Flink 学习十 FlinkSQL
Flink 学习十 Flink SQL
1. FlinkSQL 基础概念
flink sql 基于flink core ,使用sql 语义方便快捷的进行结构化数据处理的上层库; 类似理解sparksql 和sparkcore , hive和mapreduce
1.1 工作流程
整体架构和工作流程
-
数据流,绑定元数据 schema ,注册成catalog 中的表 table / view
-
用户使用table Api / table sql 来表达计算逻辑
-
table-planner利用 apache calcite 进行 sql 语法解析,绑定元数据得到逻辑执行计划
-
再由Optimizer 进行优化,得到物理执行计划
-
物理计划经过代码生成器生成代码.得到transformation tree
-
transformation tree 转化成jobGraph 提交到flink 集群运行
1.2 catalog
目录提供元数据,例如数据库、表、分区、视图以及访问存储在数据库或其他外部系统中的数据所需的功能和信息。
数据处理最重要的方面之一是管理元数据。它可能是临时元数据,如临时表,或针对表环境注册的 UDF。或永久元数据,如 Hive Metastore 中的元数据。目录提供了一个统一的 API,用于管理元数据并使其可从表 API 和 SQL 查询访问。
Catalog 使用户能够引用其数据系统中现有的元数据,并自动将它们映射到 Flink 对应的元数据。例如,Flink 可以自动将 JDBC 表映射到 Flink 表,用户无需在 Flink 中手动重写 DDL。Catalog大大简化了用户现有系统上手Flink的步骤,大大提升了用户体验;
1.3 逻辑执行计划
apache calcite 进行 sql 语法解析获取到的语法树
然后再根据查询优化对数裁剪
Flinksql 中有两个优化器
-
RBO(基于规则的优化器)遍历一系列规则(RelOptRule),只要满足条件就对原来的计划节点(表达式)进行转换或调整位置,生成最终的执行计划(分区裁剪(Partition Prune)、列裁剪,谓词下推(Predicate Pushdown)、投影下推(Projection Pushdown)、聚合下推、limit 下推、sort 下推,常量折叠(
Constant Folding),子查询内联转 join 等)
-
CBO(基于代价(成本)的优化器):会保留原有表达式,基于统计信息和代价模型,尝试探索生成等价关系表达式,最终取代价最小的执行计划,比如 根据代价 cost 选择批处理 join 有方式(sortmergejoin,hashjoin,boradcasthashjoin)。
1.4 动态表特性
和Spark 和hive等组件中的表最大不同之处,flinkSQL中的表示动态表,动态指的是动态的结果输出,结果是流式,动态,持续的
- 数据源的输入是持续的
- 查询过程是持续的
- 结果输出也是持续的
动态:不仅仅是数据追加,也有对数据输出的结果的 撤回(删除),更新;
| 传统SQL | 流处理 |
|---|---|
| 关系(或表)是有界的(多)元组集。 | 流是元组的无限序列。 |
| 对批处理数据(例如,关系数据库中的表)执行的查询可以访问完整的输入数据。 | 流式查询在启动时无法访问所有数据,必须“等待”数据流入。 |
| 批量查询在生成固定大小的结果后终止。 | 流式查询根据收到的记录不断更新其结果,并且永远不会完成。 |

-
流被转换为动态表。
-
对动态表进行连续查询评估,生成一个新的动态表。
-
生成的动态表被转换回流。
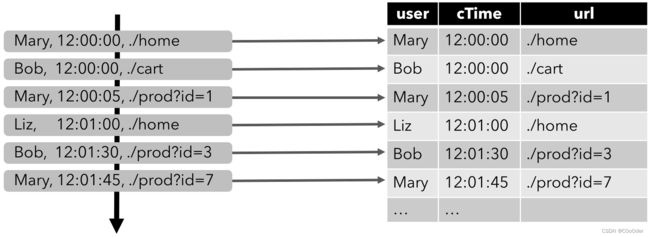
1.5 动态表示例
点击事件流来解释动态表和连续查询的概念
CREATE TABLE clicks (
user VARCHAR, -- the name of the user
url VARCHAR, -- the URL that was accessed by the user
cTime TIMESTAMP(3) -- the time when the URL was accessed
) WITH (...);
1.5.1 连续查询
连续查询在动态表上进行评估,并生成一个新的动态表作为结果。与批查询相反,连续查询永远不会终止并根据其输入表的更新更新其结果表。在任何时间点,连续查询在语义上等同于在输入表的快照上以批处理模式执行的相同查询的结果。
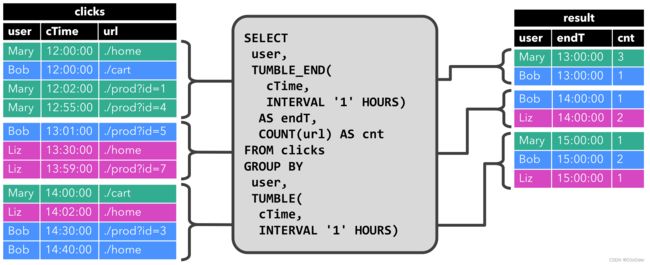
第一个查询是一个简单的GROUP-BY COUNT聚合查询。它clicks根据字段对user表格进行分组,并计算访问的 URL 的数量

第二个查询与第一个查询类似,但在计算 URL 数量之前clicks,除了属性之外,还在每小时滚动窗口user上对表进行分组(稍后讨论基于时间的计算,例如窗口是基于特殊 :时间窗口)
1.6 表到流转换
动态表可以像常规数据库表一样通过INSERT、UPDATE、DELETE 和不断修改。
Flink 的 Table API 和 SQL 支持三种方式来编码动态表的变化:
- Append-only stream : 追加流可以通过发出插入的行将仅由更改修改的动态表
INSERT转换为流 - Retract stream: 回撤流 撤回流是具有两种类型消息的流,添加消息和撤回消息

1.mary + , 2. bob + 3. mary 先delete在 insert 4. liz + 5.bob delete 后在insert
- Upsert stream : 两种消息的流,upsert messages和delete messages。转换为更新插入流的动态表需要一个(可能是复合的)唯一键。具有唯一键的动态表通过编码转换为流
INSERT,并UPDATE更改为更新插入消息和DELETE更改为删除消息。流消费操作员需要知道唯一的键属性才能正确应用消息。与 retract 流的主要区别在于UPDATE更改是用单个消息编码的,因此效率更高

2. FlinkSQL 编程
2.1 使用模板
2.1.1 添加依赖
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-table-api-java-bridge_2.12artifactId>
<version>${flink.version}version>
dependency>
2.1.2 Flinksql编程模板
- 创建 flinksql 编程入口
- 将数据源定义(映射)成表(视图)
- 执行 sql 语义的查询(sql 语法或者 tableapi)
- 将查询结果输出到目标表
2.1.3 Table Environment
flink sql 的编程入口
TableEnvironment 主要的功能是
-
注册 catalogs // hive //kafka //mysql 数据的来源种类
-
向 catalog 注册表 //
-
加载可插拔模块(目前有 hive module,以用于扩展支持 hive 的语法、函数等)
-
执行 sql 查询(sql 解析,查询计划生成,job 提交)
-
注册用户自定义函数
-
提供 datastream 和 table 之间的互转
创建方式
方式1
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.inStreamingMode()
//.inBatchMode()
.build();
TableEnvironment tEnv = TableEnvironment.create(settings);
方式2
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
2.2 Table SQL
kafka fink table 的创建
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/table/kafka/
‘format’ = ‘csv’ 格式个参考文档
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/table/formats/overview/
public class _01_flinksql {
public static void main(String[] args) throws Exception {
// 获取环境
EnvironmentSettings environmentSettings = EnvironmentSettings.inStreamingMode();
TableEnvironment tableEnv = TableEnvironment. create(environmentSettings);
String createSQL = "CREATE TABLE t_kafka (\n" +
" id BIGINT,\n" +
" age BIGINT,\n" +
" name STRING,\n" +
" gender STRING \n" +
") WITH (\n" + //创建的表的各种参数
" 'connector' = 'kafka',\n" +
" 'topic' = 'flinksql_test1',\n" +
" 'properties.bootstrap.servers' = 'CentOSA:9092,CentOSB:9092,CentOSC:9092',\n" +
" 'properties.group.id' = 'testGroup',\n" +
" 'format' = 'csv',\n" + //添加flink-csv 依赖如果是json 还需要添加flink-json 的依赖
" 'scan.startup.mode' = 'earliest-offset', \n" + //读取策略
" 'csv.ignore-parse-errors' = 'false',\n" + //解析错误是否忽略
" 'csv.allow-comments' = 'true'\n" + //是否允许注释
")";
tableEnv.executeSql(createSQL);
TableResult tableResult = tableEnv.executeSql(" select gender ,avg(age) from t_kafka group by gender ");
tableResult.print();
}
}
2.3 Table API
public class _02_flinksql_tableapi {
public static void main(String[] args) throws Exception {
// 获取环境
EnvironmentSettings environmentSettings = EnvironmentSettings.inStreamingMode();
TableEnvironment tableEnv = TableEnvironment. create(environmentSettings);
TableDescriptor build = TableDescriptor.forConnector("kafka").schema(Schema.newBuilder()
.column("id", DataTypes.INT())
.column("age", DataTypes.INT())
.column("name", DataTypes.STRING())
.column("gender", DataTypes.STRING())
.build())
.format("csv")
.option("topic", "flinksql_test1")
.option("properties.bootstrap.servers", "CentOSA:9092,CentOSB:9092,CentOSC:9092")
.option("properties.group.id", "testGroup")
.option("scan.startup.mode", "earliest-offset")
.option("csv.ignore-parse-errors", "false")
.option("csv.allow-comments", "true")
.build();
Table table = tableEnv.from(build);
//table.execute().print(); //输出表数据
//按照 gender 聚合 age的平均值
Table select = table
.groupBy($("gender"))
.select($("age").avg());
//输出数据
select.execute().print();
}
}
2.4 Table SQL && Table API
public class _03_flinksql_sqlapi_muti {
public static void main(String[] args) throws Exception {
// 获取环境
EnvironmentSettings environmentSettings = EnvironmentSettings.inStreamingMode();
TableEnvironment tableEnv = TableEnvironment. create(environmentSettings);
//table sql
String createSQL = "CREATE TABLE t_kafka (\n" +
" id BIGINT,\n" +
" age BIGINT,\n" +
" name STRING,\n" +
" gender STRING \n" +
") WITH (\n" + //创建的表的各种参数
" 'connector' = 'kafka',\n" +
" 'topic' = 'flinksql_test1',\n" +
" 'properties.bootstrap.servers' = 'CentOSA:9092,CentOSB:9092,CentOSC:9092',\n" +
" 'properties.group.id' = 'testGroup',\n" +
" 'format' = 'csv',\n" + //添加flink-csv 依赖如果是json 还需要添加flink-json 的依赖
" 'scan.startup.mode' = 'earliest-offset', \n" + //读取策略
" 'csv.ignore-parse-errors' = 'false',\n" + //解析错误是否忽略
" 'csv.allow-comments' = 'true'\n" + //是否允许注释
")";
tableEnv.executeSql(createSQL);
//前面sql 里面创建的表
Table table = tableEnv.from("t_kafka");
//table api
//按照 gender 聚合 age的平均值
Table select = table
.groupBy($("gender"))
.select($("age").avg());
select.execute().print();
}
}
2.5 其他方式
Table SQL , Table API , Flink core 都是可以混用的;
//编程环境的创建和转换
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
3. Flink 表
3.1 表的结构
-
catalog name (常用于标识不同的“源”,比如 hive catalog,inner catalog 等)
-
database name(通常语义中的“库”)
-
table name(通常语义中的“表”)
TableEnvironment tEnv = ...;
tEnv.useCatalog("a_catalog");
tEnv.useDatabase("db1");
Table table = ...;
// 注册在默认 catalog 的默认 database 中
tableEnv.createTemporaryView("a_view", table);
// 注册在默认 catalog 的指定 database 中
tableEnv.createTemporaryView("db2.a_view", table);
// 注册在指定 catalog 的指定 database 中
tableEnv.createTemporaryView("x_catalog.db3.a_view",
3.2 表和视图
Flinksq中的表,可以是virtual的(view视图)和regular的(table常规表)
- table 描述了一个物理上的外部数据源,如文件、数据库表、kafka 消息 topic
- view 则基于表创建,代表一个或多个表上的一段计算逻辑(一段查询计划的逻辑封装)
注:不管是 table 还是 view,在 tableAPI 中得到的都是 Table 对象
3.3 临时与永久
- 临时表:创建时带 temporary 关键字(crate temporary view,createtemporary table)
- 永久表:创建时不带 temporary 关键字 (create view ,create table )
// sql 定义方式
tableEnv.executeSql("create view view_1 as select .. from projectedTable")
tableEnv.executeSql("create temporary view view_2 as select .. from projectedTable")
tableEnv.executeSql("create table (id int,...) with ( 'connector'= ...)")
tableEnv.executeSql("create temporary table (id int,...) with ( 'connector'= ...)")
// tableapi 方式
tenv.createTable("t_1",tableDescriptor);
tenv.createTemporaryTable("t_1",tableDescriptor);
tenv.createTemporaryView("v_1",dataStream,schema);
tenv.createTemporaryView("v_1",table);
区别:
- 临时表/视图
表 schema 只维护在所属 flink session 运行时内存中;当所属的 flink session 结束后表信息将不复存在;且该表无法在 flink session 间共享;(任务重启后丢失)
- 常规(永久)表/视图
表 schema 可记录在外部持久化的元数据管理器中(比如 hive 的 metastore);当所属 flink session 结束后,该表信息不会丢失;且在不同 flink session 中都可访问到该表的信息
3.4 Table API 使用
Table 对象 创建方式
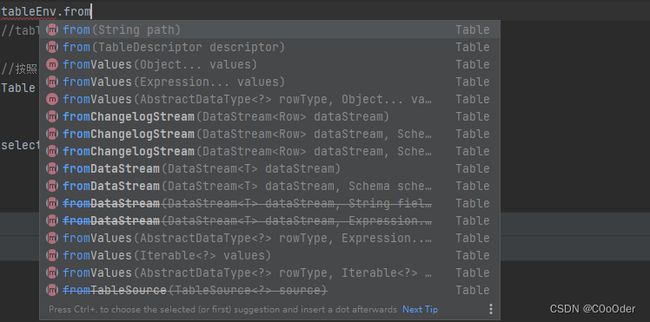
- 从之前已创建的表(已存在的表)
- 从 TableDescriptor(指定参数 连接器/format/schema/options)
- 从 DataStream
- 从 Table 对象上的查询 api 生成
- 从测试数据
3.4.1从之前已创建的表(已存在的表)
//1.获取之前创建的表(已存在的表)
Table table = tableEnv.from("t_kafka");
//4.从 Table 对象上的查询 api 生成
Table select = table
.groupBy($("gender"))
.select($("age").avg());
//5. 从测试数据
3.4.2 从 TableDescriptor
(指定参数 连接器/format/schema/options)
//2.根据表的定义创建表
TableDescriptor build = TableDescriptor.forConnector("kafka").schema(Schema.newBuilder()
.column("id", DataTypes.INT())
.column("age", DataTypes.INT())
.column("name", DataTypes.STRING())
.column("gender", DataTypes.STRING())
.build())
.format("csv")
.option("topic", "flinksql_test1")
.option("properties.bootstrap.servers", "CentOSA:9092,CentOSB:9092,CentOSC:9092")
.option("properties.group.id", "testGroup")
.option("scan.startup.mode", "earliest-offset")
.option("csv.ignore-parse-errors", "false")
.option("csv.allow-comments", "true")
.build();
Table table = tableEnv.from(build);
3.4.3 从 DataStream
//方式3:从 DataStream
// 设置kafka的参数
KafkaSource<String> kafkaSource = KafkaSource.<String>builder()
.setBootstrapServers("CentOSA:9092,CentOSB:9092,CentOSC:9092")
.setTopics("eos")
.setGroupId("eosgroup")
.setValueOnlyDeserializer(new SimpleStringSchema())
//kafkaSource 的做状态 checkpoint 时,默认会向__consumer_offsets 提交一下状态中记录的偏移量
// 但是,flink 的容错并不优选依赖__consumer_offsets 中的记录,所以可以关闭该默认机制
.setProperty("commit.offsets.on.checkpoint","false")
.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"false")
// kafkaSource 启动时,获取起始位移的策略设置,如果是 committedOffsets ,则是从之前所记录的偏移量开始
// 如果没有可用的之前记录的偏移量, 则用策略 OffsetResetStrategy.LATEST 来决定
.setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.LATEST))
.build();
DataStreamSource<String> dataStreamSource = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(),
"kafka-source");
//这种不指定schema 格式是默认的会有问题,需要定义schema数据 下面转换成对象就可以
//Table table1 = tableEnv.fromDataStream(map);
DataStream<Person> map = dataStreamSource.map(x -> JSONObject.parseObject(x, Person.class));
//这种不指定schema 格式是默认的会有问题,需要定义schema数据
Table table1 = tableEnv.fromDataStream(map);
//指定schema
// Table table2 = tableEnv.fromDataStream(map, Schema.newBuilder()
// .column("id", DataTypes.INT())
// .column("age", DataTypes.INT())
// .column("name", DataTypes.STRING())
// .column("gender", DataTypes.STRING())
// .build());
3.4.5 从 Table 对象上的查询 api 生成
//4.从 Table 对象上的查询 api 生成
//按照 gender 聚合 age的平均值
Table select = table
.groupBy($("gender"))
.select($("age").avg());
3.5.5 从测试数据
//5.测试数据
Table table2 = tableEnv.fromValues(Row.of(1,"a","shanghai"),Row.of(21,"b","beijin"));
//三个字段 f0 f1 f2
3.6 Table SQL 使用
Table SQL创建表又如下使用反式

-
从已存在的 datastream 注册
-
从已存在的 Table 对象注册
-
从 TableDescriptor(连接器)注册
-
执行 Sql 的 DDL 语句来注册
3.6.1 从已存在的 datastream 注册
DataBean bean1 = new DataBean(1, "s1", "e1", "pg1", 1000);
DataBean bean2 = new DataBean(1, "s1", "e1", "pg1", 1000);
DataStreamSource<DataBean> dataStream1 = env.fromElements(bean1,bean2);
// 1.自动推断 schema
tenv.createTemporaryView("t1",dataStream1);
// 2.也可以手动指定 schema Schema schema = Schema.Builder.column...build();
tenv.createTemporaryView("t1",dataStream1,schema);
tenv.executeSql("desc t1");
tenv.executeSql("select * from t1");
3.6.2 从已存在的 Table 对象注册
tableEnv.createTemporaryView("view_1",tableEnv.from("t_kafka"));
3.6.3 从TableDescriptor 注册
tenv.createTable("t1", TableDescriptor.forConnector("filesystem")
.option("path", "file:///d:/a.txt")
.format("csv")
.schema(Schema.newBuilder()
.column("guid",DataTypes.STRING())
.column("name",DataTypes.STRING())
.column("age",DataTypes.STRING())
.build())
.build());
3.6.4 执行 Sql 的 DDL 语句来注册
String createSQL = "CREATE TABLE t_kafka (\n" +
" id BIGINT,\n" +
" age BIGINT,\n" +
" name STRING,\n" +
" gender STRING \n" +
") WITH (\n" + //创建的表的各种参数
" 'connector' = 'kafka',\n" +
" 'topic' = 'flinksql_test1',\n" +
" 'properties.bootstrap.servers' = 'CentOSA:9092,CentOSB:9092,CentOSC:9092',\n" +
" 'properties.group.id' = 'testGroup',\n" +
" 'format' = 'csv',\n" + //添加flink-csv 依赖如果是json 还需要添加flink-json 的依赖
" 'scan.startup.mode' = 'earliest-offset', \n" + //读取策略
" 'csv.ignore-parse-errors' = 'false',\n" + //解析错误是否忽略
" 'csv.allow-comments' = 'true'\n" + //是否允许注释
")";
tableEnv.executeSql(createSQL);
tableEnv.executeSql(" select * from t_kafka");
//格式
tableEnv.executeSql(" CREATE TABLE t_kafka (...) with (... )");
tableEnv.executeSql(" CREATE temporary table t_kafka (...) with (... )");
tableEnv.executeSql(" CREATE temporary view t_kafka (...) with (... )");
tableEnv.executeSql(" CREATE temporary view as select ... from ... ");
4. Catalog
4.1 基础概念
catalog就是一个元数据空间,简单说就是记录、获取元数据(表定义信息)的实体
StreamTableEnvironment 的实现类StreamTableEnvironmentImpl 持有对象 CatalogManager
CatalogManager中持有对象 private final Map
@Internal
public class TableEnvironmentImpl implements TableEnvironmentInternal {
.....
private final CatalogManager catalogManager;
....
}
public final class CatalogManager {
...
// A map between names and catalogs.
private final Map<String, Catalog> catalogs;
...
}
Catalog
AbstractCatalog (org.apache.flink.table.catalog)
AbstractJdbcCatalog (org.apache.flink.connector.jdbc.catalog)
JdbcCatalog (org.apache.flink.connector.jdbc.catalog)
PostgresCatalog (org.apache.flink.connector.jdbc.catalog)
GenericInMemoryCatalog (org.apache.flink.table.catalog)
HiveCatalog (org.apache.flink.table.catalog.hive)
4.2 默认catalog
默认的catalog 和database
public class _06_flinksql_catalog {
public static void main(String[] args) throws Exception {
// 获取环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//方式2:从 TableDescriptor
String createSQL = "CREATE TABLE t_kafka (\n" +
" id BIGINT,\n" +
" age BIGINT,\n" +
" name STRING,\n" +
" gender STRING \n" +
") WITH (\n" + //创建的表的各种参数
" 'connector' = 'kafka',\n" +
" 'topic' = 'flinksql_test1',\n" +
" 'properties.bootstrap.servers' = 'CentOSA:9092,CentOSB:9092,CentOSC:9092',\n" +
" 'properties.group.id' = 'testGroup',\n" +
" 'format' = 'csv',\n" + //添加flink-csv 依赖如果是json 还需要添加flink-json 的依赖
" 'scan.startup.mode' = 'earliest-offset', \n" + //读取策略
" 'csv.ignore-parse-errors' = 'false',\n" + //解析错误是否忽略
" 'csv.allow-comments' = 'true'\n" + //是否允许注释
")";
tableEnv.executeSql(createSQL);
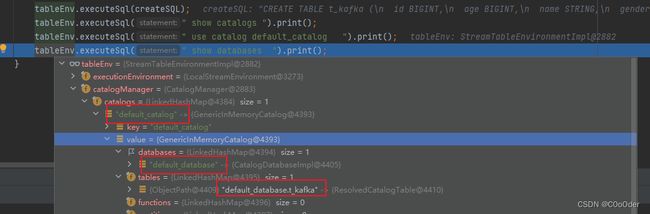
tableEnv.executeSql(" show catalogs ").print();
tableEnv.executeSql(" use catalog default_catalog ").print();
tableEnv.executeSql(" show databases ").print();
}
}
+-----------------+
| catalog name |
+-----------------+
| default_catalog | // default_catalog
+-----------------+
1 row in set
+--------+
| result |
+--------+
| OK |
+--------+
1 row in set
+------------------+
| database name |
+------------------+
| default_database | // default_database
+------------------+
4.3 使用hive catalog
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/table/hive/overview/
添加依赖
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-sql-connector-hive-3.1.2_2.11artifactId>
<version>${flink.version}version>
dependency>
添加配置文件
<configuration>
<property>
<name>hive.metastore.urisname>
<value>thrift://node1:9083value>
property>
configuration>
代码示例
public class _06_flinksql_hive_catalog {
public static void main(String[] args) throws Exception {
// 获取环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 创建了一个 hive 元数据空间的实现对象
HiveCatalog hiveCatalog = new HiveCatalog("hive", "default", "D:\\Resource\\FrameMiddleware\\FlinkNew\\hive-conf");
// 将 hive 元数据空间对象注册到 环境中
tableEnv.registerCatalog("mycatalog",hiveCatalog);
tableEnv.executeSql(" select * from `mycatalog`.`default`.`sqooptest_mysql_tohive` ").print();
tableEnv.executeSql(" create table `mycatalog`.`default`.`testtable2` ").print();
tableEnv.executeSql(" create view `mycatalog`.`default`.`flinkview` as select * from `mycatalog`.`default`.`sqooptest_mysql_tohive` ").print();
}
}
//
+-------------------------+
| tab_name |
+-------------------------+
| bigtable |
| dept_partition |
| dept_partition_1 |
| flinkview | 已添加
| jointable |
| partition_dynamic_test |
| smalltable |
| sqooptest_mysql_tohive |
| testtable1 |
| testtable2 |
| testtable4 |
| testview3 |
+-------------------------+
//--
+----------------------------------------------------+
| createtab_stmt |
+----------------------------------------------------+
| CREATE VIEW `flinkview` AS SELECT * |
| FROM `mycatalog`.`default`.`sqooptest_mysql_tohive` |
+----------------------------------------------------+
4.4 临时表&永久表
如果选择使用hive 元数据空间 (HiveCatalog)来创建表视图
- 永久表/ 视图 的元信息,都会被hive 的元数据服务保存,实现持久化存储
- 临时表/ 视图,不会被hive 元数据服务保存而是放在 catalogManager 的一个 temporaryTables 的内存 hashmap 中记录
- 临时表空间中的表名(全名)如果与 hive 空间中的表名相同,则查询时会优先选择临时表空间的表
如果使用 GenericInMemoryCatalog
-
永久表(视图)的元信息,都会被写入 GenericInMemoryCatalog 的元数据管理器中(内存中)
-
临时表(视图)的元信息,放在 catalogManager 的一个 temporaryTables 的内存 hashmap 中记录
-
无论永久还是临时,当 flink 的运行 session 结束后,所创建的表(永久、临时)都将不复存在
4.5 HiveCatalog/ Catalog
flink的Catalog 持久化能力依赖于hive 的元数据服务 metastore;
在hive中虽然可以看到这些表,但是hive是无法使用的,并不能使用spark 或者mr 来查询数据或运算数据
5. 表Schema 详解
5.1 字段定义
5.1.1 物理字段 physical column
物理字段:源自于“外部存储”系统本身 schema 中的字段
示例: kafka 中的 key ,value (数据作为JSON存储),MySQL中的字段,hive 表中的字段
5.1.2 逻辑字段computed column
在物理字段上施加一个 sql 表达式,并将表达式结果定义为一个字段;
基于物理字段的表达式
Schema.newBuilder()
// 声明表达式字段 age_exp, 它来源于物理字段 age+10
.columnByExpression("age_exp", "age+10")
CREATE TABLE MyTable (
`user_id` BIGINT,
`price` DOUBLE,
`quantity` DOUBLE,
`cost` AS price * quantity, -- cost 来源于: price*quantity
) WITH (
'connector' = 'kafka'
... );
5.1.3 metadata column
元数据字段:来源于 connector 从外部存储系统中获取到的“外部系统元信息”
比如,kafka 的消息,通常意义上的数据内容是在 record 的 key 和 value 中的,而实质上(底层角度来看),kafka 中的每一条 record,不光带了 key 和 value 数据内容,还带了这条 record 所属的 topic,所属的 partition,所在的 offset,以及 record 的 timetamp 和 timestamp 类型等“元信息”
Kafka 的元数据字段
| Key | Data Type | Description | R/W |
|---|---|---|---|
topic |
STRING NOT NULL |
Topic name of the Kafka record. | R |
partition |
INT NOT NULL |
Partition ID of the Kafka record. | R |
headers |
MAP NOT NULL |
Headers of the Kafka record as a map of raw bytes. | R/W |
leader-epoch |
INT NULL |
Leader epoch of the Kafka record if available. | R |
offset |
BIGINT NOT NULL |
Offset of the Kafka record in the partition. | R |
timestamp |
TIMESTAMP_LTZ(3) NOT NULL |
Timestamp of the Kafka record. | R/W |
timestamp-type |
STRING NOT NULL |
Timestamp type of the Kafka record. Either “NoTimestampType”, “CreateTime” (also set when writing metadata), or “LogAppendTime”. | R |
5.1.4 主键约束
//很多connector不支持 ,kafka upsert 支持
- 单字段主键约束语法:
id INT PRIMARY KEY NOT ENFORCED,
name STRING
- 多字段主键约束语法:
id int ,
name STRING,
PRIMARY KEY(id,name) NOT ENFORCED
5.1.5 示例写法
写法一 flink table sql
public class _08_flinksql_column {
public static void main(String[] args) throws Exception {
// 获取环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//方式2:从 TableDescriptor
String createSQL = "CREATE TABLE t_kafka (\n" +
" id BIGINT ,\n" + //physical column
//" id BIGINT PRIMARY KEY NOT ENFORCED,\n" +
" age BIGINT,\n" + //physical column
" min_age as age-1 ,\n" + //computed column
" name STRING,\n" + //physical column
" gender STRING, \n" + //physical column
" kafka_offset bigint metadata from 'offset', \n" + //metadata column
" kafka_timestamp TIMESTAMP_LTZ(3) metadata from 'timestamp' \n" + //metadata column
//" , PRIMARY KEY (id ,name ) NOT ENFORCED \n" +
") WITH (\n" + //创建的表的各种参数
" 'connector' = 'kafka',\n" +
" 'topic' = 'flinksql_test1',\n" +
" 'properties.bootstrap.servers' = 'CentOSA:9092,CentOSB:9092,CentOSC:9092',\n" +
" 'properties.group.id' = 'testGroup',\n" +
" 'format' = 'csv',\n" + //添加flink-csv 依赖如果是json 还需要添加flink-json 的依赖
" 'scan.startup.mode' = 'earliest-offset', \n" + //读取策略
" 'csv.ignore-parse-errors' = 'false',\n" + //解析错误是否忽略
" 'csv.allow-comments' = 'true'\n" + //是否允许注释
")";
tableEnv.executeSql(createSQL);
tableEnv.executeSql(" desc t_kafka ").print();
tableEnv.executeSql(" select * from t_kafka ").print();
}
}
// desc t_kafka
+-----------------+------------------+------+-----+---------------------------+-----------+
| name | type | null | key | extras | watermark |
+-----------------+------------------+------+-----+---------------------------+-----------+
| id | BIGINT | true | | | |
| age | BIGINT | true | | | |
| min_age | BIGINT | true | | AS `age` - 1 | |
| name | STRING | true | | | |
| gender | STRING | true | | | |
| kafka_offset | BIGINT | true | | METADATA FROM 'offset' | |
| kafka_timestamp | TIMESTAMP_LTZ(3) | true | | METADATA FROM 'timestamp' | |
+-----------------+------------------+------+-----+---------------------------+-----------+
//select * from t_kafka
+----+----------------------+----------------------+----------------------+--------------------------------+--------------------------------+----------------------+-------------------------+
| op | id | age | min_age | name | gender | kafka_offset | kafka_timestamp |
+----+----------------------+----------------------+----------------------+--------------------------------+--------------------------------+----------------------+-------------------------+
| +I | 1 | 5 | 4 | sff | male | 0 | 2023-05-22 21:42:06.547 |
| +I | 1 | 10 | 9 | sff | male | 1 | 2023-05-22 21:42:17.703 |
| +I | 1 | 10 | 9 | sff2 | male | 2 | 2023-05-22 21:42:29.272 |
| +I | 1 | 10 | 9 | sff2 | female | 3 | 2023-05-22 21:42:38.014 |
| +I | 1 | 20 | 19 | sff2 | female | 4 | 2023-05-22 21:42:43.740 |
| +I | 1 | 2 | 1 | 3 | 4 | 5 | 2023-05-24 22:57:25.991 |
| +I | 1 | 20 | 19 | sff | male | 6 | 2023-05-24 22:58:11.530 |
| +I | 1 | 20 | 19 | sff | malefa | 7 | 2023-05-24 22:59:39.722 |
写法二 flink table api
public class _09_flinksql_column {
public static void main(String[] args) throws Exception {
// 获取环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//方式2:从 TableDescriptor
tableEnv.createTable("t_kafka",
TableDescriptor.forConnector("kafka")
.schema(Schema.newBuilder()
.column("id", DataTypes.INT()) //physical column
.column("age", DataTypes.BIGINT()) //physical column
.column("name", DataTypes.STRING()) //physical column
.column("gender", DataTypes.STRING()) //physical column
.columnByExpression("min_age","age-1") //computed column
.columnByExpression("guid","id+100") //computed column
//定义字段,字段类型 元数据字段,sink 时是否出现在schema中 (写数据一般不需要写元数据 如offset)
//:注 元数据字段一般定义为 isVirtual=true
.columnByMetadata("kafka_offset",DataTypes.BIGINT(),"offset",true) //metadata column
//metadata column
.columnByMetadata("kafka_timestamp",DataTypes.TIMESTAMP_LTZ(3),"timestamp",true)
//.primaryKey("id") 需要connector 支持
.build())
.option("topic","flinksql_test1")
.format("csv")
.option("properties.bootstrap.servers","CentOSA:9092,CentOSB:9092,CentOSC:9092")
.option("properties.group.id","testGroup")
.option("scan.startup.mode","earliest-offset")
.option("csv.ignore-parse-errors","false")
.option("csv.allow-comments","true")
.build());
tableEnv.executeSql(" desc t_kafka ").print();
tableEnv.executeSql(" select * from t_kafka ").print();
}
}
5.2 format
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/table/formats/overview/
connector连接外部存储时,根据外部数据的格式不同,需要用到不同的format 组件
format 组件的作用就是告诉连接器,如何解析外部存储的数据以及映射到表的schema
注意点:
- 导入 format 组件的 jar 包依赖
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-csvartifactId>
<version>${flink.version}version>
dependency>
- 指定 format 组件的名称
" 'format' = 'csv',\n"
//
.format("csv")
- 设置 format 组件所需的参数(不同 format 组件有不同的参数配置需求)
") WITH (\n" + //创建的表的各种参数
" 'connector' = 'kafka',\n" +
" 'topic' = 'flinksql_test1',\n" +
" 'properties.bootstrap.servers' = 'CentOSA:9092,CentOSB:9092,CentOSC:9092',\n" +
" 'properties.group.id' = 'testGroup',\n" +
" 'format' = 'csv',\n" + //添加flink-csv 依赖如果是json 还需要添加flink-json 的依赖
" 'scan.startup.mode' = 'earliest-offset', \n" + //读取策略
" 'csv.ignore-parse-errors' = 'false',\n" + //解析错误是否忽略
" 'csv.allow-comments' = 'true'\n" + //是否允许注释
")";
目前支持的
| Formats | Supported Connectors |
|---|---|
| CSV | Apache Kafka, Upsert Kafka, Amazon Kinesis Data Streams, Filesystem |
| JSON | Apache Kafka, Upsert Kafka, Amazon Kinesis Data Streams, Filesystem, Elasticsearch |
| Apache Avro | Apache Kafka, Upsert Kafka, Amazon Kinesis Data Streams, Filesystem |
| Confluent Avro | Apache Kafka, Upsert Kafka |
| Debezium CDC | Apache Kafka, Filesystem |
| Canal CDC | Apache Kafka, Filesystem |
| Maxwell CDC | Apache Kafka, Filesystem |
| Apache Parquet | Filesystem |
| Apache ORC | Filesystem |
| Raw | Apache Kafka, Upsert Kafka, Amazon Kinesis Data Streams, Filesystem |
5.2.1 json fromat
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/table/formats/json/
依赖
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-jsonartifactId>
<version>1.15.0version>
dependency>
可选参数
format 组件名: json
json.fail-on-missing-field 缺失字段是否失败
json.ignor-parse-errors 是否忽略 json 解析错误
json.timestamp-format.standard json 中的 timestamp 类型字段的格式
json.map-null-key.mode 可取:FAIL ,DROP, LITERAL
json.map-null-key.literal 替换 null 的字符串
json.encode.decimal-as-plain-number
参数类型映射
看前面链接地址
复杂 json 格式解析1(嵌套对象)
{"id":10,"name":{"nick":"doe","formal":"xxxx"}}
映射成 flinksql 表
Schema schema = Schema.newBuilder()
.column("id", DataTypes.INT())
.column("name", DataTypes.ROW(
DataTypes.FIELD("nick", DataTypes.STRING()),
DataTypes.FIELD("formal", DataTypes.STRING())
)
)
.build();
//sql 方式
create table json_table2(
id int,
name map<string,string>
)
查询
select id,name.nick,name.formal from t
复杂 json 格式解析2(嵌套对象)
{"id":1,"friends":[{"name":"a","info":{"addr":"bj","gender":"male"}},{"name":"b","info":{"addr":"sh","gender":"female"}}]}
Schema schema3 = Schema.newBuilder()
.column("id", DataTypes.INT())
.column("friends", DataTypes.ARRAY(
DataTypes.ROW(
DataTypes.FIELD("name", DataTypes.STRING()),
DataTypes.FIELD("info", DataTypes.ROW(
DataTypes.FIELD("addr", DataTypes.STRING()),
DataTypes.FIELD("gender", DataTypes.STRING())
))
)))
.build();
//sql 方式
create table json_table2(
id int,
friend array<row <name string,info map<string,string>>>
)
查询
select id,friends[1].name,friends[1].info.addr from t1
5.2.2 csv fromat
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/table/formats/csv/
依赖
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-csvartifactId>
<version>1.14.4version>
dependency>
可选参数
format = csv
csv.field-delimiter = ',' csv.disable-quote-character = false
csv.quote-character = ' " ' csv.allow-comments = false
csv.ignore-parse-erros = false 是否忽略解析错误
csv.array-element-delimiter = ' ; ' 数组元素之间的分隔符
csv.escape-character = none 转义字符
csv.null-literal = none null 的字面量字符串
参数类型映射
看前面链接地址
5.3 watermark 和时间介绍
flink sql 定义watermark
{
public static void main(String[] args) throws Exception {
// 获取环境
Configuration configuration = new Configuration();
configuration.setInteger("rest.port", 8822);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(configuration);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//方式2:从 TableDescriptor
String createSQL = "CREATE TABLE t_kafka_wm (\n" +
" id BIGINT ,\n" +
" age BIGINT,\n" + //physical column
" name STRING,\n" +
" gender STRING, \n" +
" eventTime timestamp(3), \n" +
" watermark for eventTime as eventTime - interval '1' second, \n" +
//如果时间类型是long类型
// " eventTime bigint ," +
// " et as to_timestamp_ltz(eventTime,3)," +
// " watermark for et as et - interval '0.1' second "+
//" , PRIMARY KEY (id ,name ) NOT ENFORCED \n" +
//处理时间语义
" pt as proctime() " +
") WITH (\n" + //创建的表的各种参数
" 'connector' = 'kafka',\n" +
" 'topic' = 'flinksql_test_wm',\n" +
" 'properties.bootstrap.servers' = 'CentOSA:9092,CentOSB:9092,CentOSC:9092',\n" +
" 'properties.group.id' = 'testGroup',\n" +
" 'format' = 'csv',\n" + //添加flink-csv 依赖如果是json 还需要添加flink-json 的依赖
" 'scan.startup.mode' = 'earliest-offset', \n" + //读取策略
" 'csv.ignore-parse-errors' = 'false',\n" + //解析错误是否忽略
" 'csv.allow-comments' = 'true'\n" + //是否允许注释
")";
tableEnv.executeSql(createSQL);
tableEnv.executeSql(" desc t_kafka_wm ").print();
CURRENT_WATERMARK 获取watermark
tableEnv.executeSql(" select id,pt,eventTime,CURRENT_WATERMARK(eventTime) from t_kafka_wm ").print();
}
}
+-----------+-----------------------------+-------+-----+---------------+-----------------------------------+
| name | type | null | key | extras | watermark |
+-----------+-----------------------------+-------+-----+---------------+-----------------------------------+
| id | BIGINT | true | | | |
| age | BIGINT | true | | | |
| name | STRING | true | | | |
| gender | STRING | true | | | |
| eventTime | TIMESTAMP(3) *ROWTIME* | true | | | `eventTime` - INTERVAL '1' SECOND |
| pt | TIMESTAMP_LTZ(3) *PROCTIME* | false | | AS PROCTIME() | |
+-----------+-----------------------------+-------+-----+---------------+-----------------------------------+
//
+----+----------------------+-------------------------+-------------------------+-------------------------+
| op | id | pt | eventTime | EXPR$3 |
+----+----------------------+-------------------------+-------------------------+-------------------------+
| +I | 1 | 2023-06-05 23:09:18.985 | 2023-03-01 10:00:01.000 | (NULL) |
| +I | 1 | 2023-06-05 23:09:37.303 | 2023-03-01 10:00:10.000 | 2023-03-01 10:00:09.000 |
| +I | 1 | 2023-06-05 23:09:42.600 | 2023-03-01 10:00:50.000 | 2023-03-01 10:00:09.000 |
flink api 方式
// 转成 table Table table2 = tenv.fromDataStream(ds2, Schema.newBuilder()
// 声明表达式字段,并声明为 processing time 属性字段
.columnByExpression("pt", "proctime()")
// 声明表达式字段(来自 ts)
.columnByExpression("rt", "to_timestamp_ltz(ts,3)")
// 将 rt 字段指定为 event time 属性字段,并基于它指定 watermark 策略: = rt
.watermark("rt", "rt")
// 将 rt 字段指定为 event time 属性字段,并基于它指定 watermark 策略: = rt - 8s
.watermark("rt", "rt - interval '8' second")
.build());
table2.printSchema();
5.4 流与表之间waterMark传递
前提:前面的数据流已经声明了watermark
复用上面代码 , SOURCE_WATERMARK 代表使用底层流的 watermark 策略
// 将 rt 字段指定为 event time 属性字段,并沿用“源头流”的 watermark
.watermark("rt", "SOURCE_WATERMARK()") // 得到与源头 watermark 完全一致
5.5 connector 详解
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/table/overview/
5.5.1 基础概念
-
connector 通常是用于对接外部存储建表(源表或目标表)时的映射器、桥接器
-
connector 本质上是对 flink 的 table source /table sink 算子的封装;
5.5.2 使用步骤
- 导入连接器 jar 包依赖
- 指定连接器类型名
- 指定连接器所需的参数(不同连接器有不同的参数配置需求)
- 获取连接器所提供的元数据
5.5.3 kafka connector 示例
kafka connector
产生的数据以及能接受的数据流是 append-only 流只有 +I 这种 changemode
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/table/kafka/
依赖
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-kafka_2.11artifactId>
<version>1.14.4version>
dependency>
连接类型
CREATE TABLE KafkaTable (
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING,
`ts` TIMESTAMP(3) METADATA FROM 'timestamp' //获取连接器所提供的元数据
) WITH (
'connector' = 'kafka', //连接类型
'topic' = 'user_behavior', //指定连接器所需的参数
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv'
)
参数配置
上面链接中有
5.5.4 upsert kafka connector
作为source 算子
根据所定义的主键,将读取到的数据转换为 +I/-U/+U 记录,如果读到 null,则转换为-D 记录;
-- kafka 数据流
1,sfff,2222
1,ffffs,33333
kafka - connector appendonly 流
+I [1,sfff,2222]
+I [1,ffffs,33333]
upsert-kafka-connector upsert 的 changelog 流
+I [1,sfff,2222]
-U [1,sfff,2222]
+U [11,ffffs,33333]
作为 sink
对于 -U/+U/+I 记录, 都以正常的 append 消息写入 kafka;对于-D 记录,则写入一个 null 到 kafka 来表示 delete 操作;
使用示例1
t_kafka_upsert_1 --> t_kafka_upsert_2
public class _11_flinksql_upsert_kafka_1 {
public static void main(String[] args) throws Exception {
// 获取环境
Configuration configuration = new Configuration();
configuration.setInteger("rest.port", 8822);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//方式2:从 TableDescriptor
String createSQL = "CREATE TABLE t_kafka_upsert_1 (\n" +
" age BIGINT,\n" + //physical column
" gender STRING \n" +
") WITH (\n" + //创建的表的各种参数
" 'connector' = 'kafka',\n" +
" 'topic' = 't_kafka_upsert_1',\n" +
" 'properties.bootstrap.servers' = 'CentOSA:9092,CentOSB:9092,CentOSC:9092',\n" +
" 'properties.group.id' = 'testGroup',\n" +
" 'format' = 'csv',\n" +
" 'scan.startup.mode' = 'earliest-offset', \n" +
" 'csv.ignore-parse-errors' = 'false',\n" +
" 'csv.allow-comments' = 'true'\n" +
")";
//输出表 有主键约束
String createSQL2 = "CREATE TABLE t_kafka_upsert_2 (\n" +
" age BIGINT,\n" +
" gender STRING \n" +
" , PRIMARY KEY (gender ) NOT ENFORCED \n" +
") WITH (\n" +
" 'connector' = 'upsert-kafka',\n" +
" 'topic' = 't_kafka_upsert_2',\n" +
" 'properties.bootstrap.servers' = 'CentOSA:9092,CentOSB:9092,CentOSC:9092',\n" +
" 'properties.group.id' = 'testGroup',\n" +
" 'key.format' = 'csv',\n" +
" 'value.format' = 'csv' \n" +
")";
tableEnv.executeSql(createSQL);
tableEnv.executeSql(createSQL2);
tableEnv.executeSql("insert into t_kafka_upsert_2 " +
"select max(age),gender from t_kafka_upsert_1 group by gender ");
tableEnv.executeSql(" select * from t_kafka_upsert_2 ").print();
}
}
//t_kafka_upsert_1 数据
1,男 //插入 +I
5,男 //更新 2步骤 -U +U
3,女 //插入 +I
5,女 //更新 2步骤 -U +U
1,女 //计算后不需要插入
10,女 //更新 2步骤 -U +U
10,男 //更新 2步骤 -U +U
//写入t_kafka_upsert_2 数据
1,男
5,男
3,女
5,女
10,女
10,男
//表输出结果
+----+----------------------+--------------------------------+
| op | age | gender |
+----+----------------------+--------------------------------+
| +I | 1 | 男 |
| -U | 1 | 男 |
| +U | 5 | 男 |
| +I | 3 | 女 |
| -U | 3 | 女 |
| +U | 5 | 女 |
| -U | 5 | 女 |
| +U | 10 | 女 |
| -U | 5 | 男 |
| +U | 10 | 男 |
使用示例2
t_kafka_upsert_join1 join t_kafka_upsert_join2 ==> t_kafka_upsert_join3
public class _12_flinksql_upsert_kafka_2 {
public static void main(String[] args) throws Exception {
// 获取环境
Configuration configuration = new Configuration();
configuration.setInteger("rest.port", 8822);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
String createSQL1 = "CREATE TABLE t_kafka_upsert_join1 (\n" +
" id BIGINT,\n" +
" age BIGINT,\n" +
" gender STRING \n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 't_kafka_upsert_join1',\n" +
" 'properties.bootstrap.servers' = 'CentOSA:9092,CentOSB:9092,CentOSC:9092',\n" +
" 'properties.group.id' = 'testGroup',\n" +
" 'format' = 'csv',\n" +
" 'scan.startup.mode' = 'earliest-offset', \n" +
" 'csv.ignore-parse-errors' = 'false',\n" +
" 'csv.allow-comments' = 'true'\n" +
")";
String createSQL2 = "CREATE TABLE t_kafka_upsert_join2 (\n" +
" id BIGINT,\n" + //physical column
" addr STRING \n" +
") WITH (\n" + //创建的表的各种参数
" 'connector' = 'kafka',\n" +
" 'topic' = 't_kafka_upsert_join2',\n" +
" 'properties.bootstrap.servers' = 'CentOSA:9092,CentOSB:9092,CentOSC:9092',\n" +
" 'properties.group.id' = 'testGroup',\n" +
" 'format' = 'csv',\n" +
" 'scan.startup.mode' = 'earliest-offset', \n" +
" 'csv.ignore-parse-errors' = 'false',\n" +
" 'csv.allow-comments' = 'true'\n" +
")";
//输出表 有主键约束
String createSQL3 = "CREATE TABLE t_kafka_upsert_join3 (\n" +
" id BIGINT,\n" + //physical column
" age BIGINT,\n" +
" gender STRING, \n" +
" addr STRING \n" +
" , PRIMARY KEY (id ) NOT ENFORCED \n" +
") WITH (\n" +
" 'connector' = 'upsert-kafka',\n" +
" 'topic' = 't_kafka_upsert_join3',\n" +
" 'properties.bootstrap.servers' = 'CentOSA:9092,CentOSB:9092,CentOSC:9092',\n" +
" 'properties.group.id' = 'testGroup',\n" +
" 'key.format' = 'csv',\n" +
" 'value.format' = 'csv' \n" +
")";
tableEnv.executeSql(createSQL1);
tableEnv.executeSql(createSQL2);
tableEnv.executeSql(createSQL3);
tableEnv.executeSql("insert into t_kafka_upsert_join3 " +
" select t1.id,t1.age,t1.gender,t2.addr from t_kafka_upsert_join1 t1 left join t_kafka_upsert_join2 t2" +
" on t1.id=t2.id ");
tableEnv.executeSql(" select * from t_kafka_upsert_join3 ").print();
}
}
//t_kafka_upsert_join1
1,25,男 // 先输入 +I
//t_kafka_upsert_join2
1,杨浦区五角场 //后输出 -D 删除 +I
+----+----------------------+----------------------+--------------------------------+--------------------------------+
| op | id | age | gender | addr |
+----+----------------------+----------------------+--------------------------------+--------------------------------+
| +I | 1 | 25 | 男 | |
| -D | 1 | 25 | 男 | |
| +I | 1 | 25 | 男 | 杨浦区五角场 |
5.5.5 jdbc connector
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/table/jdbc/
特性
- 可作为 scan source ,底层产生 Bounded Stream有界流 (读取一次)
- 可作为 lookup source,底层是“事件驱动”式查询 CDC连接器
- 可作为 Batch 模式的 sink
- 可作为 Stream 模式下的 append sink 和 upsert sink
添加依赖
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-jdbcartifactId>
<version>1.14.4version>
dependency>
jdbc 驱动根据使用的数据库决定
| Driver | Group Id | Artifact Id | JAR |
|---|---|---|---|
| MySQL | mysql |
mysql-connector-java |
Download |
| PostgreSQL | org.postgresql |
postgresql |
Download |
| Derby | org.apache.derby |
derby |
Download |
**mysql **
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>8.0.21version>
dependency>
示例 Source
scan source模式 ,作用不大,是有界流,相当于是把数据库数据一次性读取出来
public class _13_flinksql_mysql {
public static void main(String[] args) throws Exception {
// 获取环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
String createSQL = " CREATE TABLE t_mysql_connector ( " +
" id INT , " +
" name STRING, " +
" age INT " +
" ) WITH ( " +
" 'connector' = 'jdbc', " +
" 'url' = 'jdbc:mysql://192.168.141.131:3306/flinkdemo' ," +
" 'table-name' = 'person', " +
" 'password' = 'root', " +
" 'username' = 'root' " + //是否允许注释
" ) ";
tableEnv.executeSql(createSQL);
tableEnv.executeSql(" select * from t_mysql_connector ").print();
}
}
+----+-------------+--------------------------------+-------------+
| op | id | name | age |
+----+-------------+--------------------------------+-------------+
| +I | 1 | 66e01789-7cd3-4a74-be04-117... | 88 |
| +I | 2 | 3deebae6-0ecc-4b06-86e0-09c... | 63 |
| +I | 3 | 962157ed-c7b1-465d-928d-d2d... | 11 |
| +I | 4 | 9ad1bba7-985b-4073-9f72-b2a... | 91 |
| +I | 5 | ffdf712b-ad00-4be1-a3ef-f57... | 87 |
| +I | 6 | cd7286fc-714b-49c4-9f77-11a... | 49 |
| +I | 7 | e5bbd565-04ed-4322-9933-c4e... | 15 |
| +I | 8 | 55a3e11e-e262-436e-859e-137... | 20 |
| +I | 9 | 488f78f7-c8ff-4ec8-b659-dae... | 52 |
| +I | 10 | 0ab23a15-f428-4476-9de9-04f... | 56 |
| +I | 11 | 6c9315d3-5f08-460d-9d05-cc1... | 72 |
| +I | 12 | f324d215-fe27-4d6c-a931-d87... | 19 |
| +I | 13 | bd21c9f3-d02f-4f18-9852-784... | 16 |
| +I | 14 | f31b9b18-976f-4449-a321-4d2... | 33 |
+----+-------------+--------------------------------+-------------+
lookup source模式
CDC 后面讲,就是补货数据库数据的改变,无界流数据;
示例 Sink
public class _14_flinksql_mysql_sink {
public static void main(String[] args) throws Exception {
// 获取环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
String createSQL1 = "CREATE TABLE t_kafka_upsert_join1 (\n" +
" id INT,\n" +
" age INT,\n" +
" gender STRING \n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 't_kafka_upsert_join1',\n" +
" 'properties.bootstrap.servers' = 'CentOSA:9092,CentOSB:9092,CentOSC:9092',\n" +
" 'properties.group.id' = 'testGroup',\n" +
" 'format' = 'csv',\n" +
" 'scan.startup.mode' = 'earliest-offset', \n" +
" 'csv.ignore-parse-errors' = 'false',\n" +
" 'csv.allow-comments' = 'true'\n" +
")";
String createSQL2 = "CREATE TABLE t_kafka_upsert_join2 (\n" +
" id INT, \n" + //physical column
" addr STRING \n" +
") WITH (\n" + //创建的表的各种参数
" 'connector' = 'kafka',\n" +
" 'topic' = 't_kafka_upsert_join2',\n" +
" 'properties.bootstrap.servers' = 'CentOSA:9092,CentOSB:9092,CentOSC:9092',\n" +
" 'properties.group.id' = 'testGroup',\n" +
" 'format' = 'csv',\n" +
" 'scan.startup.mode' = 'earliest-offset', \n" +
" 'csv.ignore-parse-errors' = 'false',\n" +
" 'csv.allow-comments' = 'true'\n" +
")";
tableEnv.executeSql(createSQL1);
tableEnv.executeSql(createSQL2);
//输出表 有主键约束
String createSQL = " CREATE TABLE t_mysql_connector2 ( " +
" id INT primary key , " + //需要声明主键
" age INT , " +
" gender STRING, " +
" addr STRING " +
" ) WITH ( " +
" 'connector' = 'jdbc', " +
" 'url' = 'jdbc:mysql://192.168.141.131:3306/flinkdemo' ," +
" 'table-name' = 'person2', " +
" 'password' = 'root', " +
" 'username' = 'root' " + //是否允许注释
" ) ";
tableEnv.executeSql(createSQL);
tableEnv.executeSql("insert into t_mysql_connector2 " +
" select t1.id,t1.age,t1.gender,t2.addr from t_kafka_upsert_join1 t1 left join t_kafka_upsert_join2 t2" +
" on t1.id=t2.id ");
tableEnv.executeSql(" select * from t_mysql_connector2 ").print();
}
}
幂等写出
jdbc connector 可以利用目标数据库的特性,实现幂等写出;幂等写出可以避免在 failover 发生后的可能产生的数据重复;实现幂等写出,本身并不需要对 jdbc connector 做额外的配置,只需要:指定主键字段 ,jdbc connector 就会利用目标数据库的 upsert 语法
示例mysql:INSERT .. ON DUPLICATE KEY UPDATE ..
5.5.6 filesystem connector
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/table/filesystem/
特性
-
可读可写
-
作为 source 表时,支持持续监视读取目录下新文件,且每个新文件只会被读取一次
-
作为 sink 表时,支持 多种文件格式、分区、文件滚动、压缩设置等功能
env.executeSql( "CREATE TABLE fs_table (\n" +
" user_id STRING,\n" +
" order_amount DOUBLE,\n" +
" dt STRING,\n" +
" `hour` STRING\n" +
") PARTITIONED BY (dt, `hour`) WITH (\n" + //字段需要在表定义中已经声明 区别于hive
" 'connector'='filesystem',\n" +
" 'path'='file:///e:/flinkdemo/',\n" +
" 'format'='csv',\n" +
" 'sink.partition-commit.delay'='1 h',\n" +
" 'sink.partition-commit.policy.kind'='success-file',\n" +
" 'sink.rolling-policy.file-size' = '8M',\n" + //滚动策略
" 'sink.rolling-policy.rollover-interval'='30 min',\n" + //时间间隔滚动
" 'sink.rolling-policy.check-interval'='10 second'\n" + //多久检测滚动
")"
)
5.6 完整建表语法
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/table/sql/create/#create-table
CREATE TABLE [IF NOT EXISTS] [catalog_name.][db_name.]table_name
(
{ <physical_column_definition> | <metadata_column_definition> | <computed_column_definition> }[ , ...n]
[ <watermark_definition> ]
[ <table_constraint> ][ , ...n]
)
[COMMENT table_comment]
[PARTITIONED BY (partition_column_name1, partition_column_name2, ...)]
WITH (key1=val1, key2=val2, ...)
[ LIKE source_table [( <like_options> )] ]
<physical_column_definition>:
column_name column_type [ <column_constraint> ] [COMMENT column_comment]
<column_constraint>:
[CONSTRAINT constraint_name] PRIMARY KEY NOT ENFORCED
<table_constraint>:
[CONSTRAINT constraint_name] PRIMARY KEY (column_name, ...) NOT ENFORCED
<metadata_column_definition>:
column_name column_type METADATA [ FROM metadata_key ] [ VIRTUAL ]
<computed_column_definition>:
column_name AS computed_column_expression [COMMENT column_comment]
<watermark_definition>:
WATERMARK FOR rowtime_column_name AS watermark_strategy_expression
<source_table>:
[catalog_name.][db_name.]table_name
<like_options>:
{
{ INCLUDING | EXCLUDING } { ALL | CONSTRAINTS | PARTITIONS }
| { INCLUDING | EXCLUDING | OVERWRITING } { GENERATED | OPTIONS | WATERMARKS }
}[, ...]
6. CDC连接器
https://github.com/ververica/flink-cdc-connectors
6.1 基础概念
CDC: change Date Capture 变更数据获取
CDC可以从数据库中获取已提交的变更并把更改发送到下游使用,
6.2 编译 mysql-cdc
-
https://github.com/ververica/flink-cdc-connectors下载源码 -
修改源码flink 里面的版本 分支release-2.2
- 修改父pom
<properties> <flink.version>1.14.4flink.version>- 移出不必要的项目
<modules> <module>flink-cdc-basemodule> <module>flink-connector-debeziummodule> <module>flink-connector-test-utilmodule> <module>flink-connector-mysql-cdcmodule> <module>flink-sql-connector-mysql-cdcmodule> modules>- 移出 带blink 的版本
[ERROR] Failed to execute goal on project flink-cdc-base: Could not resolve dependencies for project com.ververica:flink-cdc-base:jar:2.2-SNAPSHOT: The following artifacts could not be resolved: org.apache.flink:flink-table-p lanner-blink_2.11:jar:1.14.4, org.apache.flink:flink-table-runtime-blink_2.11:jar:1.14.4, org.apache.flink:flink-table-planner-blink_2.11:jar:tests:1.14.4: Could not find artifact org.apache.flink:flink-table-planner-blink_2. 11:jar:1.14.4 in alimaven (http://maven.aliyun.com/nexus/content/repositories/central/) -> [Help 1] org.apache.flink:flink-table-runtime-blink_2.11 ==>org.apache.flink:flink-table-runtime_2.11 -
打包
mvn install '-Dmaven.test.skip=true'

6.3 mysql 开启binlog
- 修改配置文件 /etc/my.ini 后面添加配置
server-id=1
log_bin=/var/lib/mysql/mysql-bin.log
expire_logs_days=7
binlog_format=ROW
max_binlog_size=100M
binlog_cache_size=16M max_binlog_cache_size=256M
relay_log_recovery=1
sync_binlog=1
innodb_flush_log_at_trx_commit=1
- 重启
systemctl restart mysqld
- 查看 binlog 是否生效
show variables like 'log_%';
- 或者查看服务状态
show master status
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
|---|---|---|---|---|
| mysql-bin.000001 | 154 |
6.4 示例
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(20000, CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointStorage("file:///D:/Resource/FrameMiddleware/FlinkNew/sinkout3/");
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
// 建 cdc 连接器源表
tenv.executeSql("CREATE TABLE flink_test1 (\n"
+ " id INT,\n"
+ " name string,\n"
+ " gender string,\n"
+ " score INT,\n"
+ " PRIMARY KEY(id) NOT ENFORCED\n"
+ " ) WITH (\n"
+ " 'connector' = 'mysql-cdc',\n"
+ " 'hostname' = '192.168.141.155',\n"
+ " 'port' = '3306',\n"
+ " 'username' = 'root',\n"
+ " 'password' = 'hadoop',\n"
+ " 'database-name' = 'flink',\n"
+ " 'table-name' = 'test1'\n" + ")");
// 简单查询
tenv.executeSql("select * from flink_test1").print() ;
每次Checkpoint 都会拉去binlog 数据
[2023-06-14 00:17:48] [INFO] Triggering checkpoint 3 (type=CHECKPOINT) @ 1686673068434 for job bb8a1efdd953c1b42a5ce49217b7f445.
[2023-06-14 00:17:48] [INFO] Completed checkpoint 3 for job bb8a1efdd953c1b42a5ce49217b7f445 (5970 bytes, checkpointDuration=11 ms, finalizationTime=3 ms).
[2023-06-14 00:17:48] [INFO] Marking checkpoint 3 as completed for source Source: TableSourceScan(table=[[default_catalog, default_database, flink_test1]], fields=[id, name, gender, score]).
| +I | 6 | add | male | 22222.0 |
[2023-06-14 00:18:08] [INFO] Triggering checkpoint 4 (type=CHECKPOINT) @ 1686673088434 for job bb8a1efdd953c1b42a5ce49217b7f445.
[2023-06-14 00:18:08] [INFO] Completed checkpoint 4 for job bb8a1efdd953c1b42a5ce49217b7f445 (5970 bytes, checkpointDuration=9 ms, finalizationTime=2 ms).
[2023-06-14 00:18:08] [INFO] Marking checkpoint 4 as completed for source Source: TableSourceScan(table=[[default_catalog, default_database, flink_test1]], fields=[id, name, gender, score]).
| -U | 3 | add | male | 22222.0 |
| +U | 3 | add | male11 | 22222.0 |
| -D | 1 | sff | male | 1000.0 |
[2023-06-14 00:18:28] [INFO] Triggering checkpoint 5 (type=CHECKPOINT) @ 1686673108434 for job bb8a1efdd953c1b42a5ce49217b7f445.
[2023-06-14 00:18:28] [INFO] Completed checkpoint 5 for job bb8a1efdd953c1b42a5ce49217b7f445 (5970 bytes, checkpointDuration=10 ms, finalizationTime=2 ms).
[2023-06-14 00:18:28] [INFO] Marking checkpoint 5 as completed for source Source: TableSourceScan(table=[[default_catalog, default_database, flink_test1]], fields=[id, name, gender, score]).
[2023-06-14 00:18:48] [INFO] Triggering checkpoint 6 (type=CHECKPOINT) @ 1686673128433 for job bb8a1efdd953c1b42a5ce49217b7f445.
[2023-06-14 00:18:48] [INFO] Completed checkpoint 6 for job bb8a1efdd953c1b42a5ce49217b7f445 (5970 bytes, checkpointDuration=11 ms, finalizationTime=3 ms).
[2023-06-14 00:18:48] [INFO] Marking checkpoint 6 as completed for source Source: TableSourceScan(table=[[default_catalog, default_database, flink_test1]], fields=[id, name, gender, score]).
| -U | 6 | add | male | 22222.0 |
| +U | 6 | 1 | male | 22222.0 |
[2023-06-14 00:19:08] [INFO] Triggering checkpoint 7 (type=CHECKPOINT) @ 1686673148434 for job bb8a1efdd953c1b42a5ce49217b7f445.
[2023-06-14 00:19:08] [INFO] Completed checkpoint 7 for job bb8a1efdd953c1b42a5ce49217b7f445 (5970 bytes, checkpointDuration=10 ms, finalizationTime=2 ms).
[2023-06-14 00:19:08] [INFO] Marking checkpoint 7 as completed for source Source: TableSourceScan(table=[[default_catalog, default_database, flink_test1]], fields=[id, name, gender, score]).
| -U | 5 | add | aaddasd | 1212.0 |
| +U | 5 | add | 2233 | 1212.0 |
7. 表和流的转换
7.1 changelogStream
flink 中的表: 持续输入,持续查询,数据的动态的概念
7.2 表转换成流方法

注: toDataStream 只有Insert 的流,有插入和更新的就使用toChangelogStream
7.3 流转换成表
用法参考3.6

8.表查询语法
8.1 基本查询
select /where /group by /with / distinct /limit /order by finksql 和正常的sql 含义是一样的
8.2 高阶语法
多维度聚合
group by cube(维度 1,维度 2,维度 3)
group by grouping sets( (维度 1,维度 2) ,(维度 1,维度 3), (维度 2),())
group by rollup(省,市,区)
8.3 时间窗口TVF (表值函数)
https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/dev/table/sql/queries/window-tvf/
https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/dev/table/sql/queries/window-agg/
版本 > flink1.13 提供了时间窗口聚合计算的 TVF 语法
基础使用
- 在窗口上做分组聚合,必须带上 window_start 和 window_end 作为分组 key
- 在窗口上做 topN 计算 ,必须带上 window_start 和 window_end 作为 partition 的 key.
- 带条件的 join,必须包含 2 个输入表的 window start 和 window end 等值条件
8.4 window 聚合示例
Flink SQL> desc Bid;
+-------------+------------------------+------+-----+--------+---------------------------------+
| name | type | null | key | extras | watermark |
+-------------+------------------------+------+-----+--------+---------------------------------+
| bidtime | TIMESTAMP(3) *ROWTIME* | true | | | `bidtime` - INTERVAL '1' SECOND |
| price | DECIMAL(10, 2) | true | | | |
| item | STRING | true | | | |
| supplier_id | STRING | true | | | |
+-------------+------------------------+------+-----+--------+---------------------------------+
Flink SQL> SELECT * FROM Bid;
+------------------+-------+------+-------------+
| bidtime | price | item | supplier_id |
+------------------+-------+------+-------------+
| 2020-04-15 08:05 | 4.00 | C | supplier1 |
| 2020-04-15 08:07 | 2.00 | A | supplier1 |
| 2020-04-15 08:09 | 5.00 | D | supplier2 |
| 2020-04-15 08:11 | 3.00 | B | supplier2 |
| 2020-04-15 08:13 | 1.00 | E | supplier1 |
| 2020-04-15 08:17 | 6.00 | F | supplier2 |
+------------------+-------+------+-------------+
8.4.1 滚动窗口 TUMBLE
-
滚动窗口 每10分钟的交易总额
-
TUMBLE(TABLE data, DESCRIPTOR(timecol), size [, offset ])
-- 1.滚动窗口 每10分钟的交易总额
Flink SQL> SELECT window_start, window_end, SUM(price)
FROM TABLE(
TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES))
GROUP BY window_start, window_end;
+------------------+------------------+-------+
| window_start | window_end | price |
+------------------+------------------+-------+
| 2020-04-15 08:00 | 2020-04-15 08:10 | 11.00 |
| 2020-04-15 08:10 | 2020-04-15 08:20 | 10.00 |
+------------------+------------------+-------+
8.4.2 滑动窗口 HOP
-
滑动窗口 每五分钟计算10分钟内的总额
-
滑动窗口 每五分钟计算10分钟内的总额 根据supplier_id 分组
-
HOP(TABLE data, DESCRIPTOR(timecol), slide, size [, offset ])
--2. hopping window aggregation 滑动窗口 每五分钟计算10分钟内的总额
Flink SQL> SELECT window_start, window_end, SUM(price)
FROM TABLE(
HOP(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '5' MINUTES, INTERVAL '10' MINUTES))
GROUP BY window_start, window_end;
+------------------+------------------+-------+
| window_start | window_end | price |
+------------------+------------------+-------+
| 2020-04-15 08:00 | 2020-04-15 08:10 | 11.00 |
| 2020-04-15 08:05 | 2020-04-15 08:15 | 15.00 |
| 2020-04-15 08:10 | 2020-04-15 08:20 | 10.00 |
| 2020-04-15 08:15 | 2020-04-15 08:25 | 6.00 |
+------------------+------------------+-------+
-- 3, 滑动窗口 每五分钟计算10分钟内的总额 根据supplier_id 分组
Flink SQL> SELECT window_start, window_end, SUM(price), supplier_id
FROM TABLE(
HOP(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '5' MINUTES, INTERVAL '10' MINUTES))
GROUP BY window_start, window_end,supplier_id;
+------------------+------------------+-------+
| window_start | window_end | price |
+------------------+------------------+-------+
| 2020-04-15 08:00 | 2020-04-15 08:10 | 11.00 |
| 2020-04-15 08:05 | 2020-04-15 08:15 | 15.00 |
| 2020-04-15 08:10 | 2020-04-15 08:20 | 10.00 |
| 2020-04-15 08:15 | 2020-04-15 08:25 | 6.00 |
+------------------+------------------+-------+
8.4.3 累加窗口 CUMULATE
-
使用场景 每2分钟统计10分钟内窗口数据
-
CUMULATE(TABLE data, DESCRIPTOR(timecol), step, size)
-- cumulative window aggregation 累计窗口 其他:使用场景 每个小时统计当天的数据
Flink SQL> SELECT window_start, window_end, SUM(price)
FROM TABLE(
CUMULATE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '2' MINUTES, INTERVAL '10' MINUTES))
GROUP BY window_start, window_end;
+------------------+------------------+-------+
| window_start | window_end | price |
+------------------+------------------+-------+
| 2020-04-15 08:00 | 2020-04-15 08:06 | 4.00 |
| 2020-04-15 08:00 | 2020-04-15 08:08 | 6.00 |
| 2020-04-15 08:00 | 2020-04-15 08:10 | 11.00 |
| 2020-04-15 08:10 | 2020-04-15 08:12 | 3.00 |
| 2020-04-15 08:10 | 2020-04-15 08:14 | 4.00 |
| 2020-04-15 08:10 | 2020-04-15 08:16 | 4.00 |
| 2020-04-15 08:10 | 2020-04-15 08:18 | 10.00 |
| 2020-04-15 08:10 | 2020-04-15 08:20 | 10.00 |
+------------------+------------------+-------+
8.5 window-topn
- 10 分钟滚动窗口内交易总额最高的前3家供应商,及其交易总额和交易单数
SELECT *
FROM (
SELECT *, ROW_NUMBER() OVER (PARTITION BY window_start, window_end ORDER BY price DESC) as rownum
FROM (
SELECT window_start, window_end, supplier_id, SUM(price) as price, COUNT(*) as cnt
FROM TABLE(
TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES))
GROUP BY window_start, window_end, supplier_id
)
) WHERE rownum <= 3;
8.6 window join 窗口join
- inner/left/right/full : (两边条件都满足,左边数据,右边数据,)
- inner join 关联出来两边数据都有的
- left join 左表关联右表,取左表所有的数据,右表关联上的数据,右表关联不上的为null
- right join 右表关联左表,取右表所有数据,和左表关联上的字段,左表关联不上的为null
- full join 左表关联右表 取所有的数据,关联不上的补bnull
//INNER/LEFT/RIGHT/FULL OUTER Window Join 语句的语法。
SELECT ...
FROM L [LEFT|RIGHT|FULL OUTER] JOIN R -- L and R are relations applied windowing TVF
ON L.window_start = R.window_start AND L.window_end = R.window_end AND ...
Flink SQL> desc LeftTable;
+----------+------------------------+------+-----+--------+----------------------------------+
| name | type | null | key | extras | watermark |
+----------+------------------------+------+-----+--------+----------------------------------+
| row_time | TIMESTAMP(3) *ROWTIME* | true | | | `row_time` - INTERVAL '1' SECOND |
| num | INT | true | | | |
| id | STRING | true | | | |
+----------+------------------------+------+-----+--------+----------------------------------+
Flink SQL> SELECT * FROM LeftTable;
+------------------+-----+----+
| row_time | num | id |
+------------------+-----+----+
| 2020-04-15 12:02 | 1 | L1 |
| 2020-04-15 12:06 | 2 | L2 |
| 2020-04-15 12:03 | 3 | L3 |
+------------------+-----+----+
Flink SQL> desc RightTable;
+----------+------------------------+------+-----+--------+----------------------------------+
| name | type | null | key | extras | watermark |
+----------+------------------------+------+-----+--------+----------------------------------+
| row_time | TIMESTAMP(3) *ROWTIME* | true | | | `row_time` - INTERVAL '1' SECOND |
| num | INT | true | | | |
| id | STRING | true | | | |
+----------+------------------------+------+-----+--------+----------------------------------+
Flink SQL> SELECT * FROM RightTable;
+------------------+-----+----+
| row_time | num | id |
+------------------+-----+----+
| 2020-04-15 12:01 | 2 | R2 |
| 2020-04-15 12:04 | 3 | R3 |
| 2020-04-15 12:05 | 4 | R4 |
+------------------+-----+----+
Flink SQL> SELECT L.num as L_Num, L.id as L_Id, R.num as R_Num, R.id as R_Id, L.window_start, L.window_end
FROM (
SELECT * FROM TABLE(TUMBLE(TABLE LeftTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))
) L
FULL JOIN (
SELECT * FROM TABLE(TUMBLE(TABLE RightTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))
) R
ON L.num = R.num AND L.window_start = R.window_start AND L.window_end = R.window_end;
+-------+------+-------+------+------------------+------------------+
| L_Num | L_Id | R_Num | R_Id | window_start | window_end |
+-------+------+-------+------+------------------+------------------+
| 1 | L1 | null | null | 2020-04-15 12:00 | 2020-04-15 12:05 |
| null | null | 2 | R2 | 2020-04-15 12:00 | 2020-04-15 12:05 |
| 3 | L3 | 3 | R3 | 2020-04-15 12:00 | 2020-04-15 12:05 |
| 2 | L2 | null | null | 2020-04-15 12:05 | 2020-04-15 12:10 |
| null | null | 4 | R4 | 2020-04-15 12:05 | 2020-04-15 12:10 |
+-------+------+-------+------+------------------+------------------+
- semi ( 即: where id in … )
Flink SQL> SELECT *
FROM (
SELECT * FROM TABLE(TUMBLE(TABLE LeftTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))
) L WHERE L.num IN (
SELECT num FROM (
SELECT * FROM TABLE(TUMBLE(TABLE RightTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))
) R WHERE L.window_start = R.window_start AND L.window_end = R.window_end);
+------------------+-----+----+------------------+------------------+-------------------------+
| row_time | num | id | window_start | window_end | window_time |
+------------------+-----+----+------------------+------------------+-------------------------+
| 2020-04-15 12:03 | 3 | L3 | 2020-04-15 12:00 | 2020-04-15 12:05 | 2020-04-15 12:04:59.999 |
+------------------+-----+----+------------------+------------------+-------------------------+
Flink SQL> SELECT *
FROM (
SELECT * FROM TABLE(TUMBLE(TABLE LeftTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))
) L WHERE EXISTS (
SELECT * FROM (
SELECT * FROM TABLE(TUMBLE(TABLE RightTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))
) R WHERE L.num = R.num AND L.window_start = R.window_start AND L.window_end = R.window_end);
+------------------+-----+----+------------------+------------------+-------------------------+
| row_time | num | id | window_start | window_end | window_time |
+------------------+-----+----+------------------+------------------+-------------------------+
| 2020-04-15 12:03 | 3 | L3 | 2020-04-15 12:00 | 2020-04-15 12:05 | 2020-04-15 12:04:59.999 |
+------------------+-----+----+------------------+------------------+-------------------------+
- anti ( 即: where id not in … )
Flink SQL> SELECT *
FROM (
SELECT * FROM TABLE(TUMBLE(TABLE LeftTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))
) L WHERE L.num NOT IN (
SELECT num FROM (
SELECT * FROM TABLE(TUMBLE(TABLE RightTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))
) R WHERE L.window_start = R.window_start AND L.window_end = R.window_end);
+------------------+-----+----+------------------+------------------+-------------------------+
| row_time | num | id | window_start | window_end | window_time |
+------------------+-----+----+------------------+------------------+-------------------------+
| 2020-04-15 12:02 | 1 | L1 | 2020-04-15 12:00 | 2020-04-15 12:05 | 2020-04-15 12:04:59.999 |
| 2020-04-15 12:06 | 2 | L2 | 2020-04-15 12:05 | 2020-04-15 12:10 | 2020-04-15 12:09:59.999 |
+------------------+-----+----+------------------+------------------+-------------------------+
Flink SQL> SELECT *
FROM (
SELECT * FROM TABLE(TUMBLE(TABLE LeftTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))
) L WHERE NOT EXISTS (
SELECT * FROM (
SELECT * FROM TABLE(TUMBLE(TABLE RightTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))
) R WHERE L.num = R.num AND L.window_start = R.window_start AND L.window_end = R.window_end);
+------------------+-----+----+------------------+------------------+-------------------------+
| row_time | num | id | window_start | window_end | window_time |
+------------------+-----+----+------------------+------------------+-------------------------+
| 2020-04-15 12:02 | 1 | L1 | 2020-04-15 12:00 | 2020-04-15 12:05 | 2020-04-15 12:04:59.999 |
| 2020-04-15 12:06 | 2 | L2 | 2020-04-15 12:05 | 2020-04-15 12:10 | 2020-04-15 12:09:59.999 |
+------------------+-----+----+------------------+------------------+-------------------------+
注意点:
-
在 TVF 上使用 join
-
参与 join 的两个表都需要定义时间窗口 (join 的表的窗口定义要相同)
-
join 的条件中必须包含两表的 window_start 和 window_end 的等值条件
8.7 Regular Joins 常规join
8.7.1 基础概念
常规联接是最通用的联接类型,其中任何新记录或对联接任一侧的更改都是可见的,并且会影响整个联接结果。例如左边有一条新记录,当product id 相等时,它会在右边与所有之前和未来的记录合并。
SELECT * FROM Orders
INNER JOIN Product
ON Orders.productId = Product.id
对于流式查询,常规连接的语法是最灵活的,并且允许任何类型的更新(插入、更新、删除)输入表。但是,此操作具有重要的操作含义:它需要将连接输入的两侧永远保持在 Flink 状态。因此,计算查询结果所需的状态可能会无限增长,具体取决于所有输入表和中间连接结果的不同输入行的数量。您可以为查询配置提供适当的状态生存时间 (TTL)[table.exec.state.ttl],以防止状态过大;
总之:就是关联的表的数据都会保存在状态中,如果不设置数据的TTL,状态数据会无限增长
8.7.2 常规 join
INNER JOIN/ LEFT JOIN / RIGHT JOIN /FULL OUTER JOIN
8.7.3 lookup join
使用场景是维表JOIN , 左边是流数据,在join 的时候,根据关联条件,通过连接器取实时查询原表数据(点查) (并不是所有的连接器都支持)
连接器为了提高性能,会把查询过的数据缓存起来( 默认未开启)
-- Customers is backed by the JDBC connector and can be used for lookup joins
CREATE TEMPORARY TABLE Customers (
id INT,
name STRING,
country STRING,
zip STRING
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://mysqlhost:3306/customerdb',
'table-name' = 'customers'
);
-- enrich each order with customer information
SELECT o.order_id, o.total, c.country, c.zip
FROM Orders AS o
JOIN Customers FOR SYSTEM_TIME AS OF o.proc_time AS c //
ON o.customer_id = c.id;
8.7.4 Interval Joins
区间 Join
返回受连接条件和时间约束限制的简单笛卡尔积。间隔连接至少需要一个等值连接谓词和一个限制两侧时间的连接条件。两个适当的范围谓词可以定义这样的条件(<、<=、>=、>)、BETWEEN 谓词或比较两个输入的相同类型(即处理时间或事件时间)的时间属性的单个相等谓词表。
例如,如果订单是在收到订单后四个小时发货的,则此查询将连接所有订单及其相应的发货。
SELECT *
FROM Orders o, Shipments s
WHERE o.id = s.order_id
AND o.order_time BETWEEN s.ship_time - INTERVAL '4' HOUR AND s.ship_time
关联其他表(表中数据有时间范围)
8.7.5 temporal join 事态join
左表数据关联右表数据对应时间的最新版;
订单表关联当时的汇率表
-- Create a table of orders. This is a standard
-- append-only dynamic table. 动态表
CREATE TABLE orders (
order_id STRING,
price DECIMAL(32,2),
currency STRING,
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time
) WITH (/* ... */);
-- Define a versioned table of currency rates. 版本表 需要指定主键
-- This could be from a change-data-capture
-- such as Debezium, a compacted Kafka topic, or any other
-- way of defining a versioned table.
CREATE TABLE currency_rates (
currency STRING,
conversion_rate DECIMAL(32, 2),
update_time TIMESTAMP(3) METADATA FROM `values.source.timestamp` VIRTUAL,
WATERMARK FOR update_time AS update_time,
PRIMARY KEY(currency) NOT ENFORCED //()
) WITH (
'connector' = 'kafka',
'value.format' = 'debezium-json',
/* ... */
);
SELECT
order_id,
price,
currency,
conversion_rate,
order_time
FROM orders
LEFT JOIN currency_rates FOR SYSTEM_TIME AS OF orders.order_time
ON orders.currency = currency_rates.currency;
order_id price currency conversion_rate order_time
======== ===== ======== =============== =========
o_001 11.11 EUR 1.14 12:00:00
o_002 12.51 EUR 1.10 12:06:00
8.8 over()
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/table/sql/queries/over-agg/
与GROUP BY聚合相比,OVER聚合不会将每个组的结果行数减少到一行,相反,OVER聚合为每个输入行生成一个聚合值。
以下查询为每个订单计算在当前订单之前一小时内收到的同一产品的所有订单的金额总和。
SELECT order_id, order_time, amount,
SUM(amount) OVER (
PARTITION BY product
ORDER BY order_time
RANGE BETWEEN INTERVAL '1' HOUR PRECEDING AND CURRENT ROW
) AS one_hour_prod_amount_sum
FROM Orders
语法
SELECT
agg_func(agg_col) OVER (
[PARTITION BY col1[, col2, ...]]
ORDER BY time_col
range_definition),
...
FROM ...
ORDER BY
OVER窗口是在有序的行序列上定义的。由于表没有固有顺序,因此该ORDER BY子句是强制性的。对于流式查询,Flink 目前只支持OVER按升序**[时间属性] 顺序**定义的窗口。不支持额外的order
PARTITION BY
OVER可以在分区表上定义窗口。在存在PARTITION BY子句的情况下,仅在其分区的行上为每个输入行计算聚合
range_definition
范围定义指定聚合中包含多少行。该范围是用一个子句定义的BETWEEN,该子句定义了下限和上限。这些边界之间的所有行都包含在聚合中。Flink 只支持CURRENT ROW作为上边界。
有两个选项来定义范围,ROWS intervals 和 range intervals
range intervals
RANGE BETWEEN INTERVAL '30' MINUTE PRECEDING AND CURRENT ROW
ROWS intervals
ROWS BETWEEN 10 PRECEDING AND CURRENT ROW
8.函数
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/table/functions/overview/
8.1 系统函数
自带的一些函数
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/table/functions/systemfunctions/
8.1 自定义函数
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/table/functions/udfs/
8.1.1 Scalar Function
标量函数:
特点:每次接受一行数据,输出也是一行数据
eg:upper()
示例:
import org.apache.flink.table.annotation.InputGroup;
import org.apache.flink.table.api.*;
import org.apache.flink.table.functions.ScalarFunction;
import static org.apache.flink.table.api.Expressions.*;
public static class HashFunction extends ScalarFunction {
// take any data type and return INT
public int eval(@DataTypeHint(inputGroup = InputGroup.ANY) Object o) {
return o.hashCode();
}
}
TableEnvironment env = TableEnvironment.create(...);
// call function "inline" without registration in Table API // Table API 可以不注册
env.from("MyTable").select(call(HashFunction.class, $("myField")));
// register function
env.createTemporarySystemFunction("HashFunction", HashFunction.class);
// call registered function in Table API
env.from("MyTable").select(call("HashFunction", $("myField")));
// call registered function in SQL //sql 方式使用需要注册 方法
env.sqlQuery("SELECT HashFunction(myField) FROM MyTable");
8.1.2 Table Functions
表生成函数
接受一行数据(一个或者多个字段) ,输出是多行多列数据
egexplode():
示例:略
8.1.3 Aggregate Functions
聚合函数
接受多行数据 ,输出单行数据
eg: sum() ,avg();
示例:略
8.1.4 Table Aggregate Functions
表聚合函数
接受多行数据 ,输出多列数据
eg: topn
示例:略
9. SqlClient使用
sql-client 是flink 安装包中自带的命令行工具,快捷方便的使用sql 操作
首先需要启动一个flink session集群 standalone or on yarn
./sql-client.sh -h
-f :指定初始化sql 脚本文件
-l : (--library) 指定要添加的外部jar作为依赖
-j :指定一个jar 包文件路径来加载这个jar
-s :指定要连接的flink session 集群
示例:从 kafka 中读取一个 topic 的数据然后统计每 5 分钟的去重用户数并且,把结果写入 mysql
-
存放jar 到自定义目录 (/lib/flink) flink-connector-jdbc_2.12-1.14.4.jar;flink-csv-1.14.3.jar ;flink-json-1.14.3.jar;flink-sql-connector-kafka_2.12-1.14.4.jar
-
启动 bin/sql-client.sh -l lib/
-
连接成功后,命令行中建表
//数据源表 CREATE TABLE events ( account STRING , appId STRING , appVersion STRING , ...... rt as to_timestamp_ltz(`timeStamp`,3), watermark for rt as rt - interval '0' second ) WITH ( 'connector' = 'kafka', 'topic' = 'doit-events', 'properties.bootstrap.servers' = 'doitedu:9092', 'properties.group.id' = 'testGroup', 'scan.startup.mode' = 'earliest-offset', 'format' = 'json' ) //目标表 CREATE TABLE uv_report ( window_start timestamp(3), window_end timestamp(3), uv bigint ) WITH ( 'connector' = 'jdbc', 'url' = 'jdbc:mysql://doitedu:3306/doitedu', 'table-name' = 'uv_report', 'username' = 'root', 'password'= 'root' ); //sql 开发 INSERT INTO uv_report SELECT window_start, window_end, count(distinct deviceId) as uv FROM TABLE(TUMBLE(table events,descriptor(rt),interval '1' minute)) group by window_start,window_end
10. flink监控指标Metric 体系
获取flink 运行中的基本指标;
flink 也提供了如下统计器,来方便用户自定义各类自己的状态度量,在代码中自定义添加
-
counter 计数器
-
gauge value,对值的类型没有限制
-
histogram:度量值的统计结果
-
meter:通常用来度量平均吞吐量