Flink 学习九 Flink 程序分布式运行部署
Flink 学习九 Flink 程序分布式运行部署
1.Job 执行计划
| 层级 | 说明 | 备注 |
|---|---|---|
| StreamGraph | 用户代码生成的最初的图 | 程序的运行流程图 |
| JobGraph | 将多个符合条件的节点 | 多个符合条件的节点合并,减少序列化和反序列化 |
| ExecutionGraph | JobGraph 的并行化 | 调度层的核心数据结构 |
| PhysicalGraph | JobManager根据ExecutionGraph 对Job 进行调度,在各个TaskManager上部署Task 后形成的图 | 不是一个具体的数据结构 |
如图所示在每个层级的图的示例
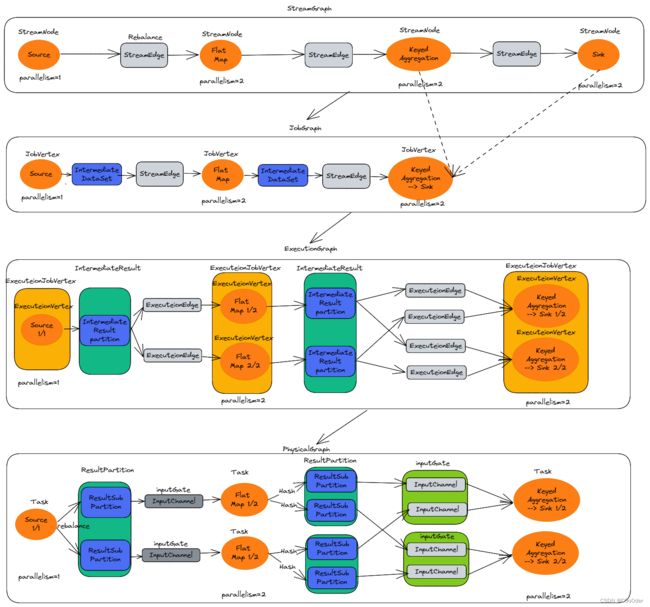
- 在客户端:根据java代码,转换成StreamGraph ,然后再判断是否符合算子chain合并的条件,可以将多个StreamNode 合并成JobGraph,
- JobGraph提交给集群中的JobManager
- JobManager 收到JobGraph 后,将JobGraph 转换成ExecutionGraph (其中具有每个点的执行并行度,序列化等),然后再根据图,申请对应的slot 槽位,并发送给对应的task
- 运行后的效果图PhysicalGraph 在代码里面的数据结构是没有的,上面三个都有
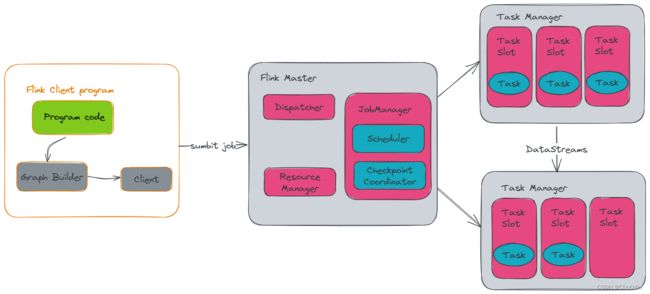
2.运行时架构
3.Flink standalone集群模式&安装
flink 程序运行为standalone 集群模式,需要安装 flink standalone集群
3.1 集群机器规划
| 服务地址 | 用户名 | 角色 | |
|---|---|---|---|
| 192.168.141.131 | CentOSA | flink/master | |
| 192.168.141.132 | CentOSB | flink/slave | |
| 192.168.141.133 | CentOSC | flink/slave | |
| 192.168.141.134 | CentOSD | flink/slave |
3.2 主机名修改
192.168.141.131 CentOSA
192.168.141.132 CentOSB
192.168.141.133 CentOSC
192.168.141.134 CentOSD
3.3 集群免密
参考之前的文章
https://blog.csdn.net/weixin_44244088/article/details/128229374?spm=1001.2014.3001.5502
3.4 安装包上传
上传安装包
/opt/flink
3.5 修改配置文件
conf/flink-conf.yaml 程序参数配置
jobmanager.rpc.address: CentOSA
taskmanager.numberOfTaskSlots: 4
conf/master 配置 JobManager 地址
CentOSA:8081
conf/workers 配置 TaskManager 机器地址
CentOSB
CentOSC
CentOSD
3.6 配置文件分发
安装包和配置文件整体分发到其余节点
3.7集群启停
./start-cluster.sh
./stop-cluster.sh
4.Flink standalone集群模式使用
启动的进程名称 StandaloneSessionClusterEntrypoint(JobManager)
4.1 应用提交
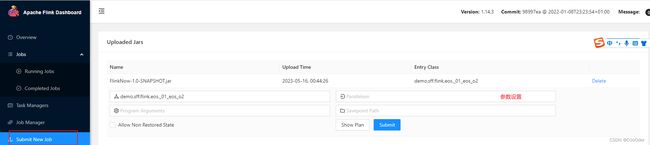
1.页面提交
4.2.命令提交
# 提交 standalone 模式的 job
# -c 主类名
# -p 并行度
# -s 从指定 savepoint 恢复
bin/flink run -t remote \
-c cn.doitedu.flink.java.demos._28_ToleranceSideToSideTest \
-p 5 \
-s hdfs://doit01:8020/eos_savepoint1/savepoint-5f1bc3-dde7a8627fff \
/root/flink_course-1.0.jar
# 触发 standalone 模式 job 做 savepoint
# -d : detach 模式,客户端提交完 job 即退出
# -t remote : 表示 job 是 standalone 运行模式
./flink savepoint -t remote 175ea838a9531c4fcdefdd42368c5eb7 hdfs://node1:8020/eos_savepoint1
注:访问hdfs 需要在lib下面添加
flink-shaded-hadoop-3-uber-3.1.1.7.2.1.0-327-9.0.jar
commons-cli-1.4.jar
下载地址:
https://repository.cloudera.com/artifactory/cloudera-repos/org/apache/flink/flink-shaded-hadoop-3-uber/3.1.1.7.2.1.0-327-9.0/
https://repo1.maven.org/maven2/commons-cli/commons-cli/1.3/
4.3 弊端
- taskmanager 数量固定,无法弹性扩容
- 集群的资源隔离不够,所有的job 是共享资源
- 所有的job 使用一个jobmanager 负载较大
5.Flink on yarn 集群模式(使用最多)
5.1 基础概念
使用 yarn 分配的容器来运行 JobManager和 TaskManager
运行模式
- Application Mode:每个job 都独享集群 ,job 退出,集群也退出; main 是在集群端 (最佳:生产中建议使用)
- Per-Job Mode: 每个job 都独享集群 ,job 退出,集群也退出 ;main 是在客户端运行;场景:每次都申请资源,适合大任务,长时间任务,
- Session Mode:多个job 共享jobmanager /taskmanager ,job 退出 ,集群也不退出 ;main 是在客户端运行;**场景:**反复提交,大量小job 的集群
三种模式的区别
- 生命周期和资源隔离
- 用户类main 方法是运行在client 还是在集群端
5.2 Session Mode 模式
TaskManager:在集群中自动扩容,需要多少资源,就申请多少资源
-
jobmanager 叫做 YarnSessionClusterEntrypoint
-
taskmanager 叫做 YarnTaskExecutorRunner
-
客户端叫做 FlinkYarnSessionCli
5.2.1 启动jobmananger 命令
# 查看帮助
bin/yarn-session.sh –help
-at,--applicationType <arg> Set a custom application type for the application on YARN
-D <property=value> use value for given property
-d,--detached If present, runs the job in detached mode ,后台运行
-h,--help Help for the Yarn session CLI.
-id,--applicationId <arg> Attach to running YARN session
-j,--jar <arg> Path to Flink jar file
-jm,--jobManagerMemory <arg> Memory for JobManager Container with optional unit (default: MB)
-m,--jobmanager <arg> Set to yarn-cluster to use YARN execution mode.
-nl,--nodeLabel <arg> Specify YARN node label for the YARN application
-nm,--name <arg> Set a custom name for the application on YARN app 的名称
-q,--query Display available YARN resources (memory, cores)
-qu,--queue <arg> Specify YARN queue. 队列名称
-s,--slots <arg> Number of slots per TaskManager 槽位
-t,--ship <arg> Ship files in the specified directory (t for transfer)
-tm,--taskManagerMemory <arg> Memory per TaskManager Container with optional unit (default: MB)
-yd,--yarndetached If present, runs the job in detached mode (deprecated; use non-YARN specific option instead)
-z,--zookeeperNamespace <arg> Namespace to create the Zookeeper sub-paths for high availability mode
#停止任务 yarn命令
yarn application -kill application_1550836652097_0002
#启动命令 -jm jobmananger 内存大小 -tm TaskManager内存大小 -s 每个tm 的槽位个数 -m 运行模式
./yarn-session.sh -jm 1024 -tm 1024 -s 2 -m yarn-cluster -nm myflinkdemo -qu default

5.2.2 提交flink job 命令
1.flink 的命令提交
yarn 模式下多指定参数-yid 其余不变
./flink run -yid application_1663767415605_0036 -p 4 -c demo.sff.flink.eos._01_eos_o2 /package/jars/FlinkNow-1.0-SNAPSHOT.jar
2.WebUI 提交
参考standalone模式
5.2 Per-job Mode 模式
jobmanager 个 taskmanager 会一起向yarn 申请
每个flink job 独自一个JobManager
提交命令
./flink run -m yarn-cluster -yjm 1024 -ynm flinkdemo2 -yqu default -ys 2 -ytm 1024 -p 4 -c demo.sff.flink.eos._01_eos_o2 /package/jars/FlinkNow-1.0-SNAPSHOT.jar

5.3 Application Mode 模式
启动命令
./flink run-application -t yarn-application -yjm 1024 -ynm sea -yqu default -ys 2 -ytm 1024 -p 4 -c demo.sff.flink.eos._01_eos_o2 /package/jars/FlinkNow-1.0-SNAPSHOT.jar
## 注:虚拟机内存设置过小这里会报错
和Per-job唯一不同,Application 的main方法是服务端运行;