Linux内存映射
1 概述
内存映射将用户态的虚拟地址空间区域和内核态的物理内存映射起来。mmap(memory map)实现了内存映射。从映射区域的内容是否和文件内容关联的视角来看,可以分为文件映射和匿名映射;从多个进程间是否共享映射的区域来看,可以分为共享映射和私有映射。
本文主要主要从下面几个方面逐层展开论述:
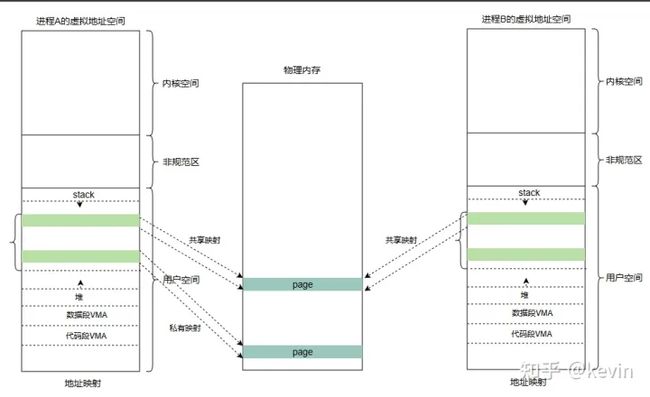
图1-1
1)虚拟内存区域( vm_area_struct );
2)内存映射的原理和创建删除映射;
3)页异常处理,包括文件页和匿名页;
2 虚拟内存区域
2.1 vma抽象
内核使用 struct vm_area_struct 结构来管理进程的虚拟内存区域,一个 struct vm_area_struct 对象就是一段进程虚拟地址空间的地址,当进程需要使用内存时,首先要向操作系统进行申请,操作系统会使用 vm_area_struct 结构来记录被分配出去的内存区的大小、起始地址和权限等。

图2-1-1
/*
* This struct describes a virtual memory area. There is one of these
* per VM-area/task. A VM area is any part of the process virtual memory
* space that has a special rule for the page-fault handlers (ie a shared
* library, the executable area etc).
*/
struct vm_area_struct {
/* The first cache line has the info for VMA tree walking. */
unsigned long vm_start; /* Our start address within vm_mm. */ //1 描述vma的开始地址
unsigned long vm_end; /* The first byte after our end address //2 描述vma的结束地址
within vm_mm. */
/* linked list of VM areas per task, sorted by address */
struct vm_area_struct *vm_next, *vm_prev; //3 指向下一个vma
struct rb_node vm_rb; //4 vma 插入rb树的节点
/*
* Largest free memory gap in bytes to the left of this VMA.
* Either between this VMA and vma->vm_prev, or between one of the
* VMAs below us in the VMA rbtree and its ->vm_prev. This helps
* get_unmapped_area find a free area of the right size.
*/
unsigned long rb_subtree_gap; //5 vma之间留有的最大空隙,方便查找没有映射的vma区域
/* Second cache line starts here. */
struct mm_struct *vm_mm; /* The address space we belong to. */ //6 指向该vma属于的进程地址空间描述符mm_struct
/*
* Access permissions of this VMA.
* See vmf_insert_mixed_prot() for discussion.
*/
pgprot_t vm_page_prot; //7 vma对应page的属性
unsigned long vm_flags; /* Flags, see mm.h. */ //8 vma的标志,mm.h定义
/*
* For areas with an address space and backing store,
* linkage into the address_space->i_mmap interval tree.
*/
struct {
struct rb_node rb;
unsigned long rb_subtree_last;
} shared; //9 区间树使用
/*
* A file's MAP_PRIVATE vma can be in both i_mmap tree and anon_vma
* list, after a COW of one of the file pages. A MAP_SHARED vma
* can only be in the i_mmap tree. An anonymous MAP_PRIVATE, stack
* or brk vma (with NULL file) can only be in an anon_vma list.
*/
struct list_head anon_vma_chain; /* Serialized by mmap_lock &
* page_table_lock */ //10 关联anon 映射,逆向映射时会用到
struct anon_vma *anon_vma; /* Serialized by page_table_lock */ //11
/* Function pointers to deal with this struct. */
const struct vm_operations_struct *vm_ops; //12 定义了操作vma的一组函数指针
/* Information about our backing store: */
unsigned long vm_pgoff; /* Offset (within vm_file) in PAGE_SIZE
units */ //13 这个vma在文件内的offset
struct file * vm_file; /* File we map to (can be NULL). */ //14 vma关联的文件指针,或者NULL
void * vm_private_data; /* was vm_pte (shared mem) */ //15
#ifdef CONFIG_SWAP
atomic_long_t swap_readahead_info; //16 和swap预读相关的
#endif
#ifndef CONFIG_MMU
struct vm_region *vm_region; /* NOMMU mapping region */ //17
#endif
#ifdef CONFIG_NUMA
struct mempolicy *vm_policy; /* NUMA policy for the VMA */ //18
#endif
struct vm_userfaultfd_ctx vm_userfaultfd_ctx; //19
} __randomize_layout;
1)vm_start 描述虚拟内存区域的开始地址;
2)vm_end 描述虚拟内存区域的结束地址;
3)vm_next 指向下一个vma;
vm_prev 指向前一个vma;
4)vm_rb vma 插入rb树的节点;
5)rb_subtree_gap 有注释,vma之间留有的最大空隙,方便查找没有映射的vma区域;
6)vm_mm 指向该vma属于的进程地址空间描述符mm_struct;
7)vm_page_prot vma对应page的属性;
8)vm_flags 有注释,vma的标志,mm.h定义;
9)区间树使用;
10)anon_vma_chain 有注释,关联anon 映射,逆向映射时会用到;
11)anon_vma 有注释,逆向映射时使用;
12)vm_ops 定义了操作vma的一组函数指针;
13)vm_pgoff 这个vma在文件内的offset(页为单位的);
14)vm_file 有注释,vma关联的文件指针,或者NULL;
15)vm_private_data 有注释,暂时没明白这个成员;
16)swap_readahead_info 和swap预读相关的,暂时没看到代码;
17)vm_region 没有MMU会用到,不关注;
18)vm_policy NUMA用到,先不关注;
19)vm_userfaultfd_ctx 暂时没看到过代码,先不关注;
vm_operations_struct
vm_operations_struct描述vma相关的操作,其中fault成员表示当虚拟内存区没有映射到物理内存地址时,将会触发缺页异常。而在缺页异常处理中,将会调用此回调函数来对虚拟内存映射到物理内存。
/*
* These are the virtual MM functions - opening of an area, closing and
* unmapping it (needed to keep files on disk up-to-date etc), pointer
* to the functions called when a no-page or a wp-page exception occurs.
*/
struct vm_operations_struct {
void (*open)(struct vm_area_struct * area);
void (*close)(struct vm_area_struct * area);
/* Called any time before splitting to check if it's allowed */
int (*may_split)(struct vm_area_struct *area, unsigned long addr);
int (*mremap)(struct vm_area_struct *area, unsigned long flags);
/*
* Called by mprotect() to make driver-specific permission
* checks before mprotect() is finalised. The VMA must not
* be modified. Returns 0 if eprotect() can proceed.
*/
int (*mprotect)(struct vm_area_struct *vma, unsigned long start,
unsigned long end, unsigned long newflags);
vm_fault_t (*fault)(struct vm_fault *vmf); //1
vm_fault_t (*huge_fault)(struct vm_fault *vmf,
enum page_entry_size pe_size);
void (*map_pages)(struct vm_fault *vmf,
pgoff_t start_pgoff, pgoff_t end_pgoff);
unsigned long (*pagesize)(struct vm_area_struct * area);
/* notification that a previously read-only page is about to become
* writable, if an error is returned it will cause a SIGBUS */
vm_fault_t (*page_mkwrite)(struct vm_fault *vmf);
/* same as page_mkwrite when using VM_PFNMAP|VM_MIXEDMAP */
vm_fault_t (*pfn_mkwrite)(struct vm_fault *vmf);
/* called by access_process_vm when get_user_pages() fails, typically
* for use by special VMAs that can switch between memory and hardware
*/
int (*access)(struct vm_area_struct *vma, unsigned long addr,
void *buf, int len, int write);
/* Called by the /proc/PID/maps code to ask the vma whether it
* has a special name. Returning non-NULL will also cause this
* vma to be dumped unconditionally. */
const char *(*name)(struct vm_area_struct *vma);
#ifdef CONFIG_NUMA
/*
* set_policy() op must add a reference to any non-NULL @new mempolicy
* to hold the policy upon return. Caller should pass NULL @new to
* remove a policy and fall back to surrounding context--i.e. do not
* install a MPOL_DEFAULT policy, nor the task or system default
* mempolicy.
*/
int (*set_policy)(struct vm_area_struct *vma, struct mempolicy *new);
/*
* get_policy() op must add reference [mpol_get()] to any policy at
* (vma,addr) marked as MPOL_SHARED. The shared policy infrastructure
* in mm/mempolicy.c will do this automatically.
* get_policy() must NOT add a ref if the policy at (vma,addr) is not
* marked as MPOL_SHARED. vma policies are protected by the mmap_lock.
* If no [shared/vma] mempolicy exists at the addr, get_policy() op
* must return NULL--i.e., do not "fallback" to task or system default
* policy.
*/
struct mempolicy *(*get_policy)(struct vm_area_struct *vma,
unsigned long addr);
#endif
/*
* Called by vm_normal_page() for special PTEs to find the
* page for @addr. This is useful if the default behavior
* (using pte_page()) would not find the correct page.
*/
struct page *(*find_special_page)(struct vm_area_struct *vma,
unsigned long addr);
};
static inline void vma_init(struct vm_area_struct *vma, struct mm_struct *mm)
{
static const struct vm_operations_struct dummy_vm_ops = {};
memset(vma, 0, sizeof(*vma));
vma->vm_mm = mm;
vma->vm_ops = &dummy_vm_ops;
INIT_LIST_HEAD(&vma->anon_vma_chain);
}
1)fault 函数指针,当虚拟内存区没有映射到物理内存地址时,将会触发缺页异常。而在缺页异常处理中,将会调用此回调函数来对虚拟内存映射到物理内存。
2.2 vma组织
进程的虚拟内存区域vma按照顺序通过两种结构组织起来;
单链表,链表头mm->mmap
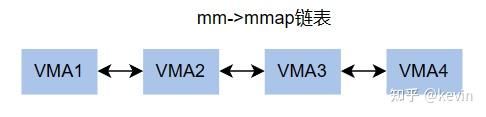
图2-2-1
rb树,根节点mm->mm_rb

图2-2-2
2.3 vma属性
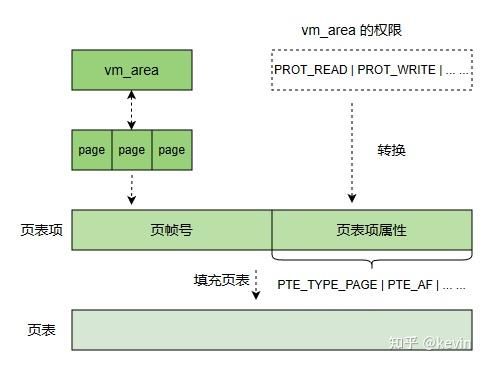
图2-3-1
include/linux/mm.h
/*
* vm_flags in vm_area_struct, see mm_types.h.
* When changing, update also include/trace/events/mmflags.h
*/
#define VM_NONE 0x00000000
#define VM_READ 0x00000001 /* currently active flags */ //1
#define VM_WRITE 0x00000002 //2 可写属性
#define VM_EXEC 0x00000004 //3
#define VM_SHARED 0x00000008 //4
/* mprotect() hardcodes VM_MAYREAD >> 4 == VM_READ, and so for r/w/x bits. */
#define VM_MAYREAD 0x00000010 /* limits for mprotect() etc */ //5
#define VM_MAYWRITE 0x00000020
#define VM_MAYEXEC 0x00000040
#define VM_MAYSHARE 0x00000080
#define VM_GROWSDOWN 0x00000100 /* general info on the segment */
#define VM_UFFD_MISSING 0x00000200 /* missing pages tracking */
#define VM_PFNMAP 0x00000400 /* Page-ranges managed without "struct page", just pure PFN */
#define VM_DENYWRITE 0x00000800 /* ETXTBSY on write attempts.. */
#define VM_UFFD_WP 0x00001000 /* wrprotect pages tracking */
#define VM_LOCKED 0x00002000
#define VM_IO 0x00004000 /* Memory mapped I/O or similar */
/* Used by sys_madvise() */
#define VM_SEQ_READ 0x00008000 /* App will access data sequentially */
#define VM_RAND_READ 0x00010000 /* App will not benefit from clustered reads */
#define VM_DONTCOPY 0x00020000 /* Do not copy this vma on fork */
#define VM_DONTEXPAND 0x00040000 /* Cannot expand with mremap() */
#define VM_LOCKONFAULT 0x00080000 /* Lock the pages covered when they are faulted in */
#define VM_ACCOUNT 0x00100000 /* Is a VM accounted object */
#define VM_NORESERVE 0x00200000 /* should the VM suppress accounting */
#define VM_HUGETLB 0x00400000 /* Huge TLB Page VM */
#define VM_SYNC 0x00800000 /* Synchronous page faults */
#define VM_ARCH_1 0x01000000 /* Architecture-specific flag */
#define VM_WIPEONFORK 0x02000000 /* Wipe VMA contents in child. */
#define VM_DONTDUMP 0x04000000 /* Do not include in the core dump */
#ifdef CONFIG_MEM_SOFT_DIRTY
# define VM_SOFTDIRTY 0x08000000 /* Not soft dirty clean area */
#else
# define VM_SOFTDIRTY 0
#endif
#define VM_MIXEDMAP 0x10000000 /* Can contain "struct page" and pure PFN pages */
#define VM_HUGEPAGE 0x20000000 /* MADV_HUGEPAGE marked this vma */
#define VM_NOHUGEPAGE 0x40000000 /* MADV_NOHUGEPAGE marked this vma */
#define VM_MERGEABLE 0x80000000 /* KSM may merge identical pages */
1)VM_READ 可读属性
2)VM_WRITE 可写属性
3)VM_EXEC 可执行属性
4)VM_SHARED 允许被多个进程共享
5)VM_MAYREAD 允许设置VM_READ
6)VM_MAYWRITE 允许设置VM_WRITE
7)VM_MAYEXEC 允许设置VM_EXEC
8)VM_MAYSHARE 允许设置VM_SHARED
9)VM_GROWSDOWN 该VM向地址增长
10)VM_UFFD_MISSING 该VMA适用于用户态的缺页异常处理
11)VM_PFNMAP 使用纯正的PFN,不需要使用内核page结构来管理页面
12)VM_DENYWRITE 不允许写入
13)VM_UFFD_WP 页面写保护跟踪
14)VM_LOCKED 该vma的内存会立刻分配物理内存,并且页面被锁定,不会被交换到交换区
15)VM_IO IO内存映射
16)VM_SEQ_READ 应用程序会顺序读vma
17)VM_RAND_READ 应用程序会随机读vma
18)VM_DONTCOPY fork时不要复制该vma
19)VM_DONTEXPND 系统调用mremap禁止扩展vma
将vma的标志转化为页表项的硬件标志
pgprot_t vm_get_page_prot(unsigned long vm_flags)
{
pgprot_t ret = __pgprot(pgprot_val(protection_map[vm_flags &
(VM_READ|VM_WRITE|VM_EXEC|VM_SHARED)]) |
pgprot_val(arch_vm_get_page_prot(vm_flags)));
return arch_filter_pgprot(ret);
}
EXPORT_SYMBOL(vm_get_page_prot);
/* description of effects of mapping type and prot in current implementation.
* this is due to the limited x86 page protection hardware. The expected
* behavior is in parens:
*
* map_type prot
* PROT_NONE PROT_READ PROT_WRITE PROT_EXEC
* MAP_SHARED r: (no) no r: (yes) yes r: (no) yes r: (no) yes
* w: (no) no w: (no) no w: (yes) yes w: (no) no
* x: (no) no x: (no) yes x: (no) yes x: (yes) yes
*
* MAP_PRIVATE r: (no) no r: (yes) yes r: (no) yes r: (no) yes
* w: (no) no w: (no) no w: (copy) copy w: (no) no
* x: (no) no x: (no) yes x: (no) yes x: (yes) yes
*
* On arm64, PROT_EXEC has the following behaviour for both MAP_SHARED and
* MAP_PRIVATE (with Enhanced PAN supported):
* r: (no) no
* w: (no) no
* x: (yes) yes
*/
pgprot_t protection_map[16] __ro_after_init = {
__P000, __P001, __P010, __P011, __P100, __P101, __P110, __P111,
__S000, __S001, __S010, __S011, __S100, __S101, __S110, __S111
};
#define PAGE_NONE __pgprot(((_PAGE_DEFAULT) & ~PTE_VALID) | PTE_PROT_NONE | PTE_RDONLY | PTE_NG | PTE_PXN | PTE_UXN)
/* shared+writable pages are clean by default, hence PTE_RDONLY|PTE_WRITE */
#define PAGE_SHARED __pgprot(_PAGE_DEFAULT | PTE_USER | PTE_RDONLY | PTE_NG | PTE_PXN | PTE_UXN | PTE_WRITE)
#define PAGE_SHARED_EXEC __pgprot(_PAGE_DEFAULT | PTE_USER | PTE_RDONLY | PTE_NG | PTE_PXN | PTE_WRITE)
#define PAGE_READONLY __pgprot(_PAGE_DEFAULT | PTE_USER | PTE_RDONLY | PTE_NG | PTE_PXN | PTE_UXN)
#define PAGE_READONLY_EXEC __pgprot(_PAGE_DEFAULT | PTE_USER | PTE_RDONLY | PTE_NG | PTE_PXN)
#define PAGE_EXECONLY __pgprot(_PAGE_DEFAULT | PTE_RDONLY | PTE_NG | PTE_PXN)
#define __P000 PAGE_NONE
#define __P001 PAGE_READONLY
#define __P010 PAGE_READONLY
#define __P011 PAGE_READONLY
#define __P100 PAGE_EXECONLY
#define __P101 PAGE_READONLY_EXEC
#define __P110 PAGE_READONLY_EXEC
#define __P111 PAGE_READONLY_EXEC
#define __S000 PAGE_NONE
#define __S001 PAGE_READONLY
#define __S010 PAGE_SHARED
#define __S011 PAGE_SHARED
#define __S100 PAGE_EXECONLY
#define __S101 PAGE_READONLY_EXEC
#define __S110 PAGE_SHARED_EXEC
#define __S111 PAGE_SHARED_EXEC
2.4 vma操作
2.4.1 查找区域
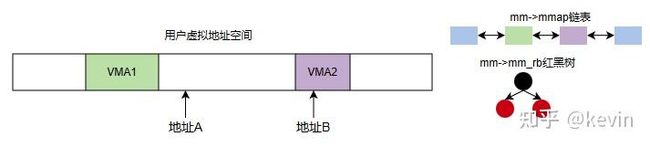
图2-4-1
/* Look up the first VMA which satisfies addr < vm_end, NULL if none. */
struct vm_area_struct *find_vma(struct mm_struct *mm, unsigned long addr)
{
struct rb_node *rb_node;
struct vm_area_struct *vma;
/* Check the cache first. */
vma = vmacache_find(mm, addr); //1
if (likely(vma))
return vma;
rb_node = mm->mm_rb.rb_node; //2
while (rb_node) {
struct vm_area_struct *tmp;
tmp = rb_entry(rb_node, struct vm_area_struct, vm_rb);
if (tmp->vm_end > addr) {
vma = tmp;
if (tmp->vm_start <= addr)
break;
rb_node = rb_node->rb_left;
} else
rb_node = rb_node->rb_right;
}
if (vma) //3
vmacache_update(addr, vma);
return vma;
}
EXPORT_SYMBOL(find_vma);
/*
* The per task VMA cache array:
*/
#define VMACACHE_BITS 2
#define VMACACHE_SIZE (1U << VMACACHE_BITS)
#define VMACACHE_MASK (VMACACHE_SIZE - 1)
struct vmacache {
u64 seqnum;
struct vm_area_struct *vmas[VMACACHE_SIZE];
};
满足vm->vm_startvma_end条件的第一个区域
1)到当前进程current的vmacache[VMACACHE_SIZE]数组去找,这个是某个内核版本加入的优化,之前vmacache是只有一个vma
2)到rb树去找
3)把找到的vma加到vmacahe,返回找到的vma
2.4.2 区域合并
新区域加入进程的地址空间时,内核会检查该区域是否可以与一个或多个现存区域合并,vma_merge函数实现将一个vma和附近的vma合并;

图2-4-2
/*
* Given a mapping request (addr,end,vm_flags,file,pgoff), figure out
* whether that can be merged with its predecessor or its successor.
* Or both (it neatly fills a hole).
*
* In most cases - when called for mmap, brk or mremap - [addr,end) is
* certain not to be mapped by the time vma_merge is called; but when
* called for mprotect, it is certain to be already mapped (either at
* an offset within prev, or at the start of next), and the flags of
* this area are about to be changed to vm_flags - and the no-change
* case has already been eliminated.
*
* The following mprotect cases have to be considered, where AAAA is
* the area passed down from mprotect_fixup, never extending beyond one
* vma, PPPPPP is the prev vma specified, and NNNNNN the next vma after:
*
* AAAA AAAA AAAA
* PPPPPPNNNNNN PPPPPPNNNNNN PPPPPPNNNNNN
* cannot merge might become might become
* PPNNNNNNNNNN PPPPPPPPPPNN
* mmap, brk or case 4 below case 5 below
* mremap move:
* AAAA AAAA
* PPPP NNNN PPPPNNNNXXXX
* might become might become
* PPPPPPPPPPPP 1 or PPPPPPPPPPPP 6 or
* PPPPPPPPNNNN 2 or PPPPPPPPXXXX 7 or
* PPPPNNNNNNNN 3 PPPPXXXXXXXX 8
*
* It is important for case 8 that the vma NNNN overlapping the
* region AAAA is never going to extended over XXXX. Instead XXXX must
* be extended in region AAAA and NNNN must be removed. This way in
* all cases where vma_merge succeeds, the moment vma_adjust drops the
* rmap_locks, the properties of the merged vma will be already
* correct for the whole merged range. Some of those properties like
* vm_page_prot/vm_flags may be accessed by rmap_walks and they must
* be correct for the whole merged range immediately after the
* rmap_locks are released. Otherwise if XXXX would be removed and
* NNNN would be extended over the XXXX range, remove_migration_ptes
* or other rmap walkers (if working on addresses beyond the "end"
* parameter) may establish ptes with the wrong permissions of NNNN
* instead of the right permissions of XXXX.
*/
struct vm_area_struct *vma_merge(struct mm_struct *mm,
struct vm_area_struct *prev, unsigned long addr,
unsigned long end, unsigned long vm_flags,
struct anon_vma *anon_vma, struct file *file,
pgoff_t pgoff, struct mempolicy *policy,
struct vm_userfaultfd_ctx vm_userfaultfd_ctx)
{
pgoff_t pglen = (end - addr) >> PAGE_SHIFT;
struct vm_area_struct *area, *next;
int err;
/*
* We later require that vma->vm_flags == vm_flags,
* so this tests vma->vm_flags & VM_SPECIAL, too.
*/
if (vm_flags & VM_SPECIAL) //1
return NULL;
next = vma_next(mm, prev); //2
area = next;
if (area && area->vm_end == end) /* cases 6, 7, 8 */
next = next->vm_next; //3
/* verify some invariant that must be enforced by the caller */
VM_WARN_ON(prev && addr <= prev->vm_start);
VM_WARN_ON(area && end > area->vm_end);
VM_WARN_ON(addr >= end);
/*
* Can it merge with the predecessor?
*/
if (prev && prev->vm_end == addr &&
mpol_equal(vma_policy(prev), policy) &&
can_vma_merge_after(prev, vm_flags,
anon_vma, file, pgoff,
vm_userfaultfd_ctx)) {
/*
* OK, it can. Can we now merge in the successor as well?
*/
if (next && end == next->vm_start &&
mpol_equal(policy, vma_policy(next)) &&
can_vma_merge_before(next, vm_flags,
anon_vma, file,
pgoff+pglen,
vm_userfaultfd_ctx) &&
is_mergeable_anon_vma(prev->anon_vma,
next->anon_vma, NULL)) {
/* cases 1, 6 */
err = __vma_adjust(prev, prev->vm_start,
next->vm_end, prev->vm_pgoff, NULL,
prev);
} else /* cases 2, 5, 7 */
err = __vma_adjust(prev, prev->vm_start,
end, prev->vm_pgoff, NULL, prev);
if (err)
return NULL;
khugepaged_enter_vma_merge(prev, vm_flags);
return prev;
}
/*
* Can this new request be merged in front of next?
*/
if (next && end == next->vm_start &&
mpol_equal(policy, vma_policy(next)) &&
can_vma_merge_before(next, vm_flags,
anon_vma, file, pgoff+pglen,
vm_userfaultfd_ctx)) {
if (prev && addr < prev->vm_end) /* case 4 */
err = __vma_adjust(prev, prev->vm_start,
addr, prev->vm_pgoff, NULL, next);
else { /* cases 3, 8 */
err = __vma_adjust(area, addr, next->vm_end,
next->vm_pgoff - pglen, NULL, next);
/*
* In case 3 area is already equal to next and
* this is a noop, but in case 8 "area" has
* been removed and next was expanded over it.
*/
area = next;
}
if (err)
return NULL;
khugepaged_enter_vma_merge(area, vm_flags);
return area;
}
return NULL;
}
1)新vma的起始地址和prev节点结束地址重叠
2)新vma的结束地址和next的起始地址重叠
3)新vma和prev和next节点正好接上
2.4.3 插入区域
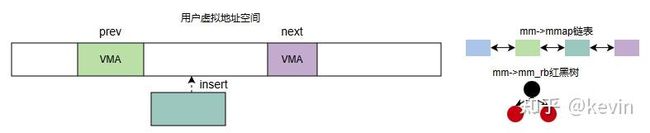
图2-4-3
/* Insert vm structure into process list sorted by address
* and into the inode's i_mmap tree. If vm_file is non-NULL
* then i_mmap_rwsem is taken here.
*/
int insert_vm_struct(struct mm_struct *mm, struct vm_area_struct *vma)
{
struct vm_area_struct *prev;
struct rb_node **rb_link, *rb_parent;
if (find_vma_links(mm, vma->vm_start, vma->vm_end,
&prev, &rb_link, &rb_parent))
return -ENOMEM;
if ((vma->vm_flags & VM_ACCOUNT) &&
security_vm_enough_memory_mm(mm, vma_pages(vma)))
return -ENOMEM;
/*
* The vm_pgoff of a purely anonymous vma should be irrelevant
* until its first write fault, when page's anon_vma and index
* are set. But now set the vm_pgoff it will almost certainly
* end up with (unless mremap moves it elsewhere before that
* first wfault), so /proc/pid/maps tells a consistent story.
*
* By setting it to reflect the virtual start address of the
* vma, merges and splits can happen in a seamless way, just
* using the existing file pgoff checks and manipulations.
* Similarly in do_mmap and in do_brk_flags.
*/
if (vma_is_anonymous(vma)) {
BUG_ON(vma->anon_vma);
vma->vm_pgoff = vma->vm_start >> PAGE_SHIFT;
}
vma_link(mm, vma, prev, rb_link, rb_parent);
return 0;
}
2.4.4 创建区域

图2-4-4
unsigned long
get_unmapped_area(struct file *file, unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags)
{
unsigned long (*get_area)(struct file *, unsigned long,
unsigned long, unsigned long, unsigned long);
unsigned long error = arch_mmap_check(addr, len, flags);
if (error)
return error;
/* Careful about overflows.. */
if (len > TASK_SIZE)
return -ENOMEM;
get_area = current->mm->get_unmapped_area;
if (file) {
if (file->f_op->get_unmapped_area)
get_area = file->f_op->get_unmapped_area;
} else if (flags & MAP_SHARED) {
/*
* mmap_region() will call shmem_zero_setup() to create a file,
* so use shmem's get_unmapped_area in case it can be huge.
* do_mmap() will clear pgoff, so match alignment.
*/
pgoff = 0;
get_area = shmem_get_unmapped_area;
}
addr = get_area(file, addr, len, pgoff, flags);
if (IS_ERR_VALUE(addr))
return addr;
if (addr > TASK_SIZE - len)
return -ENOMEM;
if (offset_in_page(addr))
return -EINVAL;
error = security_mmap_addr(addr);
return error ? error : addr;
}
EXPORT_SYMBOL(get_unmapped_area);
2.4.5 区域判断
1)判断vma是否是私有匿名的
static inline bool vma_is_anonymous(struct vm_area_struct *vma)
{
return !vma->vm_ops;
}
2)判断vma是否为栈,通过栈的增长方向判断
static inline bool vma_is_temporary_stack(struct vm_area_struct *vma)
{
int maybe_stack = vma->vm_flags & (VM_GROWSDOWN | VM_GROWSUP);
if (!maybe_stack)
return false;
if ((vma->vm_flags & VM_STACK_INCOMPLETE_SETUP) ==
VM_STACK_INCOMPLETE_SETUP)
return true;
return false;
}
static inline bool vma_is_foreign(struct vm_area_struct *vma)
{
if (!current->mm)
return true;
if (current->mm != vma->vm_mm)
return true;
return false;
}
3)判断区域是否可以访问
static inline bool vma_is_accessible(struct vm_area_struct *vma)
{
return vma->vm_flags & VM_ACCESS_FLAGS;
}
4)判断vma是否是shmem通过vma->vm_ops ==&shmem_vm_ops
#ifdef CONFIG_SHMEM
/*
* The vma_is_shmem is not inline because it is used only by slow
* paths in userfault.
*/
bool vma_is_shmem(struct vm_area_struct *vma);
#else
static inline bool vma_is_shmem(struct vm_area_struct *vma) { return false; }
#endif
bool vma_is_shmem(struct vm_area_struct *vma)
{
return vma->vm_ops == &shmem_vm_ops;
} 3 内存映射
3.1 实现原理
内存映射实现进程虚拟地址空间和实际物理页帧之间的映射,由于用户进程总的虚拟地址空间比可以使用的物理内存大的多,因此只有最常用的部分才与物理页帧关联。进程试图访问用户空间一个虚拟地址,但页表无法确定物理地址(映射未建立);处理器接下来触发一个缺页异常,内核处理缺页异常。缺页异常处理中检查缺页区域的进程地址空间数据结构,确认访问是否是否正确,正确访问的映射类型(匿名or文件),然后分配物理页(如果是文件映射从后备存储器读取所需数据填充物理页),最后建立页表将物理页映射到进程的虚拟虚拟地址空间,应用恢复执行。这些操作对用户进程来说是透明的,也就是说用户进程不会关注到物理页和虚拟地址已经建立映射还是访问后触发缺页异常处理后建立映射的。
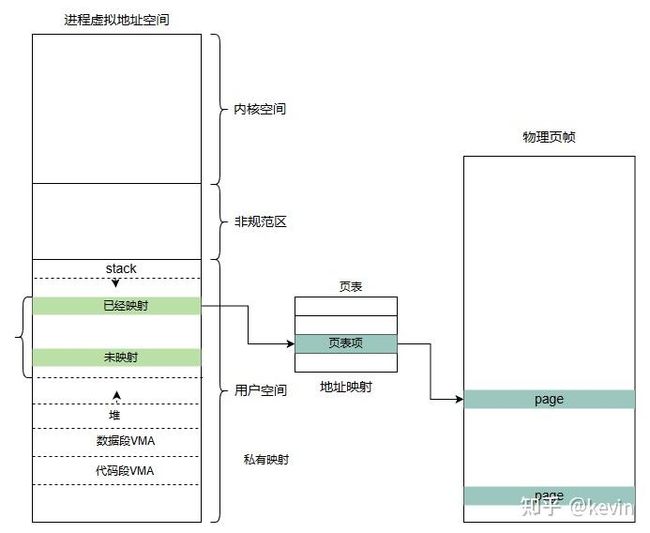
图3-1-1
3.2 创建映射
3.2.1 函数原型
void *
mmap(void *addr, size_t len, int prot, int flags, int fd, off_t offset);addr:用于指定映射到进程地址空间的起始地址,如果是NULL,让内核来分配一个合适的地址;
length:映射到进程地址空间的大小;
prot:设置内存映射区域的读写属性等;
#define PROT_READ 0x1 /* page can be read */
#define PROT_WRITE 0x2 /* page can be written */
#define PROT_EXEC 0x4 /* page can be executed */
#define PROT_SEM 0x8 /* page may be used for atomic ops */
/* 0x10 reserved for arch-specific use */
/* 0x20 reserved for arch-specific use */
#define PROT_NONE 0x0 /* page can not be accessed */
#define PROT_GROWSDOWN 0x01000000 /* mprotect flag: extend change to start of growsdown vma */
#define PROT_GROWSUP 0x02000000 /* mprotect flag: extend change to end of growsup vma */flags:设置内存映射的属性,共享映射还是私有映射;
#define MAP_SHARED 0x01 /* Share changes */
#define MAP_PRIVATE 0x02 /* Changes are private */fd:文件描述符,表示是一个文件映射,fd=-1时表示匿名映射
offset:文件映射时,表示文件的偏移量;
根据上面标记描述的文件关联性和映射区域是否共享,mmap映射可以分成下面4类:
1)私有匿名映射 (MAP_ANONYMOUS | MAP_PRIVATE)fd=-1
glibc分配大内存块,大于MMAP_THREASHOLD/128KB,glibc使用mmap代替brk分配内存。
2)共享匿名映射(MAP_ANONYMOUS | MAP_SHARED)
相关进程共享一块内存区域,父子进程间通信;mmap_region代码中调用shmem_zero_setup。(打开/dev/zero文件,通过/dev/zero文件描述符创建)
3)私有文件映射(MAP_PRIVATE)
动态共享库加载
4)共享文件映射(MAP_SHARED)
读写文件(文件映射到地址空间);进程间通信;

图3-2-1
3.2.2 函数实现
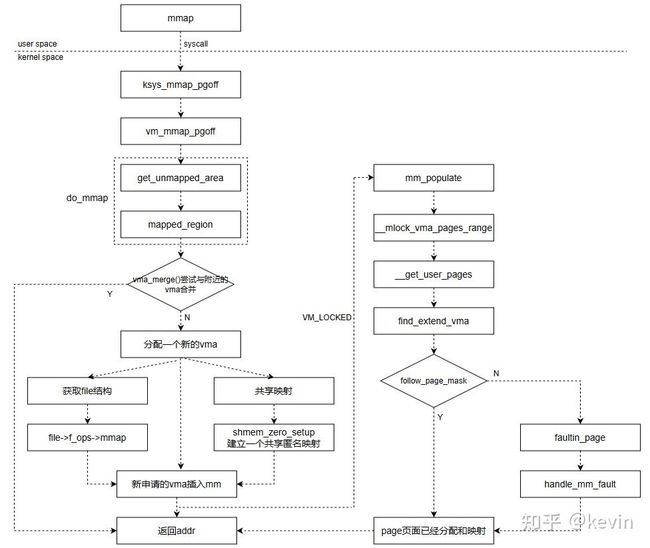
图3-2-2
unsigned long vm_mmap_pgoff(struct file *file, unsigned long addr,
unsigned long len, unsigned long prot,
unsigned long flag, unsigned long pgoff)
{
unsigned long ret;
struct mm_struct *mm = current->mm;
unsigned long populate;
LIST_HEAD(uf);
ret = security_mmap_file(file, prot, flag);
if (!ret) {
if (mmap_write_lock_killable(mm)) //1 拿mm_struct上的mmap_lock
return -EINTR;
ret = do_mmap(file, addr, len, prot, flag, pgoff, &populate,
&uf); //2 调用do_mmap
mmap_write_unlock(mm); //3 释放mm_struct的mmap_lock
userfaultfd_unmap_complete(mm, &uf);
if (populate)
mm_populate(ret, populate);
}
return ret;
}1)拿mm_struct的mmap_lock;
2)调用do_mmap,实现主要操作;
3)释放mm_struct的mmap_lock;
/*
* The caller must write-lock current->mm->mmap_lock.
*/
unsigned long do_mmap(struct file *file, unsigned long addr,
unsigned long len, unsigned long prot,
unsigned long flags, unsigned long pgoff,
unsigned long *populate, struct list_head *uf)
{
struct mm_struct *mm = current->mm;
vm_flags_t vm_flags;
int pkey = 0;
*populate = 0;
if (!len)
return -EINVAL;
/*
* Does the application expect PROT_READ to imply PROT_EXEC?
*
* (the exception is when the underlying filesystem is noexec
* mounted, in which case we dont add PROT_EXEC.)
*/
if ((prot & PROT_READ) && (current->personality & READ_IMPLIES_EXEC))
if (!(file && path_noexec(&file->f_path)))
prot |= PROT_EXEC;
/* force arch specific MAP_FIXED handling in get_unmapped_area */
if (flags & MAP_FIXED_NOREPLACE)
flags |= MAP_FIXED;
if (!(flags & MAP_FIXED))
addr = round_hint_to_min(addr);
/* Careful about overflows.. */
len = PAGE_ALIGN(len);
if (!len)
return -ENOMEM;
/* offset overflow? */
if ((pgoff + (len >> PAGE_SHIFT)) < pgoff)
return -EOVERFLOW;
/* Too many mappings? */
if (mm->map_count > sysctl_max_map_count)
return -ENOMEM;
/* Obtain the address to map to. we verify (or select) it and ensure
* that it represents a valid section of the address space.
*/
addr = get_unmapped_area(file, addr, len, pgoff, flags); //1
if (IS_ERR_VALUE(addr))
return addr;
if (flags & MAP_FIXED_NOREPLACE) {
if (find_vma_intersection(mm, addr, addr + len))
return -EEXIST;
}
if (prot == PROT_EXEC) {
pkey = execute_only_pkey(mm);
if (pkey < 0)
pkey = 0;
}
/* Do simple checking here so the lower-level routines won't have
* to. we assume access permissions have been handled by the open
* of the memory object, so we don't do any here.
*/
vm_flags = calc_vm_prot_bits(prot, pkey) | calc_vm_flag_bits(flags) |
mm->def_flags | VM_MAYREAD | VM_MAYWRITE | VM_MAYEXEC;
if (flags & MAP_LOCKED)
if (!can_do_mlock())
return -EPERM;
if (mlock_future_check(mm, vm_flags, len))
return -EAGAIN;
if (file) {
struct inode *inode = file_inode(file);
unsigned long flags_mask;
if (!file_mmap_ok(file, inode, pgoff, len))
return -EOVERFLOW;
flags_mask = LEGACY_MAP_MASK | file->f_op->mmap_supported_flags;
switch (flags & MAP_TYPE) {
case MAP_SHARED:
/*
* Force use of MAP_SHARED_VALIDATE with non-legacy
* flags. E.g. MAP_SYNC is dangerous to use with
* MAP_SHARED as you don't know which consistency model
* you will get. We silently ignore unsupported flags
* with MAP_SHARED to preserve backward compatibility.
*/
flags &= LEGACY_MAP_MASK;
fallthrough;
case MAP_SHARED_VALIDATE:
if (flags & ~flags_mask)
return -EOPNOTSUPP;
if (prot & PROT_WRITE) {
if (!(file->f_mode & FMODE_WRITE))
return -EACCES;
if (IS_SWAPFILE(file->f_mapping->host))
return -ETXTBSY;
}
/*
* Make sure we don't allow writing to an append-only
* file..
*/
if (IS_APPEND(inode) && (file->f_mode & FMODE_WRITE))
return -EACCES;
vm_flags |= VM_SHARED | VM_MAYSHARE;
if (!(file->f_mode & FMODE_WRITE))
vm_flags &= ~(VM_MAYWRITE | VM_SHARED);
fallthrough;
case MAP_PRIVATE:
if (!(file->f_mode & FMODE_READ))
return -EACCES;
if (path_noexec(&file->f_path)) {
if (vm_flags & VM_EXEC)
return -EPERM;
vm_flags &= ~VM_MAYEXEC;
}
if (!file->f_op->mmap)
return -ENODEV;
if (vm_flags & (VM_GROWSDOWN|VM_GROWSUP))
return -EINVAL;
break;
default:
return -EINVAL;
}
} else {
switch (flags & MAP_TYPE) {
case MAP_SHARED:
if (vm_flags & (VM_GROWSDOWN|VM_GROWSUP))
return -EINVAL;
/*
* Ignore pgoff.
*/
pgoff = 0;
vm_flags |= VM_SHARED | VM_MAYSHARE;
break;
case MAP_PRIVATE:
/*
* Set pgoff according to addr for anon_vma.
*/
pgoff = addr >> PAGE_SHIFT;
break;
default:
return -EINVAL;
}
}
/*
* Set 'VM_NORESERVE' if we should not account for the
* memory use of this mapping.
*/
if (flags & MAP_NORESERVE) {
/* We honor MAP_NORESERVE if allowed to overcommit */
if (sysctl_overcommit_memory != OVERCOMMIT_NEVER)
vm_flags |= VM_NORESERVE;
/* hugetlb applies strict overcommit unless MAP_NORESERVE */
if (file && is_file_hugepages(file))
vm_flags |= VM_NORESERVE;
}
addr = mmap_region(file, addr, len, vm_flags, pgoff, uf); //2
if (!IS_ERR_VALUE(addr) &&
((vm_flags & VM_LOCKED) ||
(flags & (MAP_POPULATE | MAP_NONBLOCK)) == MAP_POPULATE))
*populate = len;
return addr;
}1)get_unmapped_area 函数获取一个未使用的虚拟地址区域,返回首地址;
2)mmap_region 函数继续进行映射操作;
mmap_region
unsigned long mmap_region(struct file *file, unsigned long addr,
unsigned long len, vm_flags_t vm_flags, unsigned long pgoff,
struct list_head *uf)
{
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma, *prev, *merge;
int error;
struct rb_node **rb_link, *rb_parent;
unsigned long charged = 0;
/* Check against address space limit. */
if (!may_expand_vm(mm, vm_flags, len >> PAGE_SHIFT)) { //1 函数检查当前进程的虚拟地址空间换能不能扩展当前需要映射的大小
unsigned long nr_pages;
/*
* MAP_FIXED may remove pages of mappings that intersects with
* requested mapping. Account for the pages it would unmap.
*/
nr_pages = count_vma_pages_range(mm, addr, addr + len);
if (!may_expand_vm(mm, vm_flags,
(len >> PAGE_SHIFT) - nr_pages))
return -ENOMEM;
}
/* Clear old maps, set up prev, rb_link, rb_parent, and uf */
if (munmap_vma_range(mm, addr, len, &prev, &rb_link, &rb_parent, uf))
return -ENOMEM;
/*
* Private writable mapping: check memory availability
*/
if (accountable_mapping(file, vm_flags)) {
charged = len >> PAGE_SHIFT;
if (security_vm_enough_memory_mm(mm, charged))
return -ENOMEM;
vm_flags |= VM_ACCOUNT;
}
/*
* Can we just expand an old mapping?
*/
vma = vma_merge(mm, prev, addr, addr + len, vm_flags,
NULL, file, pgoff, NULL, NULL_VM_UFFD_CTX); //2 函数检查当前分配的虚拟地址和大小能不能合并到已有的vma中
if (vma)
goto out;
/*
* Determine the object being mapped and call the appropriate
* specific mapper. the address has already been validated, but
* not unmapped, but the maps are removed from the list.
*/
vma = vm_area_alloc(mm); //3 函数分配一个新的vma实例,用来保存需要映射的虚拟地址
if (!vma) {
error = -ENOMEM;
goto unacct_error;
}
vma->vm_start = addr; //4 初始化vma各成员
vma->vm_end = addr + len;
vma->vm_flags = vm_flags;
vma->vm_page_prot = vm_get_page_prot(vm_flags);
vma->vm_pgoff = pgoff;
if (file) {
if (vm_flags & VM_SHARED) {
error = mapping_map_writable(file->f_mapping); //5 如果是文件共享映射,判断文件映射是否可写
if (error)
goto free_vma;
}
vma->vm_file = get_file(file);
error = call_mmap(file, vma); //6
if (error)
goto unmap_and_free_vma;
/* Can addr have changed??
*
* Answer: Yes, several device drivers can do it in their
* f_op->mmap method. -DaveM
* Bug: If addr is changed, prev, rb_link, rb_parent should
* be updated for vma_link()
*/
WARN_ON_ONCE(addr != vma->vm_start); //7
addr = vma->vm_start;
/* If vm_flags changed after call_mmap(), we should try merge vma again
* as we may succeed this time.
*/
if (unlikely(vm_flags != vma->vm_flags && prev)) {
merge = vma_merge(mm, prev, vma->vm_start, vma->vm_end, vma->vm_flags,
NULL, vma->vm_file, vma->vm_pgoff, NULL, NULL_VM_UFFD_CTX); //8
if (merge) {
/* ->mmap() can change vma->vm_file and fput the original file. So
* fput the vma->vm_file here or we would add an extra fput for file
* and cause general protection fault ultimately.
*/
fput(vma->vm_file);
vm_area_free(vma);
vma = merge;
/* Update vm_flags to pick up the change. */
vm_flags = vma->vm_flags;
goto unmap_writable;
}
}
vm_flags = vma->vm_flags;
} else if (vm_flags & VM_SHARED) {
error = shmem_zero_setup(vma); //9
if (error)
goto free_vma;
} else {
vma_set_anonymous(vma); //10
}
/* Allow architectures to sanity-check the vm_flags */
if (!arch_validate_flags(vma->vm_flags)) {
error = -EINVAL;
if (file)
goto unmap_and_free_vma;
else
goto free_vma;
}
vma_link(mm, vma, prev, rb_link, rb_parent);
/* Once vma denies write, undo our temporary denial count */
unmap_writable:
if (file && vm_flags & VM_SHARED)
mapping_unmap_writable(file->f_mapping);
file = vma->vm_file;
out:
perf_event_mmap(vma);
vm_stat_account(mm, vm_flags, len >> PAGE_SHIFT);
if (vm_flags & VM_LOCKED) {
if ((vm_flags & VM_SPECIAL) || vma_is_dax(vma) ||
is_vm_hugetlb_page(vma) ||
vma == get_gate_vma(current->mm))
vma->vm_flags &= VM_LOCKED_CLEAR_MASK;
else
mm->locked_vm += (len >> PAGE_SHIFT);
}
if (file)
uprobe_mmap(vma);
/*
* New (or expanded) vma always get soft dirty status.
* Otherwise user-space soft-dirty page tracker won't
* be able to distinguish situation when vma area unmapped,
* then new mapped in-place (which must be aimed as
* a completely new data area).
*/
vma->vm_flags |= VM_SOFTDIRTY;
vma_set_page_prot(vma);
return addr;
unmap_and_free_vma:
fput(vma->vm_file);
vma->vm_file = NULL;
/* Undo any partial mapping done by a device driver. */
unmap_region(mm, vma, prev, vma->vm_start, vma->vm_end);
charged = 0;
if (vm_flags & VM_SHARED)
mapping_unmap_writable(file->f_mapping);
free_vma:
vm_area_free(vma);
unacct_error:
if (charged)
vm_unacct_memory(charged);
return error;
}1)may_expand_vm 函数检查当前进程的虚拟地址空间换能不能扩展当前需要映射的大小;
2)vma_merge 函数检查当前分配的虚拟地址和大小能不能合并到已有的vma中;
3)vm_area_alloc 函数分配一个新的vma实例,用来保存需要映射的虚拟地址;
4)初始化vma各成员;
5)如果是文件共享映射,判断文件映射是否可写;
6)如果是文件映射,调用文件的mmap方法,对于文件来说f_op->mmap是generic_file_mmap函数,genneric_file_mmap函数将vma的vm_ops设置为generic_file_vm_ops,filemap_fault函数被设置为vma读取缺页处理函数;
static inline int call_mmap(struct file *file, struct vm_area_struct *vma)
{
return file->f_op->mmap(file, vma);
}const struct vm_operations_struct generic_file_vm_ops = {
.fault = filemap_fault,
.map_pages = filemap_map_pages,
.page_mkwrite = filemap_page_mkwrite,
};
/* This is used for a general mmap of a disk file */
int generic_file_mmap(struct file *file, struct vm_area_struct *vma)
{
struct address_space *mapping = file->f_mapping;
if (!mapping->a_ops->readpage)
return -ENOEXEC;
file_accessed(file);
vma->vm_ops = &generic_file_vm_ops;
return 0;
}7)这里注释写的很清楚,调用完文件的mmap后,vma的start可能会发生变化;
8)再重新检查一次vma能不能和相邻的合并;
9)如果是共享匿名映射,调用 shmem_zero_setup 函数建立共享匿名映射,通过/dev/zero文件和vma建立映射(vma->ops=generic_file_vm_ops);
10)如果是私有匿名映射,调用 vma_set_anonymous 函数,私有匿名映射的vma->ops是NULL;
static inline void vma_set_anonymous(struct vm_area_struct *vma)
{
vma->vm_ops = NULL;
}3.3 删除映射
3.3.1 函数原型
int munmap(void *addr, size_t length);3.3.2 函数实现
SYSCALL_DEFINE2(munmap, unsigned long, addr, size_t, len)
{
addr = untagged_addr(addr);
profile_munmap(addr);
return __vm_munmap(addr, len, true);
}
static int __vm_munmap(unsigned long start, size_t len, bool downgrade)
{
int ret;
struct mm_struct *mm = current->mm;
LIST_HEAD(uf);
if (mmap_write_lock_killable(mm))
return -EINTR;
ret = __do_munmap(mm, start, len, &uf, downgrade);
/*
* Returning 1 indicates mmap_lock is downgraded.
* But 1 is not legal return value of vm_munmap() and munmap(), reset
* it to 0 before return.
*/
if (ret == 1) {
mmap_read_unlock(mm);
ret = 0;
} else
mmap_write_unlock(mm);
userfaultfd_unmap_complete(mm, &uf);
return ret;
}
/* Munmap is split into 2 main parts -- this part which finds
* what needs doing, and the areas themselves, which do the
* work. This now handles partial unmappings.
* Jeremy Fitzhardinge
*/
int __do_munmap(struct mm_struct *mm, unsigned long start, size_t len,
struct list_head *uf, bool downgrade)
{
unsigned long end;
struct vm_area_struct *vma, *prev, *last;
if ((offset_in_page(start)) || start > TASK_SIZE || len > TASK_SIZE-start)
return -EINVAL;
len = PAGE_ALIGN(len);
end = start + len;
if (len == 0)
return -EINVAL;
/*
* arch_unmap() might do unmaps itself. It must be called
* and finish any rbtree manipulation before this code
* runs and also starts to manipulate the rbtree.
*/
arch_unmap(mm, start, end);
/* Find the first overlapping VMA */
vma = find_vma(mm, start);
if (!vma)
return 0;
prev = vma->vm_prev;
/* we have start < vma->vm_end */
/* if it doesn't overlap, we have nothing.. */
if (vma->vm_start >= end)
return 0;
/*
* If we need to split any vma, do it now to save pain later.
*
* Note: mremap's move_vma VM_ACCOUNT handling assumes a partially
* unmapped vm_area_struct will remain in use: so lower split_vma
* places tmp vma above, and higher split_vma places tmp vma below.
*/
if (start > vma->vm_start) {
int error;
/*
* Make sure that map_count on return from munmap() will
* not exceed its limit; but let map_count go just above
* its limit temporarily, to help free resources as expected.
*/
if (end < vma->vm_end && mm->map_count >= sysctl_max_map_count)
return -ENOMEM;
error = __split_vma(mm, vma, start, 0);
if (error)
return error;
prev = vma;
}
/* Does it split the last one? */
last = find_vma(mm, end);
if (last && end > last->vm_start) {
int error = __split_vma(mm, last, end, 1);
if (error)
return error;
}
vma = vma_next(mm, prev);
if (unlikely(uf)) {
/*
* If userfaultfd_unmap_prep returns an error the vmas
* will remain split, but userland will get a
* highly unexpected error anyway. This is no
* different than the case where the first of the two
* __split_vma fails, but we don't undo the first
* split, despite we could. This is unlikely enough
* failure that it's not worth optimizing it for.
*/
int error = userfaultfd_unmap_prep(vma, start, end, uf);
if (error)
return error;
}
/*
* unlock any mlock()ed ranges before detaching vmas
*/
if (mm->locked_vm) {
struct vm_area_struct *tmp = vma;
while (tmp && tmp->vm_start < end) {
if (tmp->vm_flags & VM_LOCKED) {
mm->locked_vm -= vma_pages(tmp);
munlock_vma_pages_all(tmp);
}
tmp = tmp->vm_next;
}
}
/* Detach vmas from rbtree */
if (!detach_vmas_to_be_unmapped(mm, vma, prev, end))
downgrade = false;
if (downgrade)
mmap_write_downgrade(mm);
unmap_region(mm, vma, prev, start, end);
/* Fix up all other VM information */
remove_vma_list(mm, vma);
return downgrade ? 1 : 0;
}
3.4 非线性映射
文件的不同部分以不同的顺序映射到虚拟内存的连续区域中,sys_remap_file_pages。
4 页异常处理
虚拟内存必须映射到物理内存才能使用。如果访问没有映射到物理内存的虚拟内存地址,CPU 将会触发缺页异常。也就是说,虚拟内存并不能直接映射到磁盘中的文件。
由于 mmap() 系统调用并没有直接将文件的页缓存映射到虚拟内存中,所以当访问到没有映射的虚拟内存地址时,将会触发缺页异常。当 CPU 触发缺页异常时,将会调用 do_page_fault() 函数来修复触发异常的虚拟内存地址。
mmap() 系统调用的处理过程,如果是文件映射, mmap() 只是将 vma 的 vm_file 字段设置为被映射的文件对象,并且将 vma 的 fault() 回调函数设置为 filemap_fault()。也就是说,mmap() 系统调用并没有对虚拟内存进行任何的映射操作。

图4-1

图4-2
/*
* By the time we get here, we already hold the mm semaphore
*
* The mmap_lock may have been released depending on flags and our
* return value. See filemap_fault() and __lock_page_or_retry().
*/
static vm_fault_t __handle_mm_fault(struct vm_area_struct *vma,
unsigned long address, unsigned int flags)
{
struct vm_fault vmf = {
.vma = vma,
.address = address & PAGE_MASK,
.flags = flags,
.pgoff = linear_page_index(vma, address),
.gfp_mask = __get_fault_gfp_mask(vma),
};
unsigned int dirty = flags & FAULT_FLAG_WRITE;
struct mm_struct *mm = vma->vm_mm;
pgd_t *pgd;
p4d_t *p4d;
vm_fault_t ret;
pgd = pgd_offset(mm, address); //1 在页全局目录中查找虚拟地址address的页表项
p4d = p4d_alloc(mm, pgd, address); //2 在四级目录中查找虚拟地址address的表项,如果没有就创建四级目录
if (!p4d)
return VM_FAULT_OOM;
vmf.pud = pud_alloc(mm, p4d, address); //3 在上层目录中查找虚拟地址address的表项,如果没有就创建上层目录
if (!vmf.pud)
return VM_FAULT_OOM;
retry_pud:
if (pud_none(*vmf.pud) && __transparent_hugepage_enabled(vma)) {
ret = create_huge_pud(&vmf);
if (!(ret & VM_FAULT_FALLBACK))
return ret;
} else {
pud_t orig_pud = *vmf.pud;
barrier();
if (pud_trans_huge(orig_pud) || pud_devmap(orig_pud)) {
/* NUMA case for anonymous PUDs would go here */
if (dirty && !pud_write(orig_pud)) {
ret = wp_huge_pud(&vmf, orig_pud);
if (!(ret & VM_FAULT_FALLBACK))
return ret;
} else {
huge_pud_set_accessed(&vmf, orig_pud);
return 0;
}
}
}
vmf.pmd = pmd_alloc(mm, vmf.pud, address); //4 在中间目录中查找虚拟地址address的表项,如果没有就创建中间目录
if (!vmf.pmd)
return VM_FAULT_OOM;
/* Huge pud page fault raced with pmd_alloc? */
if (pud_trans_unstable(vmf.pud))
goto retry_pud;
if (pmd_none(*vmf.pmd) && __transparent_hugepage_enabled(vma)) {
ret = create_huge_pmd(&vmf);
if (!(ret & VM_FAULT_FALLBACK))
return ret;
} else {
vmf.orig_pmd = *vmf.pmd;
barrier();
if (unlikely(is_swap_pmd(vmf.orig_pmd))) {
VM_BUG_ON(thp_migration_supported() &&
!is_pmd_migration_entry(vmf.orig_pmd));
if (is_pmd_migration_entry(vmf.orig_pmd))
pmd_migration_entry_wait(mm, vmf.pmd);
return 0;
}
if (pmd_trans_huge(vmf.orig_pmd) || pmd_devmap(vmf.orig_pmd)) {
if (pmd_protnone(vmf.orig_pmd) && vma_is_accessible(vma))
return do_huge_pmd_numa_page(&vmf);
if (dirty && !pmd_write(vmf.orig_pmd)) {
ret = wp_huge_pmd(&vmf);
if (!(ret & VM_FAULT_FALLBACK))
return ret;
} else {
huge_pmd_set_accessed(&vmf);
return 0;
}
}
}
return handle_pte_fault(&vmf); //5 这里处理页表项
}1)在页全局目录中查找虚拟地址address的页表项;
2)在四级目录中查找虚拟地址address的表项,如果没有就创建四级目录;
3)在上层目录中查找虚拟地址address的表项,如果没有就创建上层目录;
4)在中间目录中查找虚拟地址address的表项,如果没有就创建中间目录;
5) 这里处理页表项;
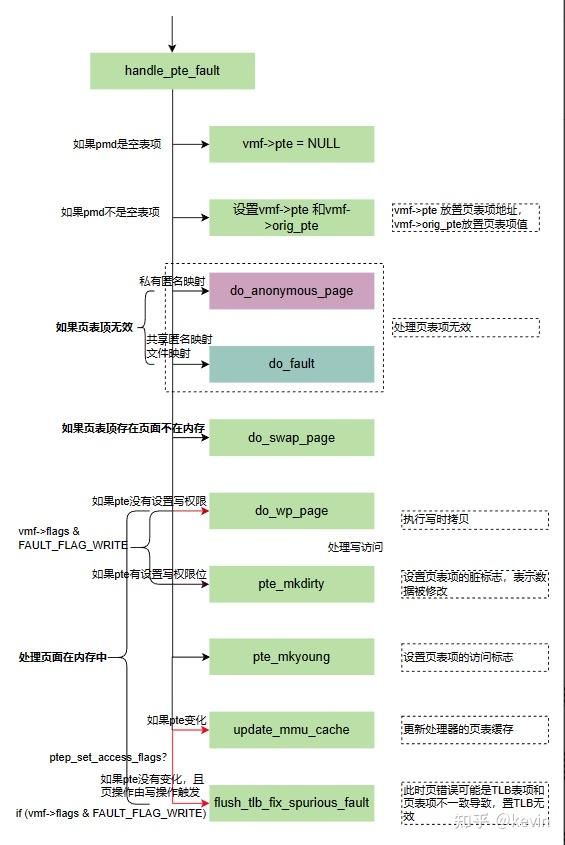
图4-3
/*
* These routines also need to handle stuff like marking pages dirty
* and/or accessed for architectures that don't do it in hardware (most
* RISC architectures). The early dirtying is also good on the i386.
*
* There is also a hook called "update_mmu_cache()" that architectures
* with external mmu caches can use to update those (ie the Sparc or
* PowerPC hashed page tables that act as extended TLBs).
*
* We enter with non-exclusive mmap_lock (to exclude vma changes, but allow
* concurrent faults).
*
* The mmap_lock may have been released depending on flags and our return value.
* See filemap_fault() and __lock_page_or_retry().
*/
static vm_fault_t handle_pte_fault(struct vm_fault *vmf)
{
pte_t entry;
if (unlikely(pmd_none(*vmf->pmd))) { //1 如果页中间目录表项是空表项,说明pte不存在,把pte设置为NULL
/*
* Leave __pte_alloc() until later: because vm_ops->fault may
* want to allocate huge page, and if we expose page table
* for an instant, it will be difficult to retract from
* concurrent faults and from rmap lookups.
*/
vmf->pte = NULL;
} else { //2 页中间目录不是空表项,说明pte存在,直接查找pte,vmf->pte置为页表项的地址, vmf->orig_pte置为页表项的值。
// 这里如果判断到页表项vmf->orig_pte为空,也就是也中间目录存在但是页表项为空的情形,vmf->pte要置NULL
/*
* If a huge pmd materialized under us just retry later. Use
* pmd_trans_unstable() via pmd_devmap_trans_unstable() instead
* of pmd_trans_huge() to ensure the pmd didn't become
* pmd_trans_huge under us and then back to pmd_none, as a
* result of MADV_DONTNEED running immediately after a huge pmd
* fault in a different thread of this mm, in turn leading to a
* misleading pmd_trans_huge() retval. All we have to ensure is
* that it is a regular pmd that we can walk with
* pte_offset_map() and we can do that through an atomic read
* in C, which is what pmd_trans_unstable() provides.
*/
if (pmd_devmap_trans_unstable(vmf->pmd))
return 0;
/*
* A regular pmd is established and it can't morph into a huge
* pmd from under us anymore at this point because we hold the
* mmap_lock read mode and khugepaged takes it in write mode.
* So now it's safe to run pte_offset_map().
*/
vmf->pte = pte_offset_map(vmf->pmd, vmf->address);
vmf->orig_pte = *vmf->pte;
/*
* some architectures can have larger ptes than wordsize,
* e.g.ppc44x-defconfig has CONFIG_PTE_64BIT=y and
* CONFIG_32BIT=y, so READ_ONCE cannot guarantee atomic
* accesses. The code below just needs a consistent view
* for the ifs and we later double check anyway with the
* ptl lock held. So here a barrier will do.
*/
barrier();
if (pte_none(vmf->orig_pte)) {
pte_unmap(vmf->pte);
vmf->pte = NULL;
}
}
if (!vmf->pte) {
if (vma_is_anonymous(vmf->vma)) //3 如果页表项不存在,是私有匿名映射的,调用do_anonymous_page处理
return do_anonymous_page(vmf);
else
return do_fault(vmf); //4 如果页表项不存在,是共享匿名映射或者文件映射的,调用 do_fault处理
}
if (!pte_present(vmf->orig_pte)) //5 如果页表项存在,页不在物理内存中,说明页被换出到swap了,调用do_swap_page
return do_swap_page(vmf);
if (pte_protnone(vmf->orig_pte) && vma_is_accessible(vmf->vma)) //6 TODO
return do_numa_page(vmf);
vmf->ptl = pte_lockptr(vmf->vma->vm_mm, vmf->pmd); //7 获取页表锁的地址
spin_lock(vmf->ptl); //8 页表锁上锁
entry = vmf->orig_pte;
if (unlikely(!pte_same(*vmf->pte, entry))) { //9 读页表项(*vmf->pte)的值和前面拿到的页表项的值比较,如果两次的值不一样,说明其他核在修改同一个页表项,当前核等待其他核处理就可以了,没有必要当前的处理了;
update_mmu_tlb(vmf->vma, vmf->address, vmf->pte);
goto unlock;
}
if (vmf->flags & FAULT_FLAG_WRITE) { //10 如果页错误由写操作触发(通过判断vma的标志)
if (!pte_write(entry)) //11 如果页错误由写操作触发(通过判断vma的标志),且页表项没有写权限,调用do_wp_page
return do_wp_page(vmf);
entry = pte_mkdirty(entry); //12 如果页错误由写操作触发(通过判断vma的标志),且页表项有写权限,设置脏标志,标识页数据被修改过
}
entry = pte_mkyoung(entry); //13 页表项设置young标志,标识页数据刚被访问过
if (ptep_set_access_flags(vmf->vma, vmf->address, vmf->pte, entry,
vmf->flags & FAULT_FLAG_WRITE)) { //14 设置页表项,如果页表项和之前比发生变化,调用 update_mmu_cache更新页表缓存
update_mmu_cache(vmf->vma, vmf->address, vmf->pte);
} else { //15 如果页表项和之前比没有发生变化,
/* Skip spurious TLB flush for retried page fault */
if (vmf->flags & FAULT_FLAG_TRIED)
goto unlock;
/*
* This is needed only for protection faults but the arch code
* is not yet telling us if this is a protection fault or not.
* This still avoids useless tlb flushes for .text page faults
* with threads.
*/
if (vmf->flags & FAULT_FLAG_WRITE) //16 如果页表项和之前比没有发生变化,并且是写操作,那么页错误很可能是页表项和TLB不一致导致的,使TLB无效
flush_tlb_fix_spurious_fault(vmf->vma, vmf->address);
}
unlock:
pte_unmap_unlock(vmf->pte, vmf->ptl); //17 释放页表锁
return 0;
}1)如果页中间目录表项是空表项,说明pte不存在,把pte设置为NULL;
页中间目录不是空表项,说明pte存在,直接查找pte,vmf->pte置为页表项的地址, vmf->orig_pte置为页表项的值。这里如果判断到页表项vmf->orig_pte为空,也就是也中间目录存在但是页表项为空的情形,vmf->pte要置NULL;

图4-4
3)如果页表项不存在,是私有匿名映射的,调用do_anonymous_page处理;
4)如果页表项不存在,是共享匿名映射或者文件映射的,调用 do_fault处理;
前面将mmap的实现时,已经看到内核使用共享文件映射实现共享匿名映射
5)如果页表项存在,页不在物理内存中,说明页被换出到swap了,调用do_swap_page处理;
6)TODO
7)/获取页表锁的地址
8)页表锁上锁;
9)读页表项(*vmf->pte)的值和前面拿到的页表项的值比较,如果两次的值不一样,说明其他核在修改同一个页表项,当前核等待其他核处理就可以了,没有必要当前的处理了;
10)如果页错误由写操作触发(通过判断vma的标志)
11)如果页错误由写操作触发(通过判断vma的标志),且没有写权限,调用do_wp_page,这里其实是写时复制的处理。想想创建新进程的时候,子进程复制父进程的页表项并设置了写保护(只读);
12)如果页错误由写操作触发(通过判断vma的标志),且页表项有写权限,设置脏标志,标识页数据被修改过;
13)页表项设置young标志,标识页数据刚被访问过;
14)设置页表项,如果页表项和之前比发生变化,调用 update_mmu_cache更新页表缓存;
15)如果页表项和之前比没有发生变化;
16)如果页表项和之前比没有发生变化,并且是写操作,那么页错误很可能是页表项和TLB不一致导致的,使TLB无效;
17)释放页表锁;
4.1 匿名页的缺页异常
回想下哪些页是匿名页,进程调用mmap创建匿名映射后,mmap中只是分配了虚拟地址空间,进程第一次访问时会触发缺页异常处理;进程调用malloc申请内存时,只是申请了一段虚拟地址空间,进程第一次访问时会触发缺页异常处理。
4.1.1 私有匿名页

图4-1-1
1)匿名映射调用do_anonymous_page,这里判断是不是匿名映射的是通过判断vma->vm_ops是否为NULL。上面分析mmap实现,如果是匿名映射,vma->vm_ops置NULL;
static inline bool vma_is_anonymous(struct vm_area_struct *vma)
{
return !vma->vm_ops;
}代码注释
/*
* We enter with non-exclusive mmap_lock (to exclude vma changes,
* but allow concurrent faults), and pte mapped but not yet locked.
* We return with mmap_lock still held, but pte unmapped and unlocked.
*/
static vm_fault_t do_anonymous_page(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
struct page *page;
vm_fault_t ret = 0;
pte_t entry;
/* File mapping without ->vm_ops ? */
if (vma->vm_flags & VM_SHARED) //1 如果是共享匿名映射,但是vm_ops为NULL(调用do_anonymous_page时判断vm_ops为NULL),返回VM_FAULT_SIGBUS
return VM_FAULT_SIGBUS;
/*
* Use pte_alloc() instead of pte_alloc_map(). We can't run
* pte_offset_map() on pmds where a huge pmd might be created
* from a different thread.
*
* pte_alloc_map() is safe to use under mmap_write_lock(mm) or when
* parallel threads are excluded by other means.
*
* Here we only have mmap_read_lock(mm).
*/
if (pte_alloc(vma->vm_mm, vmf->pmd)) //2 如果页表项为空,分配页表项,pte_alloc里面有判断
return VM_FAULT_OOM;
/* See comment in handle_pte_fault() */
if (unlikely(pmd_trans_unstable(vmf->pmd)))
return 0;
/* Use the zero-page for reads */
if (!(vmf->flags & FAULT_FLAG_WRITE) &&
!mm_forbids_zeropage(vma->vm_mm)) { //3 如果缺页异常由读操作触发&进程允许使用零页,虚拟地址映射到零页
entry = pte_mkspecial(pfn_pte(my_zero_pfn(vmf->address),
vma->vm_page_prot)); //4 生成特殊的页表项
vmf->pte = pte_offset_map_lock(vma->vm_mm, vmf->pmd,
vmf->address, &vmf->ptl); //5 在页表中查虚拟地址对应的页表项地址,并锁住页表
if (!pte_none(*vmf->pte)) { //6 如果页表项不为空,说明其他核正在修改当前页表项,等待其他核处理,更新tlb
update_mmu_tlb(vma, vmf->address, vmf->pte);
goto unlock;
}
ret = check_stable_address_space(vma->vm_mm);
if (ret)
goto unlock;
/* Deliver the page fault to userland, check inside PT lock */
if (userfaultfd_missing(vma)) { //7 TODO
pte_unmap_unlock(vmf->pte, vmf->ptl);
return handle_userfault(vmf, VM_UFFD_MISSING);
}
goto setpte; //8 设置页表项
}
/* Allocate our own private page. */
if (unlikely(anon_vma_prepare(vma))) //9 关联anon_vma实例到vma的anon_vma,逆向映射的基础结构
goto oom;
page = alloc_zeroed_user_highpage_movable(vma, vmf->address); //10 分配物理页,用0初始化该页,优先从GIGHMEM分配,这个页用来放页表项
if (!page)
goto oom;
if (mem_cgroup_charge(page_folio(page), vma->vm_mm, GFP_KERNEL))
goto oom_free_page;
cgroup_throttle_swaprate(page, GFP_KERNEL);
/*
* The memory barrier inside __SetPageUptodate makes sure that
* preceding stores to the page contents become visible before
* the set_pte_at() write.
*/
__SetPageUptodate(page); //11 给页设置标志PG_uptodate,标识页的数据是有效的;
entry = mk_pte(page, vma->vm_page_prot); //12 根据vma的权限生成页表项
entry = pte_sw_mkyoung(entry); //13 设置页表项的young标志,标识最近被访问过
if (vma->vm_flags & VM_WRITE) //14 如果vma有写权限,设置页表项的脏标志和写标志
entry = pte_mkwrite(pte_mkdirty(entry));
vmf->pte = pte_offset_map_lock(vma->vm_mm, vmf->pmd, vmf->address,
&vmf->ptl); //15 根据虚拟地址查找页表项的地址,并且拿页表锁,注意vmf->pte是放页表项内存的地址,*vmf->pte是页表项
if (!pte_none(*vmf->pte)) { //16 如果页表项不是空表项,说明其他核正在修改页表项,当前核就没有必要处理了,更新tlb后返回,
update_mmu_cache(vma, vmf->address, vmf->pte);
goto release;
}
ret = check_stable_address_space(vma->vm_mm);
if (ret)
goto release;
/* Deliver the page fault to userland, check inside PT lock */
if (userfaultfd_missing(vma)) { //17 TODO
pte_unmap_unlock(vmf->pte, vmf->ptl);
put_page(page);
return handle_userfault(vmf, VM_UFFD_MISSING);
}
inc_mm_counter_fast(vma->vm_mm, MM_ANONPAGES); //18 进程地址空间中RSS中Resident anonymous pages加1
page_add_new_anon_rmap(page, vma, vmf->address, false); //19 建立逆向映射的基础结构
lru_cache_add_inactive_or_unevictable(page, vma); //20 把页添加到LRU链表
setpte:
set_pte_at(vma->vm_mm, vmf->address, vmf->pte, entry); //21 设置页表项
/* No need to invalidate - it was non-present before */
update_mmu_cache(vma, vmf->address, vmf->pte); //22 更新页表缓存
unlock:
pte_unmap_unlock(vmf->pte, vmf->ptl);
return ret;
release:
put_page(page);
goto unlock;
oom_free_page:
put_page(page);
oom:
return VM_FAULT_OOM;
}1)如果是共享匿名映射,但是vm_ops为NULL(调用do_anonymous_page时判断vm_ops为NULL),返回VM_FAULT_SIGBUS;
2)如果页表项为空,分配页表项,pte_alloc里面有判断;
3)如果缺页异常由读操作触发&进程允许使用零页,虚拟地址映射到零页;
4) 生成特殊的页表项;
5) 在页表中查虚拟地址对应的页表项地址,并锁住页表;
6) 如果页表项不为空,说明其他核正在修改当前页表项,让其他核处理,更新tlb;
7) TODO userfault相关
8)设置页表项
9)关联anon_vma实例到vma的anon_vma,私有匿名页逆向映射的基础结构;
10)分配物理页,用0初始化该页,优先从GIGHMEM分配;
11)给页设置标志PG_uptodate,标识页的数据是有效的;
12)根据vma的权限生成页表项;
13)设置页表项的young标志,标识最近被访问过;
14)如果vma有写权限,设置页表项的脏标志和写标志;
15)根据虚拟地址查找页表项的地址,并且拿页表锁,注意vmf->pte是放页表项内存的地址,*vmf->pte是页表项;
16)如果页表项不是空表项,说明其他核正在修改页表项,当前核就没有必要处理了,更新tlb后返回;
17) TODO userfault相关;
18)进程地址空间中RSS统计中Resident anonymous pages加1;
19)建立逆向映射的基础结构,后面单独讲逆向映射;
20)把页添加到LRU链表
21)设置页表项
22)更新页表缓存
4.1.2 共享匿名页
前面我们已经提到,共享匿名页的映射关联到文件/dev/zero,和共享文件页的异常流程一样;
4.2 文件页的缺页异常
使用mmap创建文件映射,把文件的一部分或者全部映射到进程的虚拟地址空间,第一次访问的时候就会触发文件页的缺页异常。还有就是进程启动的时候,内核使用elf_map将进程的可执行文件的代码段和数据段以私有文件映射的方式映射到进程的虚拟地址空间,第一次访问的时候就会触发文件页的缺页异常。
这里再提一下,共享匿名映射是关联到文件/dev/zero
前面已经提到了,do_fault函数处理共享匿名页和文件页的缺页异常处理,执行流程如下
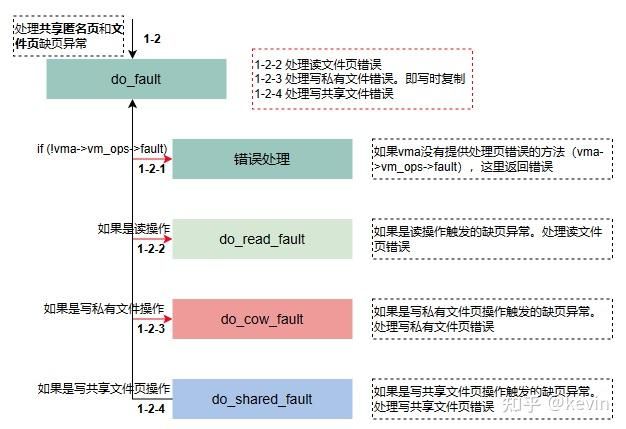
图4-2-1
1)处理读文件页错误(do_read_fault),包括读共享文件页和读私有文件页的页错误处理;
2)处理写私有文件页错误(do_cow_fault);
3)处理写共享文件页错误(do_share_fault);
代码注释
/*
* We enter with non-exclusive mmap_lock (to exclude vma changes,
* but allow concurrent faults).
* The mmap_lock may have been released depending on flags and our
* return value. See filemap_fault() and __lock_page_or_retry().
* If mmap_lock is released, vma may become invalid (for example
* by other thread calling munmap()).
*/
static vm_fault_t do_fault(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
struct mm_struct *vm_mm = vma->vm_mm;
vm_fault_t ret;
/*
* The VMA was not fully populated on mmap() or missing VM_DONTEXPAND
*/
if (!vma->vm_ops->fault) { //1 如果虚拟内存区域没有提供处理页异常的方法,即vma->vm_ops->fault为空。这里是处理文件映射和共享匿名映射,所以必定fault不为空;
/*
* If we find a migration pmd entry or a none pmd entry, which
* should never happen, return SIGBUS
*/
if (unlikely(!pmd_present(*vmf->pmd)))
ret = VM_FAULT_SIGBUS;
else {
vmf->pte = pte_offset_map_lock(vmf->vma->vm_mm,
vmf->pmd,
vmf->address,
&vmf->ptl);
/*
* Make sure this is not a temporary clearing of pte
* by holding ptl and checking again. A R/M/W update
* of pte involves: take ptl, clearing the pte so that
* we don't have concurrent modification by hardware
* followed by an update.
*/
if (unlikely(pte_none(*vmf->pte)))
ret = VM_FAULT_SIGBUS;
else
ret = VM_FAULT_NOPAGE;
pte_unmap_unlock(vmf->pte, vmf->ptl);
}
} else if (!(vmf->flags & FAULT_FLAG_WRITE)) //2 如果是读文件页操作,调用do_read_fault处理读文件页错误;
ret = do_read_fault(vmf);
else if (!(vma->vm_flags & VM_SHARED)) //3 如果是写私有文件操作,调用函数do_cow_fault处理写私有文件页错误,即写时拷贝;
ret = do_cow_fault(vmf);
else
ret = do_shared_fault(vmf); //4 如果是写共享文件页操作,调用函数do_share_fault处理写共享文件页错误;
/* preallocated pagetable is unused: free it */
if (vmf->prealloc_pte) {
pte_free(vm_mm, vmf->prealloc_pte);
vmf->prealloc_pte = NULL;
}
return ret;
}1)如果虚拟内存区域没有提供处理页异常的方法,即vma->vm_ops->fault为空。这里是处理文件映射和共享匿名映射,所以必定fault不为空;
2)如果是读文件页操作,调用do_read_fault处理读文件页错误;
3)如果是写私有文件操作,调用函数do_cow_fault处理写私有文件页错误,即写时拷贝;
4)如果是写共享文件页操作,调用函数do_share_fault处理写共享文件页错误;
4.2.1 共享文件页
4.2.1.1 读共享文件页
do_read_fault函数处理文件页的读操作触发的异常,其中包括共享文件页和私有文件页的读操作;读共享文件页的异常处理主要做了两件事,一是把文件内容从磁盘读到文件的页缓存的物理页中,二是设置页表项,把进程的虚拟地址和页缓存的物理页关联起来;

图4-2-2
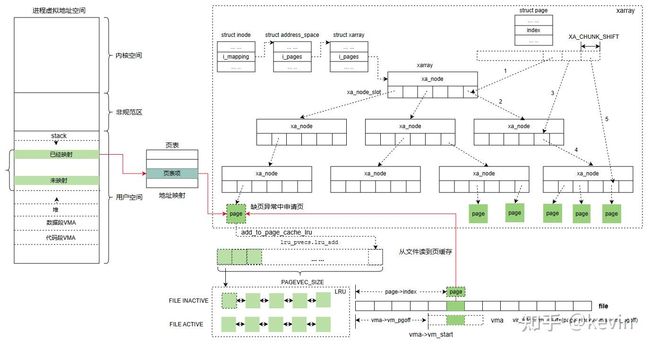
文件内容从磁盘读到文件的页缓存的物理页:
static vm_fault_t do_read_fault(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
vm_fault_t ret = 0;
/*
* Let's call ->map_pages() first and use ->fault() as fallback
* if page by the offset is not ready to be mapped (cold cache or
* something).
*/
if (vma->vm_ops->map_pages && fault_around_bytes >> PAGE_SHIFT > 1) {
if (likely(!userfaultfd_minor(vmf->vma))) {
ret = do_fault_around(vmf); //1 如果正在访问的文件后面几个文件页(fault_around_bytes标识长度)也被映射到进程的虚拟地址空间,预先读到页缓存中。这样做是为了减少页异常的次数,做预读;
if (ret)
return ret;
}
}
ret = __do_fault(vmf); //2 文件页读到文件的缓存中
if (unlikely(ret & (VM_FAULT_ERROR | VM_FAULT_NOPAGE | VM_FAULT_RETRY)))
return ret;
ret |= finish_fault(vmf); //3 设置页表项,把文件的页缓存的物理页和进程虚拟地址之间建立页表项
unlock_page(vmf->page);
if (unlikely(ret & (VM_FAULT_ERROR | VM_FAULT_NOPAGE | VM_FAULT_RETRY)))
put_page(vmf->page);
return ret;
}1)如果正在访问的文件后面几个文件页(fault_around_bytes标识长度)也被映射到进程的虚拟地址空间,预先读到页缓存中。这样做是为了减少页异常的次数,做预读;( do_fault_around函数注释写的很清楚);
2)文件页读到文件的缓存中,__do_fault函数调用vma的操作函数集合中的fault方法(vma->vm_ops->fault)把文件页读到内存中,前面我们已经提到mmap创建文件映射的时候,会把fault设置成被映射文件所属文件系统的虚拟内存操作函数集中的fault方法,例如,ext4文件系统是ext4_file_vm_ops.fault,即ext4_filemap_fault,很多文件系统注册的faultfault方法使用的是通用的filemap_fault;
3)设置页表项,把文件的页缓存的物理页和进程虚拟地址之间建立页表项;
/*
* The mmap_lock must have been held on entry, and may have been
* released depending on flags and vma->vm_ops->fault() return value.
* See filemap_fault() and __lock_page_retry().
*/
static vm_fault_t __do_fault(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
vm_fault_t ret;
/*
* Preallocate pte before we take page_lock because this might lead to
* deadlocks for memcg reclaim which waits for pages under writeback:
* lock_page(A)
* SetPageWriteback(A)
* unlock_page(A)
* lock_page(B)
* lock_page(B)
* pte_alloc_one
* shrink_page_list
* wait_on_page_writeback(A)
* SetPageWriteback(B)
* unlock_page(B)
* # flush A, B to clear the writeback
*/
if (pmd_none(*vmf->pmd) && !vmf->prealloc_pte) {
vmf->prealloc_pte = pte_alloc_one(vma->vm_mm);
if (!vmf->prealloc_pte)
return VM_FAULT_OOM;
}
ret = vma->vm_ops->fault(vmf); //1
if (unlikely(ret & (VM_FAULT_ERROR | VM_FAULT_NOPAGE | VM_FAULT_RETRY |
VM_FAULT_DONE_COW)))
return ret;
if (unlikely(PageHWPoison(vmf->page))) {
struct page *page = vmf->page;
vm_fault_t poisonret = VM_FAULT_HWPOISON;
if (ret & VM_FAULT_LOCKED) {
if (page_mapped(page))
unmap_mapping_pages(page_mapping(page),
page->index, 1, false);
/* Retry if a clean page was removed from the cache. */
if (invalidate_inode_page(page))
poisonret = VM_FAULT_NOPAGE;
unlock_page(page);
}
put_page(page);
vmf->page = NULL;
return poisonret;
}
if (unlikely(!(ret & VM_FAULT_LOCKED)))
lock_page(vmf->page);
else
VM_BUG_ON_PAGE(!PageLocked(vmf->page), vmf->page);
return ret;
}1)调用vma的 fault() 回调函数(也就是 filemap_fault() 函数)来获取到文件的页缓存。
4.2.1.2 写共享文件页
如图4-2-1,do_share_fault处理写文件页错误;共享文件页的写异常处理主要做了两件事,一是把文件内容从磁盘读到文件的页缓存的物理页中,二是设置页表项,把进程的虚拟地址和页缓存的物理页关联起来;

图4-2-3
static vm_fault_t do_shared_fault(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
vm_fault_t ret, tmp;
ret = __do_fault(vmf); //1 把文件页读到文件缓存中
if (unlikely(ret & (VM_FAULT_ERROR | VM_FAULT_NOPAGE | VM_FAULT_RETRY)))
return ret;
/*
* Check if the backing address space wants to know that the page is
* about to become writable
*/
if (vma->vm_ops->page_mkwrite) { //2 vma->vm_ops->page_mkwrite被设置为创建映射文件所属的文件系统的虚拟内存操作集合的page_mkwrite方法,
unlock_page(vmf->page);
tmp = do_page_mkwrite(vmf); //3 通知文件系统页将要变为可写的,文件系统做相应的处理,do_page_mkwrite中会调用vma->vm_ops->page_mkwrite
if (unlikely(!tmp ||
(tmp & (VM_FAULT_ERROR | VM_FAULT_NOPAGE)))) {
put_page(vmf->page);
return tmp;
}
}
ret |= finish_fault(vmf); //4 设置页表项
if (unlikely(ret & (VM_FAULT_ERROR | VM_FAULT_NOPAGE |
VM_FAULT_RETRY))) {
unlock_page(vmf->page);
put_page(vmf->page);
return ret;
}
ret |= fault_dirty_shared_page(vmf); //5 设置脏标志,标识页数据被更新过,文件系统会处理回写;
return ret;
}1) 把文件页内容读到文件缓存页中;
2)2 vma->vm_ops->page_mkwrite被设置为创建映射文件所属的文件系统的虚拟内存操作集合的page_mkwrite方法;
3) 通知文件系统页将要变为可写的,文件系统做相应的处理,do_page_mkwrite中会调用vma->vm_ops->page_mkwrite;
4)设置页表项,进程虚拟地址和页缓存的物理页之间;
5)设置脏标志,标识页数据被更新过,更新文件的修改时间;
4.2.2 私有文件页
对于私有文件映射,在写的时候生成页错误异常,页错误异常处理程序执行写时复制,新的物理页于文件脱离关系,属于匿名页。
4.2.2.1 读私有文件页
如4.2.1.1节,和共享文件页的读操作处理流程是一样的;
4.2.2.2 写私有文件页
如果4-2-1中描述,do_cow_fault函数处理写私有文件页错误;写共享文件页的异常处理主要做了三件事,一是把文件内容从磁盘读到文件的页缓存的物理页中;二是执行写时复制,为文件页缓存的物理页创建一个副本,这个副本是进程私有的,和文件没有关系了,进程写操作之后更新自己的副本,不会更新文件;三是设置页表项,把进程的虚拟地址和副本物理页关联起来;

图4-2-4
static vm_fault_t do_cow_fault(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
vm_fault_t ret;
if (unlikely(anon_vma_prepare(vma))) //1 关联anon_vma实例到vma
return VM_FAULT_OOM;
vmf->cow_page = alloc_page_vma(GFP_HIGHUSER_MOVABLE, vma, vmf->address); //2 分配一个物理页作为写的副本,因为是私有文件映射,每次写的时候都拷贝一份副本,数据拷贝到副本以后和文件就没啥关系了,类似匿名页
if (!vmf->cow_page)
return VM_FAULT_OOM;
if (mem_cgroup_charge(vmf->cow_page, vma->vm_mm, GFP_KERNEL)) {
put_page(vmf->cow_page);
return VM_FAULT_OOM;
}
cgroup_throttle_swaprate(vmf->cow_page, GFP_KERNEL);
ret = __do_fault(vmf); //3 把文件内容读到文件的页缓存中
if (unlikely(ret & (VM_FAULT_ERROR | VM_FAULT_NOPAGE | VM_FAULT_RETRY)))
goto uncharge_out;
if (ret & VM_FAULT_DONE_COW)
return ret;
copy_user_highpage(vmf->cow_page, vmf->page, vmf->address, vma); //4 把页缓存的物理页的数据拷贝到2中分配的副本页中
__SetPageUptodate(vmf->cow_page); //5 设置副本物理页的PG_uptodate标志位,标识副本页包含有效数据
ret |= finish_fault(vmf); //6 设置页表项,把虚拟地址和物理页关联起来
unlock_page(vmf->page);
put_page(vmf->page);
if (unlikely(ret & (VM_FAULT_ERROR | VM_FAULT_NOPAGE | VM_FAULT_RETRY)))
goto uncharge_out;
return ret;
uncharge_out:
put_page(vmf->cow_page);
return ret;
}1)关联anon_vma实例到vma;
2)分配一个物理页作为写的副本,因为是私有文件映射,每次写的时候都拷贝一份副本;
3)把文件内容读到文件的页缓存中;
4) 把页缓存的物理页的数据拷贝到2中分配的副本页中;
5)设置副本物理页的PG_uptodate标志位,标识副本页包含有效数据;
6)设置页表项,把虚拟地址和物理页关联起来
欢迎关注同名微信订阅号,获取最新文章

参考文献
[1] https://zhuanlan.zhihu.com/p/546009181
[2] Linux内存映射 - 知乎 (zhihu.com)