计算机网络——自顶向下方法(第二章学习记录)
本章学习应用层
网络应用是计算机网络存在的理由。
网络应用程序体系结构
现代网络应用程序有两种主流体系结构:客户—服务器体系结构和对等(P2P)体系结构
客户—服务器体系结构(client-server ),在这个结构中,有一个总是打开的主机称为服务器,它服务于来自许多其他称为客户的主机的请求。
(一个典型的例子是Web应用程序,其中总是打开的Web服务器服务于来自浏览器(运行在客户主机)的请求。当它接收到请求后,它向该客户发送所请求的对象作为响应)
这种结构有几个特点:客户相互之间不直接通信;服务器具有固定的、周知的地址(IP地址)
具有这种结构的著名的应用程序包括Web、FTP、Telnet、和电子邮件
P2P体系结构,在这个结构中对位于数据中心的专用服务器有最小的(或者没有)依赖,相反,应用程序在间断连接的主机对之间使用直接通信,这些主机对被称为对等方。这种对等通信不必通过专门的服务器,因此该结构被称为对等方到对等方的。
这种结构最引人入胜的特征之一是它的自扩展性。
(例如,在一个P2P文件共享应用中,尽管每个对等方都由于请求文件产生工作负载。但每个对等方通过向其他对等方分发文件也为系统增加服务能力)
进程通信
用操作系统的术语来说,进行通信的实际上是进程(process)而不是程序。一个进程可以被认为是运行在端系统中的一个程序。在两个不同端系统上的进程,通过跨越计算机网络交换报文而相互通信。发送进程生成并向网络中发送报文,接收进程接收这些报文并可能通过回送报文进行响应。
客户和服务器进程
网络应用程序由成对的进程组成,这些进程通过网络相互发送报文。
(在Web应用程序中,一个客户浏览器进程与一台Web服务器进程交换报文;在一个P2P系统中,文件从一个对等方中的进程传输到另一个对等方中的进程)。对于每对通信进程,常将这两个进程之一标识为客户(client),而另一进程标识为服务器(server),
具体来说就是:在一对进程之间之间的通信会话场景中,发起通信的进程被标识为客户,在会话开始时等待联系的进程是服务器。
进程与计算机网络之间的接口
多数程序是由通信进程对组成,每对中的两个进程相互发送报文。从一个进程向另一个进程发送的报文必须通过下面的网络,进程通过一个称为套接字(socket)的软件接口向网络发送报文和从网络接收报文。
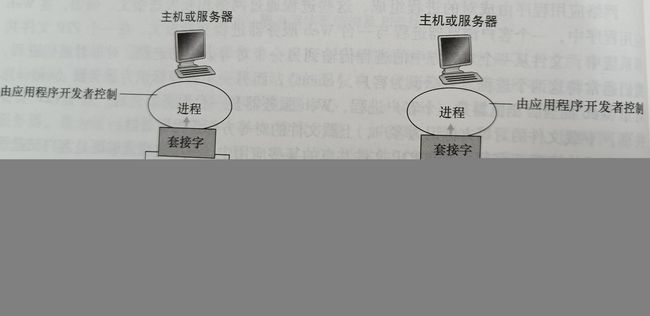
套接字是同一台主机内应用层与运输层之间的接口。由于该套接字是建立网络应用程序的可编程接口,因此套接字也称为应用程序和网络之间的应用程序编程接口(Application Programming Interface,API),应用程序开发者可以控制套接字在应用层端的一切,但是对该套接字的运输层几乎没有控制权。
进程寻址
在一台主机上运行的进程为了向在另一台主机上运行的进程发送分组,接收进程需要有一个地址,为了标识该接收进程,需要定义两种信息:①主机的地址②在目的主机中指定接收进程的标识符。在因特网中,主机由其IP地址标识(IP地址是一个32比特的量且它能够唯一地标识该主机)。接收主机用端口号(port number)来标识接收进程。
因特网提供的运输服务
因特网为应用程序提供两个运输层协议,UDP和TCP, 当软件开发者为因特网创建一个新的应用时,首先要做出的决定是选择UDP还是TCP,每个协议为第哦啊用它们的应用程序提供不同的服务集合。
TCP服务
TCP服务模型包括面向连接服务和可靠数据传输服务。当某个应用程序调用TCP作为其运输协议,该应用程序就能获得来自TCP地这两种服务。
- 面向连接的服务:在应用层数据报文开始流动之前,TCP让客户和服务器互相交换运输层控制信息,这个握手过程提醒客户和服务器,让它们为大量分组的到来做好准备,在握手阶段后,一个TCP连接就在两个进程的套接字之间建立了,这条连接是全双工的,即连接双方的进程可以在此连接上同时进行报文收发。当应用程序结束报文发送时,必须拆除该连接
- 可靠的数据传送服务:通信进程能够依靠TCP,无差错、按适当的顺序交付所有发送的数据。当应用程序的一端将字节流传进套接字时,它能够依靠TCP将相同的字节流交付给接收方的套接字,没有字节的丢失和冗余
TCP协议还具有拥塞控制机制,这种服务不一定能为通信进程带来直接好处,但能为因特网带来整体好处。当发送方和接收方之间的网络出现拥塞时,TCP的拥塞控制机制会抑制发送进程。
UDP服务
UDP是一种不提供不必要服务的轻量级运输协议,它仅提供最小服务。
- UDP是无连接的,因此在两个进程通信前没有握手过程。
- UDP协议提供一种不可靠数据传输服务,当进程将一个报文发送进UDP套接字时,UDP协议并不保证该报文将到达接收进程,而且到达接收进程的报文也有可能是乱序到达的。
UDP没有包括拥塞控制机制,所以UDP的发送端可以用它选定的任何速率向其下层(网络层)注入数据
这里需要注意的是无论是TCP还是UDP,都没有提供任何加密机制。发送进程传进其套接字的数据与经网络传送到目的端进程的数据相同,明文方式传送,这就可能使得信息在任何中间链路被发现。因此研制了TCP的加强版本——安全套接字(Secure Sockets Layer,SSL)。用SSL加强后的TCP不仅能够做传统TCP所能做的一切,而且提供了关键的进程到进程的安全性服务,包括加密、数据完整性和端点鉴别。
应用层协议
应用层协议定义了运行在不同端系统上的应用程序进程如何相互传递报文,特别是应用层协议定义了:
- 交换的报文类型,例如请求报文和响应报文
- 各种报文类型的语法,如报文中的各个字段及这些字段是如何描述的
- 字段的语义,即这些字段中的信息的含义
- 确定一个进程何时以及如何发送报文,对报文进行响应的规则
Web和HTTP
HTTP概况
Web的应用层协议是超文本传输协议(HyperText Transfer Protocol,HTTP),它是Web的核心。HTTP由两个程序实现:一个客户程序和一个服务器程序。客户程序和服务器程序运行在不同的端系统中,通过交换HTTP报文进行会话,HTTP定义了这些报文的结构以及客户和服务器进行报文交换的方式。
{Web页面是由对象组成的,一个对象只是一个文件,如HTML文件、JEPG图形、Java小程序这样的文件,且它们可以通过一个URL地址寻址,每个URL地址由两部分组成:存放对象的服务器主机名和对象的路径名}
HTTP定义了Web客户向Web服务器请求Web页面的方式,以及服务器向客户传送Web页面的方式。当用户请求一个Web页面(如点击一个超链接)时,浏览器向服务器发出对该页面中所包含对象的HTTP请求报文,服务器接收到请求并用包含这些对象的HTTP响应报文进行响应,如下图所示。
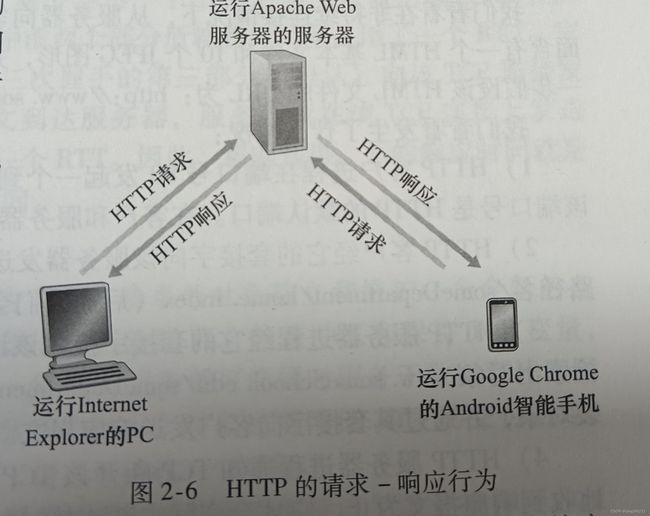
HTTP使用TCP作为它的支撑运输协议(而不是UDP)。HTTP客户首先发起一个与服务器的TCP连接,一旦连接建立,该浏览器和服务器进程就可以通过套接字接口访问TCP(客户端的套接字接口是客户进程与TCP连接之间的门,服务器端的套接字接口则是服务器进程与TCP连接之间的门。客户向它的套接字接口发送HTTP请求报文并从它的套接字接口接收HTTP响应报文,类似的服务器端也是如此, 一旦客户向它的套接字接口发送一个请求报文,该报文就脱离客户控制并进入TCP的控制,而TCP为HTTP提供可靠的数据传输服务)
服务器向客户发送被请求的文件,而不存储任何关于该客户的状态信息,假如客户在短时间内连续请求同一个对象,服务器会依次对每一个请求做出回应,不会因为之前的反应而不再提供服务。因为HTTP服务器不保存关于客户的任何信息,所以说HTTP协议是一个无状态协议(stateless protocol)
非持续连接和持续连接
客户和服务器再一个相当长的时间范围内通信,其中客户发出一系列请求并且服务器对每个请求进行响应,每个请求/响应对是经一个单独的TCP连接发送(非持续连接),或者所有的请求和响应经过相同的TCP连接发送(持续连接)。
- 非持续连接的HTTP的过程
在非持续连接情况下,从服务器向客户传送一个Web页面(假设该页面含有一个HTML基本文件和10个JEPG图形,并且这11个对象位于同一台服务器上)
(1)HTTP客户进程在端口号80发起一个到服务器的TCP连接,该端口号是HTTP的默认端口。在客户和服务器上分别有一个套接字与该连接相关联
(2)HTTP客户经它的套接字向该服务器发送一个HTTP请求报文
(3)HTTP服务器进程经它的套接字接收该请求报文,并向客户发送封装了对象的HTTP响应报文
(4)HTTP服务器进程通知TCP断开TCP连接
(5)HTTP客户接收响应报文,TCP连接关闭
上面的举例步骤说明了非持续连接的使用,其中每个TCP连接在服务器发送一个对象后关闭,即该连接并不为其他的对象而持续下来。每个TCP连接只传输一个请求报文和一个响应报文。
往返时间(Round-Trip Time,RTT)是指一个短分组从客户到服务器然后再返回所花费的时间。RTT包含分组传播时延、分组在中间路由器和交换机上的排队时延以及分组处理时延
估算一下从客户请求HTML基本文件到客户收到整个文件所花费的时间?
当用户点击链接时,引起浏览器在它和Web服务器之间发起一个TCP连接;这涉及一次”三次握手“过程,即客户向服务器发送一个小TCP报文段,服务器用一个小TCP报文段做出确认和响应,最后客户向服务器返回确认。
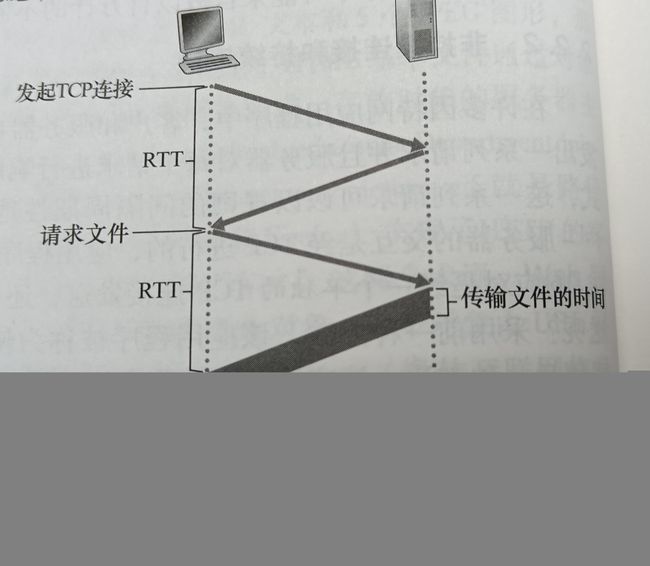
三次握手中前两部分耗费的时间占用了一个RTT,完成后客户向TCP连接发送一个HTTP请求报文,服务器对此HTTP请求做出HTTP响应,这样又耗费一个RTT,因此
总的响应时间就是两个RTT加上服务器传输HTML文件的时间。
- 持续连接的HTTP
非持续连接有一些缺点。第一,必须为每一个请求的对象建立和维护一个全新的连接,对于每一个这样的连接,在客户和服务器中都要分配TCP的缓冲区和保持TCP变量,给Web服务器带来严重负担;第二,每一个对象经受两倍RTT的交付时延,一个RTT用于创建TCP,另一个用于请求和接收对象。
在采用持续连接情况下,服务器在发送响应后保持该TCP连接打开。在相同的客户和服务器之间,后续的请求和响应报文能够通过相同的连接进行传送。HTTP的默认模式是使用带流水线的持续连接。
用户与服务器的交互:cookie
我们已经知道HTTP服务器是无状态的,然而一个Web站点通常希望能够识别用户,为此HTTP使用了cookie。
如图,cookie技术有4个组件:①在HTTP响应报文中的一个cookie首部行;②在HTTP请求报文中的一个cookie首部行;③在用户端系统保留有一个cookie文件,由用户的浏览器进行管理;④位于Web站点的一个后端数据库。
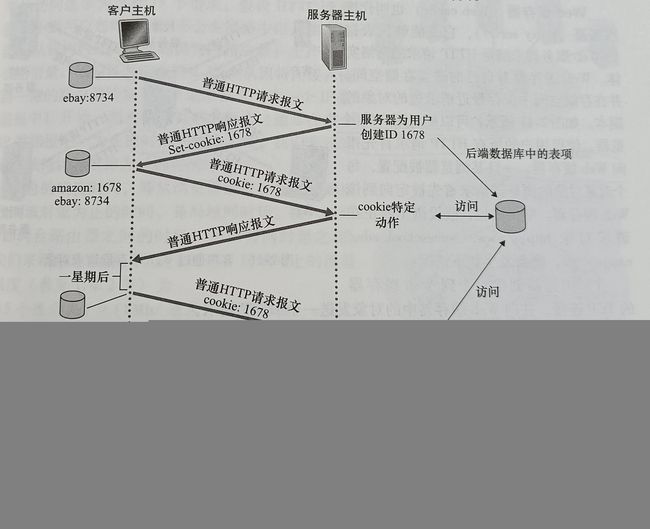
cookie可用于标识一个用户。用户首次访问一个站点时,可能需要提供一个用户标识。在后继会话中,浏览器向服务器传递一个cookie首部,从而向该服务器标识了用户。因此cookie可以在无状态的HTTP之上建立一个用户会话层。但是cookie的使用仍有争议,因为它们被认为是对用户隐私的一种侵害。
Web缓存
Web缓存也叫代理服务器,它是能够代表初始Web服务器来满足HTTP请求的网络实体。
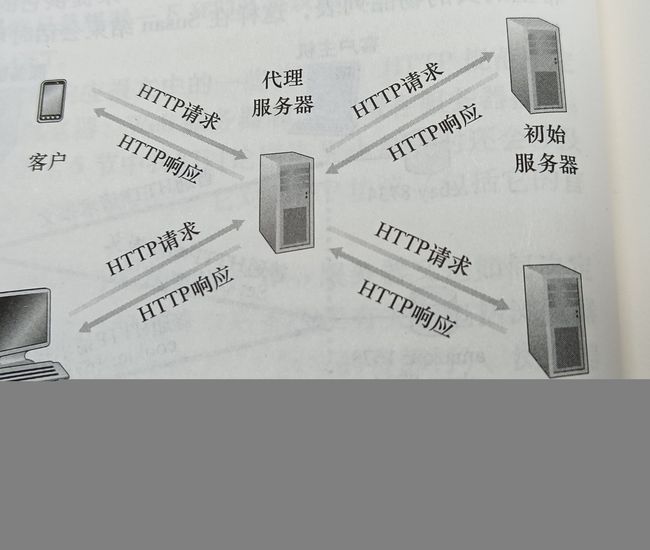
可以配置用户的浏览器,使得用户的所有HTTP请求首先指向Web缓存器,一旦某浏览器被配置,每个对某对象的浏览器请求首先被定向到该Web缓存器。
假设浏览器正在请求对象,会发生如下情况:
(1)浏览器创建一个到Web缓存器的TCP连接,并向Web缓存器中的对象发送一个HTTP请求
(2)Web缓存器进行检查,看看本地是否存储了该对象副本,如果有,Web缓存器就向客户浏览器用HTTP响应报文返回该对象
(3)如果Web缓存器中没有该对象,它就打开一个与该对象的初始服务器的TCP连接。Web缓存器则在这个缓存器到服务器的TCP连接上发送一个该对象的HTTP请求,在收到该请求后,初始服务器向该Web缓存器发送具有该对象的HTTP响应 。
(4)当Web缓存器接收到该对象时,它在本地存储空间存储一份副本,并向客户的浏览器用HTTP响应报文发送该副本(通过现有的客户浏览器和Web缓存器之间的TCP连接)
需要注意的是Web缓存器既是服务器又是客户。当它接收浏览器的请求并发回响应时,它是一个服务器,当它向初始服务器发出请求并接收响应时,它是一个客户。
在因特网上部署Web缓存器有两个原因。首先,Web缓存器可以大大减少对客户请求的响应时间;其次,Web缓存器能够大大减少一个机构的接入链路到因特网的通信量。
因特网中的电子邮件
电子邮件是一种异步通信媒介。
下图给出因特网电子邮件系统的总体情况。
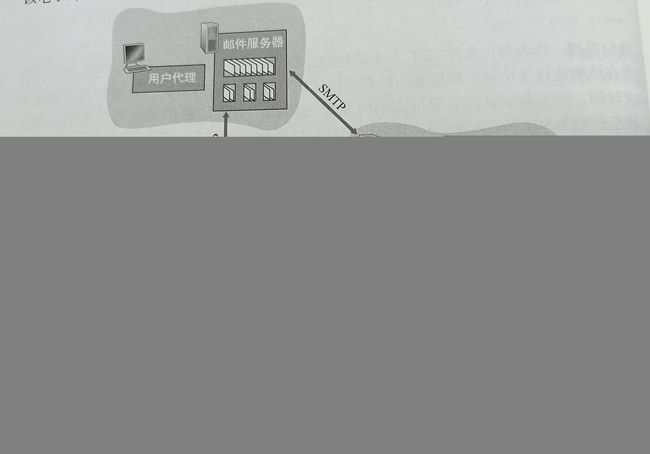
它有三个主要组成部分:用户代理(user agent)、邮件服务器(mail server)、简单邮件传输协议(Simple Mail Transfer Protocol,SMTP)。
一个典型的邮件发送过程:从发送方的用户代理开始,传输到发送方的邮件服务器,再传输到接收方的邮件服务器,然后在这里被分发到接收方的邮箱中。
SMTP是因特网电子邮件中主要的应用层协议。它使用TCP可靠数据传输服务,从发送方的邮件服务器向接收方的邮件服务器发送邮件。
假设Alice想给Bob发送一封简单的报文,
(1)Alice调用她的邮件代理程序并提供Bob的邮件地址,撰写报文,然后指示用户代理发送该报文。
(2)Alice的用户代理把报文发给她的邮件服务器,在那里该报文被放在报文队列中。
(3)运行在Alice的邮件服务器上的SMTP客户端发现了报文队列中的这个报文,它就创建一个到运行在Bob的邮件服务器上的SMTP服务器的TCP连接。
(4)在经过一些初始SMTP握手后,SMTP客户端通过该TCP连接发送Alice的报文。
(5)在Bob的邮件服务器上,SMTP的服务器端接收该报文。Bob的邮件服务器然后将该报文放入Bob的邮箱中。
(6)在Bob方便的时候,他调用用户代理阅读该报文。
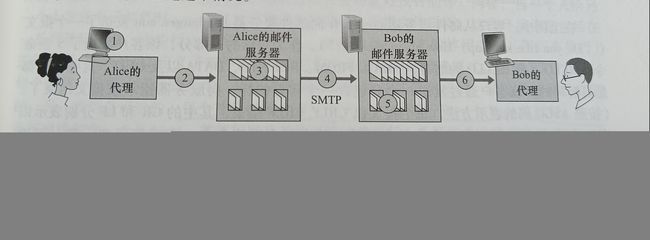
SMTP一般不使用中间邮件服务器发送邮件,即使这两个邮件服务器位于地球两端也是这样。如果Bob的邮件服务器没有开机,该报文回保留在Alice的邮件服务器上并等待进行新的尝试,这意味着邮件并不在中间的某个邮件服务器存留。
SMTP与HTTP的对比
这两个协议都是用于从一台主机向另一台主机传送文件:HTTP从Web服务器向Web客户(通常是一个浏览器)传送文件;SMTP从一个邮件服务器向另一个邮件服务器传送文件(电子邮件报文),当进行文件传送时,持续的HTTP和SMTP都使用持续连接。
两者之间的区别:
(1) HTTP主要是一个拉协议(pull protocol),用户使用HTTP从该服务器拉取这些信息。这个TCP连接是由想接收文件的机器发起的;另一方面,SMTP基本上是一个推协议(push protocol),即发送邮件服务器把文件推向接收邮件服务器,这个TCP连接是由要发送该文件的及其发起的。
(2)SMTP要求每个报文(包括他们的体)采用7比特ASCII码格式。如果某报文包含了非7比特ASCII字符或二进制数据,则该报文必须按照7比特ASCII码进行编码。HTTP数据则不受这种限制。
(3)第三个重要区别是如何处理一个既包含文本又包含图形(也可能是其他媒体类型)的文档,HTTP把每个对象封装到它自己的HTTP响应报文中,而SMTP则把所有报文对象放在一个报文之中。
邮件访问协议
一旦SMTP将邮件报文从Alice的邮件服务器交付给Bob的邮件服务器 ,该报文就被放入Bob的邮箱。如下图所示,Alice的用户代理用SMTP将电子邮件报文推入她的邮件服务器,接着她的邮件服务器(作为一个SMTP客户)再用SMTP将该邮件中继到Bob的邮件服务器。这里为什么要分为两步?主要是因为不通过Alice的邮件服务器进行中继,Alice的用户代理没有办法到达一个不可达的目的地接收服务器。
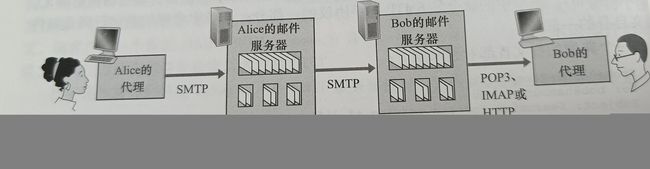
Bob是如何通过运行其本地PC上的用户代理,获得位于他的某ISP的邮件服务器上的邮件呢?
Bob的用户代理不能使用SMTP得到报文,因为取报文是一个拉操作,而SMTP协议是一个推协议。通过引入一个特殊的邮件访问协议来解决这个难题,该协议将Bob邮件服务器上的报文传送给他的本地PC。目前有一些流行的邮件访问协议包括第三版的邮局协议(PostOffice Protocol——Version3,POP3),因特网邮件访问协议(Internet Mail Access Protocol,IMAP)以及HTTP
如上图(图2-16),SMTP用来将邮件从发送方的邮件服务器传输到接收方的邮件服务器 ,也用来将邮件从发送方的用户代理传送到发送方的邮件服务器,POP3这样的邮件访问协议用来将邮件从接收方的邮件服务器传送到接收方的用户代理。
POP3
POP3是一个极为简单的邮件访问协议,由RFC1939进行定义。当用户代理(客户)打开了一个到邮件服务器(服务器)端口110上的TCP连接后,POP3就开始工作了,随着建立TCP连接,POP3按照三个阶段进行工作:特许、事务处理以及更新。
IMAP
基于Web的电子邮件
DNS:因特网的目录服务
因特网的主机和人类一样,可以使用多种方式进行标识,主机的一种标识方法是用它的主机名(hostname) ,也可以使用IP地址进行标识。
DNS提供的服务
识别主机有两种方式,通过主机名或者IP地址。人们喜欢便于记忆的主机名标识方式,而路由器则喜欢定长的、有着层次结构的IP地址,为了折中,我们需要一种能进行主机名到IP地址转换的目录服务,这就是域名系统(Domain Name System,DNS)的主要任务。DNS是:①一个由分层的DNS服务器(DNS server)实现的分布式数据库;②一个使得主机能够查询分布式数据库的应用层协议DNS协议运行在UDP上,使用53号端口。
DNS通常是由其他应用层协议所使用的,包括HTTP、SMTP和FTP,将用户提供的主机名解析为IP地址。
举一个例子,考虑运行在某用户主机上的一个浏览器(即一个HTTP客户)请求URL www.someschool.edu/index.html页面时会发生什么现象。为了使用户的主机能够将一个HTTP请求报文发送到Web服务器www.someschool.edu,该用户主机必须获得www.someschool.edu的IP地址。其做法如下
(1)同一台用户主机上运行着DNS应用的客户端
(2)浏览器从上述URL中抽取出主机名www.someschool.edu,并将这台主机名传给DNS应用的客户端
(3)DNS客户向DNS服务器发送一个包含主机名的请求
(4)DNS客户最终会收到一份响应报文,其中含有对应于该主机名的IP地址
(5)一旦浏览器接收到来自DNS的该IP地址,它能够向位于该IP地址80端口的HTTP服务器进程发起一个TCP连接
除了进行主机名到IP地址的转换外,DNS还提供了一些重要的服务:
- 主机别名 有着复杂主机名的主机能拥有一个或多个别名,应用程序可以调用DNS来获得主机别名对应的规范主机名以及主机的IP地址
- 邮件服务器别名
- 负载分配 DNS也用在冗余的服务器之间进行负载分配
DNS工作机理概述
假设运行在用户主机上的某些应用需要将主机名转换为IP地址。这些应用程序将调用DNS的客户端,并指明需要被转换的主机名。用户主机上的DNS接收到后,向网络中发送一个DNS查询报文。所有的DNS请求和回答报文使用UDP数据报经端口53发送 。经过若干时间的时延后,用户主机上的DNS接收到一个提供所希望映射的DNS回答报文,这个映射结果则被传递到调用DNS的应用程序。因此从用户主机上调用应用程序的角度看 ,DNS是一个提供简单、直接的转换服务的黑盒子。
DNS的一种简单设计是在因特网上只使用一个DNS服务器,该服务器包含所有的映射。在这种集中式设计中,客户直接将所有查询直接发往单一的DNS服务器,同时该DNS服务器直接对所有的查询客户做出响应,但是这种集中式设计的问题包括:
(1)单点故障 如果该DNS服务器崩溃,整个因特网随之瘫痪
(2)通信容量 单个DNS不得不处理所有的DNS查询
(3)远距离的集中式数据库 单个DNS服务器不可能”邻近“所有查询客户,所以可能会导致严重的时延
(4)维护 单个DNS服务器不得不为所有的因特网主机保留记录,这将使这个中央数据库庞大。
因此DNS采用了分布式的设计方案
(1)分布式、层次结构
为了处理扩展性问题,DNS使用了大量的DNS服务器,它们以层次方式组织,并且分布在全世界范围内。没有一台DNS服务器拥有因特网上所有主机的映射,相反这些映射分布在所有的DNS服务器上,大致来说有三种类型的DNS服务器:根DNS服务器、顶级域(Top-Level Domain,TLD)DNS服务器和权威DNS服务器
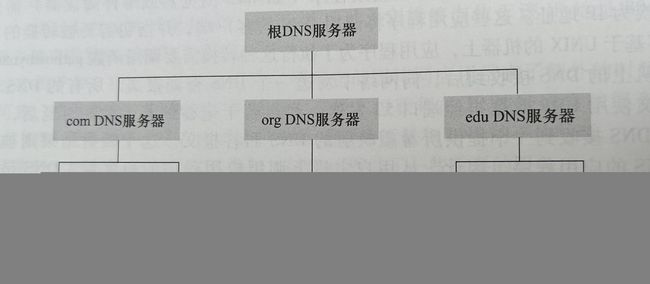
- 根服务器 有400多个根服务器遍及全世界,这些根服务器由13个不同的组织管理,根服务器提供TLD服务器的IP地址
- 顶级域DNS服务器 对于每个顶级域和所有国家的顶级域,都有TLD服务器。TLD服务器提供了权威DNS服务器的IP地址
- 权威DNS服务器 在因特网上具有公共可访问主机的每个组织机构必须提供公共可访问的DNS记录,这些记录将这些主机的名字映射为IP地址
根、TLD、和权威DNS服务器都处在该DNS服务器的层次结构中,还有另一类重要的DNS服务器,称为本地DNS服务器(local DNS server),严格来说一个本地DNS服务器并不属于该服务器的层次结构,但他对DNS层次结构是至关重要的。每个ISP都有一台本地DNS服务器,当主机与某个ISP连接时,该ISP提供一台主机的IP地址,该主机具有一台或多台其本地DNS服务器的IP地址
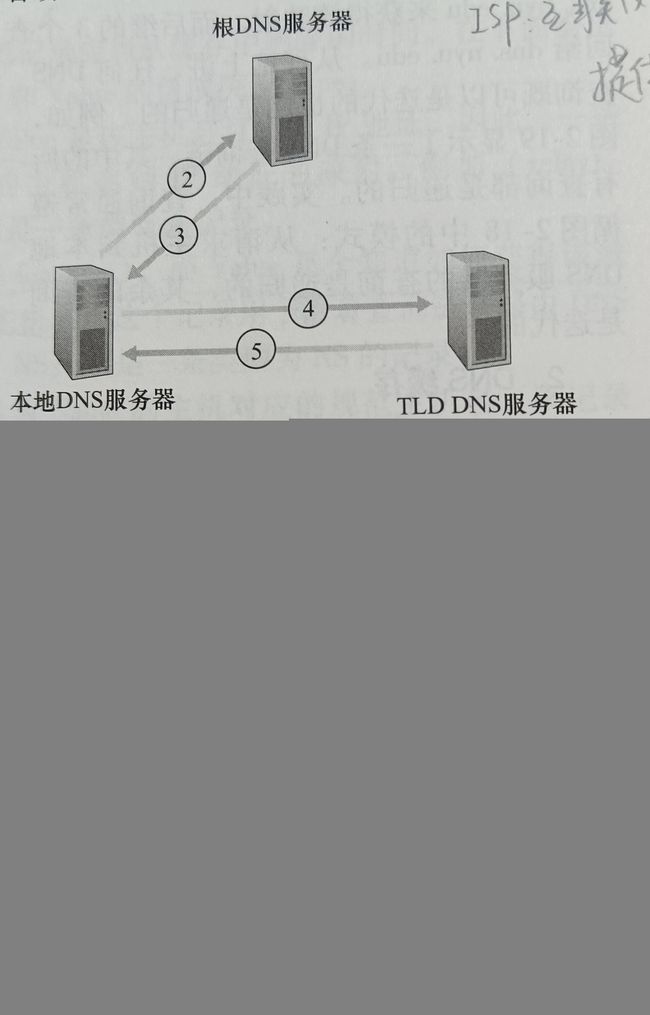
DNS缓存
为了改善时延性能并减少在因特网上到处传输的DNS报文数量,DNS广泛使用了缓存技术。DNS缓存的原理非常简单,在一个请求链中,当某DNS服务器接收一个DNS回答时,它能将映射缓存在本地存储器中,事实上因为缓存,除了少数DNS查询以外,根服务器被绕过了。
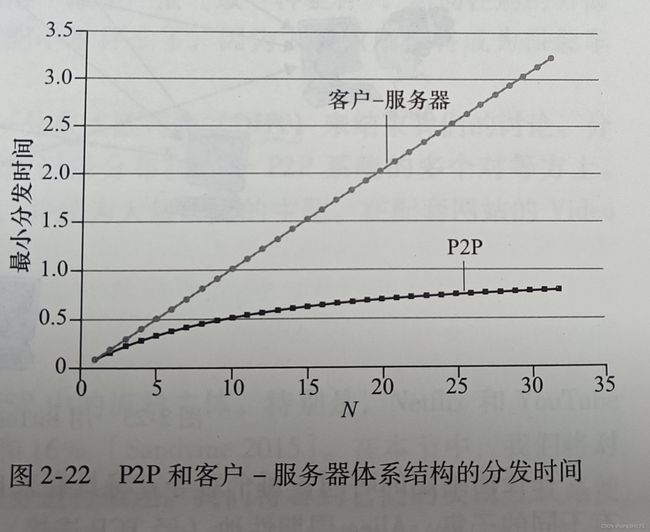
P2P文件分发
截至目前我们所描述的应用都采用了客户——服务器模式,极大地依赖总是打开的基础设施服务器,而使用p2p体系,对总是打开的基础设施服务器有最小的(或者没有)依赖,成对间歇连接的主机(称为对等方)彼此直接通信,这些对等方并不为服务提供商所拥有。
在客户——服务器模式下进行文件分发,该服务器必须向每个对等方发送该文件的一个副本,即服务器承受了极大的负担,并且消耗了大量的服务器带宽。在P2P文件分发中,每个对等方能够向任何其他对等方重新发送它已经收到的该文件的任何部分,从而在分发过程中协助该服务器。
具有P2P体系结构的应用程序能够是自扩展的。这种扩展性的直接成因是:对等方除了是比特的消费者外还是它们的重新分发者。