Linux线程同步(下)

文章目录
- 1. POSIX信号量
- 2. 基于环形队列的生产消费模型
-
- 2.1 代码实现
-
- 2.1.1 构造函数和析构函数
- 2.1.2 生产和消费
- 2.1.3 测试
- 3. 线程池
-
- 3.1 成员变量
- 3.2 构造和析构
- 3.3 push和pop
- 3.4 启动线程池
- 3.5 测试
- 4. 将线程池改成单例模式
- 5. STL、智能指针和线程安全
- 6. 其他常见的各种锁
-
- 6.1 自旋锁的概念
- 7. 读者写者问题
-
- 7.1 读写锁
- 7.2 使用读写锁
1. POSIX信号量
POSIX信号量和SystemV信号量作用相同,都是用于同步操作,达到无冲突的访问共享资源目的。 但POSIX可以用于线程间同步。
从前面的学习,我们知道:信号量是一个计数器,描述临界资源数量的计数器。只要信号量申请成功,那么就一定能获取指定的资源。
临界资源可不可以看作一个个小部分,被多个线程并发执行呢?
结合一定的场景,一个线程执行临界资源的一小部分是可以的,它们并不冲突。
我们知道:访问临界资源前,需要申请锁和释放锁,假设信号量为1,那么信号量由1到0的过程就是加锁,信号量由0到1的过程就是解锁。这个也叫做二元信号量,也就是互斥锁。
初始化信号量:

销毁信号量:

等待信号量:

发布信号量:

2. 基于环形队列的生产消费模型
上一节生产者-消费者的例子是基于queue的,其空间可以动态分配。现在基于固定大小的环形队列重写这个程序。
环形队列采用数组模拟,用模运算来模拟环状特性。
如果大家不懂环形队列,可以看这篇文章:环形队列的讲解
环形结构起始状态和结束状态都是一样的,不好判断为空或者为满,所以可以通过加计数器或者标记位来判断满或者空。另外也可以预留一个空的位置,作为满的状态。但是我们现在有信号量这个计数器,就很简单的进行多线程间的同步过程。
环形队列什么时候会发生访问同一个位置?
当只有空和满的时候,头和尾会指向同一个位置。
当环形队列为空的时候,只能让生产者先走,消费者不能走。当环形队列为满的时候,只能让消费者先走,生产者不能走。
从这里我们可以看出:它是具备同步和互斥关系的。
这个是由信号量来保证的。
那么其它时候,指向的是不同位置。指向不同位置,也就是指向不同的临界资源,那么生产者和消费者是可以进行并发的。
那么生产生和消费者最关心的资源是什么?
生产者最关心的是空间,消费者最关心的是数据。
假设环形队列一开始有N个空间,那么生产者的信号量(roomSem)一开始就是从N开始,然后到0。消费者的信号量(dataSem)一开始从0开始,然后到N。
那么生产线程首先需要P(roomSem)申请空间,这样空间信号量会少一个,然后放数据到空间里。最后V(dataSem),因为数据的信号量会增加一个。
消费线程首先需要P(dataSem)将数据的信号量减1,然后消费数据,最后V(roomSem),因为空间就会多出来一个。
2.1 代码实现
2.1.1 构造函数和析构函数

这个是环形队列的成员变量。然后我们需要将它们初始化和析构。
信号量如何初始化和释放的呢?我们在上面已经了解过:

信号量的初始化,第一个参数是你要初始化的信号量,第二个参数意思是你是否要共享,我们在这先设置为0,第三个参数是信号量的初始值。

这是信号量的释放,比较简单。

2.1.2 生产和消费
根据我们上面原理的分析,按照顺序来写:

2.1.3 测试

我们让生产者慢点,这样消费者就会按照生产者的顺序来。
运行结果是:

生产一个消费一个。
但是这存在一个问题:这里是单生产者,单消费者。如果是多生产者,多消费者会有什么问题呢?

假设信号量roomSem为20,然后有5个线程,那么就可能都申请到了信号量,那么就会同时进行生产,那么就会同时访问pIndex_,就会把其它线程的数据给覆盖了。消费者也是一样的道理。那么我们就需要让消费者和生产者各自加锁。

加上锁之后,就只能有一个线程竞争到锁,然后再去竞争信号量。但是这样的信号量无法被多次的申请。

那么我们的线程就是先申请信号量,也就是说你先占据了资源,然后再去申请锁。这样在某种程度上可以提高效率。
3. 线程池
线程池:一种线程使用模式。线程过多会带来调度开销,进而影响缓存局部性和整体性能。而线程池维护着多个线程,等待着监督管理者分配可并发执行的任务。这避免了在处理短时间任务时创建与销毁线程的代价。线程池不仅能够保证内核的充分利用,还能防止过分调度。
大致过程如下:

如果有任务就放到任务队列里面,然后线程去任务队列去获取,如果任务队列里面没有,线程就阻塞等待。
3.1 成员变量

如果没有任务时,让线程在条件变量下去等,有任务时就唤醒某一个线程。我们知道:条件变量本来就是排队的,没有任务时,线程都在排队,有任务时,就唤醒某个线程去执行,这样就可以实现多线程负载均衡,按照轮询方式去执行对应的任务。
3.2 构造和析构

当我们第一次构造的时候,可以判断线程的个数,以防有人传恶意数据。将isStart设置成false,说明还没有启动。
3.3 push和pop
既然如此,我们需要放任务和拿任务,push可以是公有的,pop可以设置私有:

既然生产了任务,说明任务队列里面有任务了,可以选择一个线程去执行。也就是随机唤醒一个线程。

3.4 启动线程池

我们启动时先判断这个线程池有没有启动过,如果已经启动过就报错。如果没启动就先启动,然后把isStart设置true。
但是这里有一个问题,我们先来测试一下:

我们编译一下:

原因是:threadRoutine这个回调函数是类里面的成员函数,以前都是在类外的定义。在类里面的成员函数是有隐藏的this指针,所以我们本应该传两个参数。
解决办法:加个static修饰这个成员函数。

那么我们用static修饰了,那么函数就不能使用this指针了,也就不能访问类的成员变量了。
然后我们创建线程的时候再传this指针过去,就能访问成员了。
然后我们需要让线程去执行对应的任务:

我们让每个线程分离。这样就不需要等待了。获取线程池对象的指针就可以访问类的成员函数和成员变量。
如果任务队列里面有任务,我们就可以取出来,去执行。
![]()
这里的Log()是一个日志打印函数:

3.5 测试
前面写过一个计算的任务:

然后我们以主线程去派发任务:

运行结果:

4. 将线程池改成单例模式
如果不知道单例模式,可以看这篇文章:单例模式
我们以懒汉模式为例:

静态的成员变量需要在类外定义。

把构造函数设置成私有,析构为公有。然后在写一个能获取这个对象的函数:

我们知道这里是会有线程安全的,第一次调用 getInstance 的时候,如果两个线程同时调用,可能会创建出两份 T 对象的实例。那么我们就需要加锁。这里我们用的是一个RAII思想的锁:


我们定义了一个static的锁,也就是全局的,它可以自动构造和释放。
那么我们怎么使用呢?

在这里介绍一个函数:

这个函数是设置线程的属性。


我们给主线程设置姓名为master,给新线程姓名为follower。
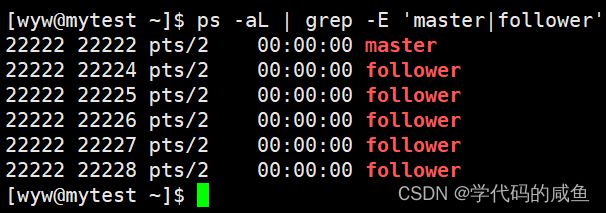
这里意思是匹配其中一个就行了,可以看到线程的名字改了。
5. STL、智能指针和线程安全

6. 其他常见的各种锁

6.1 自旋锁的概念

在临界区中,我们没有讨论过临界区里的时间问题。如果在临界区里等待时间短的话,就比较适合轮询测试是否就绪。如果在临界区里等待时间长的话,就比较适合挂起等待。
之前,我们用的锁都是挂起等待锁,也就是默认按照等待时间长的来加锁的。如果我们想用轮询测试的方式,我们就可以用自旋锁(pthread_spin_lock)。它的接口和mutex是一样的,就是换成spin。
7. 读者写者问题
7.1 读写锁
在编写多线程的时候,有一种情况是十分常见的。那就是,有些公共数据修改的机会比较少。相比较改写,它们读的机会反而高的多。通常而言,在读的过程中,往往伴随着查找的操作,中间耗时很长。给这种代码段加锁,会极大地降低我们程序的效率。那么有没有一种方法,可以专门处理这种多读少写的情况呢? 有,那就是读写锁。
它有1个读写场所,2种角色:读者和写者,3种关系:写者和写者是互斥的关系,读者和读者没有关系,读者和写者是互斥关系(因为在写的时候,我们读的话可能数据不准确)。
那么为什么前面消费者和消费者之间是互斥关系,这里读者和读者之间没有关系呢?
原因是:消费者会把数据拿走,而读者不会。
既然读者和写者的数量比是n:1的,那么它们进入临界区的时候,如何判断是读者还是写者?这就需要用到读写锁了。
读者:加读锁,然后读取内容,释放锁。
写者:加写锁,写入修改内容,释放锁。

这个是读写锁的初始化和销毁。

这个是读者的加锁。

这个是写者的加锁。

这个是解锁,解锁都是一样的。
7.2 使用读写锁
那么读者就加读锁,写者就加写锁,那么就可以分辨两种角色了。

这就是读写锁的使用。