数组(1)
文章目录
- 目录
-
- 1. 一维数组的创建和初始化
-
- 1.1 一维数组的创建
- 1.2 一维数组的初始化
- 2. 一维数组的使用
- 3. 一维数组在内存中的存储
- 4. 二维数组的创建和初始化
-
- 4.1 二维数组的创建
- 4.2 二维数组的初始化
- 5. 二维数组的使用
- 6. 二维数组在内存中的存储
- 7. 数组越界
- 8. 数组作为函数参数
- 附:
目录
- 一维数组的创建和初始化
- 一维数组的使用
- 一维数组在内存中的存储
- 二维数组的创建和初始化
- 二维数组的使用
- 二维数组在内存中的存储
- 数组越界
- 数组作为函数参数
- 三子棋
- 扫雷游戏
1. 一维数组的创建和初始化
1.1 一维数组的创建
数组是一组相同类型元素的集合。
数组的创建方式:
type_t arr_name [const_n];
type_t 是指数组的元素类型
const_n 是一个常量表达式,用来指定数组的大小
数组创建的实例:
int main()
{
int arr1[10];
int count = 10;
int arr2[count];//常量表达式才可以
//VS2019 VS2022 这样的IDE 不支持C99 中的变长数组
//C99 标准之前 数组的大小只能是常量表达式
//C99 标准中引入了:变长数组的概念,使得数组在创建的时候可以使用变量,但是这样的数组不能初始化
return 0;
}
//gcc中就支持变长数组
#include 1.2 一维数组的初始化
数组的初始化是指在创建数组的同时给数组的内容一些合理初始值(初始化)。
int main()
{
//int arr1[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };//完全初始化
//int arr2[10] = { 1, 2, 3 };//不完全初始化,剩余的元素默认都是0
//int arr3[10] = { 0 };//不完全初始化,剩余的元素默认都是0
//int arr4[] = { 0 };//省略数组的大小,数组必须初始化,数组的大小是根据初始化的内容来确定
//int arr5[] = { 1, 2, 3 };
//int arr6[];//err
char arr1[] = "abc";
char arr2[] = { 'a', 'b', 'c' };
char arr3[] = { 'a', 98, 'c' };
return 0;
}
2. 一维数组的使用
对于数组的使用我们之前介绍了一个操作符: [] (下标引用操作符),它其实就是数组访问的操作符。
#include #include #include #include 总结:
- 数组是使用下标来访问的,下标是从0开始。
- 数组的大小可以通过计算得到。
#include 3. 一维数组在内存中的存储
//%p -- 是用来打印地址的
#include 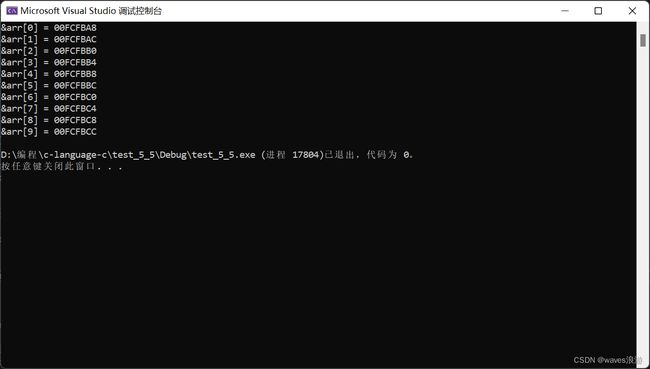
仔细观察输出的结果,我们知道,随着数组下标的增长,元素的地址也在有规律的递增。由此可以得出结论:一维数组在内存中是连续存放的。
4. 二维数组的创建和初始化
4.1 二维数组的创建
int main()
{
//数组的创建
int arr[4][5];
char ch[3][8];
return 0;
}
4.2 二维数组的初始化
int main()
{
//数组的初始化
int arr[4][5] = { {1,2,3,4,5},{2,3,4,5,6},{3,4,5,6,7},{5,6,7,8,9} };
int arr2[4][5] = { 1,2,3,4,5,2,3,4,5,6,3,4,5,6,7,5,6,7,8,9 };
//二维数组即使初始化了的
//行是可以省略的,但是列是不能省略的
int arr3[][5] = { {1,2,3}, {2,3,4}, {3,4,5,6,7}, {5,6,7,8,9} };
return 0;
}
5. 二维数组的使用
二维数组的使用也是通过下标的方式。
#include 6. 二维数组在内存中的存储
#include 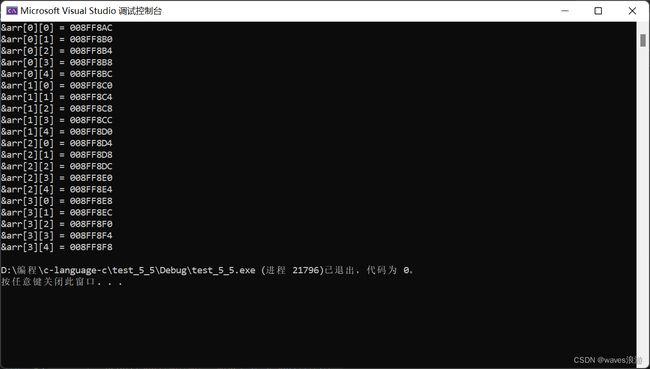
通过结果我们可以分析到,其实二维数组在内存中也是连续存储的。

注:
//假想是:1 2 3 4 5
// 2 3 4 5 6
// 3 4 5 6 7
// 5 6 7 8 9
//实际上:连续存放的
//1. 二维数组是【一维数组】的数组
// 元素
//
//2. 可以这样理解: 类比一维数组 int arr[10] arr[j];//0~9 --> arr[0][j]中arr[0]是数组名 j是下标
7. 数组越界
- 数组的下标是有范围限制的:数组的下标规定是从0开始的,如果数组有n个元素,最后一个元素的下标就是n-1;所以数组的下标如果小于0,或者大于n-1,就是数组越界访问了,超出了数组合法空间的访问。
- C语言本身是不做数组下标的越界检查,编译器也不一定报错,但是编译器不报错,并不意味着程序就是正确的,所以程序员写代码时,最好自己做越界的检查。
#include 注: 二维数组的行和列也可能存在越界。
8. 数组作为函数参数
往往我们在写代码的时候,会将数组作为参数传给函数,比如:要实现一个冒泡排序(这里要讲算法思想)函数,将一个整形数组排序。
首先,来看一下不用函数的写法:
//输入10个整数,对这组数进行排序
//排序有很多的方法
//1. 冒泡排序
//2. 选择排序
//3. 插入排序
//4. 快速排序
// ....
#include 接着,我们运用函数来实现:
#include 此外,我们还可以对它进行一些优化:
//冒泡排序的优化
#include 看完以上代码,肯定会有疑惑:为什么sizeof(arr)中的arr表示整个数组,而传参时arr表示数组首元素的地址呢?
//数组名该怎么理解?
//数组名通常情况下就是数组首元素的地址
//但是有2个例外:
//1. sizeof(数组名),数组名单独放在sizeof()内部,这里的数组名表示整个数组,计算的是整个数组的大小
//2. &数组名,这里的数组名也表示整个数组,这里取出的是整个数组的地址
//除此之外,所有遇到的数组名都表示数组首元素的地址
#include 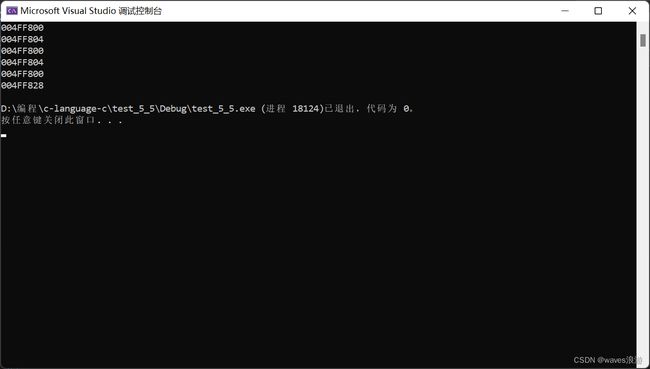
附:
数组(2)
数组(3)