原文地址:machine-learning-is-fun-part-1,原文共分三个部分,笔者在这里合并到一篇文章中,并且对内容进行了重新排版以方便阅读。
笔者的数据科学/机器学习知识图谱以及系列文章在Github的Repo,欢迎关注与点赞,笔者之前攒了很多零散的笔记,打算拾掇拾掇整理出来
笔者自大学以来一直断断续续的学过机器学习啊、自然语言处理啊等等方面的内容,相信基本上每个本科生或者研究生都会接触过这方面,毕竟是一个如此大的Flag。不过同样的,在机器学习,或者更大的一个概念,数据科学这个领域中,同样是学了忘忘了学。不可否认,数学是机器学习的一个基石,但是也是无数人,包括笔者学习机器学习的一个高的门槛,毕竟数学差。而在这篇文章中,原作者并没有讲很多的数学方面的东西,而是以一个有趣实用的方式来介绍机器学习。另一方面,其实很多数学原理也是很有意思的,笔者记得当年看完数学之美有一个不小的感触,就是知道了TF-IDF的计算公式是怎么来的~
What is Machine Learning: Machine Learning的概念与算法介绍
估计你已经厌烦了听身边人高谈阔论什么机器学习、深度学习但是自己摸不着头脑,这篇文章就由浅入深高屋建瓴地给你介绍一下机器学习的方方面面。本文的主旨即是让每个对机器学习的人都有所得,因此你也不能指望在这篇文章中学到太多高深的东西。言归正传,我们先来看看到底什么是机器学习:
Machine learning is the idea that there are generic algorithms that can tell you something interesting about a set of data without you having to write any custom code specific to the problem. Instead of writing code, you feed data to the generic algorithm and it builds its own logic based on the data.
笔者在这里放了原作者的英文描述,以帮助更好地理解。Machine Learning即是指能够帮你从数据中寻找到感兴趣的部分而不需要编写特定的问题解决方案的通用算法的集合。通用的算法可以根据你不同的输入数据来自动地构建面向数据集合最优的处理逻辑。举例而言,算法中一个大的分类即分类算法,它可以将数据分类到不同的组合中。而可以用来识别手写数字的算法自然也能用来识别垃圾邮件,只不过对于数据特征的提取方法不同。相同的算法输入不同的数据就能够用来处理不同的分类逻辑。
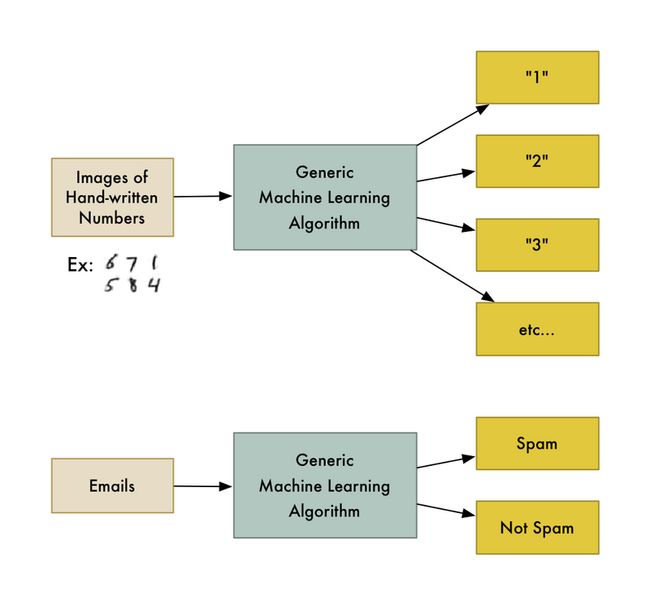
“Machine learning” is an umbrella term covering lots of these kinds of generic algorithms.
Two kinds of Machine Learning Algorithms: 两类机器学习算法
粗浅的划分,可以认为机器学习攘括的算法主要分为有监督学习与无监督学习,概念不难,但是很重要。
Supervised Learning: 有监督学习
假设你是一位成功的房地产中介,你的事业正在蒸蒸日上,现在打算雇佣更多的中介来帮你一起工作。不过问题来了,你可以一眼看出某个房子到底估值集合,而你的实习生们可没你这个本事。为了帮你的实习生尽快适应这份工作,你打算写个小的APP来帮他们根据房子的尺寸、邻居以及之前卖的类似的屋子的价格来评估这个屋子值多少钱。因此你翻阅了之前的资料,总结成了下表:
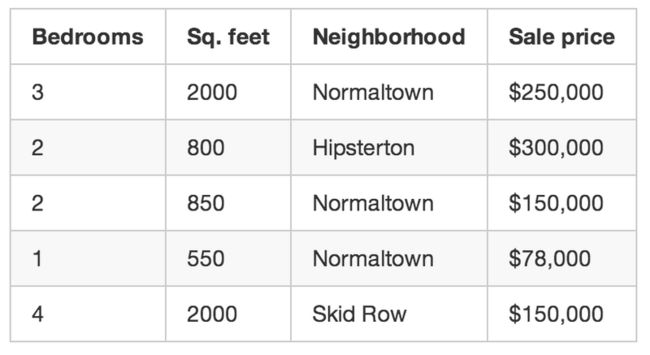
利用这些数据,我们希望最后的程序能够帮我们自动预测一个新的屋子大概能卖到多少钱:

解决这个问题的算法呢就是叫做监督学习,你已知一些历史数据,可以在这些历史数据的基础上构造出大概的处理逻辑。在将这些训练数据用于算法训练之后,通用的算法可以根据这个具体的场景得出最优的参数,有点像下面这张图里描述的一个简单的智力题:
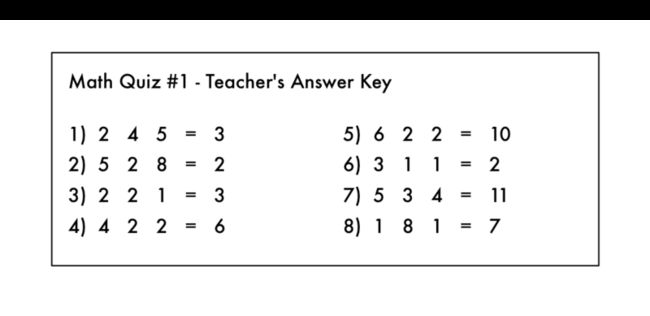
这个例子里,你能够知道根据左边的数字的不同推导出不同的右边的数字,那么你脑子里就自然而然生成了一个处理该问题的具体的逻辑。在监督学习里,你则是让机器帮你推导出这种关系,一旦知道了处理特定系列问题的数学方法,其他类似的问题也就都能迎刃而解。
Unsupervised Learning: 无监督学习
我们再回到最初的那个问题,如果你现在不知道每个房间的售价,而只知道房间大小、尺寸以及临近的地方,那咋办呢?这个时候,就是无监督学习派上用场的时候了。

这种问题有点类似于某人给了你一长串的数字然后跟你说,我不知道每个数字到底啥意思,不过你看看能不能通过某种模式或者分类或者啥玩意找出它们之间是不是有啥关系。那么对于你的实习生来说,这种类型的数据有啥意义呢?你虽然不能知道每个屋子的价格,但是你可以把这些屋子划分到不同的市场区间里,然后你大概能发现购买靠近大学城旁边的屋子的人们更喜欢更多的小卧室户型,而靠近城郊的更喜欢三个左右的卧室。知道不同地方的购买者的喜好可以帮助你进行更精确的市场定位。
另外你也可以利用无监督学习发现些特殊的房产,譬如一栋大厦,和其他你售卖的屋子差别很大,销售策略也不同,不过呢却能让你收获更多的佣金。本文下面会更多的关注于有监督学习,不过千万不能觉得无监督学习就无关紧要了。实际上,在大数据时代,无监督学习反而越来越重要,因为它不需要标注很多的测试数据。
这里的算法分类还是很粗浅的,如果要了解更多的细致的分类可以参考:
House Price Estimation With Supervised Learning: 利用监督学习进行房屋价格估计
作为高等智慧生物,人类可以自动地从环境与经历中进行学习,所谓熟读唐诗三百首,不会做诗也会吟,你房子卖多了那自然而然看到了某个屋子也就能知道价格以及该卖给啥样的人了。这个Strong_AI项目也就是希望能够将人类的这种能力复制到计算机上。不过目前的机器学习算法还没这么智能,它们只能面向一些特定的有一定限制的问题。因此,Learning这个概念,在这里更应该描述为:基于某些测试数据找出解决某个问题的等式,笔者也喜欢描述为对于数据的非线性拟合。希望五十年后看到这篇文章的人,能够推翻这个论述。
Let's Write the Program
基本的思想很好理解,下面就开始简单的实战咯。这里假设你还没写过任何机器学习的算法,那么直观的来说,我们可以编写一些简单的条件判断语句来进行房屋价格预测,譬如:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
price = 0
# 俺们这嘎达,房子基本上每平方200
price_per_sqft = 200
if neighborhood == "hipsterton":
# 市中心会贵一点
price_per_sqft = 400
elif neighborhood == "skid row":
# 郊区便宜点
price_per_sqft = 100
# 可以根据单价*房子大小得出一个基本价格
price = price_per_sqft * sqft
# 基于房间数做点调整
if num_of_bedrooms == 0:
# 没房间的便宜点
price = price — 20000
else:
# 房间越多一般越值钱
price = price + (num_of_bedrooms * 1000)
return price这就是典型的简答的基于经验的条件式判断,你也能通过这种方法得出一个较好地模型。不过如果数据多了或者价格发生较大波动的时候,你就有心无力了。而应用机器学习算法则是让计算机去帮你总结出这个规律,大概如下所示:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
price =
return price 通俗的理解,价格好比一锅炖汤,而卧室的数量、客厅面积以及邻近的街区就是食材,计算机帮你自动地根据不同的食材炖出不同的汤来。如果你是喜欢数学的,那就好比有三个自变量的方程,代码表述的话大概是下面这个样子:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
price = 0
# a little pinch of this
price += num_of_bedrooms * .841231951398213
# and a big pinch of that
price += sqft * 1231.1231231
# maybe a handful of this
price += neighborhood * 2.3242341421
# and finally, just a little extra salt for good measure
price += 201.23432095
return price注意,上面那些譬如.841...这样奇怪的数据,它们就是被称为权重,只要我们能根据数据寻找出最合适的权重,那我们的函数就能较好地预测出房屋的价格。
Weights
首先,我们用一个比较机械式的方法来寻找最佳的权重。
Step 1
首先将所有的权重设置为1:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
price = 0
# a little pinch of this
price += num_of_bedrooms * 1.0
# and a big pinch of that
price += sqft * 1.0
# maybe a handful of this
price += neighborhood * 1.0
# and finally, just a little extra salt for good measure
price += 1.0
return priceStep 2
拿已知的数据来跑一波,看看预测出来的值和真实值之间有多少差距,大概效果如下所示:

咳咳,可以看出这个差距还是很大的啊,不过不要担心,获取正确的权重参数的过程漫漫,我们慢慢来。我们将每一行的真实价格与预测价格的差价相加再除以总的屋子的数量得到一个差价的平均值,即将这个平均值称为cost,即所谓的代价函数。最理想的状态就是将这个代价值归零,不过基本上不太可能。因此,我们的目标就是通过不断的迭代使得代价值不断地逼近零。
Step 3
不断测试不同的权重的组合,从而找出其中最靠近零的一组。
Mind Blowage Time
很简单,不是吗?让我们再回顾下你刚才做了啥,拿了一些数据,通过三个泛化的简单的步骤获取一个预测值,不过在进一步优化之前,我们先来讨论一些小小的思考:
过去40年来,包括语言学、翻译等等在内的很多领域都证明了通用的学习算法也能表现出色,尽管这些算法本身看上去毫无意义。
刚才咱写的那个函数也是所谓的无声的,即函数中,并不知道卧室数目bedrooms、客厅大小square_feet这些变量到底是啥意思,它只知道输入某些数字然后得出一个值。这一点就很明显地和那些面向特定的业务逻辑的处理程序有很大区别。
估计你是猜不到哪些权重才是最合适的,或许你连自己为啥要这么写函数都不能理解,虽然你能证明这么写就是有用的。
如果我们把参数
sqft改成了图片中的像素的敏感度,那么原来输出的值是所谓的价格,而现在的值就是所谓的图片的类型,输入的不同,输出值的意义也就可以不一样。
Try every number?
言归正传,我们还是回到寻找最优的权重组合上来。你可以选择去带入所有的可能的权重组合,很明显是无穷大的一个组合,这条路肯定是行不通的。是时候展示一波数学的魅力了,这里我们介绍一个数学中常见的优化求值的方法:
首先,我们将Step 2中提出的代价方程公式化为如下形式:
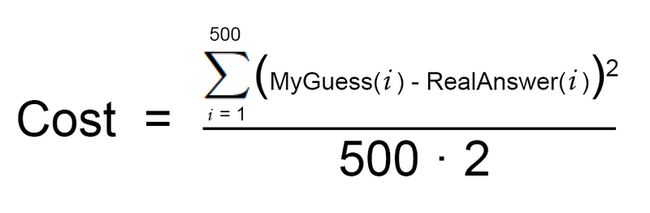
然后,我们将这个代价方程变得更加通用一点:

这个方程就代表了我们目前的权重组合离真实的权重组合的差距,如果我们测试多组数据,那么大概可以得出如下的数据图:
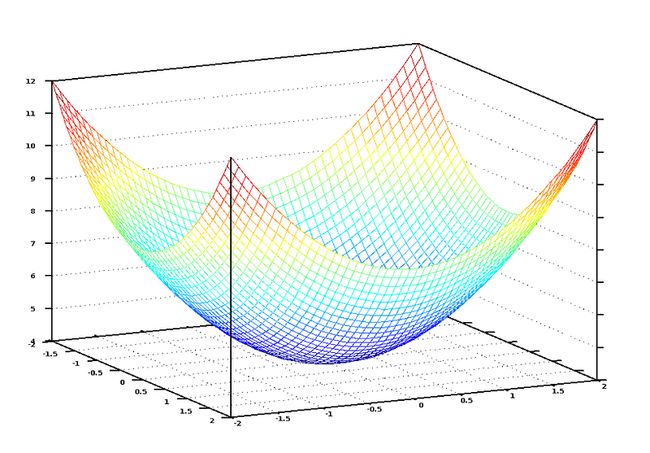
图中的蓝色低点即意味着代价最小,也就是权重组合最接近完美值的时候。
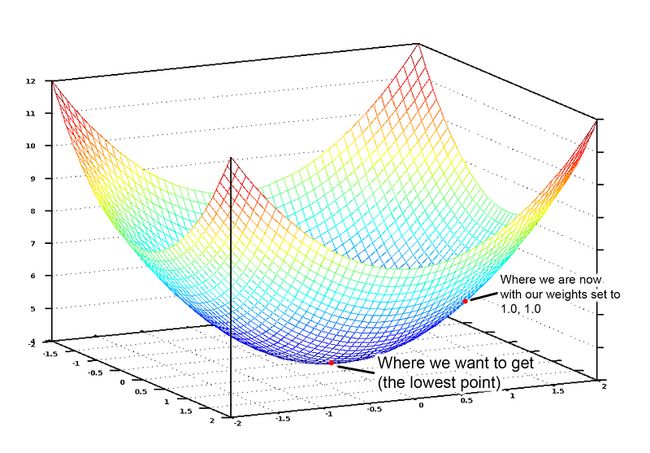
有了图之后是不是感觉形象多了?我们寻找最优权重的过程就是一步一步走到谷底的过程,如果我们每次小小地修改权重而使得其不断向谷底靠近,我们也就在向结果靠近。如果你还记得微积分的一些知识,应该知道函数的导数代表着函数的切线方向,换言之,在图中的任何一点我们通过计算函数的导数就知道变化的方向,即梯度下降的方向。我们可以计算出代价函数中每个变量的偏导数然后将每个当前变量值减去该偏导数,即按照梯度相反的方向前进,那就可以逐步解决谷底咯。如果你感兴趣的话,可以深入看看批量梯度下降相关的知识。
如果你是打算找个机器学习的工具库来辅助工具,那么到这里你的知识储备已经差不多咯,下面我们再扯扯其他的东西。
Something Skip Over: 刚才没提到的一些东西
上文提到的所谓三步的算法,用专业的名词表述应该是多元线性回归。即通过输入含有多个自变量的训练数据获得一个有效的计算表达式用于预测未来的部分房屋的价格。但是上面所讲的还是一个非常简单的例子,可能并不能在真实的环境中完美地工作,这时候就会需要下文即将介绍的包括神级网络、SVM等等更复杂一点的算法了。另外,我还没提到一个概念:overfitting(过拟合)。在很多情况下,只要有充足的时间我们都能得到一组在训练数据集上工作完美的权重组合,但是一旦它们用于预测,就会跌破眼镜,这就是所谓的过拟合问题。同样的,关于这方面也有很多的方法可以解决,譬如正则化 或者使用 交叉验证。
一言以蔽之,尽管基础的概念非常简单,仍然会需要一些技巧或者经验来让整个模型更好地工作,就好像一个才学完Java基础的菜鸟和一个十年的老司机一样。
Further Reading: 深入阅读
可能看完了这些,觉着ML好简单啊,那这么简单的东西又是如何应用到图片识别等等复杂的领域的呢?你可能会觉得可以用机器学习来解决任何问题,只要你有足够多的数据。不过还是要泼点冷水,千万记住,机器学习的算法只在你有足够的解决某个特定的问题的数据的时候才能真正起作用。譬如,如果你想依靠某个屋子内盆栽的数目来预测某个屋子的价格,呵呵。这是因为房屋的价格和里面的盆栽数目没啥必然联系,不管你怎么尝试,输入怎么多的数据,可能都不能如你所愿。
所以,总结而言,如果是能够手动解决的问题,那计算机可能解决的更快,但是它也无法解决压根解决不了的问题。在原作者看来,目前机器学习存在的一个很大的问题就是依然如阳春白雪般,只是部分科研人员或者商业分析人员的关注对象,其他人并不能简单地理解或者使用,在本节的最后也推荐一些公开的课程给对机器学习有兴趣的朋友:
Neural Network: 神级网络
上文中,我们通过一个简单的房价预测的例子了解了机器学习的基本含义,在本节,我们将会继续用一些泛化的算法搭配上一些特定的数据做些有趣的事情。本节的例子大概如下图所示,一个很多人的童年必备的游戏:马里奥,让我们用神级网络帮你设计一些新奇的关卡吧。
在正文之前,还是要强调下,本文是面向所有对机器学习有兴趣的朋友,所以大牛们看到了勿笑。
Introduction To Neural Networks: 神经网络模型初探
上文中我们是使用了多元线性回归来进行房屋价格预测,数据格式大概这个样子:

最后得到的函数是:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
price = 0
# a little pinch of this
price += num_of_bedrooms * 0.123
# and a big pinch of that
price += sqft * 0.41
# maybe a handful of this
price += neighborhood * 0.57
return price如果用图来表示的话,大概是这个样子:
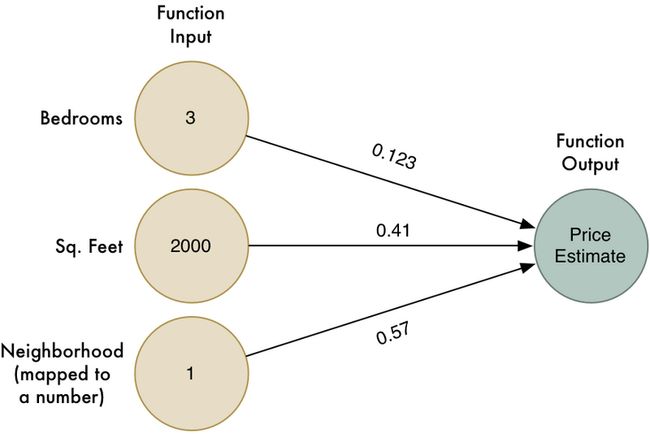
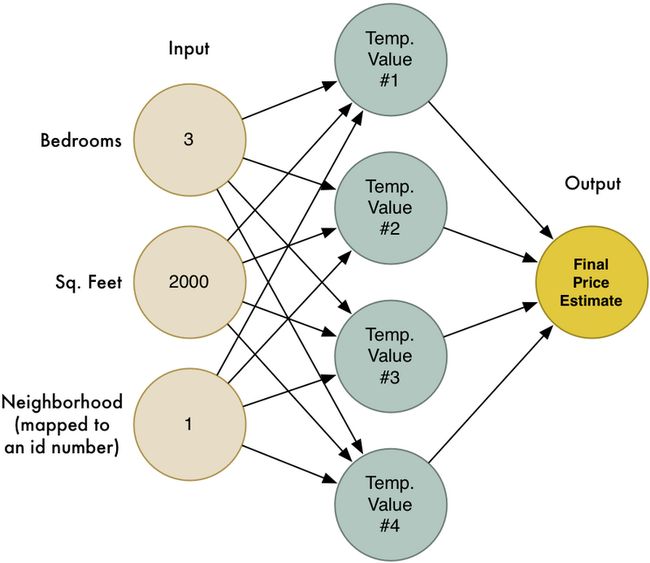
不过正如上文中提到的,这个算法只能处理一些较为简单的问题,即结果与输入的变量之间存在着某些线性关系。Too young,Too Simple,真实的房价和这些可不仅仅只有简单的线性关系,譬如邻近的街区这个因子可能对面积较大和面积特别小的房子有影响,但是对于那些中等大小的毫无关系,换言之,price与neighborhood之间并不是线性关联,而是类似于二次函数或者抛物线函数图之间的非线性关联。这种情况下,我们可能得到不同的权重值(形象来理解,可能部分权重值是收敛到某个局部最优):
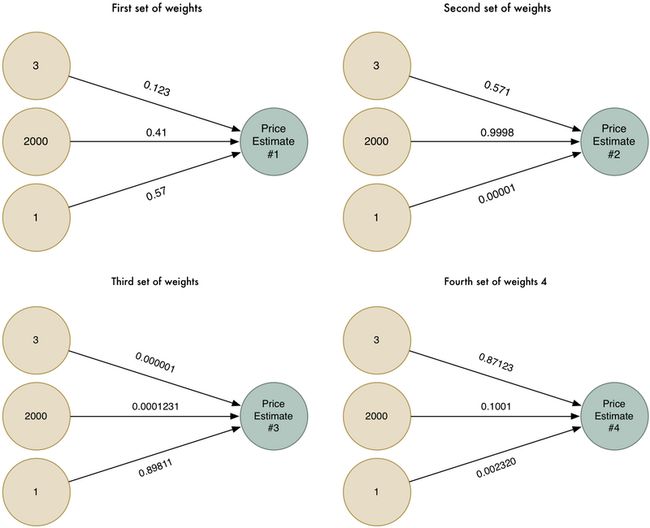
现在等于每次预测我们有了四个独立的预测值,下一步就是需要将四个值合并为一个最终的输出值:
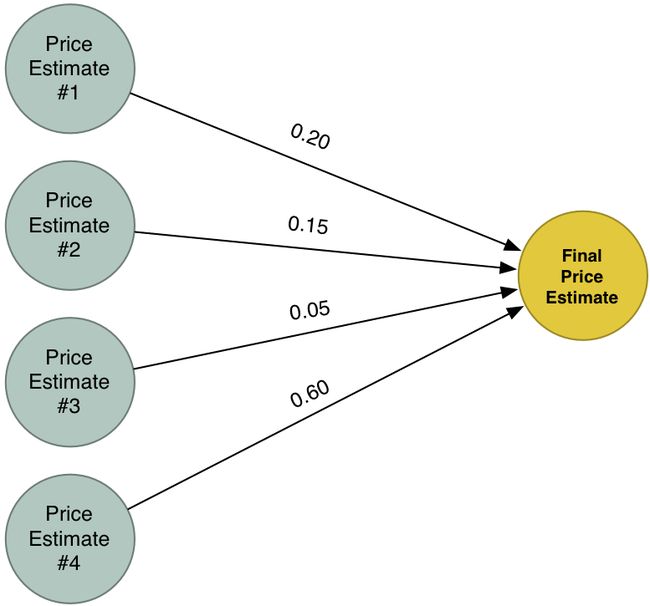
What is Neural Network?: 神经网络初识
我们将上文提到的两个步骤合并起来,大概如下图所示:
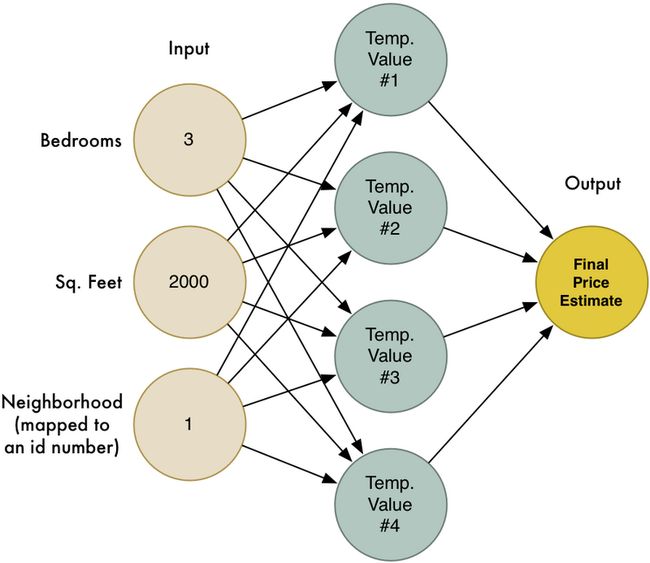
咳咳,没错,这就是一个典型的神级网络,每个节点接收一系列的输入,为每个输入分配权重,然后计算输出值。通过连接这一系列的节点,我们就能够为复杂的函数建模。同样为了简单起见,我在这里也跳过了很多概念,譬如 feature scaling 以及 activation function,不过核心的概念是:
每个能够接收一系列的输入并且能够按权重求和的估值函数被称为Neuron(神经元)
多个简单的神经元的连接可以用来构造处理复杂问题的模型
有点像乐高方块,单个的乐高方块非常简单,而大量的乐高方块却可以构建出任何形状的物体:

Giving Our Neural Network a Memory: 给神级网络加点上下文
目前,整个神级网络是无状态的,即对于任何相同的输入都返回相同的输出。这个特性在很多情况下,譬如房屋价格估计中是不错的,不过这种模式并不能处理时间序列的数据。举个栗子,我们常用的输入法中有个智能联想的功能,可以根据用户输入的前几个字符预测下一个可能的输入字符。最简单的,可以根据常见的语法来推测下一个出现的字符,而我们也可以根据用户历史输入的记录来推测下一个出现的字符。基于这些考虑,我们的神经网络模型即如下所示:

譬如用户已经输入了如下的语句:
Robert Cohn was once middleweight boxi你可能会猜想是n,这样整个词汇就是boxing,这是基于你看过了前面的语句以及基本的英文语法得出的推论,另外,middleweight这个单词也给了我们额外的提示,跟在它后面的是boxing。换言之,在文本预测中,如果你能将句子的上下文也考虑进来,再加上基本的语法知识就能较为准确地预测出下一个可能的字符。因此,我们需要给上面描述的神经网络模型添加一些状态信息,也就是所谓的上下文的信息:
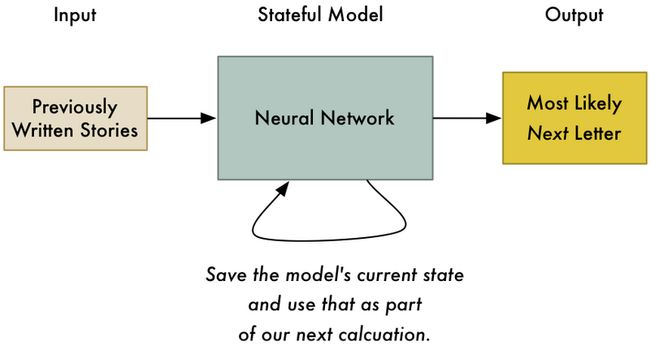
在神经网络模型中也保持了对于上下文的追踪,从而使得该模型不仅仅能预测第一个词是啥,也能预测最有可能出现的下一个词汇。该模型就是所谓的Recurrent Neural Network:循环神经网络的基本概念。每次使用神经网络的同时也在更新其参数,也就保证了能够根据最新的输入内容预测下一个可能的字符,只要有足够的内存情况下,它可以将完整的时序上下文全部考虑进去。
Generating a story: 生成一个完整的故事
正如上文所说,文本预测在实际应用中一个典型的例子就是输入法,譬如iPhone里面会根据你之前输入的字符自动帮你补全:
不过我们做的更疯狂一点,既然模型可以根据上一个字符自动预测下一个字符,那我们何不让模型来自动构建一个完整的故事? 我们在这里使用Andrej Karpathy创建的Recurrent Neural Network implementation框架来进行实验,他也发表了一系列关于如何使用RNN进行文档生成的博客。我们还是使用The Sun Also Rises这篇文章,该文章包括大小写、标点符号等在内一共有84个不同的字符以及362239个词汇。这个数据集合的大小和真实环境中的应用文本相比还是很小的,为了尽可能模仿原作者的风格,最好的是能有数倍的文本进行训练,不过作为例子这边还是足够的。经过大概100次迭代之后,得到的结果是:
hjCTCnhoofeoxelif edElobe negnk e iohehasenoldndAmdaI ayio pe e h’e btentmuhgehi bcgdltt. gey heho grpiahe.
Ddelnss.eelaishaner” cot AAfhB ht ltny
ehbih a”on bhnte ectrsnae abeahngy
amo k ns aeo?cdse nh a taei.rairrhelardr er deffijha惨不忍睹啊,继续进行训练,大概1000次迭代之后,内容看起来好一点了:
hing soor ither. And the caraos, and the crowebel for figttier and ale the room of me? Streat was not to him Bill-stook of the momansbed mig out ust on the bull, out here. I been soms
inick stalling that aid.
“Hon’t me and acrained on .Hw’s don’t you for the roed,” In’s pair.”
“Alough marith him.”已经能够识别基本的句型结构与语法规则咯,甚至能够较好地为上下文添加标点符号了,不过还是存在着大量的无意义词汇,我们继续增加训练的次数:
He went over to the gate of the café. It was like a country bed.
“Do you know it’s been me.”
“Damned us,” Bill said.
“I was dangerous,” I said. “You were she did it and think I would a fine cape you,” I said.
“I can’t look strange in the cab.”
“You know I was this is though,” Brett said.
“It’s a fights no matter?”
“It makes to do it.”
“You make it?”
“Sit down,” I said. “I wish I wasn’t do a little with the man.”
“You found it.”
“I don’t know.”
“You see, I’m sorry of chatches,” Bill said. “You think it’s a friend off back and make you really drunk.”现在差不多能看了,有些句式还是很模仿Hemingway’s的风格的,而原作者的内容是:
There were a few people inside at the bar, and outside, alone, sat Harvey Stone. He had a pile of saucers in front of him, and he needed a shave.
“Sit down,” said Harvey, “I’ve been looking for you.”
“What’s the matter?”
“Nothing. Just looking for you.”
“Been out to the races?”
“No. Not since Sunday.”
“What do you hear from the States?”
“Nothing. Absolutely nothing.”
“What’s the matter?”Super Mario: 利用神级网络进行Mario过关训练
In 2015, Nintendo 宣布了 Super Mario Maker™ 用于Wii U游戏系统上。
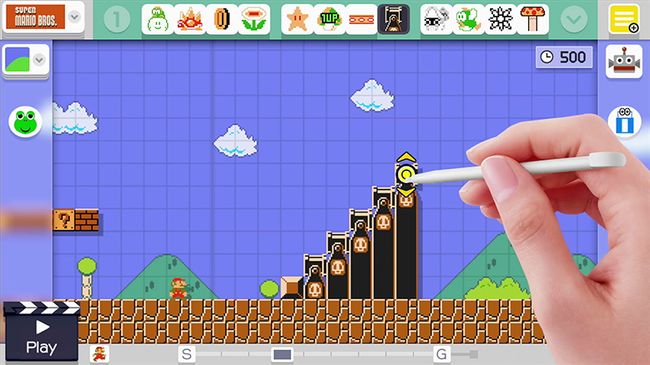
这个制作器能够让你去手动制作马里奥的一些关卡,很不错的和朋友之间进行互动的小工具。你可以添加常见的障碍物或者敌人到你自己设计的关卡中,有点像可视化的乐高工作台。我们可以使用刚才创建的用于预测Hemingway文本的模型来自动地创建一个超级马里奥的关卡。首先呢,我们还是需要去找一些训练数据,最早的1985年推出的经典的超级马里奥的游戏不错:

这个游戏有大概32个关卡,其中70%的场景都有相似的外观,很适合用来做训练数据啊。我找来了每一关的设计方案,网上有很多类似的教程教你怎么从内存中读取游戏的设计方案,有兴趣的话你也可以试试。下面呢就是一个经典的全景视图:

用放大镜观察的话,可以看出每一关都是由一系列的网格状对象组成的:

这样的话,我们可以将每个网格中的对象用一个字符代替,而整个关卡的字符化表述就是:
--------------------------
--------------------------
--------------------------
#??#----------------------
--------------------------
--------------------------
--------------------------
-##------=--=----------==-
--------==--==--------===-
-------===--===------====-
------====--====----=====-
=========================-其中:
-代表空白=代表坚固的方块#代表那些可以被撞破的块?代表钱币块

仔细瞅瞅这个文件,你会发现如果按照一行一行从左到右读的话,好像是毫无头绪:

不过如果按照列的次序从上往下读的话,你会发现还是有点套路的:

为了更好地训练数据,我们打算按列来分割数据,这里我们会使用特征选择的技术来将数据转化为最合适的表示。首先,我们将整个文本旋转90度:
-----------=
-------#---=
-------#---=
-------?---=
-------#---=
-----------=
-----------=
----------@=
----------@=
-----------=
-----------=
-----------=
---------PP=
---------PP=
----------==
---------===
--------====
-------=====
------======
-----=======
---=========
---=========然后就可以使用上面创建好的模型进行训练咯,经过几轮训练之后大概可以得出这个样子:
--------------------------
LL+<&=------P-------------
--------
---------------------T--#--
-----
-=--=-=------------=-&--T--------------
--------------------
--=------$-=#-=-_
--------------=----=<----
-------b
-最初的训练里模型认知到应该大量的出现-与=字符,不过还是很粗糙,再经过几千次的训练,得出的内容是:
--
-----------=
----------=
--------PP=
--------PP=
-----------=
-----------=
-----------=
-------?---=
-----------=
-----------=此时模型已经能够认知到需要将每行保证相同的长度,甚至开始寻找出Mario内在的规律:管道呢一般都是两个块这么宽,所以它将所有的P都放到了2*2的矩阵中,聪明了一点啊。继续学习:
--------PP=
--------PP=
----------=
----------=
----------=
---PPP=---=
---PPP=---=
----------=
看上去像模像样了,其中有几个需要特别注意的地方:
Lakitu,就是那个小怪兽被放到了半空中,跟Mario关卡一样一样的。
它认知到了应该把管道插入大地
并没有让玩家无路可走
看起来风格非常像最传统的马里奥的版本
最后生成出来的游戏截图大概是这样的:

你可以在这里观看完整的游戏视频。
Toys VS Real World Applications
这里用于训练模型的循环神经网络算法与真实环境下大公司用于解决语音识别以及文本翻译等常见问题的算法一本同源,而让我们的模型看上去好像个玩具一样的原因在于我们的训练数据。仅仅取自最早期的超级马里奥的一些关卡数据远远不足以让我们的模型出类拔萃。如果我们能够获取由其他玩家创建的成百上千的关卡信息,我们可以让模型变得更加完善。不过可惜的是我们压根获取不到这些数据。
随着机器学习在不同的产业中变得日渐重要,好的程序与坏的程序之间的差异越发体现在输入数据的多少。这也就是为啥像Google或者Facebook这样的大公司千方百计地想获取你的数据。譬如Google最近开源的TensorFlow,一个用于大规模可扩展的机器学习的集群搭建应用,它本身就是Google内部集群的重要组成部分。不过没有Google的海量数据作为辅助,你压根创建不了媲美于Google翻译那样的牛逼程序。下次你再打开 Google Maps Location History 或者 Facebook Location History ,想想它们是不是记录下你日常的东西。
Further Reading
条条大道通罗马,在机器学习中解决问题的办法也永远不止一个。你可以有很多的选项来决定如何进行数据预处理以及应该用啥算法。增强学习正是可以帮你将多个单一的方法组合起来的好途径。如果你想更深入的了解,你可以参考下面几篇较为专业的论文:
Amy K. Hoover’s team used an approach that represents each type of level object (pipes, ground, platforms, etc) as if it were single voice in an overall symphony. Using a process called functional scaffolding, the system can augment levels with blocks of any given object type. For example, you could sketch out the basic shape of a level and it could add in pipes and question blocks to complete your design.
Steve Dahlskog’s team showed that modeling each column of level data as a series of n-gram “words” makes it possible to generate levels with a much simpler algorithm than a large RNN.
Object Recognition In Images With Deep Learning: 利用深度学习对于图片中对象进行识别
近年来关于深度学习的讨论非常火爆,特别是之前阿尔法狗大战李世乭之后,更是引发了人们广泛地兴趣。南大的周志华教授在《机器学习》这本书的引言里,提到了他对于深度学习的看法:深度学习掀起的热潮也许大过它本身真正的贡献,在理论和技术上并没有太大的创新,只不过是由于硬件技术的革命,从而得到比过去更精细的结果。相信读者看完了第三部分也会有所感。
仁者见仁智者见智,这一章节就让我们一起揭开深度学习的神秘面纱。在本章中,我们还是基于一个实际的例子来介绍下深度学习的大概原理,这里我们会使用简单的卷积神级网络来进行图片中的对象识别。换言之,就类似于Google Photos的以图搜图的简单实现,大概最终的产品功能是这个样子的:
就像前两章一样,本节的内容尽量做到即不云山雾罩,不知所云,也不阳春白雪,曲高和寡,希望每个队机器学习感兴趣的人都能有所收获。这里我们不会提到太多的数学原理与实现细节,所以也不能眼高手低,觉得深度学习不过尔尔呦。
Recognizing Objects: 对象识别
先来看一个有趣的漫画:

这个漫画可能有点夸张了,不过它的灵感还是来自于一个现实的问题:一个三岁的小孩能够轻易的辨别出照片中的鸟儿,而最优秀的计算机科学家需要用50年的时间来教会机器去识别鸟儿。在过去的数年中,我们发现了一个对象识别的好办法,即是利用深度卷积神级网络。有点像William Gibson的科幻小说哈,不过只要跟着本文一步一步来,你就会发现这事一点也不神秘。Talk is cheap, Show you the word~
Starting Simple: 先来点简单的
在尝试怎么识别照片中的鸟儿之前,我们先从一些简单的识别开始:怎么识别手写的数字8。在上一章节,我们了解了神级网络是如何通过链式连接组合大量的简单的neurons(神经元)来解决一些复杂的问题。我们创建了一个简单的神级网络来基于床铺数目、房间大小以及邻居的类型来预测某个屋子的可能的价格。
再重述下机器学习的理念,即是一些通用的,可以根据不同的数据来处理不同的问题的算法。因此我们可以简单地修改一些神级网络就可以识别手写文字,在这里简单起见,我们只考虑一个字符:手写的数字8。
大量的数据是机器学习不可代替的前提条件与基石,首先我们需要去寻找很多的训练数据。索性对于这个问题的研究已持续了很久,也有很多的开源数据集合,譬如MNIST关于手写数字的数据集。MNIST提供了60000张不同的关于手写数字的图片,每个都是18*18的大小,其中部分关于8的大概是这个样子:

上章节中构造的神级网络有三个输入,在这里我们希望用神级网络来处理图片,第二步就是需要将一张图片转化为数字的组合,即是计算机可以处理的样子。表担心,这一步还是很简单的。对于电脑而言,一张图片就是一个多维的整型数组,每个元素代表了每个像素的模糊度,大概是这样子:
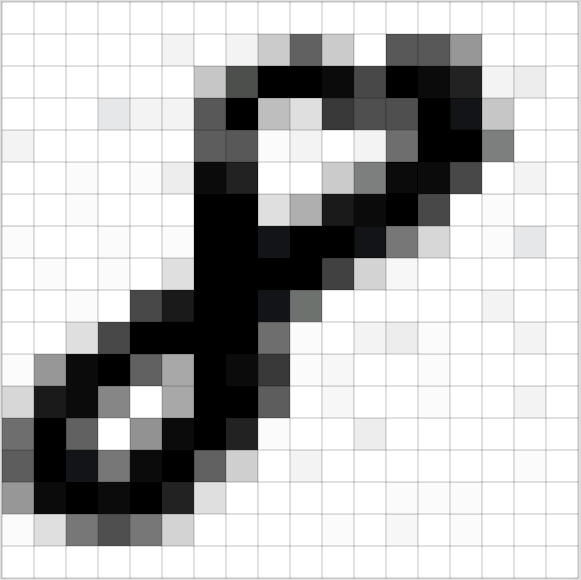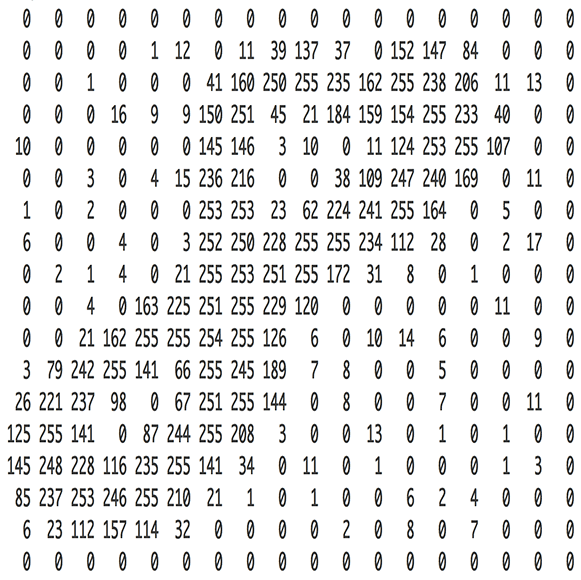
为了能够将图片应用到我们的神经网络模型中,我们需要将18*18像素的图片转化为324个数字:

这次的共有324个输入,我们需要将神经网络扩大化转化为324个输入的模型:
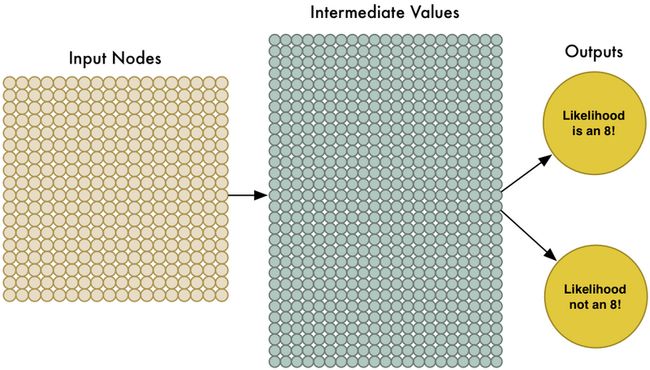
注意,我们的神经网络模型中有两个输出,第一个输出预测该图片是8的概率,第二个输出是预测图片不是8的概率。对于要辨别的图片,我们可以使用神经网络将对象划分到不同的群组中。虽然这次我们的神经网络比上次大那么多,但是现代的电脑仍然可以在眨眼间处理上百个节点,甚至于能够在你的手机上工作。(PS:Tensorflow最近支持iOS了)在训练的时候,当我们输入一张确定是8的图片的时候,会告诉它概率是100%,不是8的时候输入的概率就是0%。我们部分的训练数据如下所示:

Tunnel Vision
虽然我们上面一直说这个任务不难,不过也没那么简单。首先,我们的识别器能够对于标准的图片,就是那些数字端端正正坐在中间,不歪不扭的图片,可以非常高效准确地识别,譬如:

不过实际情况总不会如我们所愿,当那些熊孩子一般的8也混进来的时候,我们的识别器就懵逼了。

1. Searching with a Sliding Window: 基于滑动窗口的搜索
虽然道路很曲折,但是问题还是要解决的,我们先来试试暴力搜索法。我们已经创建了一个可以识别端端正正的8的识别器,我们的第一个思路就是把图片分为一块块地小区域,然后对每个区域进行识别,判断是否属于8,大概思路如下所示:

这方法叫滑动窗口法,典型的暴力搜索解决方法。在部分特定的情况下能起到较好地作用,不过效率非常低下。譬如对于同一类型但是大小不同的图片,你可能就需要一遍遍地搜索。
1. More data and a Deep Neural Net
刚才那个识别器训练的时候,我们只是把部分规规矩矩的图片作为输入的训练数据。不过如果我们选择更多的训练数据时,自然也包含那些七歪八斜的8的图片,会不会起到什么神奇的效果呢?我们甚至不需要去搜集更多的测试数据,只要写个脚本然后把8放到图片不同的位置上即可:

用这种方法,我们可以方便地创建无限的训练数据。数据有了,我们也需要来扩展下我们的神经网络,从而使它能够学习些更复杂的模式。具体而言,我们需要添加更多的中间层:
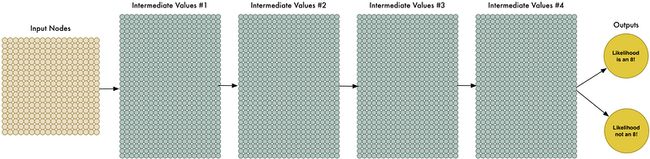
这个呢,就是我们所谓的深度神经网络,因为它比传统的神经网络有更多的中间层。这个概念从十九世纪六十年代以来就有了,不过训练大型的神经网络一直很缓慢而无法达到真实的应用预期。不过近年来随着我们认识到使用3D图卡来代替传统的CPU处理器来进行神经网络的训练,使用大型的神经网络突然之间就变得不再那么遥不可及。

不过尽管我们可以依靠3D图卡解决计算问题,仍然需要寻找合适的解决方案。我们需要寻找合适的将图片处理能够输入神经网络的方法。好好考虑下,我们训练一个网络用来专门识别图片顶部的8与训练一个网络专门用来识别图片底部的8,把这两个网络分割开来,好像压根没啥意义。因此,我们最终要得到的神经网络是要能智能识别无论在图片中哪个位置的8。
The Solution is Convolution:卷积神经网络
人们在看图片的时候一般都会自带层次分割的眼光,譬如下面这张图:

你可以一眼看出图片中的不同的层次:
地上覆盖着草皮与水泥
有个宝宝
宝宝坐在个木马上
木马在草地上
更重要的是,不管宝宝坐在啥上面,我们都能一眼看到那嘎达有个宝宝。即使宝宝坐在汽车、飞机上,我们不经过重新的学习也可以一眼分辨出来。可惜现在我们的神经网络还做不到这一点,它会把不同图片里面的8当成不同的东西对待,并不能理解如果在图片中移动8,对于8而言是没有任何改变的。也就意味着对于不同位置的图片仍然需要进行重新学习。我们需要赋予我们的神经网络能够理解平移不变性:不管8出现在图片的哪个地方,它还是那个8。我们打算用所谓的卷积的方法来进行处理,这个概念部分来自于计算机科学,部分来自生物学,譬如神经学家教会猫如何去辨别图片。
How Convolution Works
上面我们提到一个暴力破解的办法是将图片分割到一个又一个的小网格中,我们需要稍微改进下这个办法。
1. 将图片分割为重叠的砖块
譬如上面提到的滑动窗口搜索,我们将原图片分割为独立的小块,大概如下图所示:

通过这一步操作,我们将原始图片分割为了77张大小相同的小图片。
2. 将每个图片瓷砖输入到小的神经网络中
之前我们就训练一个小的神经网络可以来判断单个图片是否属于8,不过在这里我们的输出并不是直接判断是不是8,而是处理输出一个特征数组:
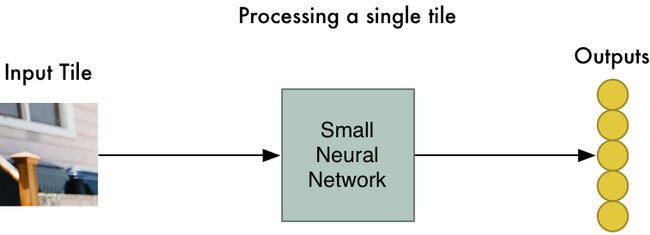
对于不同的图片的瓷砖块,我们都会使用具有相同权重的神经网络来进行处理。换言之,我们将不同的图片小块都同等对待,如果在图片里发现了啥好玩的东西,我们会将该图片标识为待进一步观察的。
3. 将每个小块的处理结果存入一个新的数组
对于每个小块输出的数组,我们希望依然保持图片块之间的相对位置关联,因此我们将每个输出的数组仍然按照之前的图片块的次序排布:
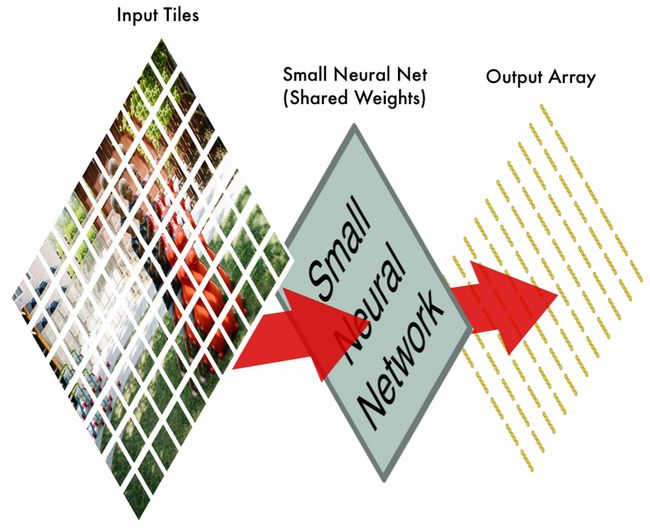
到这里,我们输入一个大图片,输出一个相对而言紧密一点的数组,包含了我们可能刚兴趣的块的记录。
4. 缩减像素采样
上一步的结果是输出一个数组,会映射出原始图片中的哪些部分是我们感兴趣的。不过整个数组还是太大了:

为了缩减该特征数组的大小,我们打算使用所谓的max pooling算法来缩减像素采样数组的大小,这算法听起来高大上,不过还是挺简单的:
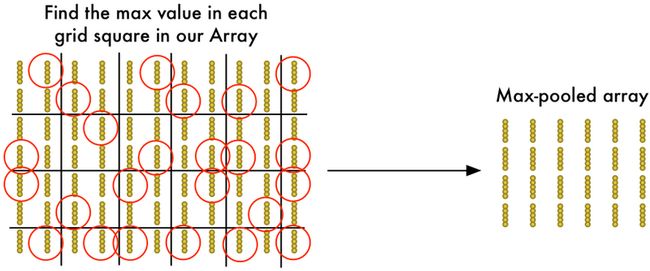
Max pooling处理过程上呢就是将原特征矩阵按照2*2分割为不同的块,然后从每个方块中找出最有兴趣的位保留,然后丢弃其他三个数组。
5. 进行预测
截至目前,一个大图片已经转化为了一个相对较小地数组。该数组中只是一系列的数字,因此我们可以将该小数组作为输入传入另一个神经网络,该神经网络会判断该图片是否符合我们的预期判断。为了区别于上面的卷积步骤,我们将此称为fully connected网络,整个步骤呢,如下所示:
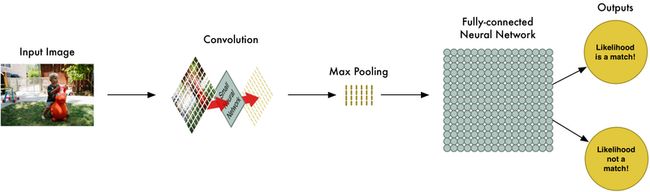
6. 添加更多的步骤
上面的图片处理过程可以总结为以下步骤:
Convolution: 卷积
Max-pooling: 特征各维最大汇总
Full-connected: 全连接网络
在真实的应用中,这几个步骤可以组合排列使用多次,你可以选择使用两个、三个甚至十个卷积层,也可以在任何时候使用Max-pooling来减少数据的大小。基本的思想就是将一个大图片不断地浓缩直到输出一个单一值。使用更多地卷积步骤,你的网络就可以处理学习更多地特征。举例而言,第一个卷积层可以用于识别锐边,第二个卷积层能够识别尖锐物体中的鸟嘴,而第三个卷积层可以基于其对于鸟嘴的知识识别整个鸟。下图就展示一个更现实点地深度卷积网络:
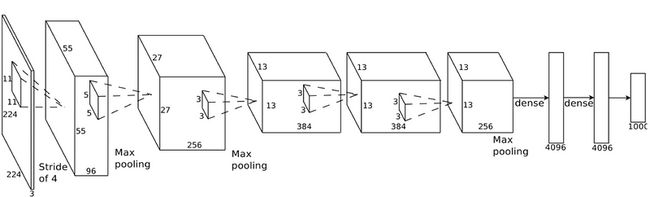
在这个例子中,最早地是输入一个224*224像素的图片,然后分别使用两次卷积与Max-pooling,然后再依次使用卷积与Max-pooling,最后使用两个全连接层。最后的结果就是图片被分到哪一类。
Building our Bird Classifier: 构建一个真实的鸟儿分类器
概念了解了,下面我们就动手写一个真正的鸟类分类器。同样地,我们需要先收集一些数据。免费的 CIFAR10 data set包含了关于鸟儿的6000多张图片以及52000张不是鸟类的图片。如果不够,Caltech-UCSD Birds-200–2011 data set 中还有12000张鸟类的图片。其中关于鸟类的图片大概如下所示:

非鸟类的图片大概这样:

这边我们会使用TFLearn来构建我们的程序,TFLearn是对于Google的TensorFlow 深度学习库的一个包裹,提供了更易用的API,可以让编写卷积神经网络就好像编译我们其他的网络层一样简单:
# -*- coding: utf-8 -*-
"""
Based on the tflearn example located here:
https://github.com/tflearn/tflearn/blob/master/examples/images/convnet_cifar10.py
"""
from __future__ import division, print_function, absolute_import
# Import tflearn and some helpers
import tflearn
from tflearn.data_utils import shuffle
from tflearn.layers.core import input_data, dropout, fully_connected
from tflearn.layers.conv import conv_2d, max_pool_2d
from tflearn.layers.estimator import regression
from tflearn.data_preprocessing import ImagePreprocessing
from tflearn.data_augmentation import ImageAugmentation
import pickle
# Load the data set
X, Y, X_test, Y_test = pickle.load(open("full_dataset.pkl", "rb"))
# Shuffle the data
X, Y = shuffle(X, Y)
# Make sure the data is normalized
img_prep = ImagePreprocessing()
img_prep.add_featurewise_zero_center()
img_prep.add_featurewise_stdnorm()
# Create extra synthetic training data by flipping, rotating and blurring the
# images on our data set.
img_aug = ImageAugmentation()
img_aug.add_random_flip_leftright()
img_aug.add_random_rotation(max_angle=25.)
img_aug.add_random_blur(sigma_max=3.)
# Define our network architecture:
# Input is a 32x32 image with 3 color channels (red, green and blue)
network = input_data(shape=[None, 32, 32, 3],
data_preprocessing=img_prep,
data_augmentation=img_aug)
# Step 1: Convolution
network = conv_2d(network, 32, 3, activation='relu')
# Step 2: Max pooling
network = max_pool_2d(network, 2)
# Step 3: Convolution again
network = conv_2d(network, 64, 3, activation='relu')
# Step 4: Convolution yet again
network = conv_2d(network, 64, 3, activation='relu')
# Step 5: Max pooling again
network = max_pool_2d(network, 2)
# Step 6: Fully-connected 512 node neural network
network = fully_connected(network, 512, activation='relu')
# Step 7: Dropout - throw away some data randomly during training to prevent over-fitting
network = dropout(network, 0.5)
# Step 8: Fully-connected neural network with two outputs (0=isn't a bird, 1=is a bird) to make the final prediction
network = fully_connected(network, 2, activation='softmax')
# Tell tflearn how we want to train the network
network = regression(network, optimizer='adam',
loss='categorical_crossentropy',
learning_rate=0.001)
# Wrap the network in a model object
model = tflearn.DNN(network, tensorboard_verbose=0, checkpoint_path='bird-classifier.tfl.ckpt')
# Train it! We'll do 100 training passes and monitor it as it goes.
model.fit(X, Y, n_epoch=100, shuffle=True, validation_set=(X_test, Y_test),
show_metric=True, batch_size=96,
snapshot_epoch=True,
run_id='bird-classifier')
# Save model when training is complete to a file
model.save("bird-classifier.tfl")
print("Network trained and saved as bird-classifier.tfl!")如果你有足够的RAM,譬如Nvidia GeForce GTX 980 Ti或者更好地硬件设备,大概能在1小时内训练结束,如果是普通的电脑,时间要耗费地更久一点。随着一轮一轮地训练,准确度也在不断提高,第一轮中准确率只有75.4%,十轮之后准确率到91.7%,在50轮之后,可以达到95.5%的准确率。
Testing out Network
我们可以使用如下脚本进行图片的分类预测:
# -*- coding: utf-8 -*-
from __future__ import division, print_function, absolute_import
import tflearn
from tflearn.layers.core import input_data, dropout, fully_connected
from tflearn.layers.conv import conv_2d, max_pool_2d
from tflearn.layers.estimator import regression
from tflearn.data_preprocessing import ImagePreprocessing
from tflearn.data_augmentation import ImageAugmentation
import scipy
import numpy as np
import argparse
parser = argparse.ArgumentParser(description='Decide if an image is a picture of a bird')
parser.add_argument('image', type=str, help='The image image file to check')
args = parser.parse_args()
# Same network definition as before
img_prep = ImagePreprocessing()
img_prep.add_featurewise_zero_center()
img_prep.add_featurewise_stdnorm()
img_aug = ImageAugmentation()
img_aug.add_random_flip_leftright()
img_aug.add_random_rotation(max_angle=25.)
img_aug.add_random_blur(sigma_max=3.)
network = input_data(shape=[None, 32, 32, 3],
data_preprocessing=img_prep,
data_augmentation=img_aug)
network = conv_2d(network, 32, 3, activation='relu')
network = max_pool_2d(network, 2)
network = conv_2d(network, 64, 3, activation='relu')
network = conv_2d(network, 64, 3, activation='relu')
network = max_pool_2d(network, 2)
network = fully_connected(network, 512, activation='relu')
network = dropout(network, 0.5)
network = fully_connected(network, 2, activation='softmax')
network = regression(network, optimizer='adam',
loss='categorical_crossentropy',
learning_rate=0.001)
model = tflearn.DNN(network, tensorboard_verbose=0, checkpoint_path='bird-classifier.tfl.ckpt')
model.load("bird-classifier.tfl.ckpt-50912")
# Load the image file
img = scipy.ndimage.imread(args.image, mode="RGB")
# Scale it to 32x32
img = scipy.misc.imresize(img, (32, 32), interp="bicubic").astype(np.float32, casting='unsafe')
# Predict
prediction = model.predict([img])
# Check the result.
is_bird = np.argmax(prediction[0]) == 1
if is_bird:
print("That's a bird!")
else:
print("That's not a bird!")How accurate is 95% accurate?: 怎么理解这95%的准确率
刚才有提到,我们的程序有95%的准确度,不过这并不意味着你拿张图片来,就肯定有95%的概率进行准确分类。举个栗子,如果我们的训练数据中有5%的图片是鸟类而其他95%的都不是鸟类,那么就意味着每次预测其实不是鸟类的准确度达到95%。因此,我们不仅要关注整体的分类的准确度,还需要关注分类正确的数目,以及哪些图片分类失败,为啥失败的。这里我们假设预测结果并不是简单的正确或者错误,而是分到不同的类别中:
首先,我们将正确被标识为鸟类的鸟类图片称为:True Positives

其次,对于标识为鸟类的非鸟类图片称为:True Negatives

对于划分为鸟类的非鸟类图片称为:False Positives

对于划分为非鸟类的鸟类图片称为:False Negatives

最后的值可以用如下矩阵表示:

这种分法的一个现实的意义譬如我们编写一个程序在MRI图片中检测癌症,false positives的结果很明显好于false negatives。False negatives意味着那些你告诉他没得癌症但是人家就是癌症的人。这种错误的比例应该着重降低。除此之外,我们还计算Precision_and_recall来衡量整体的准确度:

Further Reading
