Redis
典型的非关系型数据库,那么什么叫非关系型数据库?
不保证关系数据的ACID特性
那么什么叫ACID,是指数据库管理系统在写入或更新资料的过程中,为保证事务是正确可靠的,所必须具备的四个特性:原子性、一致性、隔离性、持久性。
原子性:
一个事务必须被视为一个不可分割的最小工作单元,整个事务中的所有操作要么全部提交成功,要么全部失败回滚,对于一个事务来说,不可能只执行其中的一部分操作,这就是事务的原子性。
一致性:
数据库总是从一个一致性的状态转换到另一个一致性的状态。
隔离性:
并发事务之间互相影响的程度,比如一个事务会不会读取到另一个未提交的事务修改的数据
持久性:
一旦事务提交,则其所做的修改就会永久保存到数据库中,此时即使系统崩溃,修改的数据也不会丢失
Redis快的原因:
1、redis完全基于内存:绝大部分请求是纯粹的内存操作,非常快速。
2、数据结构简单:redis中的数据结构是专门进行设计的。
3、采用单线程模型,避免了不必要的上下文切换和竞争条件:也不存在多线程或者多线程切换而消耗CPU, 不用考虑各种锁的问题, 不存在加锁, 释放锁的操作, 没有因为可能出现死锁而导致性能消耗
4、使用了多路IO复用模型:非阻塞IO
常用数据类型:
字符串 :String
散列(0或1):Hash
列表:List
集合:Set
有序集合:Sorted Set(zset)
| String(字符串) |
1.重复设置会覆盖 2.获取不存在的key返回nil(与go语言的空类型一致) 3.setnx:设置锁的一种(set if not exit) |
1.设置指定 key 的值:set key value 2.获取指定 key 的值:get key 3.指定过期时间:setex key time value 4.获取key对应值的长度:strlen key 5.只有在 key 不存在时设置 key 的值:setnx key value 6.给指定的值加一 incr key 7.给指定的值减一 decr key |
| Hash(字典) |
1.是一个 string 类型的 field(字段) 和 value(值) 的映射表,hash 特别适合用于存储对象(类似于go语言的map或者slice) 2.重复设置会覆盖 |
1.设置值:Hset key field value 2.获取值:hget key field 3.获取全部的field名称:hkeys key 4.获取全部的filed和对应值:HGETALL key 5.删除:hdel key field 6.获取所有指:hvals key |
| List(列表) |
获取数据关键字:lrange(go语循环用range for) |
1.插入:lpush key value 2.插入数据的头部:lpush key value1 values 3.获取数据:lrange key start end 4.获取队列长度:llen key 5.删除:lpop |
| Set(集合) |
无序集合 |
1.插入数据:sadd key value 2.插入多个:sadd key value1 value2 3.获取全部数据:smembers key 4.移除:spop key 5.获取交集:sinter key1 key2 |
| Sorted Set(有序集合) |
数据插入集合时,已经进行天然排序(可以利用score坐标标准排序:排行榜) |
1.添加一个或者多个数据:zadd key score1 member1 score2 member2 2.获取数据分数:zscore key member 3.获取成员个数:zcard key 4.获取成员:zrange key start end 5.获取全部的数据:zrange key start end withscores 6.移除:zrem key member 7.给指定成员加数据量: incrementzincrby key increment member 8.获取范围排名:zrevrange key start end |
其他数据类型:
HyperLogLogs(基数统计)
Bitmap (位存储)
geospatial (地理位置)
缓存穿透
一些恶意的请求会故意查询不存在的key,请求量很大,就会对后端系统造成很大的压力。这就叫做缓存穿透
解决方案:
1.对查询结果为空的情况也进行缓存,缓存时间设置短一点,或者该key对应的数据insert之后清理缓存。
2.对一定不存在的key进行过滤。可以把所有的可能存在的key放到一个大的Bitmap中,查询时通过该Bitmap过滤。
缓存雪崩
当缓存服务器重启或者大量缓存集中在某一时间段失效,这样在失效的时候,会给后端系统带来很大的压力,导致系统崩溃。
解决方案:
1.在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其它线程等待;
2.做二级缓存,不同的key,设置不同的过期时间,让缓存失效的时间尽量均匀;
缓存击穿
产生缓存雪崩的原因:redis中的某个热点key过期,但是此时有大量的用户访问该过期key
提前对热点数据进行设置
Redis持久化有几种方式?
redis提供了两种持久化的方式,分别是RDB(Redis DataBase)和AOF(Append Only File)。
RDB:将存储的数据生成快照并存储到磁盘等介质上;
AOF:将redis执行过的所有写指令记录下来,在下次redis重新启动时,只要把这些写指令从前到后再重复执行一遍,就可以实现数据恢复了。
其实RDB和AOF两种方式也可以同时使用,在这种情况下,如果redis重启的话,则会优先采用AOF方式来进行数据恢复,这是因为AOF方式的数据恢复完整度更高,但是RDB体积小,会更快
redis加锁分类
redis能用的的加锁命令分别是 INCR、SETNX、SET
1. 第一种锁命令INCR
这种加锁的思路是, key 不存在,那么 key 的值会先被初始化为 0 ,然后再执行 INCR 操作进行加一。
然后其它用户在执行 INCR 操作进行加一时,如果返回的数大于 1 ,说明这个锁正在被使用当中。
1、 客户端A请求服务器获取key的值为1表示获取了锁
2、 客户端B也去请求服务器获取key的值为2表示获取锁失败
3、 客户端A执行代码完成,删除锁
4、 客户端B在等待一段时间后在去请求的时候获取key的值为1表示获取锁成功
5、 客户端B执行代码完成,删除锁
$redis->incr($key);
$redis->expire($key, $ttl); //设置生成时间为1秒
2. 第二种锁SETNX(set if not exists)
这种加锁的思路是,如果 key 不存在,将 key 设置为 value,如果 key 已存在,则 SETNX 不做任何动作,成功返回1,失败返回0
1、 客户端A请求服务器设置key的值,如果设置成功就表示加锁成功
2、 客户端B也去请求服务器设置key的值,如果返回失败,那么就代表加锁失败
3、 客户端A执行代码完成,删除锁
4、 客户端B在等待一段时间后在去请求设置key的值,设置成功
5、 客户端B执行代码完成,删除锁
$redis->setNX($key, $value);
$redis->expire($key, $ttl);
3. 第三种锁SET
上面两种方法都有一个问题,会发现,都需要设置 key 过期。那么为什么要设置key过期呢?如果请求执行因为某些原因意外退出了,导致创建了锁但是没有删除锁,那么这个锁将一直存在,以至于以后缓存再也得不到更新。于是乎我们需要给锁加一个过期时间以防不测。
但是借助 Expire 来设置就不是原子性操作了。所以还可以通过事务来确保原子性,但是还是有些问题,所以官方就引用了另外一个,使用 SET 命令本身已经从版本 2.6.12 开始包含了设置过期时间的功能。
Redis的过期策略有哪些
1.惰性删除
2.定期删除
redis集群:
1.主从复制
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master),后者称为从节点(slave);数据的复制是单向的,只能由主节点到从节点。
作用:
1.数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
2.故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
3.负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务,分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
4.高可用基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。
5.主从库之间采用的是读写分离的方式。
2.分片模式
范围分区
最简单的分区方式是按范围分区,就是映射一定范围的对象到特定的Redis实例。比如,ID从0到10000的用户会保存到实例R0,ID从10001到 20000的用户会保存到R1,以此类推。这种方式是可行的,并且在实际中使用,不足就是要有一个区间范围到实例的映射表。这个表要被管理,同时还需要各 种对象的映射表,通常对Redis来说并非是好的方法。主要思想:分段
哈希分区
另外一种分区方法是hash分区。这对任何key都适用,也无需是object_name:这种形式,像下面描述的一样简单:用一个hash函数将key转换为一个数字,比如使用crc32 hash函数。对key foobar执行crc32(foobar)会输出类似93024922的整数。主要思想:取模
3.哨兵模式
作用:
1.集群监控:负责监控 redis master 和 slave 进程是否正常工作。
2.消息通知:如果某个 redis 实例有故障,那么哨兵负责发送消息作为报警通知给管理员。
3.故障转移:如果 master node 挂掉了,会自动转移到 slave node 上。
4.配置中心:如果故障转移发生了,通知 client 客户端新的 master 地址。
5.哨兵至少需要 3 个实例,来保证自己的健壮性。哨兵 + redis 主从的部署架构,是不保证数据零丢失的,只能保证 redis 集群的高可用性。
lua脚本:
| 执行 | EVAL script numkeys key [key ...] arg [arg ...] |
| 执行 | EVALSHA sha1 numkeys key [key ...] arg [arg ...] |
| 查看指定的脚本是否已经被保存在缓存当中 | SCRIPT EXISTS script [script ...] |
| 从缓存中移除所有脚本 | SCRIPT FLUSH |
| 杀死当前正在运行的 脚本 | SCRIPT KILL |
| 将脚本添加到脚本缓存中(不会马上执行) | SCRIPT LOAD script |
安装(windows环境下):
1.下载地址(下载zip包):https://github.com/tporadowski/redis/releases
2.链接客户端命令:redis-server.exe redis.windows.conf
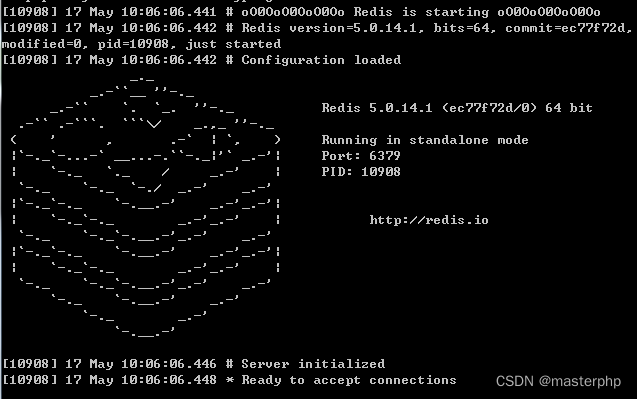
3.运行redis命令:redis-cli.exe -h 127.0.0.1 -p 6379
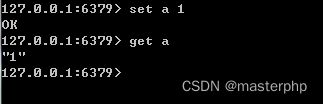
4.测试:
总结:
本篇文章介绍了redis的基础知识,基本上都是面试会经常问到的,至于常用的一些命令放在了常用数据类型那里,其他数据类型也是有很大用处的,比如GEO(地理位置)存储地理位置,里面有可以用来计算距离的方法,附近的人就是使用这个功能来实现的,在本人看来,redis作为一个工具大家都会,关键是搭建使用的方法,这个点才是关键点,使用得好才能将工具最大的效果发挥出来,实现开发的最优解,所以简单的列举属性和使用方法,最终对redis的理解还是要多动手多实践,只有多踩坑才能更好的了解和使用redis,这个适用于任何工具类。