网站上没有相关的数据。
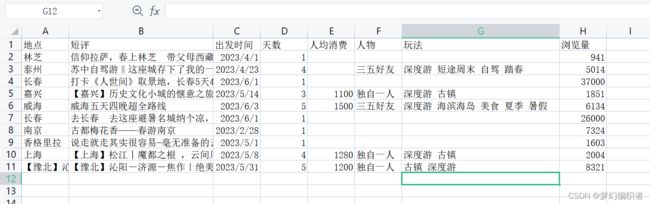
读取csv文件
import pandas as pd
from pyecharts.commons.utils import JsCode
from pyecharts.charts import *
from pyecharts import options as opts
df = pd.read_csv('去哪儿.csv')
print(df)

进行数据清洗,把NaN值若前后都不为空时,用前后的均值填充,同时兼具向前填充的功能
import pandas as pd
data = pd.read_csv(r'去哪儿.csv')
#缺失值填充
data= data.interpolate() #若前后都不为空时,用前后的均值填充,同时兼具向前填充的功能
data= data.fillna(method='bfill') #向后填充
data.to_csv("去哪儿旅行.csv",encoding='utf-8') #保存数据
print("保存成功")再读取去哪儿旅行.csv数据
import pandas as pd
from pyecharts.commons.utils import JsCode
from pyecharts.charts import *
from pyecharts import options as opts
df = pd.read_csv('去哪儿旅行.csv',encoding='utf-8')
print(df) 
# 筛选出人物为三五好友的数据
# 筛选出人物为三五好友的数据
filtered_data = df[(df['人物'] == '三五好友')]
# 输出结果
filtered_data 
筛选出人物为独自一人的数据
# 筛选出人物为独自一人的数据
filtered_data = df[(df['人物'] == '独自一人')]
# 输出结果
filtered_data 
做每个地点对应的消费图
import matplotlib.pyplot as plt
import pandas as pd
#读取数据
df = pd.read_csv('去哪儿旅行.csv')
#提取地点和人均消费情况
x = df['地点']
y = df['人均消费']
plt.rcParams["font.sans-serif"] = ["SimHei"] # 设置字体
plt.rcParams["axes.unicode_minus"] = False # 该语句解决图像中的“-”负号的乱码问题
#绘制折线图
plt.figure(dpi=500, figsize=(10, 5))
plt.title("人均消费折线图")
plt.plot(x, y, marker='o')
#将地点旋转30°
plt.xticks(rotation=30)
plt.xticks(fontsize=8)
plt.ylabel("人均消费")
plt.xlabel("地点")
plt.savefig("人均消费折线图")
plt.show() 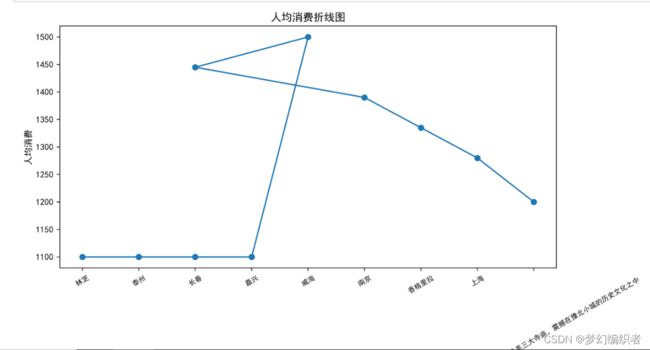
做旅游出行方式的饼图
import pandas as pd
import matplotlib.pyplot as plt
# 读取旅游数据
data = pd.read_csv('去哪儿旅行.csv')
# 统计人物出现次数
x = data['人物']
# 生成饼图
plt.pie(x.value_counts(), labels=x.value_counts().index,autopct='%1.1f%%')
plt.title('旅游出现方式最多的')
plt.show()
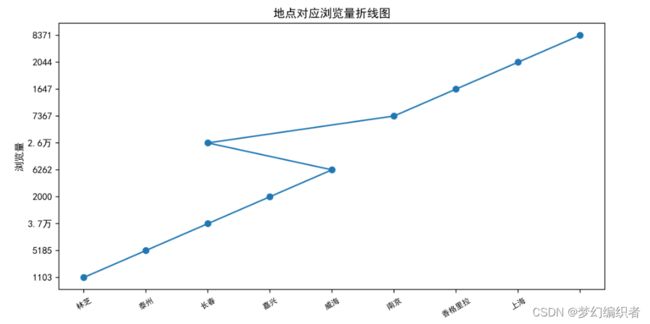
每个地点的浏览量
import matplotlib.pyplot as plt
import pandas as pd
#读取数据
df = pd.read_csv('去哪儿旅行.csv')
#提取地点和人均消费情况
x = df['地点']
y = df['浏览量']
plt.rcParams["font.sans-serif"] = ["SimHei"] # 设置字体
plt.rcParams["axes.unicode_minus"] = False # 该语句解决图像中的“-”负号的乱码问题
#绘制折线图
plt.figure(dpi=500, figsize=(10, 5))
plt.title("地点对应浏览量折线图")
plt.plot(x, y, marker='o')
#将地点旋转30°
plt.xticks(rotation=30)
plt.xticks(fontsize=8)
plt.ylabel("浏览量")
plt.xlabel("地点")
plt.savefig("地点对应浏览量折线图")
plt.show()