Node.js入门之process模块、child_process模块、cluster模块
简介
本文主要介绍node中跟进程相关的三个模块。process是node的全局模块,作用比较直观。可以通过它来获得node进程相关的信息,child_process主要用来创建子进程,可以有效解决node单线程效率不高的问题。cluster是node的集群模块,提供了开箱即用的进程创建功能。
process
下面我们来看看process的一些常用的属性和方法。
process.env
process.env为node运行服务的环境变量。里面默认的变量很多,笔者就不一一列举了。
比如我们常用的NODE_ENV,我们执行NODE_ENV=production node process.js
console.log(process.env.NODE_ENV); // production
我们还可以传别的参数,比如我们执行aaa=dev node process.js
console.log(process.env.aaa); // dev
可以发现,通过key=value这种方式传递的参数就是环境变量。
process.argv
process.argv用来获取命令行参数,会返回一个数组。它的第一第二个参数是固定的,分别是node可执行程序绝对路径和当前执行文件的绝对路径。后面的参数就是我们自己传传递的了。
比如我们执行node process.js name randy
console.log(process.argv);
输出如下 
注意,这种参数是没有=的。
process.execArgv
process.execArgv用来获取特殊的参数。也就是运行node程序特有的参数啦,比如 --harmony。
我们来测试一下,执行node --harmony process.js name randy
console.log(process.execArgv); // [ '--harmony' ]
process.cwd()
process.cwd() 返回当前工作路径
console.log(process.cwd()); // /Users/randy/myproject/base-learn/node
process.chdir(directory)
process.chdir(directory) 切换当前工作路径
process.chdir("../npm");
console.log(process.cwd()); // /Users/randy/myproject/base-learn/npm
process.config
process.config返回node的编译配置相关参数。这个配置的参数也有很多,笔者就不一一列举了。
console.log("process.config", process.config);
process.pid
返回当前进程id。
console.log(process.pid); // 19540
process.title
返回和设置当前进程的名称,当你用ps命令,同时有多个node进程在跑的时候,作用就出来了。
process.title = "主进程";
console.log(process.title); // 主进程
process.uptime()
返回当前node进程已经运行了多长时间(单位是秒)。
console.log(process.uptime()); // 0.0291715
process.memoryUsage()
返回进程占用的内存,单位为字节。
console.log(process.memoryUsage());
返回如下

process.version
返回当前node的版本
console.log(process.version); // v14.21.1
process.versions
返回node的版本,以及依赖库的版本
console.log(process.versions);
返回如下

process.execPath
返回 node 可执行程序的绝对路径
console.log(process.execPath); // C:\Users\lq\AppData\Roaming\nvm\v14.21.1\node.exe
process.arch
返回当前系统的处理器架构(字符串),比如’arm’, ‘ia32’, or ‘x64’。
console.log(process.arch); // x64
process.platform
返回当前系统平台描述的字符串
console.log(process.platform); // win32
process.nextTick(fn)
这个方法类似js里面的promise.then(),是node中的微任务。不过还是有细微差别,后面讲node事件循环的时候我们再细说。现在简单理解成微任务就行。
setTimeout(() => {console.log("setTimeout");
}, 0);
process.nextTick(() => {console.log("process.nextTick");
});
输出如下
我们可以看到,就算定时器在前,并且延迟是0毫秒也会在process.nextTick后输出。
process.stdin、process.stdout、process.stderr
process.stdin、process.stdout、process.stderr 分别代表进程的标准输入、标准输出、标准错误输出。
process.stdin.setEncoding("utf8");
// 监听读取
process.stdin.on("readable", () => {var chunk = process.stdin.read();if (chunk !== null) {process.stdout.write(`data: ${chunk}`);}
});
// 读关闭
process.stdin.on("end", () => {process.stdout.write("stdin end");
});
执行程序,可以看到,程序通过 process.stdin 读取用户输入的同时,通过 process.stdout 将内容输出到控制台
hello
data: hello
world
data: world
child_process
我们知道,node 是单线程的,当有密集计算时就会出现性能瓶颈,child_process就是该性能瓶颈的一个解决方法。他能创建多个子进程分别处理,可以有效的提高程序的执行效率。
利用node提供的child_process模块,可以很容易的衍生出一个子进程,而且子进程之间可以通过事件消息系统进行互相通信。
node的child_process模块提供四种异步函数和三种同步函数的方式创建子进程:

spawn(command,[args],[options])
spawn启动一个子进程,并执行命令。
该方法参数如下:
- command, 需要运行的命令* args, 运行命令的参数, 是一个字符串数组* options, 配置项* shell
| true,则在 shell 内运行command* stdio| 环境变量键值对,默认值:process.env - 返回值 ChildProcess, 返回 ChildProcess 的实例下面我们举个简单的例子,创建一个子进程并执行
ls -al命令。
const childProcess = require("child_process");
const ls = childProcess.spawn("ls", ["-al"]);
ls.stdout.on("data", function (data) {console.log("data from child: " + data);
});
// 错误
ls.stderr.on("data", function (data) {console.log("error from child: " + data);
});
ls.on("close", function (code) {console.log("child exists with code: " + code);
});
输出如下

exec(command[, options][, callback])
exec方法将会生成一个子shell,然后在该 shell 中执行命令,并缓冲产生的数据,当子流程完成后,并将子进程的输出以回调函数参数的形式一次性返回。exec方法会从子进程中返回一个完整的buffer。
默认情况下,这个buffer的大小应该是200k。如果子进程返回的数据大小超过了200k,程序将会崩溃,同时显示错误信息“Error:maxBuffer exceeded”。你可以通过在exec的可选项中设置一个更大的buffer体积来解决这个问题,但是你不应该这样做,因为exec本来就不是用来返回很多数据的方法。
该方法参数如下:
- command, 需要运行的命令* options*
cwd:当前工作路径。*env:环境变量。*encoding:编码,默认是utf8。*shell:用来执行命令的shell,unix上默认是/bin/sh,windows上默认是cmd.exe。*timeout:默认是0。*killSignal:默认是SIGTERM。*uid:执行进程的uid。*gid:执行进程的gid。*maxBuffer: 标准输出、错误输出最大允许的数据量(单位为字节),如果超出的话,子进程就会被杀死。默认是200*1024(就是200k啦) - callback 回调函数,下面我们举个简单的例子,创建一个子进程并执行
ls -al命令。
const childProcess = require("child_process");
childProcess.exec("ls -al", {encoding: 'utf8'}, function (error, stdout, stderr) {if (error) {console.error("error: " + error);return;}console.log("stdout: " + stdout);
});
输出如下
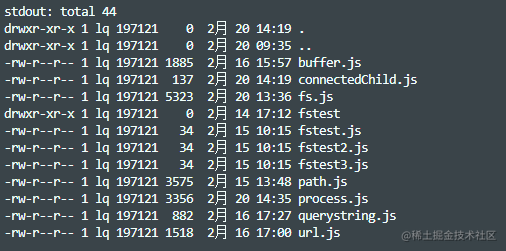
execFile(file[, args][, options][, callback])
child_process.execFile() 函数与 child_process.exec()类似,不同之处在于它默认不衍生 shell。 而是指定的可执行文件 file 直接作为新进程衍生,使其比 child_process.exec() 略有效率。
支持与 child_process.exec()相同的options。 由于未衍生 shell,因此不支持 I/O 重定向和文件通配等行为。
该方法参数如下:
- file, 可以是执行文件的名字,或者路径。* args, 运行命令的参数, 是一个字符串数组* options*
cwd:当前工作路径。*env:环境变量。*encoding:编码,默认是utf8。*shell:用来执行命令的shell,unix上默认是/bin/sh,windows上默认是cmd.exe。*timeout:默认是0。*killSignal:默认是SIGTERM。*uid:执行进程的uid。*gid:执行进程的gid。*maxBuffer: 标准输出、错误输出最大允许的数据量(单位为字节),如果超出的话,子进程就会被杀死。默认是200*1024(就是200k啦) - callback 回调函数下面我们举个简单的例子,创建一个子进程并执行
node --version命令。
const childProcess = require("child_process");
childProcess.execFile("node", ["--version"], function (error, stdout, stderr) {if (error) {throw error;}console.log("execFile", stdout); // execFile v14.21.1
});
fork(modulePath[, args][, options])
child_process.fork 是 spawn() 的特殊形式,用于在子进程中运行的模块,如 fork('./connectedChild.js') 相当于 spawn(‘node’, ['./connectedChild.js']) 。与spawn方法不同的是,fork会在父进程与子进程之间,建立一个通信管道,用于进程之间的通信。
该方法参数如下:
- modulePath, 需要在子进程中运行的模块地址* args, 字符串参数列表* options 配置项*
execPath: 用来创建子进程的可执行文件,默认是/usr/local/bin/node。也就是说,你可通过execPath来指定具体的node可执行文件路径。(比如多个node版本)*execArgv: 传给可执行文件的字符串参数列表。默认是process.execArgv,跟父进程保持一致。*silent: 默认是false,即子进程的stdio从父进程继承。如果是true,则直接pipe向子进程的child.stdin、child.stdout等。*stdio: 如果声明了stdio,则会覆盖silent选项的设置。
下面我们举个简单的例子,创建一个子进程,并完成父子进程的通信。
// connectedChild.js
// 监听主进程传递来的数据
process.on("message", (msg) => {console.log("Message from parent:", msg);// 如果当前进程是子进程,且与父进程之间通过IPC通道连接着,则process.connected为trueconsole.log("process.connected: " + process.connected);
});
// 发送数据给主进程
setTimeout(() => {process.send({ name: "child message" });// 断开与父进程之间的IPC通道,此时会将 process.connected 置为falseprocess.disconnect();console.log("process.connected: " + process.connected);
}, 1000);
主进程通过fork创建一个子进程执行connectedChild.js。
const childProcess = require("child_process");
const forked = childProcess.fork("./connectedChild.js");
// 发送数据给子进程
forked.send({ hello: "world" });
// 监听子进程发送来的数据
forked.on("message", (msg) => {console.log("Message from child", msg);
});
输出如下

总结
1.fork 和 spawn 方法返回的是一个stream2.exec 和 execFile 方法会把执行结果放在callback中3.execFile 会执行一个文件,跟exec不一样的地方在于,他不创建一个shell。4 fork 是 spawn 的一种变体,在创建子进程的时候,进程之间会建立IPC通信channel,并通过 on(‘message’, callbak), send(jsonobject) 来交换数据。
5.fork、exec、execFile都是基于spawn的封装。
cluster
前面我们介绍了child_process模块,该模块主要用来创建子进程,产生多个子进程,这样就可以使用多核CPU,充分利用了服务器的资源。但是child_process模块需要我们手动创建子进程并管理。但是Node的 cluster 模块,提供了开箱即用的子进程创建功能,使用的好能大大提高我们系统的可用性和稳定性。接下来让我们去详细了解一下。
cluster 模块基于child_process模块的fork方法,多次fork主进程,产生多个子进程,这样就可以使用多核CPU,充分利用了服务器的资源。
这种方式 主进程监听一个端口,子进程不监听端口,通过主进程分发请求到子进程,实现负载均衡
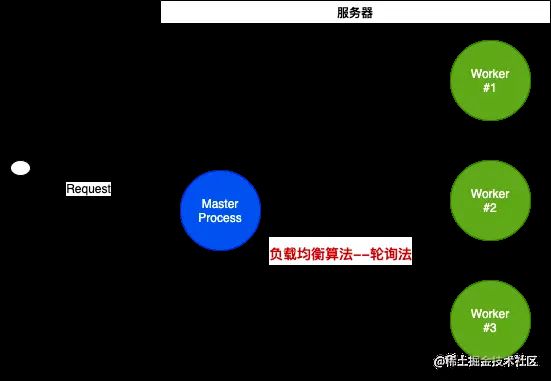
在 cluster 模式中存在 master 和 worker 的概念,master 就是主进程,worker 则是子进程。master会通过fork产生多个worker,并管理他们。每一个worker代表着一个应用程序的实例。
master会接收所有的请求,并通过负载均衡算法(round-robin)分发给子进程。Linux服务器默认会开启这个功能,并且可以全局修改以让操作系统本身支持负载均衡。
负载均衡算法在轮询的基础上在所有可用进程之间平均分配负载。第一个请求被转发到第一个worker 进程,第二个请求转发到列表中的下一个worker 进程,依此类推。当到达列表的末尾时,算法又从头开始。
提高服务器的可用性
下面我们举个简单的例子
// server.js
const cluster = require("cluster");
const http = require("http");
console.log(cluster.isMaster, process.pid);
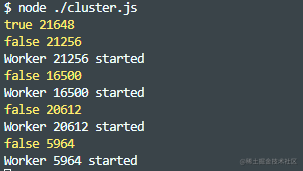
if (cluster.isMaster) {for (var i = 0; i < 4; i++) {cluster.fork();}
} else {http.createServer(function (req, res) {res.end(`response from worker ${process.pid}`);}).listen(3000);console.log(`Worker ${process.pid} started`);
}
执行我们的server.js,如果是主程序就会创建子进程,如果是子进程就会创建http服务。
node ./server.js
输出如下
创建批处理脚本:.req.sh。批量执行请求。
#!/bin/bash
# req.sh
for((i=1;i<=4;i++)); do curl http://127.0.0.1:3000echo ""
done
执行脚本,输出如下。可以看到,响应来自不同的进程。
response from worker 21256
response from worker 21256
response from worker 20612
response from worker 5964
从这里我们可以看出,通过集群创建多个子进程来运行我们的服务,能充分利用电脑多核的优势,能大大提高我们系统的可用性。
说完了cluster的简单使用,接下来我们来讨论下面三个问题。
1. master、worker如何通信
这个问题比较简单。master进程通过 cluster.fork() 来创建 worker 进程。cluster.fork() 内部是通过 child_process.fork() 来创建子进程。
也就是说:
1.master进程、worker进程是父、子进程的关系。
2.master进程、woker进程可以通过IPC通道进行通信。
2. 如何实现端口共享
在前面的例子中,多个woker中创建的server监听了同个端口3000。通常来说,多个进程监听同个端口,系统会报错。
为什么我们的例子没问题呢?
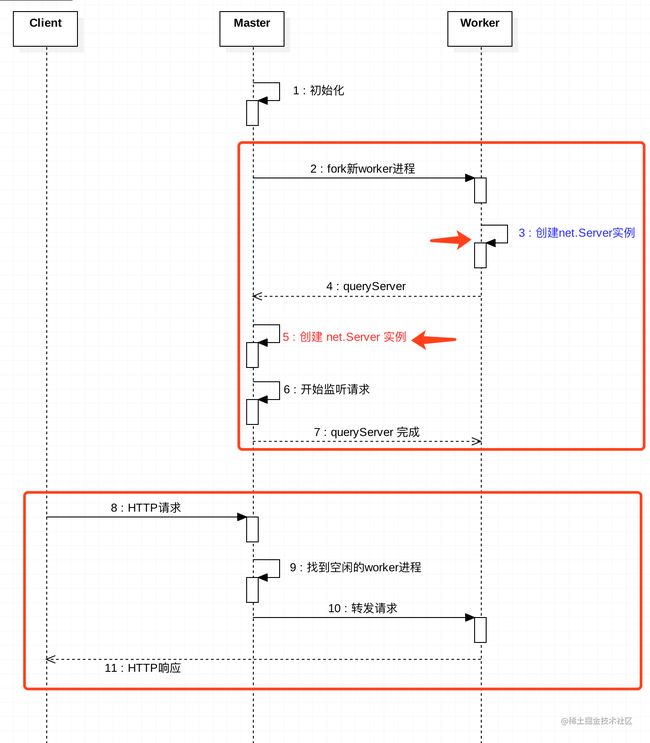
秘密在于,net模块中,对 listen() 方法进行了特殊处理。根据当前进程是master进程,还是worker进程:
1.master进程:在该端口上正常监听请求。(没做特殊处理)
2.worker进程:创建server实例。然后通过IPC通道,向master进程发送消息,让master进程也创建 server 实例,并在该端口上监听请求。当请求进来时,master进程将请求转发给worker进程的server实例。
归纳起来,就是:master进程监听特定端口,并将客户请求转发给worker进程。
如下图所示:
3. 如何将请求分发到多个worker
每当worker进程创建server实例来监听请求,都会通过IPC通道,在master上进行注册。当客户端请求到达,master会负责将请求转发给对应的worker。
具体转发给哪个worker?这是由转发策略决定的。可以通过环境变量NODE_CLUSTER_SCHED_POLICY设置,也可以在cluster.setupMaster(options)时传入。
默认的转发策略是轮询(SCHED_RR)。
当有客户请求到达,master会轮询一遍worker列表,找到第一个空闲的worker,然后将该请求转发给该worker。
提高服务器的稳定性
单个实例运行Node应用程序,当实例崩溃时,该实例必须重启。这会导致这两个操作之间会出现一些停机事件,即使该过程是自动化的,也会有时间差。而且,单个实例的情况下部署新的代码,也需要停机。
所以运行多个实例,可以避免这个问题。
下面模拟服务器的随机停机:
// worker 子进程 server.js
setTimeout(() => {process.exit(1)
}, Math.random()*10000);
master 进程监听 退出事件,给事件注册一个处理程序,并在任何worker进程退出时创建一个新的woker进程
//master 主进程 cluster.js
cluster.on("exit", (worker, code, signal) => {if (code !== 0 && !worker.exitedAfterDisconnect) {console.log(`Worker ${worker.id} crashed.` + "Starting a new worker...");cluster.fork();}
});
代码中添加了一个处理程序,并判断了worker进程退出时,重新创建一个worker进程。这层判断 排除了主进程手动断开或者杀死的情况。
如果使用了太多的服务器资源,master会根据需要通过disconnect方法杀死一些worker进程,这种情况下 worker.exitedAfterDisconnect值为true,并不需要重新创建一个worker进程。
最后
最近找到一个VUE的文档,它将VUE的各个知识点进行了总结,整理成了《Vue 开发必须知道的36个技巧》。内容比较详实,对各个知识点的讲解也十分到位。




有需要的小伙伴,可以点击下方卡片领取,无偿分享